






在第 6 章中,我们介绍了细分 (BD) 图,这是一种用于计算模型预测的解释变量归属的过程。我们还指出,在存在交互作用的情况下,归因的计算值取决于计算中使用的解释协变量的顺序。第 6 章中介绍的这个问题的一个解决方案是找到一个将最重要的变量放在开头的顺序。第 7 章中描述的另一种解决方案是识别交互作用并明确呈现它们对预测的贡献。
在本章中,我们将介绍另一种解决排序问题的方法。它基于对所有(或大量)可能的排序的变量属性值进行平均的想法。这个想法与最初为合作游戏开发的“Shapley价值观”密切相关(Shapley 1953)。Štrumbelj 和 Kononenko (2010) 以及 Štrumbelj 和 Kononenko (2014) 首先将该方法转化为机器学习领域。在 Lundberg 和 Lee (2017) 和 Python 的 SHapley Additive exPlanations 库 (SHAP (Lundberg 2019) 的论文发表后,它已被广泛采用。SHAP的作者为基于树的模型引入了一种有效的算法(Lundberg,Erion和Lee 2018)。他们还表明,Shapley值可以呈现为用于模型解释的不同常用技术的集合的统一(Lundberg和Lee,2017)。
1、直观了解
图 8.1 显示了 10 个随机排序(由每个图中的行顺序表示)的解释变量的 BD 图,用于预测 Johnny D的随机森林模型titanic_rf泰坦尼克号数据集。这些图显示了不同排序的各种变量的贡献的明显差异。对于票价和舱位等变量,可以观察到最显着的差异,贡献会根据顺序改变符号。
