



什么是GRU?为什么要学习GRU?
GRU也是也可处理序列数据的一种模型,是循环神经网络的一种,同时呢它也是LSTM的一种变体,然后为什么要学习它,是因为我们了解了LSTM后发现他有很多可以精简改进的地方,例如说它复杂的模型结构,因此GRU就诞生了。相比较LSTM内部结构进行了简化,同时准确率也得到了提升。
为什么说GPU比LSTM更加的精简?
首先我们知道LSTM总共有三个门,遗忘门,输入门,输出门,而我们的GRU中呢使用的是两个门,重置门和更新门。
结构如图:

GRU和LSTM的区别:
- LSTM有三个门,而GRU有两个门
- 去掉了细胞单元C
- 输出的时候取消了二阶的非线性函数
两个门的理解:
重置门:
作用对象是前边的隐藏状态
作用呢就是决定了有多少过去信息需要遗忘
更新门:(可以理解为LSTM中的遗忘门和输入门相结合)
作用对象是当前时刻和上一时刻的隐藏单元
作用就是上一时刻,以及当前时刻总共有多少有用的信息需要接着向下传递
前向传播: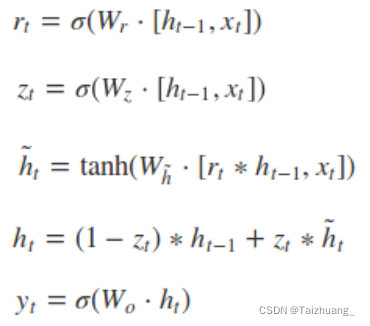
重点:我们来理解一下sigmoid和(1-sigmoid)
大家想一下我们更新门的作用和意义是什么,是不是就是为了将上一时刻和当前时刻总共有多少有用的信息需要接着往下传递呀,我们更新门的输入数据是什么是不是就是ht-1和xt,那么我们假设上一时刻有用的信息是0.2,那么我本时刻传递的时候是不是就传递1-0.2=0.8的有用信息啦,一般情况下极端值比较好理解,我们假设说上一时刻传递的信息都没有用,那么也就是说我的上一时刻的信息是不是不需要继续往下传递了呀,所以他的sigmoid输出是不是就成了0啦,然后我当前时刻有用的信息是不是要接着往下传啦,传递多少呢,1-0=1,是不是代表的意思就是说,我上一时刻的所有信息都没有用,全部抛弃啦,然后我是不是就相当于在当前时刻又重新开始记忆啦,那么我当前时刻就是我要重新记忆的开始,所以我要全记住接着往下传递,就好像我在第一时刻和第二时刻一样,我第二时刻传递进来的上一时刻的信息不就是第一时刻所有的信息吗。
引入一个图片介绍:
LSTM和GRU的对比:
都通过了门去保留重要的特征
准确率不相上下
但是GRU更快因为它拥有更少的参数,少了一个门就少了很多的矩阵的乘法,在数据上训练的时候GRU就能节省下来很多的时间。

















 3325
3325




 到【灌水乐园】发言
到【灌水乐园】发言







