






实训要求
利用python编写爬虫程序,从招聘网站上爬取数据,将数据存入到MongoDB数据库中,将存入的数据作一定的数据清洗后做数据分析,利用flume采集日志进HDFS中,利用hive进行分析,将hive分析结果利用sqoop技术存储到mysql数据库中,并显示分析结果,最后将分析的结果做数据可视化。
搭建爬虫
本次选取的网站是前程无忧网,利用框架是scrapy。
1. 用scrapy框架创建爬虫
2. items.py
import scrapy
class Job51Item(scrapy.Item):
zhiweimingcheng = scrapy.Field()
xinzishuipin = scrapy.Field()
zhaopindanwei = scrapy.Field()
gongzuodidian = scrapy.Field()
gongzuojingyan = scrapy.Field()
xueliyaoqiu = scrapy.Field()
yaoqiu = scrapy.Field()
jineng = scrapy.Field()
fabushijian = scrapy.Field()
3. setting.py
BOT_NAME = 'job51'
SPIDER_MODULES = ['job51.spiders']
NEWSPIDER_MODULE = 'job51.spiders'
ROBOTSTXT_OBEY = False
# mongodb地址
MONGODB_HOST='127.0.0.1'
# mongodb端口号
MONGODB_PORT = 27017
# 数据库名称
MONGODB_DBNAME = '51job_scrapy'
# 表名称
MONGODB_DOCNAME = '51job_scrapy_table01'
# 请求头信息
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User_Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
# 下载管道
# ITEM_PIPELINES = {
# 'qianchengwuyou.pipelines.QianchengwuyouPipeline': 300,
# }
ITEM_PIPELINES = {
'job51.pipelines.Job51Pipeline':300,
}
# 下载延时
DOWNLOAD_DELAY = 0.01
4. pipelines.py
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
import pymongo
class Job51Pipeline:
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
self.client = pymongo.MongoClient(host=host,port=port)
self.db = self.client[settings['MONGODB_DBNAME']]
self.coll = self.db[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
data = dict(item)
self.coll.insert(data)
return item
def close(self):
self.client.close()
5. start.py
from scrapy.cmdline import execute
execute("scrapy crawl job_scrapy".split())
mongodb中存储的数据

将文件存如mongodb导出为csv文件
在mongodb目录下输入
mongoexport -h localhost:27017 -d lx -c wuyou -o D:qcwy.csv
csv文件
6. 爬取下来的数据保存到flume日志存储到hdfs中

测试hive导入数据是否成功

7. Hive数据分析




8. 将hive分析结果利用sqoop技术存储到mysql数据库中
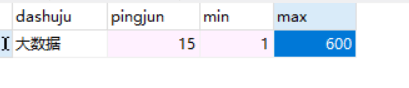
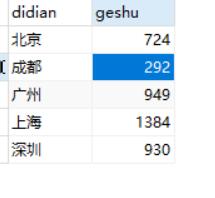
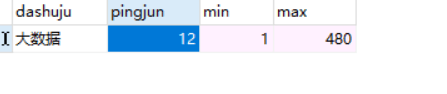

9. 数据可视化处理和分析
- 1-3年大数据的工资分析

- 分析地区岗位个数

- 数据分析,大数据开发,数据采集岗位的最低,最高,平均的工资

- 相关岗位需求的走向趋势折线图
















 5017
5017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