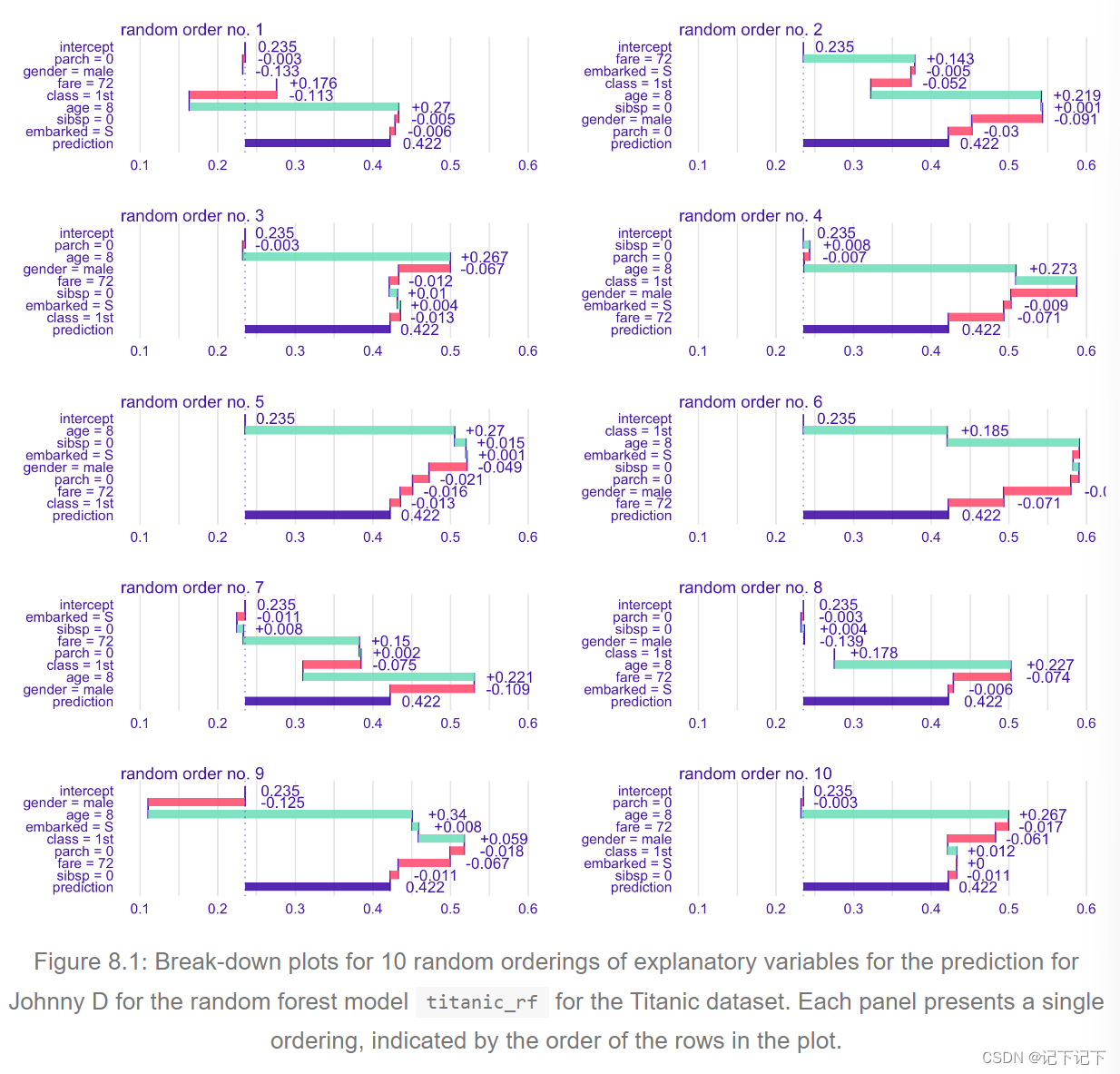
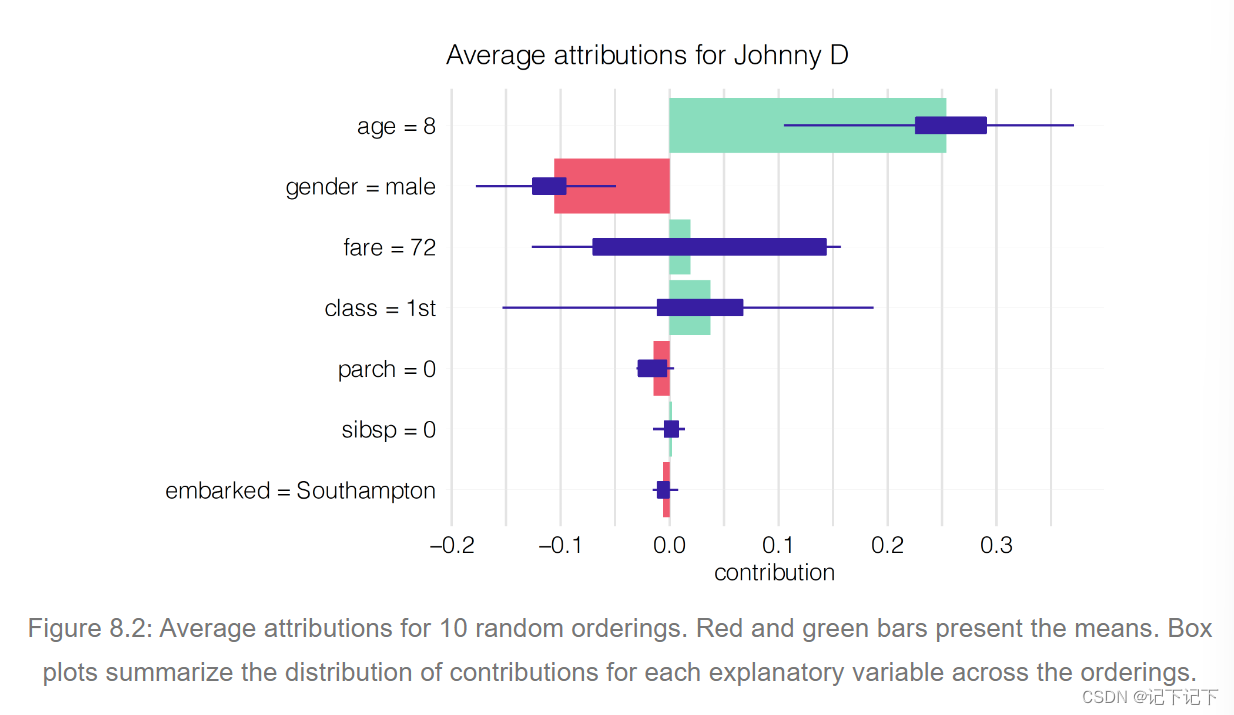
为了消除变量排序的影响,我们可以计算归因的平均值。图 8.2 显示了根据图 8.1 中所示的十个排序计算的平均值。红色和绿色条形分别表示负平均值和正平均值 紫罗兰色箱形图总结了每个解释变量在不同顺序上的属性分布。该图表明,从 Johnny D 的预测角度来看,最重要的变量是年龄、阶级和性别。
2、计算原理
SHapley 加法解释 (SHAP) 基于 Shapley (1953) 在合作博弈论中提出的“Shapley 值”。请注意,这些术语乍一看可能会令人困惑。为合作游戏引入了 Shapley 值。SHAP 是专为预测模型设计的方法的首字母缩写词。为避免混淆,我们将使用术语“Shapley 值”。
Shapley 值是以下问题的解决方案。参与者联盟合作并从合作中获得一定的整体收益。玩家是不一样的,不同的玩家可能有不同的重要性。合作是有益的,因为它可能比个人行动带来更多的好处。要解决的问题是如何在玩家之间分配产生的盈余。Shapley值为这个问题提供了一个可能的公平答案(Shapley 1953)。
