







近年来,随着以OpenAI的ChatGPT和Meta的LLaMA为代表的基于数百万网页数据训练的大型Transformer语言模型的兴起,开放域语言生成领域吸引了越来越多的关注。开放域中的条件语言生成效果令人印象深刻,典型的例子有:GPT2在独角兽话题上的精彩续写和XLNet等。促成这些进展的除了transformer架构的改进和大规模无监督训练数据外,更好的采样策略也发挥了不可或缺的作用。
本文简述了不同的采样策略,同时向读者展示了如何使用流行的transformer库轻松实现这些采样策略!

LLM输出概率分布
许多大型语言模型具有推理时(inference-time)参数,用于控制输出的“随机性”。这些参数通常是贪心搜索(Greedy search), 波束搜索(Beam search), Top-K采样(Top-K sampling), Top-p采样(Top-p sampling), 温度(Temperature)。
LLM 通常对一系列tokens进行操作,这些tokens可以是词、字符、子词(words, letters, or sub-word units)。(例如,OpenAI GPT LLM在子词单元进行tokenize,其中 100 个tokens平均为 75 个单词)这些tokens集合被称为LLM 的词汇表。
LLM 接受输入的tokens序列,然后尝试预测下一个token。它通过使用softmax函数作为网络的最后一层,在所有可能的tokens上生成离散概率分布来实现这一点。这是LLM的原始输出。
由于这是概率分布,因此所有值的总和将为1。一旦有了这个概率分布,就可以决定如何从中采样,这就是采样策略的用武之地。
贪心搜索贪心搜索在每个时间步都简单地选择概率最高的词作为当前输出词: wt=argmaxwP(w∣w1:t−1) ,如下图所示。
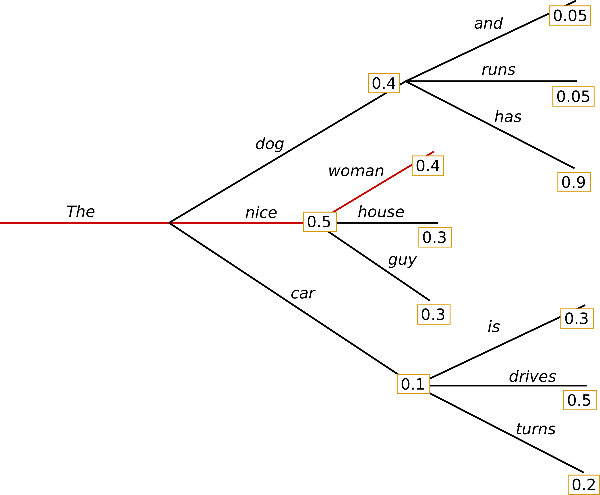
从单词{“The”}开始,算法在第一步贪心地选择条件概率最高的词{“nice”}作为输出,依此往后。最终生成的单词序列为({“The”}, {“nice”},{“woman”}),其联合概率为0.5 * 0.4 = 0.2。
下面,输入文本序列({“I”}, {“enjoy”}, {“walking”}, {“with”}, {“my”}, {“cute”},{“dog”})给 GPT2 模型,让模型生成下文。以此为例看看如何在 transformers 中使用贪心搜索:
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2",pad_token_id=tokenizer.eos_token_id)# encode context the generation is conditioned on
model_inputs = tokenizer('I enjoy walking with my cute dog', return_tensors='pt').to(torch_device)
# generate 40 new tokens
greedy_output = model.generate(**model_inputs, max_new_tokens=40)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll根据上文生成的单词是合理的,但模型很快开始输出重复的文本!这在语言生成中是一个非常普遍的问题,在贪心搜索和波束搜索中更容易出现。
贪心搜索的主要缺点是它错过了隐藏在低概率词后面的高概率词,如上图所示:
条件概率为0.9的单词{“has”}隐藏在单词{“dog”}后面,而{“dog”}因为在 t=1 时条件概率值只排第二所以未被选择,因此贪心搜索会错过序列{“The”}, {“dog”}, {“has”}。
这种问题可以用波束搜索来缓解!

