










CSDN 目录展示
目录
钉钉机器人消息推送
1- 文本text类型
推送代码案例
import json
from datetime import datetime
import requests
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=*************'
keywords = 'DataWorks'
# 钉钉机器人,发送消息
def dd_robot(url:str, content: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "text",
"text": {
"content": content
}
#这是配置需要@的人
#,"at": {"atMobiles": ["15xxxxxx06",'18xxxxxx1'], "atUserIds": ["user123"], "isAtAll": False}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 主函数
if __name__ == '__main__':
# 编辑需要推送的文档信息
content = keywords + "(DQC)校验告警: \n "
content = content + "【测试时间】:" + now_time + " \n "
content = content + "【测试内容】:" + "测试钉钉推送text文档信息;"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, content)
推送结果
DataWorks(DQC)校验告警:
【测试时间】:2024-12-03 14:34:18
【测试内容】:测试钉钉推送text文档信息;

参数说明
{
"at": {
"atMobiles": [
"180xxxxxx"
],
"atUserIds": [
"user123"
],
"isAtAll": false
},
"text": {
"content": "这里是需要推送的文本内容"
},
"msgtype": "text"
}
| 参数 | 是否必填 | 类型 | 说明 |
|---|---|---|---|
| msgtype | 是 | String | text。 |
| text.content | 是 | String | 消息文本。 |
| at.atMobiles | 否 | Array | 被@人的手机号。 |
| at.atUserIds | 否 | Array | 被@人的用户userid。 |
| at.isAtAll | 否 | Boolean | @所有人是true,否则为false。 |
| keywords | 是 | String | 钉钉机器人的关键词 |
2- 链接Link类型
推送代码案例
import json
from datetime import datetime
import requests
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=**********'
keywords = 'DataWorks'
# 钉钉机器人,发送消息
def dd_robot(url:str, text_content: str, title_content: str, pic_url: str, message_url: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "link",
"link": {
"text": text_content,
"title": title_content,
"picUrl": pic_url,
"messageUrl": message_url
}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 主函数
if __name__ == '__main__':
# 编辑需要推送的信息
title_content = keywords + ":这里是一个Link消息 \n"
text_content = "SQL统计连续登陆3天的用户(连续活跃超3天用户)"
pic_url = "https://img-blog.csdnimg.cn/img_convert/f63f1c575e3c48d9a3f7e4ba9bd460d2.png"
message_url = "https://blog.csdn.net/Taerge0110/article/details/134536574?spm=1001.2014.3001.5502"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, text_content, title_content, pic_url, message_url)
推送结果
DataWorks:这里是一个Link消息
SQL统计连续登陆3天的用户(连续活跃超3天用户)

参数说明
{
"msgtype": "link",
"link": {
"text": "SQL统计连续登陆3天的用户(连续活跃超3天用户)",
"title": "DataWorks:这里是一个Link消息",
"picUrl": "https://img.alicdn.com/tfs/TB1NwmBEL9TBuNjy1zbXXXpepXa-2400-1218.png",
"messageUrl": "https://open.dingtalk.com/document/"
}
}
| 参数 | 参数类型 | 是否必填 | 说明 |
|---|---|---|---|
| msgtype | String | 是 | 消息类型,此时固定为:link。 |
| link.title | String | 是 | 消息标题。如果太长只会部分展示。 |
| link.text | String | 是 | 消息内容。如果太长只会部分展示。 |
| link.messageUrl | String | 是 | 点击消息跳转的URL。 |
| link.picUrl | String | 否 | 图片URL。 |
| keywords | String | 是 | 钉钉机器人的关键词 |
3- Markdown类型
推送代码案例1
import json
from datetime import datetime
import requests
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=************'
keywords = 'DataWorks'
# 钉钉机器人,发送消息
def dd_robot(url:str, text_content: str, title_content: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "markdown",
"markdown": {
"title": title_content,
"text": text_content,
}
#这是配置需要@的人
,"at": {"atMobiles": ["15xxxxxx06"], "atUserIds": ["user123"], "isAtAll": False}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 主函数
if __name__ == '__main__':
# 编辑需要推送的信息
title_content = keywords + ":百度百科 \n"
text_content = "#### 百度百科 \n 百度公司推出的网络百科全书 \n  \n [百度百科](https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E7%99%BE%E7%A7%91?fromModule=lemma_search-box) \n @15xxxxxx06"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, text_content, title_content)
推送结果1
百度百科
百度公司推出的网络百科全书
[图片]
百度百科
@Johnathan

推送代码案例2
import json