让我们将这个问题转换为模型预测的上下文。解释变量是参与者,而模型f( )则扮演联盟的角色。联盟的回报是模型的预测。要解决的问题是如何将模型的预测分布在特定变量之间
Štrumbelj和Kononenko(2010)提出了使用Shapley值评估局部变量重要性的想法。我们将使用第 6.3.2 节中介绍的表示法来定义值。
让我们考虑一个指数集合的排列 J { 1 , 2 , ..., p } 对应于模型 f ( ) 中包含的 p 解释变量的排序。用 π ( J ,j )表示位于 J 中的变量的索引集,该变量位于第 j 个变量之前。请注意,如果将第 j 个变量作为第一个变量,则 π( J ,j )= ∅ 。考虑模型对特定感兴趣实例的预测 f ( x∗ )x∗ 。Shapley 值定义如下:

其中总和被接管了所有 p !可能的排列(解释变量的排序)和变量重要性度量 Δ j | J ( x ∗ ) 在第 6.3.2 节的等式 (6.7) 中定义。从本质上讲,φ ( x∗ , j ) 是解释变量所有可能排序的变量重要性度量的平均值。
值得注意的是,Δ j | π ( J , j ) ( x ∗ ) 对于共享相同子π集 ( J, j ) 的所有排列 J 都是常数。因此,等式(8.1)可以用另一种形式表示:
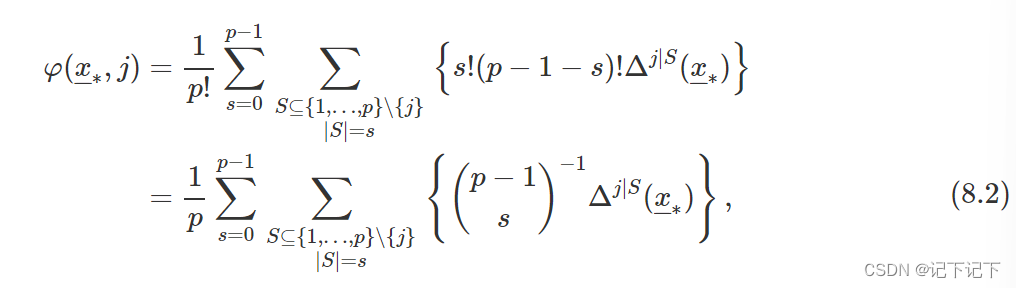
其中 | 小号 | 表示集合 S 的基数(大小),第二个和被取于所有解释变量的子集 S,不包括大小为 s 的第 j 个子集。
