







阿里拍卖是阿里巴巴旗下拍卖平台,覆盖房产、机动车、土地、债权等类目。召回策略作为推荐场景的第一环,决定了整个推荐系统的上限,目前包含了包括向量召回、I2I、LBS2I、C2I等多路召回。召回的核心目标是尽可能的返回用户所有可能会感兴趣的商品,给到后续粗排、精排、重排环节,最终曝光给用户。
与淘宝APP的普通商品不同,大资产商品有其独有的特点。唯一性:每件商品都是唯一的、单库存的,世界上没有两套一模一样的房子,导致对于单商品的学习难度较大;周期性:资产的预展周期通常为一个月左右,从资产上拍预展到结拍下架,时间很短,模型可能刚学习完这个商品,商品就要下架了;高价性:房子价格动辄几百上千万,土地价格动辄上亿,对于目标人群的筛选难度较高。
本文旨在分享多兴趣向量召回MIND和深度I2I召回模型PDN在阿里拍卖资产推荐场景的实践经验。内容包括模型的介绍,大资产场景的针对性优化,以及最终的效果分析,希望能对大家有所帮助和启发。

背景
阿里资产作为资产交易平台,一方面,由于资产处置的独特性,每天在线的大资产数量较少,在百万级;另一方面,资产的地域性很强,用户感兴趣的不动产,通常都在某个偏好地内,例如:偏好杭州房产的用户不会突然对成都的房产感兴趣。结合类目和地域进行筛选后,所剩的资产数量可能就在百级别。所以在用户偏好地和偏好类目挖掘较明确和单一的情况下,规则化的个性化召回是一个较强的baseline。
我们分析数据发现,实际很多用户有多个偏好地和类目,比如:用户同时关注杭州和北京的房产;买土地用户,可能也对部分化工设备感兴趣。对于这类用户,之前的召回策略显得力不从心。因此,需要引入更加个性化的召回策略,对房产、机动车、土地等主要GMV贡献类目,召回更多地域,扩大召回类目,减缓推荐域常见的EE问题。在过去一年,我们引入了集团内的优秀工作MIND、PDN,结合大资产的特性,进行对应的优化,拿到了显著的GMV增长结果。

向量召回范式
▐ MIND模型介绍
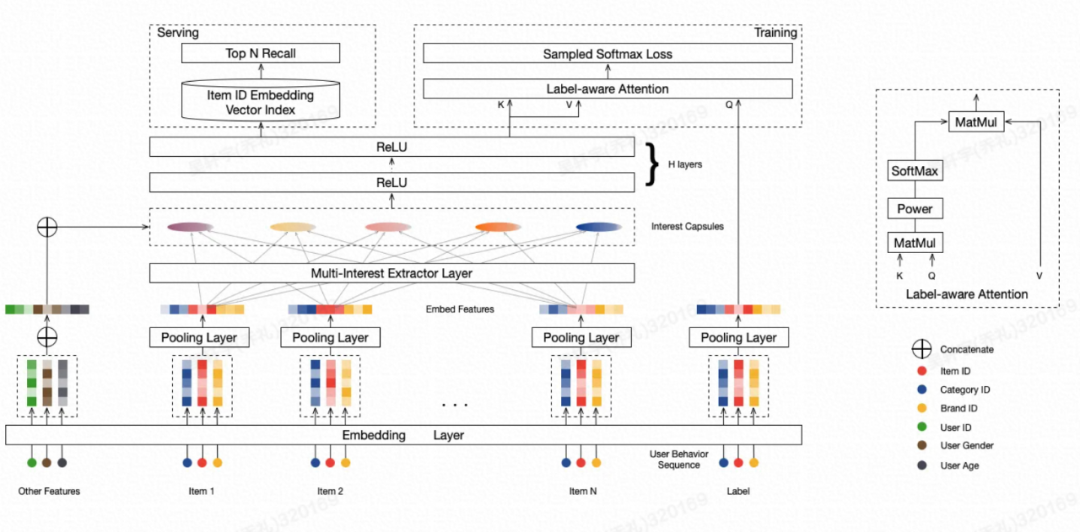
MIND模型结构(来源于文献1)
模型包括Embedding & Pooling Layer、Multi-Interest Extractor Layer和Label-aware Attention Layer。
Embedding层将用户和商品特征转为Embedding,Pooling层通过average pooling融合各类特征。
