






在第 6 章和第 8 章中分别介绍的细分 (BD) 图和 Shapley 值最适合具有少量或中等解释变量的模型。
这些方法都不适合具有大量解释变量的模型,因为它们通常确定模型中所有变量的非零属性。然而,在基因组学或图像识别等领域,具有数十万甚至数百万个解释(输入)变量的模型并不少见。在这种情况下,具有少量变量的稀疏解释提供了一个有用的替代方案。这种稀疏解释器最流行的例子是局部可解释模型无关解释 (LIME) 方法及其修改。
LIME 方法最初由 Ribeiro、Singh 和 Guestrin (2016) 提出。其背后的关键思想是通过更简单的玻璃盒模型局部近似黑盒模型,这更容易解释。在本章中,我们将介绍这种方法。
1、直观了解
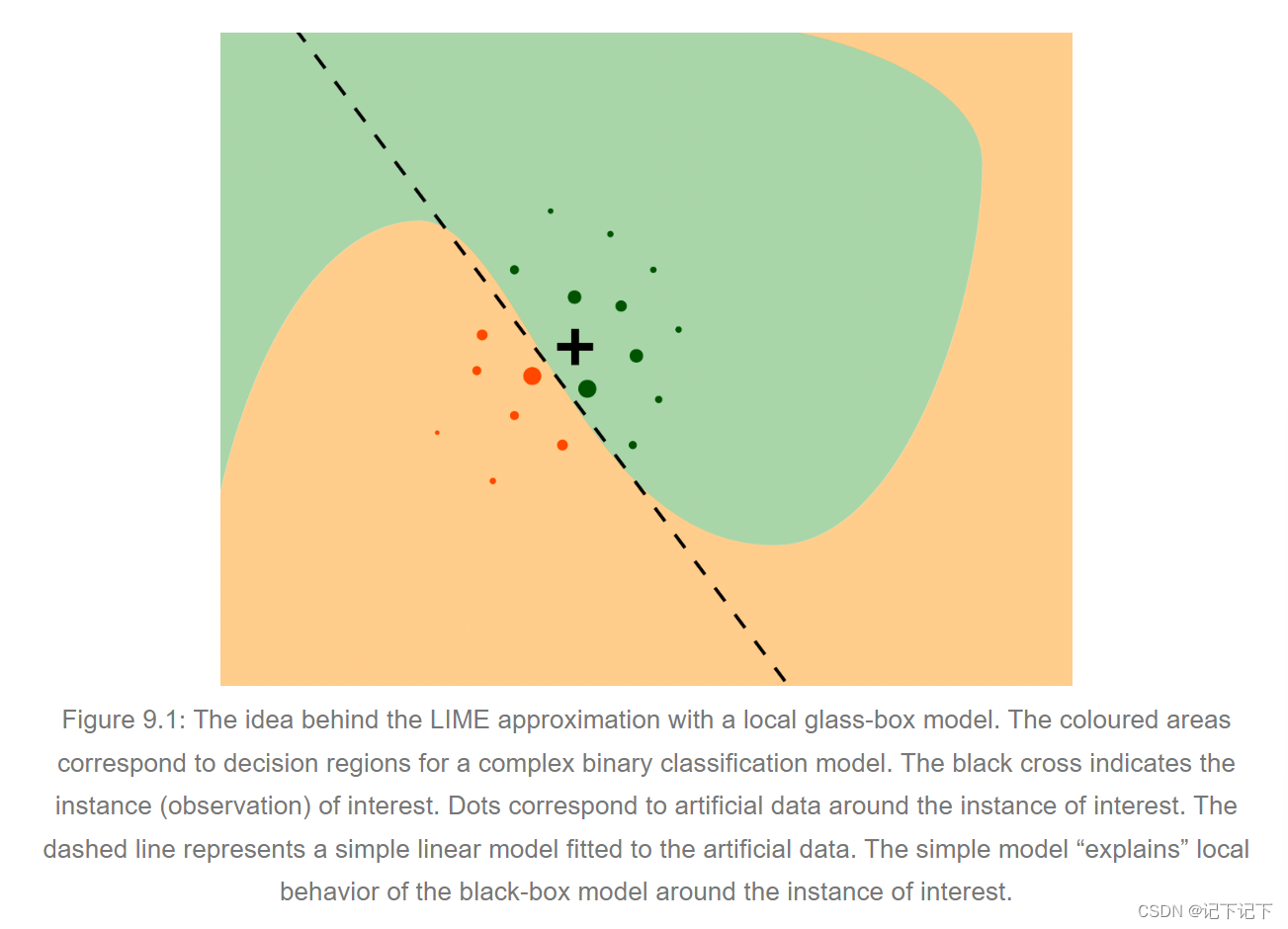
图 9.1 解释了 LIME 方法背后的直觉。我们想要了解影响单个感兴趣实例(黑色十字)的复杂黑盒模型的因素。图 9.1 中显示的彩色区域对应于二元分类器的决策区域,即它们与二元因变量值的预测有关。轴表示两个连续解释变量的值。彩色区域表示两个变量的值的组合,模型根据这两个变量将观察结果归类为两个类之一。为了了解复杂模型在感兴趣点周围的局部行为,我们生成了一个人工数据集,并对其拟合了一个玻璃盒模型。图 9.1 中的点表示生成的人工数据;点的大小对应于与感兴趣实例的接近度。我们可以将一个更简单的玻璃盒模型拟合到人工数据中,以便它在局部近似黑盒模型的预测。在图 9.1 中,一个简单的线性模型(用虚线表示)用于构建局部近似。较简单的模型充当较复杂模型的“局部解释器”。
