







本系列文章包含每平每屋过去一年在召回、排序和冷启动等模块中的一些探索和实践经验,本文为该专题的第四篇。
第一篇指路:冷启动系统优化与内容潜力预估实践
第二篇指路:GNN在轻应用内容推荐中的召回实践
第三篇指路:基于特征全埋点的精排ODL实践总结
前言
在每平每屋以及我们团队负责的其他一些场景,MMoE多任务模型是精排阶段常用的模型。在每平每屋场景中,我们使用MMoE模型,对场景中的三个任务同时进行点击率预估,即内容的一跳点击、内容详情页点击以及跳转的商品详情页点击。MMoE结构有别于简单的Hard Parameter Sharing的方式,可以通过模型去学习不同任务之间哪些参数共享(Experts),共享的程度如何(Gates)
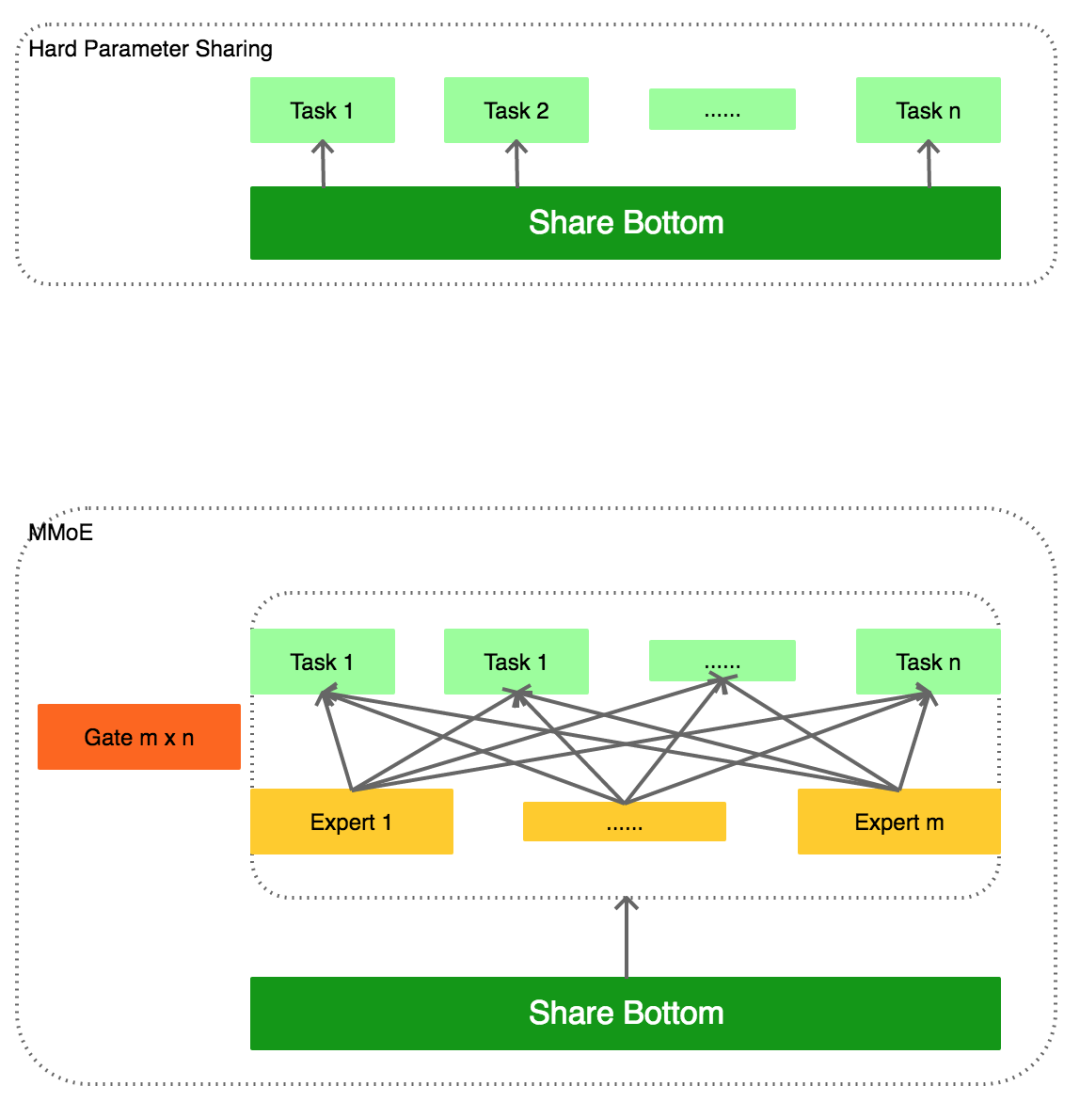
建模
MMoE是从Model Structure的角度来对共享参数做精细化控制,并在很多场景都取得了提升。除了Model Structure之外,我们还可以从Model Dynamics的角度去考虑优化。由于不同任务之间天然存在着数据量、样本分布、难易程度的差别,导致在训练过程中,收敛速度、收敛结果都会存在不小的差异。Model Dynamics希望在模型训练过程中去动态调整训练的速度等变量。
建模
Model Dynamics的优化,一般通过loss函数来实现。常见的多任务模型loss,可以简单对多个任务的loss相加得到,如下所示
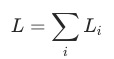
这种方式的不合理之处是显然的,训练的loss很容易被一些loss特别大的任务所主导,导致最终的优化未能取得预期的效果。一个简单的优化是基于人工经验,对多个任务的loss分别赋予一个固定权重,但是这个权重在整个训练周期中是固定的,并没有考虑到不同的训练阶段,权重可能变化的情况。
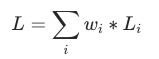
一个更合理的加权方式,应该是动态的,这里我们对权重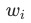 通过2个参数来控制,
通过2个参数来控制,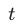 为训练的steps数,
为训练的steps数,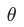 为其他可能的参数。接下来的介绍我们都是基于这个框架展开,演示一些实际的实现方式
为其他可能的参数。接下来的介绍我们都是基于这个框架展开,演示一些实际的实现方式
▐ Dynamic Weight Averaging
DWA发表于CVPR 2019的论文《End-to-End Multi-Task Learning with Attention》,核心公式如下所示
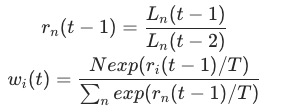
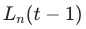 表示任务
表示任务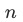 在
在 步时的训练loss,
步时的训练loss,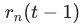 表示此时的loss下降速度,
表示此时的loss下降速度,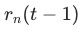 越小,训练速度越快
越小,训练速度越快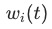 代表不同任务loss的权重,
代表不同任务loss的权重,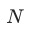 为任务的数量,
为任务的数量,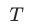 为一个temperature参数,
为一个temperature参数,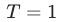 时,
时,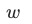 为softmax,
为softmax,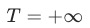 时,
时,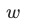 为1。直观的结果来看,loss收敛越快的任务,获得的权重越小
为1。直观的结果来看,loss收敛越快的任务,获得的权重越小