from datetime import datetime
import requests
from odps import ODPS
import pandas as pd
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=*************'
keywords = 'DataWorks'
# 钉钉机器人,发送消息
def dd_robot(url:str, text_content: str, title_content: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "markdown",
"markdown": {
"title": title_content,
"text": text_content,
}
#这是配置需要@的人
#,"at": {"atMobiles": ["15xxxxxx06","18xxxxxx1"], "atUserIds": ["user123"], "isAtAll": False}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 执行SQL体
sql = """
SELECT stat_day, COUNT(1) AS ct
FROM st_bi_stock_sales_ratio_msku_hi
WHERE pt = MAX_PT('st_bi_stock_sales_ratio_msku_hi')
GROUP BY stat_day
ORDER BY stat_day
"""
# 主函数
if __name__ == '__main__':
# 执行SQL并读取结果
with odps.execute_sql(sql).open_reader() as reader:
df = reader.to_pandas() # 转换为Pandas DataFrame
#print(df)
# 转换为Markdown表格格式
markdown_table = "| " + " | ".join(df.columns) + " |\n"
markdown_table += "| " + " | ".join(["---"] * len(df.columns)) + " |\n"
for row in df.itertuples(index=False):
markdown_table += "| " + " | ".join(map(str, row)) + " |\n"
# 打印Markdown格式表格
#print(markdown_table)
# 编辑需要推送的信息
title_content = keywords + ":数据量查看 \n"
text_content = "#### 库销比统计 \n 库销比统计近4天数据量(" + now_time + ") \n"
text_content += markdown_table + "\n"
text_content += "By Johnathan \n"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, text_content, title_content)
推送结果2
库销比统计
库销比统计近4天数据量(2024-12-04 16:47:41)
stat_day ct
2024-12-01 10603
2024-12-02 10612
2024-12-03 10595
2024-12-04 10625
By Johnathan

推送代码案例2 (版本2)
import json
from datetime import datetime
import requests
from odps import ODPS
import pandas as pd
from tabulate import tabulate
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=**********'
keywords = 'DataWorks'
# 钉钉机器人,发送消息
def dd_robot(url:str, text_content: str, title_content: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "markdown",
"markdown": {
"title": title_content,
"text": text_content,
}
#这是配置需要@的人
#,"at": {"atMobiles": ["15xxxxxx06","18xxxxxx1"], "atUserIds": ["user123"], "isAtAll": False}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 执行SQL体
sql = """
SELECT stat_day, COUNT(1) AS ct
FROM st_bi_stock_sales_ratio_msku_hi
WHERE pt = '2024121312'
GROUP BY stat_day
ORDER BY stat_day
"""
# 主函数
if __name__ == '__main__':
# 执行SQL并读取结果
with odps.execute_sql(sql).open_reader() as reader:
df = reader.to_pandas() # 转换为Pandas DataFrame
#print(df)
# 转换为Markdown格式
markdown_table = df.to_markdown()
# 输出Markdown表格
print(markdown_table)
# 编辑需要推送的信息
title_content = keywords + ":数据量查看 \n"
text_content = "#### 库销比统计 \n 库销比统计近4天数据量(" + now_time + ") \n"
text_content += markdown_table + "\n"
text_content += "By Johnathan \n"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, text_content, title_content)
推送结果2(版本2)

参数说明
{
"msgtype": "markdown",
"markdown": {
"title":"百度百科",
"text": "#### 百度百科 \n 百度公司推出的网络百科全书 \n  \n [百度百科](https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E7%99%BE%E7%A7%91?fromModule=lemma_search-box) \n @15xxxxxx06"
},
"at": {
"atMobiles": [
"15xxxxxx06"
],
"atUserIds": [
"user123"
],
"isAtAll": false
}
}
| 参数 | 是否必填 | 类型 | 说明 |
|---|---|---|---|
| msgtype | 是 | String | markdown。 |
| markdown.title | 是 | String | 首屏会话透出的展示内容。 |
| markdown.text | 是 | String | Markdown格式的消息内容。 |
| at.atMobiles | 否 | Array | 被@人的手机号。消息内容text内要带上"@手机号",跟atMobiles参数结合使用,才有@效果。 |
| at.atUserIds | 否 | Array | 被@人的用户userid。 |
| at.isAtAll | 否 | Boolean | @所有人是true,否则为false。 |
| keywords | 是 | String | 钉钉机器人的关键词 |
目前只支持Markdown语法的子集,支持的元素如下:
标题
# 一级标题
## 二级标题
### 三级标题
#### 四级标题
##### 五级标题
###### 六级标题
引用
> A man who stands for nothing will fall for anything.
