







 本文介绍了一款名为AskYourPDF的插件,用于从PDF文档中快速提取信息,配合GPT4.0账号使用,通过上传文件并生成ID,方便整理和检索。
本文介绍了一款名为AskYourPDF的插件,用于从PDF文档中快速提取信息,配合GPT4.0账号使用,通过上传文件并生成ID,方便整理和检索。
使用插件AskYourPDF
简介
AskYourPdf 是一款设计用来从PDF文档中快速提取信息的插件,可以用来整理分析、检索论文、会议记录等,对阅读PDF格式的文档非常有用。Ask Your PDF 官网
怎么去使用呢
首先得先有一个GPT4.0的账号,请参考我上篇文章,并且开通ChatGPT4.0;
步骤一
进入插件模式,安装下面插件
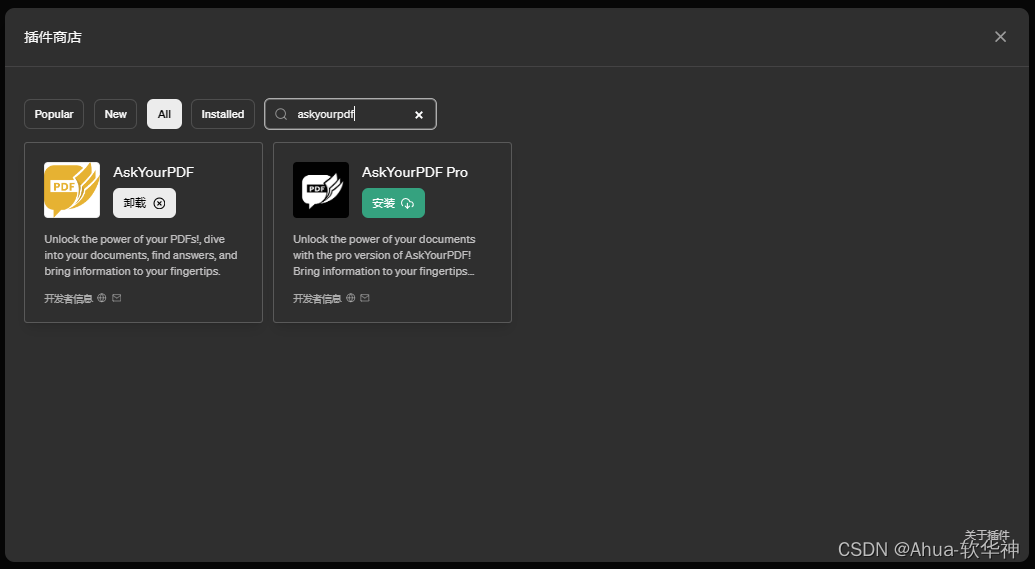
步骤二
输入:请帮我生成一个上传PDF文件的链接,点击【upload】
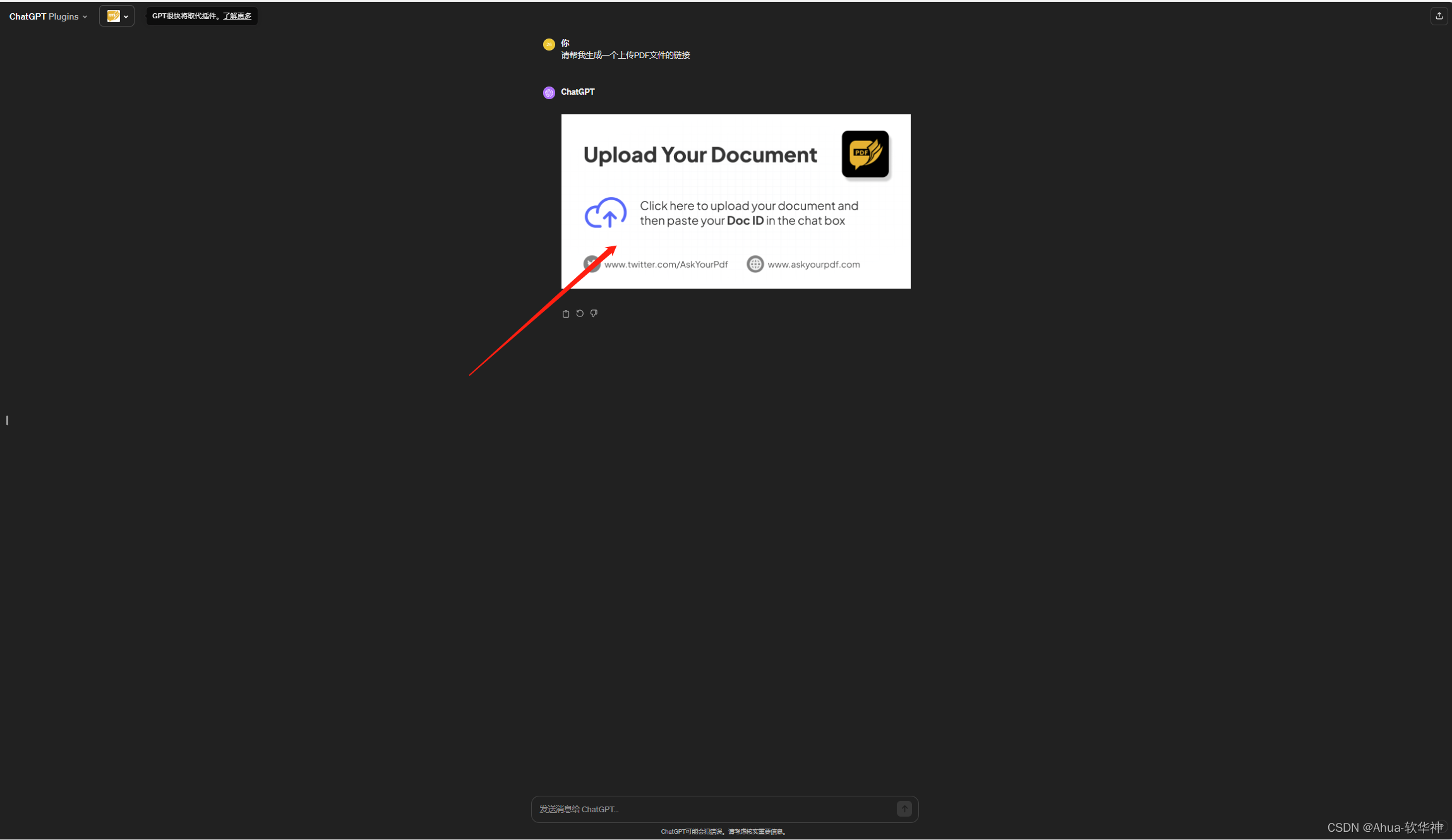
步骤三
第一次进去需要登录邮箱,正常登录即可,使用账户邮箱或者谷歌邮箱;
接下来就上传需要上传的文件