波束搜索
波束搜索通过在每个时间步保留最可能的num_beams个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。以num_beams=2为例:
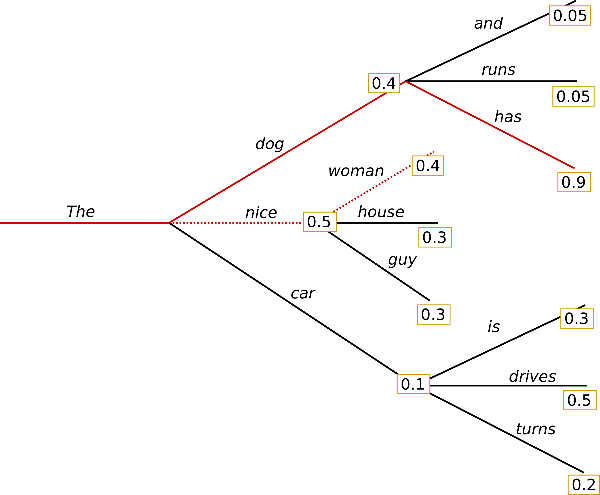
在时间步 1,除了最有可能的假设({“The”}, {“nice”}),波束搜索还跟踪第二可能的假设 ({“The”}, {“dog”})。在时间步 2,波束搜索发现序列 ({“The”}, {“dog”}, {“has”}) 概率为0.36,比 ({“The”}, {“nice”}, {“woman”}) 的 0.2 更高。
波束搜索一般都会找到比贪心搜索概率更高的输出序列,但仍不保证找到全局最优解。
下面展示如何在 transformers 中使用波束搜索。设置 num_beams > 1 和 early_stopping=True 以便在所有波束达到EOS(End of Sentence)时直接结束生成。
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll虽然结果比贪心搜索更流畅,但输出中仍然包含重复。一个简单的补救措施是引入 n-grams (即连续 n 个词的词序列) 惩罚。最常见的 n-grams 惩罚是确保每个 n-gram 都只出现一次,方法是如果看到当前候选词与其上文所组成的 n-gram 已经出现过了,就将该候选词的概率设置为 0。
可以通过设置 no_repeat_ngram_size=2 来试试,这样任意 2-gram 不会出现两次:
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break可以看到生成的文本已经没有重复了。但是n-gram 惩罚使用时必须谨慎,如有一篇关于某个城市的文章就不应使用 2-gram 惩罚,否则这个城市名称在整个文本中将只出现一次!
波束搜索的另一个重要特性是能够比较概率最高的几个波束,并选择最符合要求的波束作为最终生成文本。
在 transformers 中,只需将参数 num_return_sequences 设置为需返回的概率最高的波束的数量,需要确保 num_return_sequences <= num_beams!