文字加粗、斜体
**bold**
*italic*
链接
[this is a link](https://www.dingtalk.com/)
图片

无序列表
- item1
- item2
有序列表
1. item1
2. item2
4- 整体跳转ActionCard类型
推送代码案例
import json
from datetime import datetime
import requests
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=**********'
keywords = 'DataWorks'
# 钉钉机器人,发送消息
def dd_robot(url:str, text_content: str, title_content: str, single_title: str, single_url: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "actionCard",
"actionCard": {
"title": title_content,
"text": text_content,
"singleTitle" : single_title,
"singleURL" : single_url
}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 主函数
if __name__ == '__main__':
# 编辑需要推送的信息
title_content = keywords + ": CASE WHEN用法 \n"
text_content = " \n "
text_content += "#### SQL中的 CASE WHEN用法详解 \n CASE WHEN 语句提供了一种在 SQL 查询中根据不同条件执行逻辑的灵活方法。它可用于简单的条件检查,也可用于复杂的逻辑操作。使用 CASE WHEN 可以使查询更具可读性,并且可以减少在应用程序代码中进行逻辑操作的需要。\n"
single_title = "阅读全文"
single_url = "https://blog.csdn.net/Taerge0110/article/details/136261423?spm=1001.2014.3001.5502"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, text_content, title_content, single_title, single_url)
推送结果

参数说明
{
"msgtype": "actionCard",
"actionCard": {
"title": "CASE WHEN用法",
"text": " \n #### SQL中的 CASE WHEN用法详解 \n CASE WHEN 语句提供了一种在 SQL 查询中根据不同条件执行逻辑的灵活方法。它可用于简单的条件检查,也可用于复杂的逻辑操作。使用 CASE WHEN 可以使查询更具可读性,并且可以减少在应用程序代码中进行逻辑操作的需要。\n",
"singleTitle" : "阅读全文",
"singleURL" : "https://blog.csdn.net/Taerge0110/article/details/136261423?spm=1001.2014.3001.5502"
}
}
| 参数 | 是否必填 | 类型 | 说明 |
|---|---|---|---|
| msgtype | 是 | String | actionCard。 |
| actionCard.title | 是 | String | 首屏会话透出的展示内容。 |
| actionCard.text | 是 | String | markdown格式的消息内容。 |
| actionCard.singleTitle | 是 | String | 单个按钮的标题。 |
| actionCard.singleURL | 是 | String | 单个按钮的跳转链接。 |
| keywords | 是 | String | 钉钉机器人的关键词 |
5- 推送文件链接供下载
推送背景
1. 需要推送的结果比较多, 不方便展示 ;
2. 推送结果需要保存下载 ;
3. 使用Markdown输出较长文档, 格式显示换行, 不适合观看, 转为图片展示 ;
推送代码案例1
说明: 基于DataWorks, 使用Python 查询数据库的数据, 将查询结果保存到OSS, 将OSS文件链接 通过钉钉机器人的方式推送到钉钉群里
import json
from datetime import datetime
import requests
from odps import ODPS
import pandas as pd
import oss2
from io import StringIO
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=*********'
keywords = 'DataWorks'
# 阿里云 OSS 配置
access_key_id = "your-access-key-id"
access_key_secret = "your-access-key-secret"
bucket_name = "your-bucket-name"
endpoint = "https://oss-cn-your-region.aliyuncs.com" # 替换为你的OSS区域
# 初始化 OSS 连接
auth = oss2.Auth(access_key_id, access_key_secret)
bucket = oss2.Bucket(auth, endpoint, bucket_name)
# 钉钉机器人,发送消息
def dd_robot(url:str, text_content: str, title_content: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "markdown",