请注意,从 0 到 p − 1 的所有大小的子集的数量是 2 p − 1 ,即它远小于所有排列 p 的数量! .然而,对于一个大的 p ,计算 Shapley 值既不使用 (8.1) 也不使用 (8.2) 是可行的。在这种情况下,可以考虑基于排列样本的估计。蒙特卡洛估计器由Štrumbelj和Kononenko(2014)引入。在包 SHAP 中使用了基于树的模型的 Shapley 值计算的有效实现(Lundberg 和 Lee 2017)。
从合作博弈的 Shapley 值的属性可以看出,在预测模型的上下文中,它们具有以下属性:
- 对称性:如果两个解释变量 j 和 k 是可互换的,即,如果对于任何一组解释变量 S ⊆ { 1 , ... , p } ∖ { j , k } 我们得到
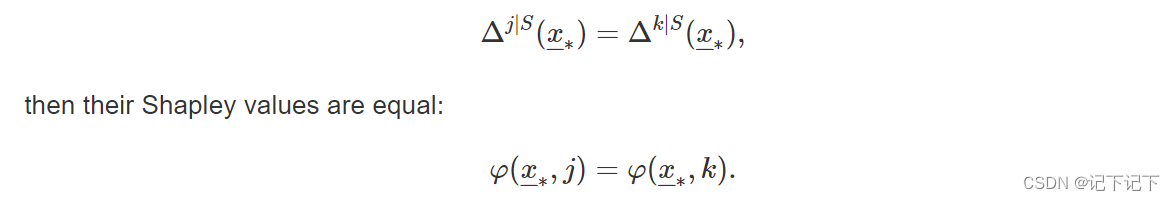
- 虚拟特征:如果解释变量 j 对任何一组解释变量 S ⊆ { 1 , ... , p } ∖ { j } 的任何预测都没有贡献,即如果
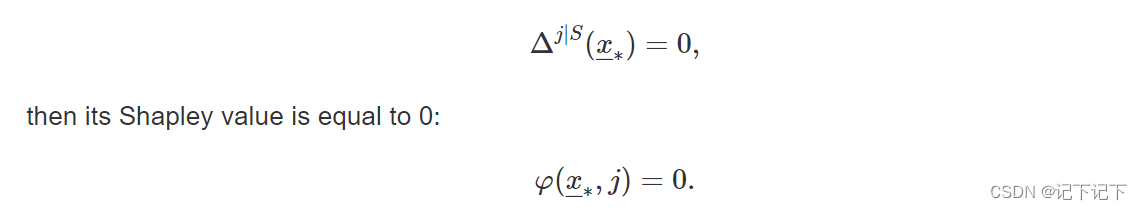
- 可加性:如果模型 f ( ) 是另外两个模型 g ( ) 和 h ( ) 的总和,则模型 f ( ) 计算的 Shapley 值是模型 g ( ) 和 h ( ) 的 Shapley 值之和。
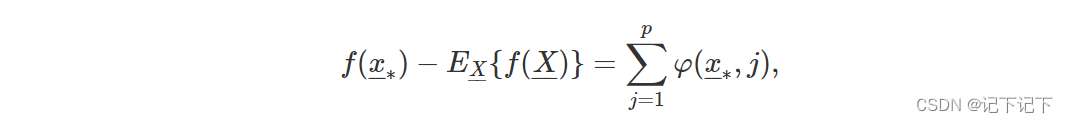
其中 X是被视为随机值的解释变量(对应于 x∗)的向量。