我们可能会选择不同类别的玻璃盒模型。最典型的选择是正则化线性模型,如 LASSO 回归(Tibshirani 1994)或决策树(Hothorn、Hornik 和 Zeileis 2006)。两者都会产生更易于理解的稀疏模型。重点是限制模型的复杂性,以便更容易解释。
2、计算原理
我们想找到一个模型,该模型在感兴趣的实例 x –– ∗ 周围局部近似黑盒模型 f ( )。考虑 G 类简单、可解释的模型,例如线性模型或决策树。为了找到所需的近似值,我们最小化一个“损失函数”:
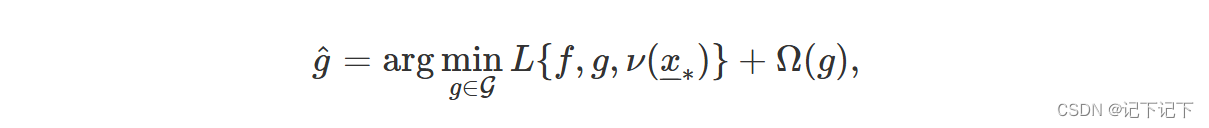
其中模型 g ( ) 属于 G 类 , ν ( x ∗ ) 定义了 x∗ 的邻域,其中寻求近似值,L ( ) 是测量模型 f ( ) 和 g ( ) 在邻域 ν ( x ∗) 中的差异的函数,而 Ω ( g ) 是对模型 g ( ) 复杂度的惩罚。惩罚用于支持 G 类的简单模型。在应用中,通过将 G 类限制为具有相同复杂度(即具有相同系数)的模型,通常可以简化此标准。在这种情况下,每个模型 g ( ) 的 Ω ( g ) 是相同的,因此可以在优化中省略它。
请注意,模型 f ( ) 和 g ( ) 可以在不同的数据空间上运行。黑盒模型(函数)f ( x –– ) : X → R 定义在一个大的 p 维空间 X 上,对应于模型中使用的 p 解释变量。玻璃盒模型(函数)g ( x –– ) : ~ X → R 定义在 q 维空间 ~ X 上,其中 q << p ,通常称为“可解释表示空间”。我们将在下一节中介绍一些 ~ X 的例子。现在,我们只假设某个函数 h ( ) 将 X 转换为 ~ X 。
如果我们将 G 类限制为非零系数数量有限的线性模型,例如 K,则可以使用以下算法来查找可解释的玻璃盒模型 g ( ),其中包含 K 个最重要的、可解释的、解释性的变量:

在步骤 7 中,K-LASSO(y', x', w') 代表加权 LASSO 线性回归,它根据权重为 w' 的新数据 y' 和 x' 选择 K 个变量。
这一想法的实际实施涉及三个重要步骤,这些步骤将在后续小节中讨论。
(1)可解释的数据表示
如前所述,黑盒模型 f ( ) 和玻璃盒模型 g ( ) 在不同的数据空间上运行。例如,让我们考虑一个在ImageNet数据上训练的VGG16神经网络(Simonyan和Zisserman 2015)(邓等人,2009)。该模型使用 244 × 244 像素大小的图像作为输入,并预测图像属于 1000 个潜在类别中的哪一个。原始空间 X 的维度为 3 × 244 × 244(单个像素的三个单色通道(红色、绿色、蓝色)× 244 × 244 像素),即输入空间为 178,608 维。在这样一个高维空间中解释预测是很困难的。相反,从单个感兴趣实例的角度来看,空间可以转换为超像素,这些超像素被视为可以打开或关闭的二进制特征。 图 9.2(右侧面板)显示了为模棱两可的图片创建的 100 个超像素的示例。因此,在这种情况下,黑盒模型 f ( ) 在空间 X = R 178608 上运行,而玻璃盒模型 g ( ) 适用于空间 ~ X = { 0 , 1 } 100 。
值得注意的是,基于图像分割的超像素是图像数据的常见选择。对于文本数据,单词组经常用作可解释变量。对于表格数据,通常对连续变量进行离散化以获得可解释的分类数据。在分类变量的情况下,通常使用类别组合。我们将在下一节中介绍示例。

(2)围绕感兴趣的实例进行抽样
要开发局部近似玻璃盒模型,我们需要在感兴趣的实例周围的低维可解释数据空间中获取新的数据点。可以考虑从原始数据集中采样数据点。但是,可能没有足够的点可供采样,因为高维数据集中的数据通常非常稀疏,数据点彼此“相距甚远”。因此,我们需要新的人工数据点。出于这个原因,开发玻璃盒模型的数据通常是通过使用感兴趣的实例的扰动来创建的。
对于低维空间中的二进制变量,常见的选择是切换(从 0 到 1 或从 1 到 0)描述感兴趣实例的随机选择的变量数量的值。
对于连续变量,不同的论文提出了各种建议。例如,Molnar、Bischl 和 Casalicchio (2018) 和 Molnar (2019) 建议向连续变量添加高斯噪声。 Pedersen 和 Benesty (2019) 建议使用分位数对连续变量进行离散化,然后扰动变量的离散化版本。Staniak 等人 (2019) 根据局部其他条件不变轮廓的分割对连续变量进行离散化(有关轮廓的更多信息,请参阅第 10 章)。
在图 9.2 中的鸭马图像示例中,可以通过随机排除一些超像素来创建图像的扰动。此过程的图示如图 9.3 所示。

(3) 拟合玻璃盒模型
一旦围绕感兴趣实例创建了人工数据,我们就可以尝试从类别 G 中拟合一个可解释的玻璃盒模型 g()。
对于类别 G ,最常见的选择是广义线性模型。为了获得稀疏模型,即具有有限数量变量的模型,可以使用 LASSO(最小绝对收缩和选择算子)(Tibshirani 1994)或类似的正则化建模技术。例如,在第 9.3 节中介绍的算法中提到了具有 K 个非零系数的 K-LASSO 方法。另一种选择是分类和回归树模型(Breiman 等人 1984)。
对于图 9.2 中的鸭马图像示例,VGG16 网络提供了 1000 个概率,表明该图像属于用于训练网络的 1000 个类别之一。看来该图像最可能的两个类别是“标准贵宾犬”(概率为 0.18)和“鹅”(概率为 0.15)。图 9.4 展示了 LIME 对这两个预测的解释。这些解释是使用 K-LASSO 方法获得的,该方法选择了从模型预测的角度来看最具影响力的 K = 15 个超像素。对于选定的两个类别中的每一个,将突出显示具有非零系数的 K 个超像素。有趣的是,包含喙的超像素对“鹅”预测有影响,而与白色相关的超像素对“标准贵宾犬”预测有影响。至少对于前者,图中的影响特征确实与图像的预期内容相对应。因此,解释的结果增加了对模型预测的信心。