▐ Dynamic Task Prioritization
DTP发表于ECCV 2018的论文《Dynamic task prioritization for multitask learning》,核心公式如下所示
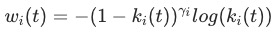
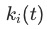 表示在
表示在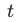 步时的某衡量KPI值,取值为[0, 1] 之间,例如在分类任务里,KPI可以是分类的准确率。
步时的某衡量KPI值,取值为[0, 1] 之间,例如在分类任务里,KPI可以是分类的准确率。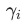 是一个固定的temperature参数,可用于人工调节
是一个固定的temperature参数,可用于人工调节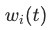 代表不同任务loss的权重。直观的结果来看,KPI越高的任务,获得的权重越小
代表不同任务loss的权重。直观的结果来看,KPI越高的任务,获得的权重越小
▐ Gradient Normalization
GradNorm发表于ICML 2018的论文《Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks》,其核心思想相对前述的DWA和DTP更为复杂,核心观点为
不仅考虑loss收敛的速度,进一步希望loss本身的量级能尽量接近
不同的任务以相近的速度训练(与gradient相关)
我们同样还是从 这个公式出发,作者定义了两个loss,一个是常规的标签loss,即
这个公式出发,作者定义了两个loss,一个是常规的标签loss,即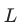 ,另一个loss为gradient loss,是一个和权重
,另一个loss为gradient loss,是一个和权重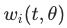 相关的loss
相关的loss
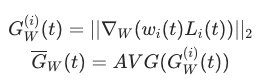
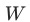 为模型参数的子集,也是我们要应用Gradient Normalization的参数集,在论文中作者选择的是模型中共享参数的最后一层。
为模型参数的子集,也是我们要应用Gradient Normalization的参数集,在论文中作者选择的是模型中共享参数的最后一层。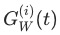 为
为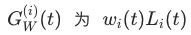
对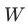 求导后的 gradient的 L2范式,主要用来表征loss的量级。 为全部
求导后的 gradient的 L2范式,主要用来表征loss的量级。 为全部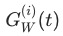 的均值
的均值
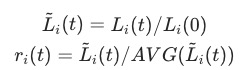
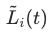 用于衡量任务训练的反向速度,
用于衡量任务训练的反向速度,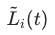 越大,表明任务训练越慢,这点和DWA的思想接近,但是这里使用的是第一步的loss,而不是DWA中的前一步loss。
越大,表明任务训练越慢,这点和DWA的思想接近,但是这里使用的是第一步的loss,而不是DWA中的前一步loss。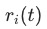 用于衡量任务训练的相对反向速度,
用于衡量任务训练的相对反向速度,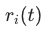 越大,表明任务相对所有任务而言训练较慢。最终我们得到的gradient loss
越大,表明任务相对所有任务而言训练较慢。最终我们得到的gradient loss
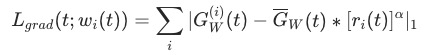
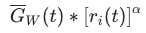 表示理想的梯度标准化后的值。这里的gradient loss只用于更新