3、案例
让我们考虑随机森林模型titanic_rf和乘客 Johnny D作为泰坦尼克号数据中感兴趣的实例。
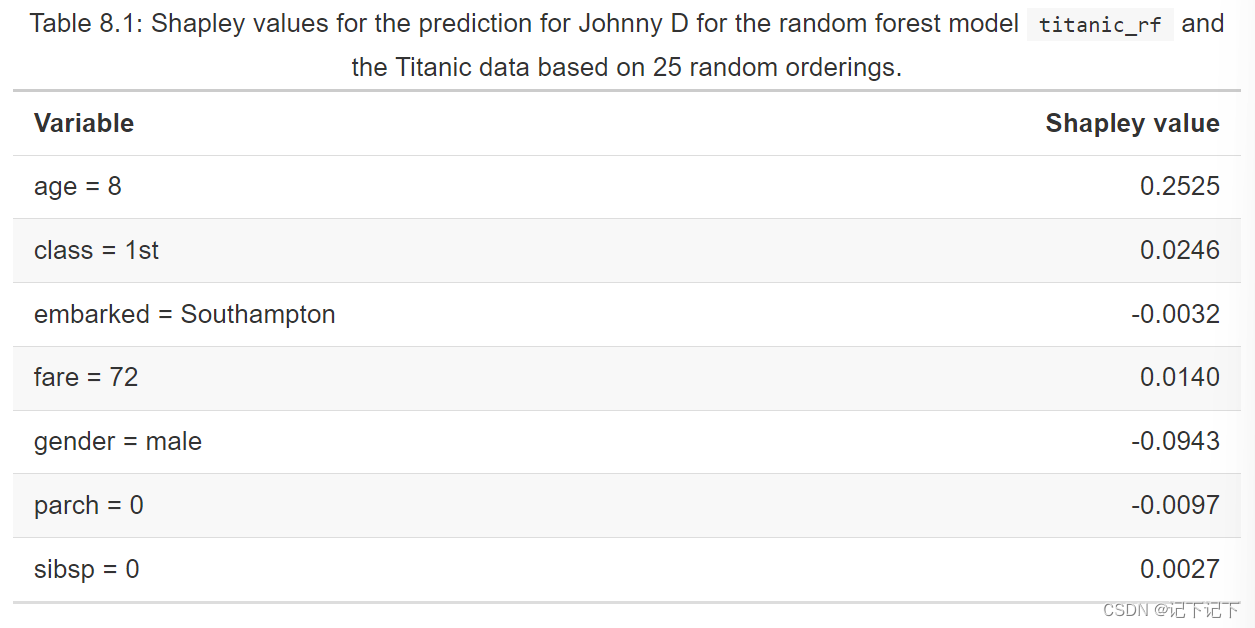
图中的箱形图显示了贡献 Δ j | π ( J , j ) ( x ∗ ) 对于模型的每个解释变量,解释变量的 25 个随机排序。红色和绿色条形分别表示整个排序的负值和正值 Shapley 值。很明显,Johnny D 的年轻对所有订单都做出了积极贡献;生成的 Shapley 值等于 0.2525。另一方面,性别的影响在所有情况下都是负的,Shapley 值等于 -0.0908。
变量票价和类的情况更加复杂,因为它们的贡献甚至可以根据顺序改变符号。请注意,图中分别显示了两个变量中每个变量的 Shapley 值。然而,值得回顾的是,上一节 iBD 图表明了两个变量之间相互作用的重要贡献。因此,它们的贡献不应分开。因此,应谨慎解释图中所示的票价和舱位的 Shapley 值。
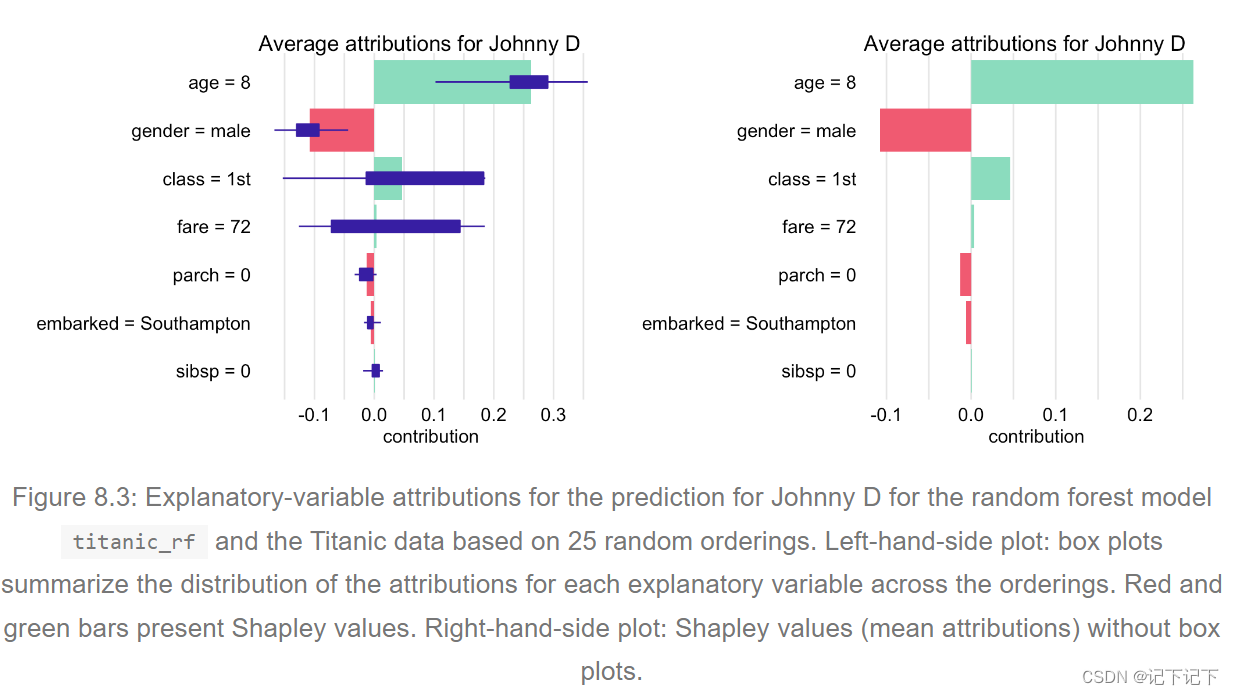
在大多数应用中,有关变量贡献在所考虑的解释变量排序中的分布的详细信息可能不感兴趣。因此,可以通过仅显示 Shapley 值来简化绘图,如图 8.3 右侧面板所示。表 8.1 显示了该图所依据的 Shapley 值。
4、优缺点