"markdown": {
"title": title_content,
"text": text_content,
}
#这是配置需要@的人
#,"at": {"atMobiles": ["15xxxxxx06","18xxxxxx1"], "atUserIds": ["user123"], "isAtAll": False}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 执行SQL体
sql = """
SELECT platform_id, platform_name,
COUNT(1) AS ct
, SUM(wait_arrival_quantity) AS wait_arrival_quantity -- 1.采购中
, SUM(no_qc_quantity) AS no_qc_quantity -- 2.待质检
, SUM(doing_qc_quantity) AS doing_qc_quantity -- 3.质检
, SUM(inspected_quantity) AS inspected_quantity -- 已质检
, SUM(usable_quantity) AS usable_quantity -- 5.良品
, SUM(testing_quantity) AS testing_quantity -- 4.检测良品
, SUM(occupy_quantity) AS occupy_quantity -- 6.占用
, SUM(imperfect_quantity) AS imperfect_quantity -- 7.次品
, SUM(shipping_quantity) AS shipping_quantity -- 8.发货中
, SUM(allocation_quantity) AS allocation_quantity -- 9.调拨在途
, SUM(repair_quantity) AS repair_quantity -- 10.返修在途
, SUM(interception_quantity) AS interception_quantity -- 截留在途
FROM dws_wh_scm_inventory_details_df
WHERE pt = '20241212'
AND store_name IS NOT NULL
GROUP BY platform_id, platform_name
"""
# 主函数
if __name__ == '__main__':
# 执行SQL并读取结果
with odps.execute_sql(sql).open_reader() as reader:
df = reader.to_pandas() # 转换为Pandas DataFrame
#print(df)
# 将 DataFrame 转为 CSV 格式字符串
csv_buffer = StringIO()
df.to_csv(csv_buffer, index=False)
csv_data = csv_buffer.getvalue()
#print(csv_data)
# 上传文件到 OSS
oss_file_path = "data-test/***/scm_inventory.csv"
try:
bucket.put_object(oss_file_path, csv_data)
print(f"文件已成功上传到 OSS: {oss_file_path}")
except Exception as e:
print(f"文件上传失败: {e}")
# OSS 文件的对象键(路径)
object_key = oss_file_path
# 设置签名 URL 的有效期(单位:秒)
expire_seconds = 3600 # 1小时
# 生成临时访问链接
res_url = bucket.sign_url('GET', object_key, expire_seconds)
#print(f"OSS文件的访问地址(有效期{expire_seconds}秒):\n{url_1}")
# 编辑需要推送的信息
title_content = keywords + ":数据量查看 \n"
text_content = "#### 库存明细数据统计: \n "
text_content += " \n" # 文档内容可自定义
text_content += "[下载链接](" + res_url + ") \n"
text_content += "By Johnathan \n"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, text_content, title_content)
推送结果1



推送代码案例2
推送xlsx表格文件, 和统计值转成图片
'''PyODPS 3
请确保不要使用从 MaxCompute下载数据来处理。下载数据操作常包括Table/Instance的open_reader以及 DataFrame的to_pandas方法。
推荐使用 PyODPS DataFrame(从 MaxCompute 表创建)和MaxCompute SQL来处理数据。
更详细的内容可以参考:https://help.aliyun.com/document_detail/90481.html
'''
import json
from datetime import datetime
import requests
from odps import ODPS
import pandas as pd
import oss2
from io import StringIO
from io import BytesIO
from tabulate import tabulate
import matplotlib.pyplot as plt
from matplotlib import rcParams
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=******' #测试