表示理想的梯度标准化后的值。这里的gradient loss只用于更新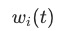 。
。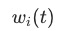 还会经过最终的renormalize,使得
还会经过最终的renormalize,使得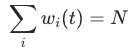 ,
,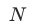 为任务的数量。从gradient loss的定义来看,
为任务的数量。从gradient loss的定义来看,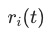 越大,表明任务训练越快,gradient loss 越大;
越大,表明任务训练越快,gradient loss 越大;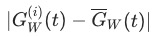 表征loss 量级的变化,不论
表征loss 量级的变化,不论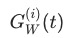 过大或者过小都会导致gradient loss 变大。
过大或者过小都会导致gradient loss 变大。
GradNorm实践
我们实现的代码部分主要参考了 https://github.com/vpetren/gradnorm_tf/blob/master/gradnorm_tf.py 的开源部分。实验场景为每平每屋轻应用。我们首先实现了一版基于作者原始论文中描述的版本,但是发现这一版本的效果不佳,gradient loss的收敛较差且波动大。其主要原因在于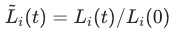 中
中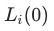 为训练的第一步loss,在推荐系统的训练中,单个batch的训练loss相对来说比较不稳定,导致
为训练的第一步loss,在推荐系统的训练中,单个batch的训练loss相对来说比较不稳定,导致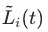 的计算不置信。我们同样也验证了
的计算不置信。我们同样也验证了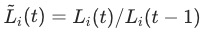 的计算方式在我们的场景中也效果不佳。最终我们选用了
的计算方式在我们的场景中也效果不佳。最终我们选用了
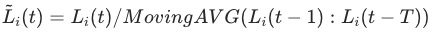
分母设置为 到
到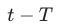 之间的
之间的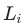 的 Moving Average
的 Moving Average
▐ 离线对比
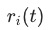 : inv_training_rate对比
: inv_training_rate对比
type | ctr inv_training_rate | cvr inv_training_rate | fav inv_training_rate |
train gradient loss | 2 ~ 2.3 | 0.6 | 0.05 |
no train gradient loss | 1.4 ~ 2 | 1.2 | 0.16 |
可以看到,增加了gradient loss之后,ctr任务的训练速度在相对变慢,cvr和fav两个任务的训练速度相对变快
 的变化趋势
的变化趋势
auc结果波动性
我们对同样的模型参数组,连续训练三次,计算每次结果三个任务auc的均值和方差,我们可以发现,在不使用gn的基准组,一跳点击、二跳点击、商详点击的预估auc方差逐次增大,这也表明二跳点击和商详点击的预估任务,在相同训练参数下波动较大,表明任务训练的结果不好,这对于线上结果显然是有害的。而在使用了gn的实验组,auc的方差都保持在相对较低的水平,表明这几个任务的训练结果应当是稳定的。
type | click auc | detail auc | fav auc |
baseline | 0.6720 ± 0.0013 | 0.6886 ± 0.0057 | 0.6915 ± 0.0095 |
baseline + gn | 0.6828 ± 0.0023 | 0.7078 ± 0.0014 | 0.7155 ± 0.0012 |