Shapley 值提供了一种统一的方法,可以将模型的预测分解为可以加法归因于不同解释变量的贡献。Lundberg 和 Lee (2017) 表明,该方法统一了不同的加法变量归因方法,如 DeepLIFT(Shrikumar、Greenside 和 Kundaje 2017)、逐层相关性传播(Binder 等人,2016 年)或局部可解释模型无关解释(Ribeiro、Singh 和 Guestrin 2016)。该方法从合作博弈论中衍生出坚实的形式基础。它还在 Python 中享有高效的实现,在 R 中具有移植或重新实现。
Shapley 值的一个重要缺点是它们提供了解释变量的累加贡献(归因)。如果模型不是可加的,则 Shapley 值可能会产生误导。这个问题可以看作是由于这样一个事实而产生的,即在合作游戏中,目标是在付款人之间分配收益。然而,在预测建模的背景下,我们想了解参与者如何影响收益?因此,我们不仅限于为玩家提供独立的收益分配。
值得注意的是,对于加法模型,第 6-7 章和当前模型中介绍的方法会导致相同的归因。原因是,对于加法模型,不同的排序会导致相同的贡献。由于 Shapley 值可以看作是所有排序的平均值,因此它本质上是相同值的平均值,即它也假定相同的值。
一般模型无关方法的一个重要实际局限性是,对于大型模型,Shapley 值的计算非常耗时。但是,可以使用子采样来解决此问题。对于基于树的模型,可以使用有效的实现。

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