keywords = 'DataWorks'
# 阿里云 OSS 配置
access_key_id = "your-access-key-id"
access_key_secret = "your-access-key-secret"
bucket_name = "your-bucket-name"
endpoint = "https://oss-cn-your-region.aliyuncs.com" # 替换为你的OSS区域
# 初始化 OSS 连接
auth = oss2.Auth(access_key_id, access_key_secret)
bucket = oss2.Bucket(auth, endpoint, bucket_name)
# 钉钉机器人,发送消息
def dd_robot(url:str, text_content: str, title_content: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "markdown",
"markdown": {
"title": title_content,
"text": text_content,
}
#这是配置需要@的人
#,"at": {"atMobiles": ["15xxxxxx06","18xxxxxx1"], "atUserIds": ["user123"], "isAtAll": False}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 渲染表格并上传到 OSS
def render_table_to_oss(df, oss_object_key):
# 确保索引包含在表格中(比如 "物流员")
#df = df.reset_index()
# 确保索引被重置,并只使用数据部分
df = df.reset_index(drop=True) # 去除索引
# 创建绘图
fig, ax = plt.subplots(figsize=(0.1, len(df) * 0.1 + 0.1))
ax.axis('off') # 隐藏坐标轴
ax.axis('tight')
# 渲染表格
table = ax.table(cellText=df.values,
colLabels=df.columns,
cellLoc='center',
loc='center')
table.auto_set_font_size(False)
table.set_fontsize(10)
table.auto_set_column_width(col=list(range(len(df.columns))))
# 保存到内存中的 BytesIO 对象
buffer = BytesIO()
plt.savefig(buffer, format='png', bbox_inches='tight', pad_inches=0.1)
plt.close(fig)
buffer.seek(0)
# 上传到 OSS
bucket.put_object(oss_object_key, buffer)
buffer.close()
print(f"Image successfully uploaded to OSS: {oss_object_key}")
# 生成结果表格并上传到 OSS
def res_table_to_oss(df, oss_file_path):
# 将 DataFrame 数据写入 Excel 文件内存对象
excel_buffer = BytesIO() # 使用内存作为存储
with pd.ExcelWriter(excel_buffer, engine='xlsxwriter') as writer:
df.to_excel(writer, index=False, sheet_name="Sheet1")
# 获取 Excel 数据的二进制内容
excel_data = excel_buffer.getvalue()
# 关闭缓冲区
excel_buffer.close()
try:
bucket.put_object(oss_file_path, excel_data)
print(f"文件已成功上传到 OSS: {oss_file_path}")
except Exception as e:
print(f"文件上传失败: {e}")
# 当天日期拼接
date = args['date']
to_day = args['date'] + ' 23:59:59'
print(date)
tbl_name = "puture_bigdata.dwd_shipt_scm_shipment_order_conf_validity_dt"
# 执行SQL体
sql = f"""
SET odps.sql.hive.compatible=TRUE ;
SELECT
NVL(inspector, '') AS name --`质检员`
, shipment_bill_id AS `货件单号`
, NVL(qc_bill_id, '') AS `质检单号`
, NVL(arrive_bill_id, '') AS `到货单号`
, shipment_order_status_name AS `状态名称`
, platform_name AS `平台名称`
, country AS `发往目的国`
, NVL(shipment_create_time, '') AS `货件单创建时间`
, NVL(estimate_take_time, '') AS `预计提货时间`
, NVL(take_time, '') AS `提货时间`
, NVL(qc_start_time, '') AS `质检开始时间`
, NVL(qc_time, '') AS `完成质检时间`
, NVL(arrive_time, '') AS `到货单确认到货时间`
, qc_delay_time AS `质检延期时长`
, NVL(cofn_base_time, '') AS `基准时间_质检点单`
, NVL(qc_validity, '') AS `质检点单时效`