Multi-Interest Extractor Layer是兴趣多峰分布表征的核心,使用了基于动态路由的胶囊网络。假设胶囊网络有两层,一层为low-level胶囊网络(用户历史行为embedding),另一层为high-level胶囊网络(用户兴趣embedding)。low-level层有m个向量(即m个历史行为),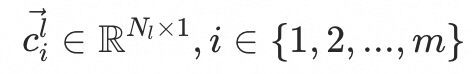 ,high-level层有n个向量(即n个兴趣),
,high-level层有n个向量(即n个兴趣),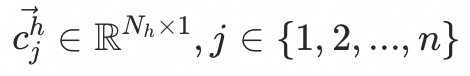 。
。
那么如何将信息从下层胶囊 传递到上层胶囊
传递到上层胶囊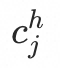 ?首先计算两者之间的路由系数
?首先计算两者之间的路由系数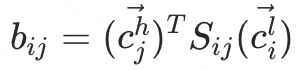 ,其中
,其中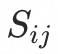 是双线性映射矩阵,随后通过softmax将
是双线性映射矩阵,随后通过softmax将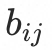 归一化为
归一化为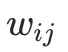 。将
。将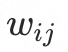 应用于下层胶囊, 就得到了上层胶囊的输入
应用于下层胶囊, 就得到了上层胶囊的输入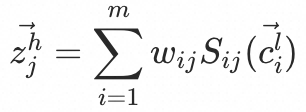 ,最终的high-level胶囊j的向量表示为
,最终的high-level胶囊j的向量表示为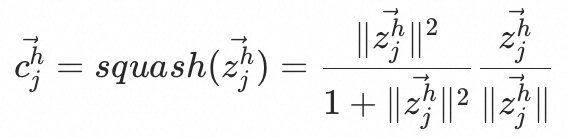 。由此可见,新
。由此可见,新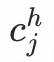 是由旧
是由旧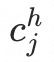 和
和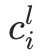 来更新的,可以用EM算法更新。
来更新的,可以用EM算法更新。
完整的流程如下:
 MIND流程(来源于文献1)
MIND流程(来源于文献1)
Label-aware Attention Layer旨在解决如何对多个兴趣向量同时学习的问题。其从多个兴趣中挑选出一个与target item最接近的兴趣,针对性的对这个兴趣进行学习,这种挑选兴趣的机制称为Label-aware Attention。在线上serving时,多个兴趣向量都被直接用于后续的召回中。