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to get back to
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to take a break
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to get back to
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
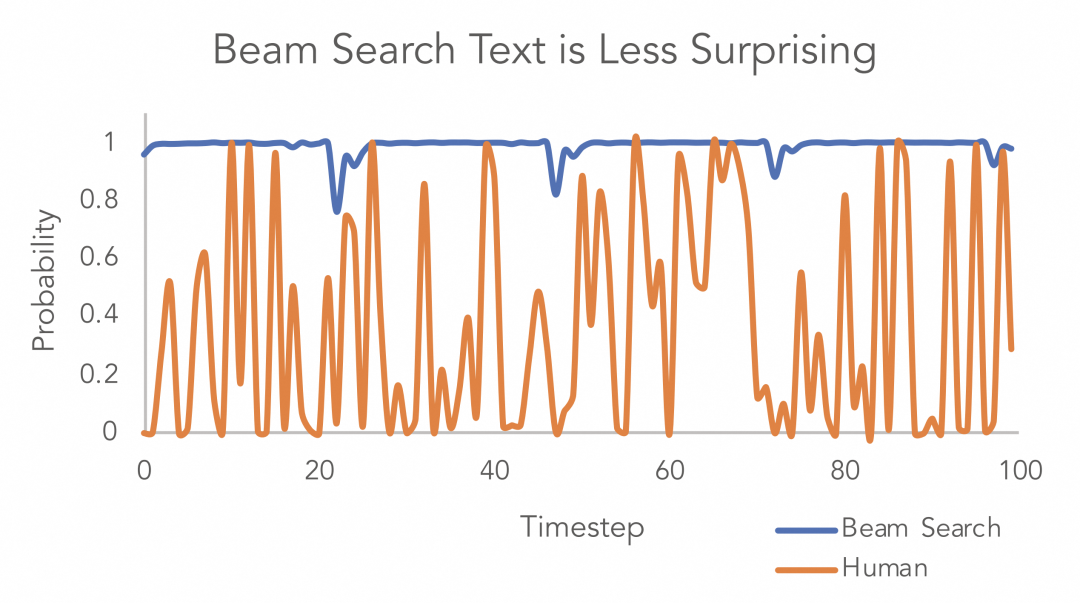
I've been thinking about this for a while now, and I think it's time for me to take a step如上所示,五个波束彼此之间仅有少量差别,由此可见波束搜索可能并不是最佳方案。Ari Holtzman等人在“The Curious Case of Neural Text Degeneration”中的观点表明:高质量的人类语言并不遵循最大概率法则。如下图所示论文作者画了一个概率图,很好地展示了这一点,从图中可以看出人类文本带来的惊喜度比波束搜索高。

Top-K采样
在 Top-K 采样中,概率最大的 K 个词会被选出,然后这 K 个词的概率会被重新归一化,最后就在这重新被归一化概率后的 K 个词中采样。GPT2 采用了这种采样方案,这也是它在故事生成这样的任务上取得成功的原因之一。
将上文例子中的候选单词数从 3 个单词扩展到 10 个单词,以更好地说明 Top-K 采样。
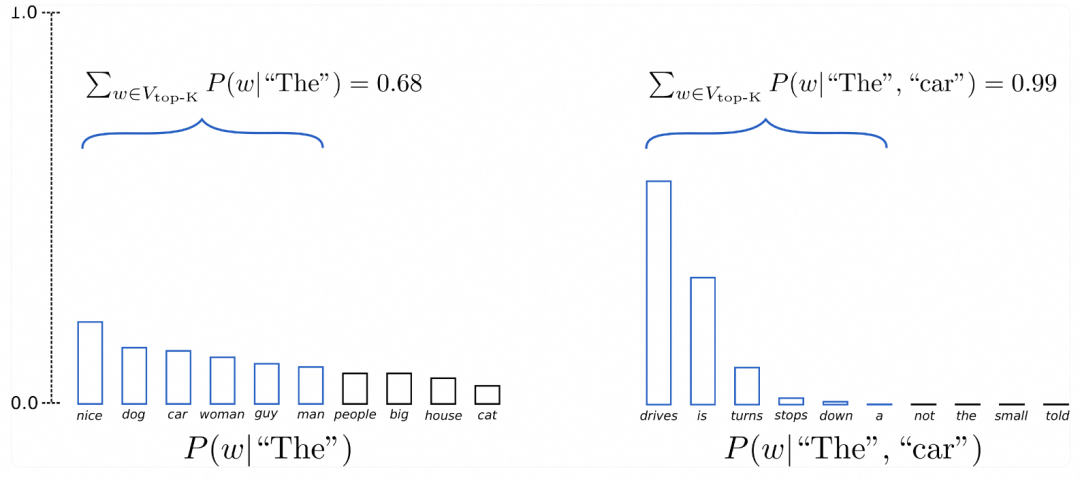
设K = 6,即将在两个采样步的采样池大小限制为 6 个单词。定义 6 个最有可能的词的集合为V_top-K。在第一步中,V_top-K仅占总概率的大约三分之二,但在第二步,它几乎占了全部的概率。可以看到在第二步该方法成功地消除了那些奇怪的候选词({“not”}, {“the”}, {“small”}, {“told”})。
下面以设置 top_k=50 为例看如何在 transformers 库中使用Top-K:
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# set top_k to 50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. It's so good to have an environment where your dog is available to share with you and we'll be taking care of you.