, is_qc_delay AS `是否质检延期`
FROM {tbl_name}
WHERE pt = DATE_FORMAT('{date}', 'yyyyMMdd')
AND estimate_take_time <= '{to_day}'
AND shipment_order_status_name = '待提货'
AND iz_inspection = 0
"""
# 统计指标 逻辑SQL
sql_stat = f"""
SET odps.sql.hive.compatible=TRUE ;
SELECT
NVL(NVL(a.name, b.name), '-') AS name
, NVL(a.orders, '-') AS orders
, NVL(a.qc_delay_hours, '-') AS qc_delay_hours
, NVL(b.omit_orders, 0) AS omit_orders
FROM (
SELECT
inspector AS name
, COUNT(1) AS orders
, ROUND(SUM(qc_delay_time), 2) AS qc_delay_hours
FROM {tbl_name}
WHERE pt = DATE_FORMAT('{date}', 'yyyyMMdd')
AND estimate_take_time <= '{to_day}'
AND shipment_order_status_name = '待提货'
AND iz_inspection = 0
GROUP BY inspector
) a
FULL JOIN (
SELECT
inspector AS name
, COUNT(1) AS omit_orders
FROM {tbl_name}
WHERE pt = DATE_FORMAT('{date}', 'yyyyMMdd')
AND shipment_order_status_name = '待提货'
AND iz_inspection = 0
AND qc_delay_time > 0
GROUP BY inspector
) b
ON NVL(a.name, '-') = NVL(b.name, '-')
"""
# 主函数
if __name__ == '__main__':
# 执行SQL并读取结果
with odps.execute_sql(sql, hints={"odps.sql.submit.mode":"script"}).open_reader() as reader:
df = reader.to_pandas() # 转换为Pandas DataFrame
# print(df)
data_count = df.count().max()
print("数据条数: " + str(data_count))
if data_count > 0 :
print("执行推送程序!!!")
# 上传结果文件到 OSS
oss_file_path = "data-test/johnathan/qc_order_data/data/质检单据点击延迟数据明细_" + args['date'] + ".xlsx"
res_table_to_oss(df, oss_file_path)
# 设置签名 URL 的有效期(单位:秒)
expire_seconds = 24 * 3600 # 24小时
# 生成带自定义文件名的访问链接
custom_filename = "质检单据点击延迟明细_" + args['date'] + ".xlsx"
params = {'response-content-disposition': f'attachment;filename="{custom_filename}"'}
res_url = bucket.sign_url('GET', oss_file_path, expire_seconds, params=params)
# 执行统计SQL并将结果转成图片存储
with odps.execute_sql(sql_stat, hints={"odps.sql.submit.mode":"script"}).open_reader() as reader:
stat_res = reader.to_pandas() # 转换为Pandas DataFrame
# 设置 OSS 路径, 将图片写入OSS
oss_object_key = "data-test/johnathan/qc_order_data/photo/质检单据点击延迟数据统计_" + args['date'] + ".png"
render_table_to_oss(stat_res, oss_object_key)
#获取图片链接
photo_url = bucket.sign_url('GET', oss_object_key, 60*24*3600)
# 编辑需要推送的信息
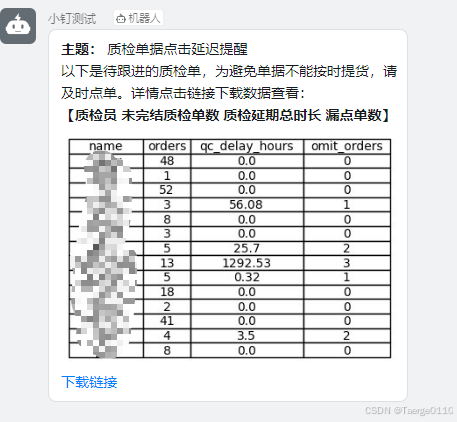
title_content = keywords + "质检单据点击延迟提醒"
text_content = "**主题:** 质检单据点击延迟提醒 \n"
text_content += "\n 以下是待跟进的质检单,为避免单据不能按时提货,请及时点单。详情点击链接下载数据查看: \n "
text_content += "\n 【**质检员** **未完结质检单数** **质检延期总时长** **漏点单数**】 \n"
text_content += " \n "
text_content += "\n" + "[下载链接](" + res_url + ") \n"
# 调用推送函数, 推送消息到钉钉群
dd_robot(url, text_content, title_content)
else :
print("无延迟情况发生;")
推送结果2
结语:
持续更新
欢迎交流

















 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