3、参考案例
LIME 方法的大多数示例都与文本或图像数据有关。在本节中,我们将提供一个表格数据二分类的示例,以便于比较不同章节中介绍的方法。
我们将随机森林模型 titanic_rf(参见第 4.2.2 节)和乘客 Johnny D(参见第 4.2.5 节)作为泰坦尼克号数据的感兴趣实例。
首先,我们必须定义一个可解释的数据空间。一种选择是将相似的变量收集到与某些概念相对应的更大的结构中。例如,舱位和票价变量可以组合成“财富”,年龄和性别组合成“人口统计”,等等。然而,在这个例子中,我们得到的变量数量相对较少,因此我们将使用二元向量形式的更简单的数据表示。为了这个目标,每个变量都被分成两个级别。例如,将年龄转换为二元变量,类别为“ ≤ 15.36”和“>15.36”,将阶级转换为二元变量,类别为“一等/二等/甲板船员”和“其他”,等等。一旦定义了低维数据空间,就将 LIME 算法应用于该空间。具体来说,我们首先必须为 Johnny D 适当地转换数据。随后,我们生成一个新的人工数据集,该数据集将用于随机森林模型的 K-LASSO 近似。具体来说,K = 3 的 K-LASSO 方法用于识别三个最具影响力的(二元)变量,这些变量将为 Johnny D 的预测提供解释。这三个变量是:年龄、性别和阶级。这个结果与前几章得出的结论一致。图 9.5 显示了为 K-LASSO 模型估计的系数。

4、优缺点
正如 Ribeiro、Singh 和 Guestrin (2016) 所提到的,LIME 方法
(1)是模型无关的,因为它不包含任何关于黑盒模型结构的假设;(2)提供可解释的表示,因为原始数据空间被转换(例如,通过将图像数据的单个像素替换为超像素)为更易于解释的低维空间;(3)提供局部保真度,即解释在局部上与黑盒模型非常吻合。
该方法已在文本和图像分析中得到广泛采用,部分原因是可解释的数据表示。在这种情况下,解释以图像/文本片段的形式提供,用户可以轻松找到此类解释的理由。该方法的基本原理很容易理解:使用更简单的模型来近似更复杂的模型。通过使用更简单的模型和更少数量的可解释解释变量,预测更容易解释。LIME 方法可以应用于复杂的高维模型。
但是,有几个重要的限制。例如,如第 9.3.2 节所述,对于表格数据,已经提出了多种寻找连续和分类解释变量的可解释表示的提案。这个问题还没有解决。这导致了 LIME 的不同实现,它们使用不同的变量转换方法,因此可能导致不同的结果。
另一个重要的一点是,由于选择玻璃盒模型来近似黑盒模型而不是数据本身,所以该方法不能控制玻璃盒模型与数据的局部拟合质量。因此,后一种模型可能会产生误导。
最后,在高维数据中,数据点是稀疏的。定义感兴趣实例的“局部邻域”可能并不简单。例如,Alvarez-Melis 和 Jaakkola (2018) 讨论了选择邻域的重要性。有时,邻域中的微小变化也会强烈影响获得的解释。
总而言之,LIME 最有用的应用仅限于高维数据,人们可以为高维数据定义低维可解释的数据表示,如图像分析、文本分析或基因组学。















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









