







一、爬取数据
①qiancheng.py

②pipelines.py

③sitting

④items

二、数据储存
1、把MongoDB数据导出为csv文件
在E:\MongoDB\bin下cmd
mongoexport.exe --csv -f _id,name,salary,gongsi,didian,jingyan,xueli,neirong,jineng -d qiancheng -c Table -o Test.csv


2、上传数据
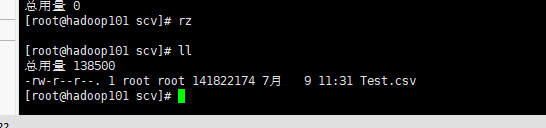
3、利用flume收集日志
(1)创建agent-hdfs.conf文件
vi agent-hdfs.conf
(2)配置agent-hdfs.conf文件

(3)查看日志
在这里执行目录下执行命令

./bin/flume-ng agent --conf ./conf/ --name a2 --conf-file ./conf/agent_hdfs.conf -Dflume.root.logger=DEBUG,console


三、数据分析
1、导入数据
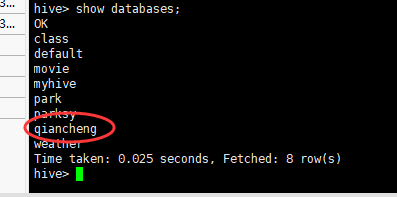
(1)创建数据库
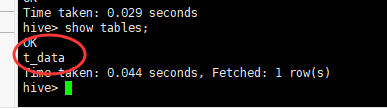
(2)创建表
(3)导入数据到t_data表中
(4)查看数据
select * from t_data;

2、岗位薪资分析
(1)数据分析岗位
①模糊匹配:条件为数据分析、万/月,提取name和salary字段存入sjfx1表中
create table sjfx1 as select name, salary from t_data where name like '%数据分析%' and salary like '%万/月%';
查看sjfx1中是否有数据
select * from sjfx1 limit 10;

②分割薪资,求出每个岗位的最高、最低、平均工资
create table sjfx2 as select name, regexp_extract(salary,'([0-9]+)-',1) as salary1_min, regexp_extract(salary,'-([0-9]+)',1) as salary1_max, (regexp_extract(salary,'([0-9]+)-',1) + regexp_extract(salary,'-([0-9]+)',1))/2 as salary1_avg from sjfx1;
查看sjfx2中是否有数据
select * from sjfx2 limit 10;

③计算所有数据分析岗位的最大 、最小、平均工资
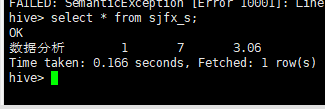
create table sjfx_s as select "数据分析" as name, min(int(salary1_min)) as salary1_min, max(int(salary1_max)) as salary1_max, regexp_extract(avg(salary1_avg),'([0-9]+.[0-9]?[0-9]?)',1) as salary1_avg from sjfx2;
查看sjfx_s表中数据
(2)大数据开发工程师
①模糊匹配:条件为大数据开发工程师、万/月,提取name和salary字段存入kfgc1表中
create table kfgc1 as select name, salary from t_data where name like '%大数据开发%' and salary like '%万/月%';
查看kfgc1中是否有数据
select * from kfgc1 limit 10;

②分割薪资,求出每个岗位的最高、最低、平均工资
create table kfgc2 as select name, regexp_extract(salary,'([0-9]+)-',1) as salary2_min, regexp_extract(salary,'-([0-9]+)',1) as salary2_max, (regexp_extract 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