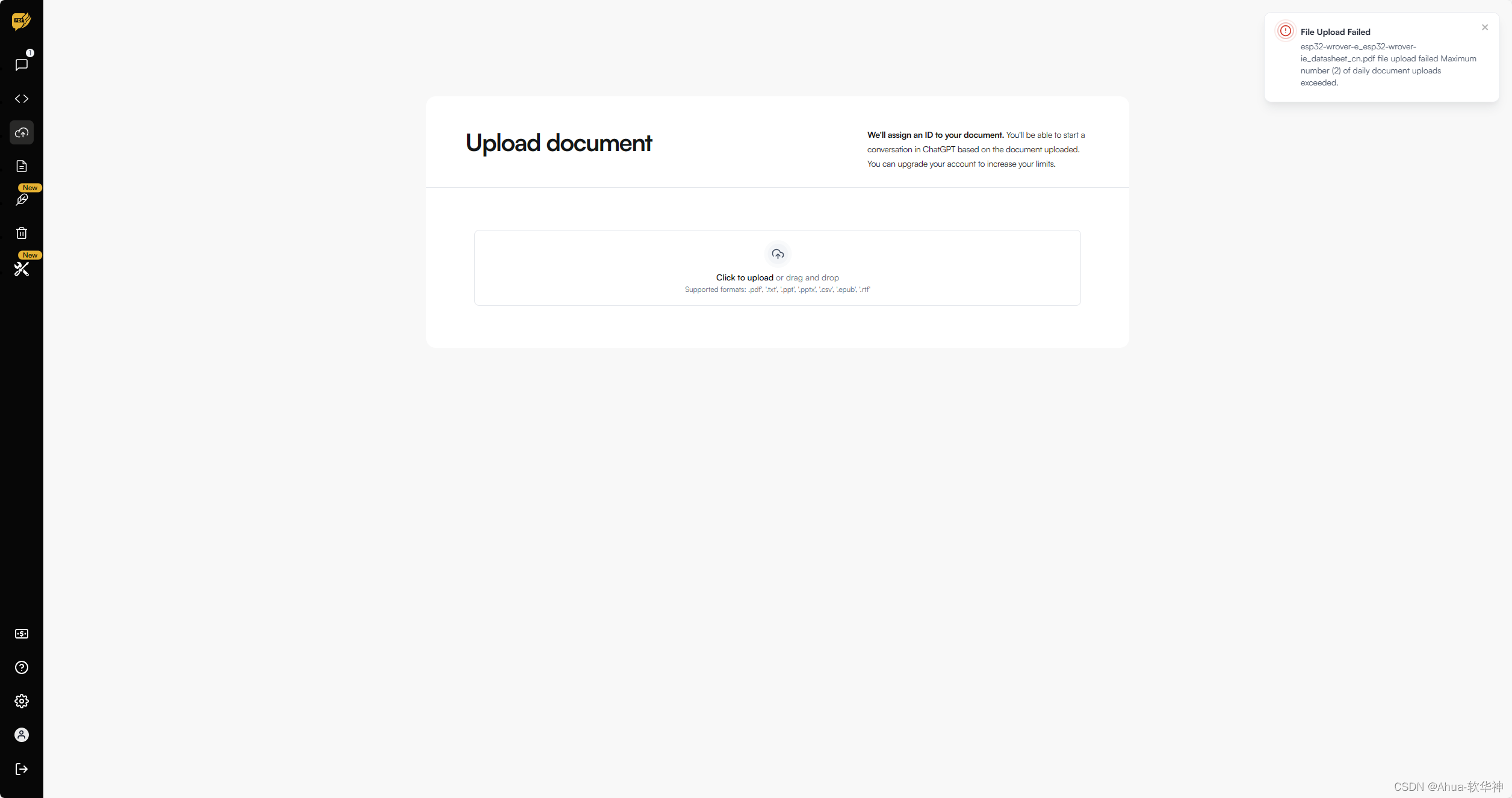
步骤三
上传成功后,如下图会生成一个ID,复制ID
这里我上传一个机械臂平台的官方开发文档
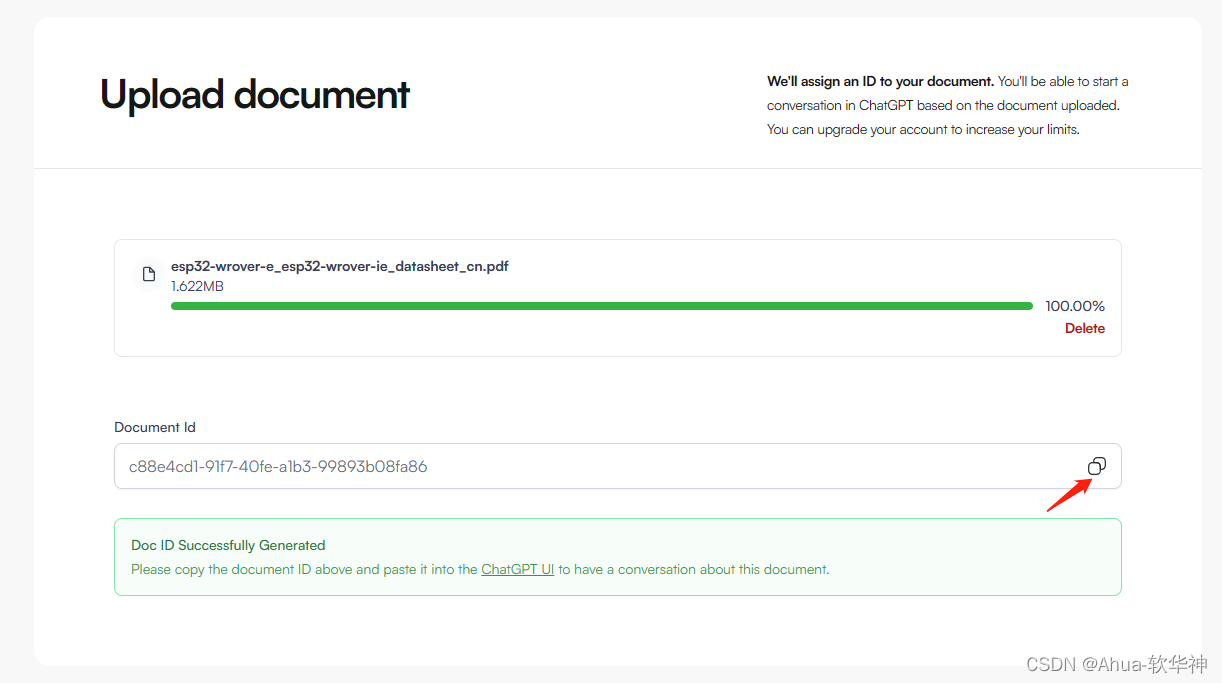
步骤四
它推荐使用GPTs中一个官方助手的新版本,你们也可以去尝试一下


















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











