







机器学习(5)之牛顿算法
1. 牛顿迭代算法简介

牛顿方法应用于机器学习:
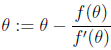
1. 使用这个方法需要f满足一定条件,适用于Logistic回归和广义线性模型
2. 一般初始化为0
2. 在Logistic的应用
在Logistic回归中,我们要使得对数最大似然值最大,即求
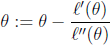
牛顿方法的收敛速度:二次收敛
每次迭代使解的有效数字的数目加倍:假设当前误差是0.01,一次迭代后,误差为0.001,再一次迭代,误差为0.0000001。该性质当解距离最优质的足够近才会发现。
3. 牛顿方法的一般化
Θ是一个向量而不是一个数字,一般化的公式为:
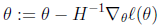
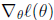
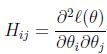
上述公式的意义就是,用一个一阶导数的向量乘以一个二阶导数矩阵的逆
优点:若特征数和样本数合理,牛顿方法的迭代次数比梯度上升要少得多
缺点:每次迭代都要重新计算Hessian矩阵,如果特征很多,则H矩阵计算代价很大















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