baseline 平均波动:0.0055
baseline + gn 平均波动:0.0016
整体训练波动被大幅缩小,尤其是在正样本比较稀疏的 detail 任务和 fav 任务上,此外加入gn之后整体auc有明显的提升。
▐ 线上AB
线上ab结果,pctcvr +3.49%,avg_ipv +4.04%
ab_name | uctr_improv | pctr_improv | avg_expo_improv | avg_click_improv | ipv_uctr_improv | ipv_pctr_improv | uctcvr_improv | pctcvr_improv | avg_ipv_improv |
GradNorm | 2.25% | 4.59% | 0.51% | 5.13% | -0.19% | -1.05% | 2.06% | 3.49% | 4.04% |
Baseline AA | 0.00% | -0.15% | 0.43% | 0.27% | 0.03% | 0.02% | 0.03% | -0.13% | 0.26% |
Baseline | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
总结
在实际推荐、搜索场景中,我们所优化的业务目标往往并不单一,使用多任务、多目标模型在目前业界比较常见。不同于MMoE、PLE等Model Structure优化,我们从Model Dynamic的角度出发,人为定义一系列"好的"Model Dynamic标准,并在建模中应用,取得了在MMoE基础上的进一步提升。两类优化具有互补性,在实际使用中可以同时应用。
团队介绍
*本项工作是本组实习生知同在职时合作完成。
淘系技术部-淘宝智能团队
淘宝智能团队是一支数据和算法一体的团队,服务于淘宝、天猫、聚划算、闲鱼和每平每屋等业务线的二十余个业务场景,提供线上零售、内容社区、3D智能设计和端上智能等数据和算法服务。我们通过机器学习、强化学习、数据挖掘、机器视觉、NLP、运筹学、3D算法、搜索和推荐算法,为千万商家寻找商机,为平台运营提供智能化方案,为用户提高使用体验,为设计师提供自动搭配和布局,从而促进平台和生态的供给繁荣和用户增长,不断拓展商业边界。
这是一支快速成长中的学习型团队。在创造业务价值的同时,我们不断输出学术成果,在KDD、ICCV、Management Science等国际会议和杂志上发表数篇学术论文。团队学习氛围浓厚,每年组织上百场技术分享交流,互相学习和启发。真诚邀请海内外相关方向的优秀人才加入我们。如果您有兴趣可将简历发至bangzhu.gx@alibaba-inc.com,期待您的加入!
参考文献
[1] 多任务学习优化(Optimization in Multi-task learning) https://zhuanlan.zhihu.com/p/269492239
[2] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts, KDD 2018 https://dl.acm.org/doi/10.1145/3219819.3220007
[3] End-to-End Multi-Task Learning with Attention, CVPR 2019 https://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_End-To-End_Multi-Task_Learning_With_Attention_CVPR_2019_paper.pdf
[4] Dynamic task prioritization for multitask learning, ECCV 2018 https://openaccess.thecvf.com/content_ECCV_2018/papers/Michelle_Guo_Focus_on_the_ECCV_2018_paper.pdf
[5] GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks, ICML 2018 http://proceedings.mlr.press/v80/chen18a/chen18a.pdf
✿ 拓展阅读

作者|邦祝
编辑|橙子君
出品|阿里巴巴新零售淘系技术


















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