We hope you'll find this story interesting!
I am from该文本是上述中最"像人"的文本。但还有一个问题,Top-K采样不会动态调整从需要概率分布中选出的单词数。这可能会有问题,因为某些分布可能是非常尖锐 (上图中右侧的分布),而另一些可能更平坦 (上图中左侧的分布),所以对不同的分布使用同一个绝对数 K 可能并不普适。
在 t=1 时,Top-K 将 ({“people”}, {“big”}, {“house”}, {“cat”}) 排出了采样池,而这些词似乎是合理的候选词。另一方面,在t=2 时,该方法却又把不太合适的 ({“down”}, {“a”}) 纳入了采样池。因此,将采样池限制为固定大小 K 可能会在分布比较尖锐的时候产生胡言乱语,而在分布比较平坦的时候限制模型的创造力。

Top-P采样
在 Top-p 中,采样不只是在最有可能的 K 个单词中进行,而是在累积概率超过概率 p 的最小单词集中进行。然后在这组词中重新分配概率质量。这样,词集的大小 (又名集合中的词数) 可以根据下一个词的概率分布动态增加和减少。
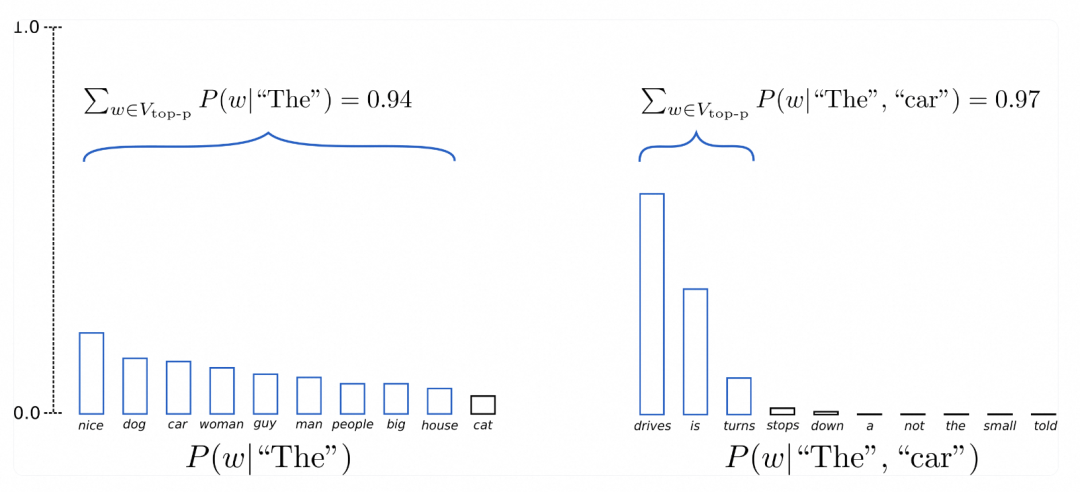
假设 p=0.92,Top-p 采样对单词概率进行降序排列并累加,然后选择概率和首次超过 p=92% 的单词集作为采样池,定义为 V_top-p。在 t=1 时 V_top-p有 9 个词,而在 t=2 时它只需要选择前 3 个词就超过了 92%。可以看出,在单词比较不可预测时,它保留了更多的候选词,如 P(w | {“The”}),而当单词似乎更容易预测时,只保留了几个候选词,如 P(w | {“The”}, {“car”})。
可以通过设置 0 < top-p < 1 来激活 Top-p 采样:
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He will never be the same. I watch him play.
Guys, my dog needs a name. Especially if he is found with wings.
What was that? I had a lot o从理论上讲, Top-p 似乎比 Top-K 更优雅,但这两种方法在实践中都很有效。Top-p 也可以与 Top-K 结合使用,这样可以避免排名非常低的词,同时允许进行一些动态选择。

温度
温度会影响模型输出的“随机”程度,并且与上述参数的原理不同。不同于直接对输出概率进行操作,温度是影响softmax函数本身,softmax函数工作原理如下。
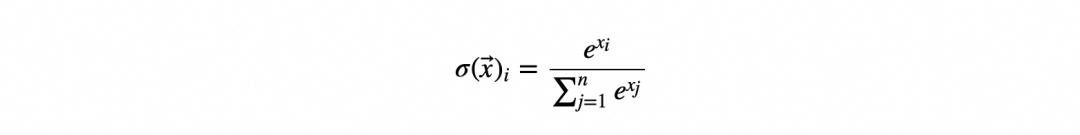
该函数应用于输入向量中的每个元素 产生相应的输出向量。即:
产生相应的输出向量。即:
-
指数函数应用于元素 xi
然后将结果值通过所有元素的指数总和进行归一化xj,这确保了结果值的总和为1,使输出向量成为概率分布
这就是所操作的 token 概率分布的方式。模型中倒数第二层的维度与词汇表中token数量相同,但输出向量 表示不能解释为概率分布的原始预激活值。Softmax 将其转换为最后一层所有可能tokens的概率分布。
表示不能解释为概率分布的原始预激活值。Softmax 将其转换为最后一层所有可能tokens的概率分布。
除了将输出转换为概率分布之外,softmax 还改变每个元素之间的相对差异。softmax函数的效果取决于输入元素的范围,
如果被比较的两个输入元素都是小于1,那么它们之间的差异就会减少。
如果被比较的两个元素中有一个是大于1,那么他们之间的差异就会被放大。这可以使模型对预测更加“确定”。
下面是标准 softmax 函数的输入和输出值,看相对差异是如何改变的。当输入值小于1,输出值的相对差异减少:
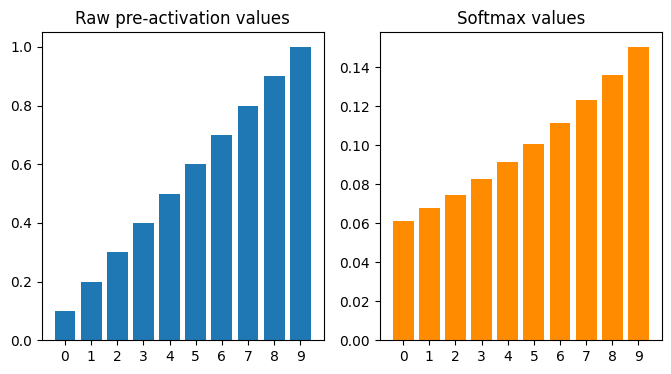
输入小于 1 时的 Softmax 变换
当某些输入值大于1,它们之间的差异在输出值中被放大:
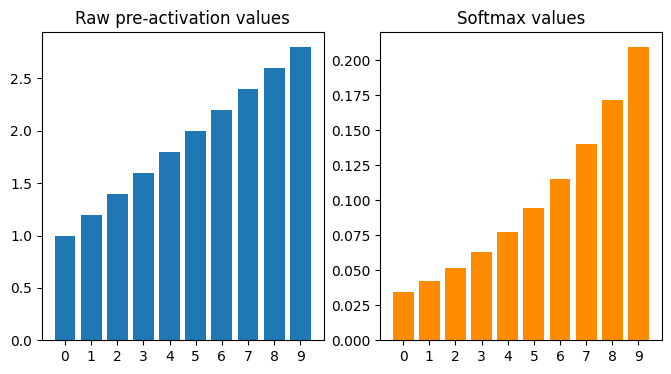
当某些输入大于 1 时的 Softmax 变换
输出值的减少或放大会影响模型预测的“确定性”程度。如何才能控制softmax输出的概率分布中的这种“确定性”呢?这就是温度参数的用处。用以下形式的“缩放”softmax 函数:
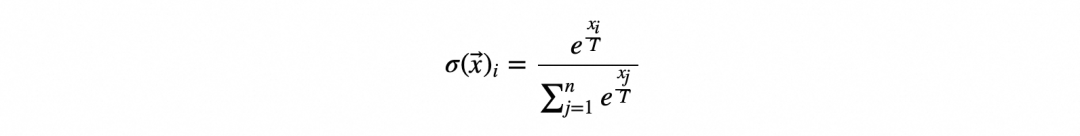
跟标准softmax 函数的唯一区别是逆缩放参数1/T,应用于指数函数,其中T被定义为温度。温度对输出的影响如下:
如果0 < T< 1,那么输入值被推得更远0,并且差异被放大。
如果T>1,那么输入值被推向0,并且差异减少了。
下面以不同的温度T值为变量绘制softmax 函数的输出:
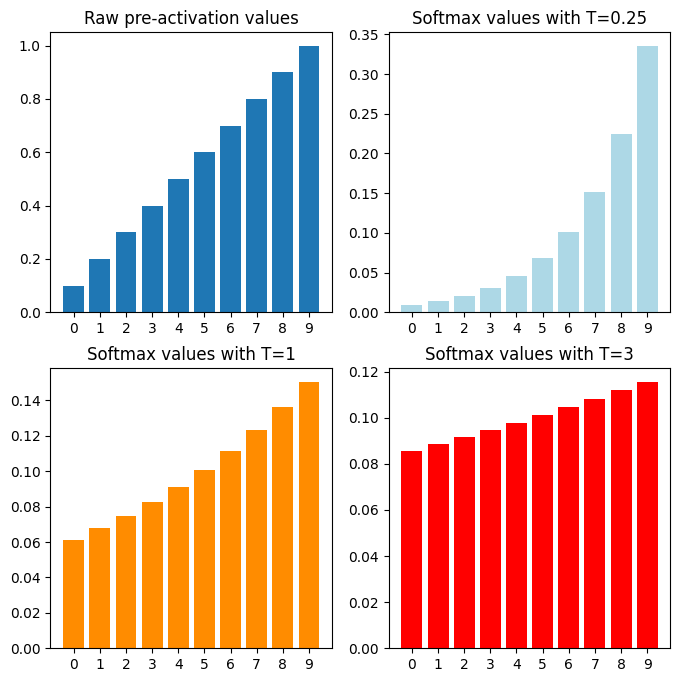
温度T对softmax的影响
由上图可知,温度越小、输入差异越大。本质上,温度改变了概率分布的形状。随着温度升高,概率差异减小,从而导致模型输出更加“随机”。这在LLM中表现为更具“创造性”的输出。相反,较低的温度使输出更具确定性。

总结
贪心搜索、波束搜索、Top-K采样、Top-p采样和温度都是影响LLM如何生成token的推理时参数。它们都根据LLM输出的概率分布进行操作。
贪心搜索、波束搜索、Top-K采样和Top-p采样只是采样策略。它们并不是专门针对LLM,甚至根本不是神经网络。它们只是从离散概率分布中采样的方法。
Top-K采样限制在一定数量要考虑的tokens。
Top-p采样限制在一定概率质量内的tokens。
相比之下,温度的作用有所不同:
温度不是采样策略,而是softmax函数的参数,该函数是网络的最后一层。
温度影响概率分布的形状。
高温使token分布概率更加接近,也就是概率较低的token可能会出现。这使得输出更加“有创意”或随机。
低温通过放大概率差异使模型更加“确定”。这使得输出更具确定性。

团队介绍
我们是淘天集团-场景智能技术团队,一支专注于通过AI和3D技术驱动商业创新的技术团队, 依托大淘宝丰富的业务形态和海量的用户、数据, 致力于为消费者提供创新的场景化导购体验, 为商家提供高效的场景化内容创作工具, 为淘宝打造围绕家的场景的第一消费入口。我们不断探索并实践新的技术, 通过持续的技术创新和突破,创新用户导购体验, 提升商家内容生产力, 让用户享受更好的消费体验, 让商家更高效、低成本地经营。
¤ 拓展阅读 ¤
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