▐ 大资产适配
特征
特征层面,我们只使用了商品基本的类目、地域和少数关键属性特征。我们发现再此基础上增加更多细粒度特征反而带来了负向效果。
我们对于行为序列的时间权重做了更贴合资产场景的改动。在传统电商领域,用户的决策周期较短,从第一次看到商品到最终下单,长则需要几天,短则只需要几分钟,原有的时间权重根据分钟级衰减函数分桶。在大资产领域,用户的决策周期通常需要一个月以上,模型用户行为序列的跨度为半年,按分钟级衰减会导致大部分行为的时间权重趋同,模型无法区分行为时间。我们将时间权重改为天级别分桶后,取得了明显的效果,单路离线hitrate@300相对提升5%。
难负样本的构建
MIND的负样本为batch内随机负采样,这类样本能够使模型学到基本的判别能力,但是在大资产场景,这类负样本过于简单。在用户偏好类目和地域较窄的情况下,模型很容易学到喜欢杭州房产的人不应该召回成都土地,但是对于杭州房产的商品池区分度较低。因此需要更多难负样本指导模型学习。
曝光未点击
第一类难负样本是用户行为当天真实曝光未点击的商品,这类样本会与用户有一定相关性,可以认为是较难的负样本。我们将此类样本加入负样本,调试与随机负采样样本的比例后,发现最优的难易样本比例为1:5,这种设置下单路离线hitrate@300相对提升了6.5%。我们还尝试了去除随机负样本,只用曝光未点击作为负样本让模型学习,最终效果很差,原因是模型失去了在全量商品池中选品的能力。
同类目/地域采样
第二类难负样本是同类目和地域的采样。为了防止模型过度依赖类目和地域特征,对于每一条正样本,我们会增加同类目/地域下随机采样的商品作为负样本。对于资产供应较为丰富的类目,可以认为用户对于其中大部分商品都是不感兴趣的,此时在类目内随机采样做负样本是符合常理的。对于地域属性极强的类目,如房产、土地,我们还会增加部分同省/同城市下的随机采样,能增加模型对于同地域下商品的判别能力。
具体的,我们统计了主要大资产类目下,同城/同省的行为占比,并以此为基础设定同地域下采样的比例。
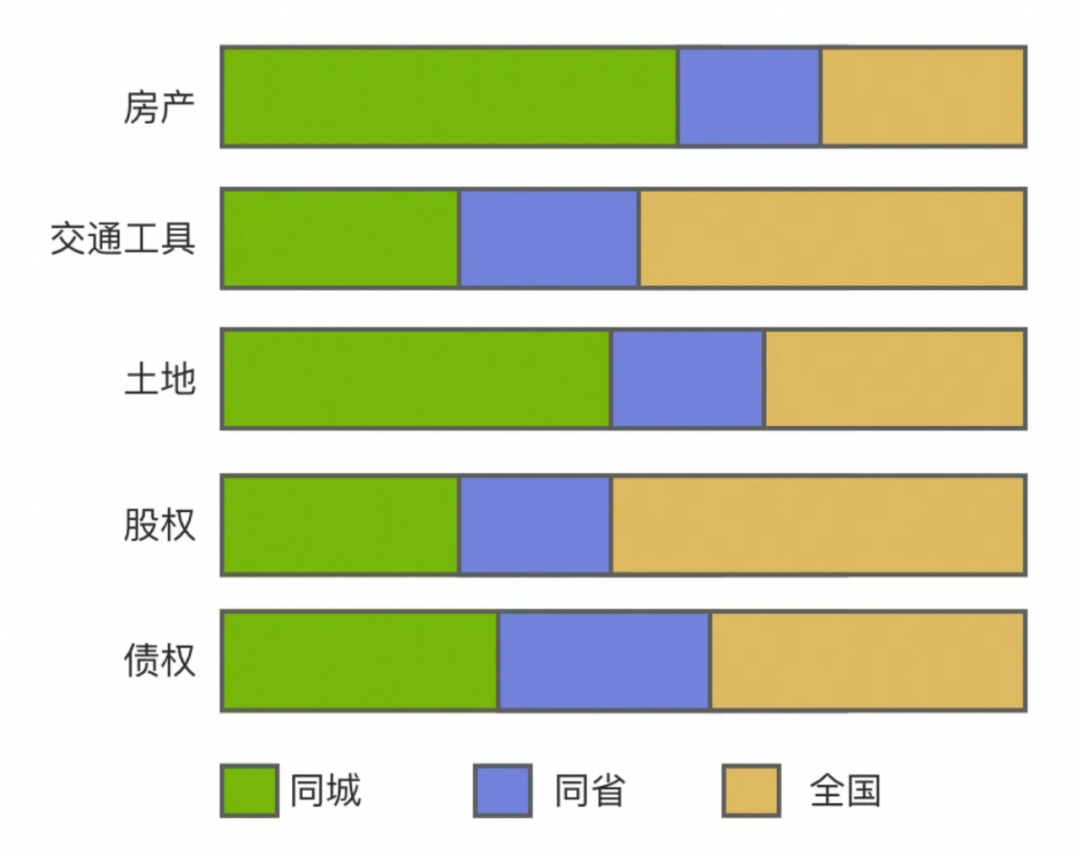
分类目地域行为占比统计
经过多轮采样比例调整实验后,加入此类负样本使得房产类目的离线hitrate相对提升了3%。
最终的样本中,每一个正样本,搭配了5个难负样本和25个简单负样本,其中难负样本的50%为曝光未点击,50%为同类目/地域下的采样。由于batch内会共享负样本,实际训练时,每个正样本对应的负样本数量为30*batch_size。
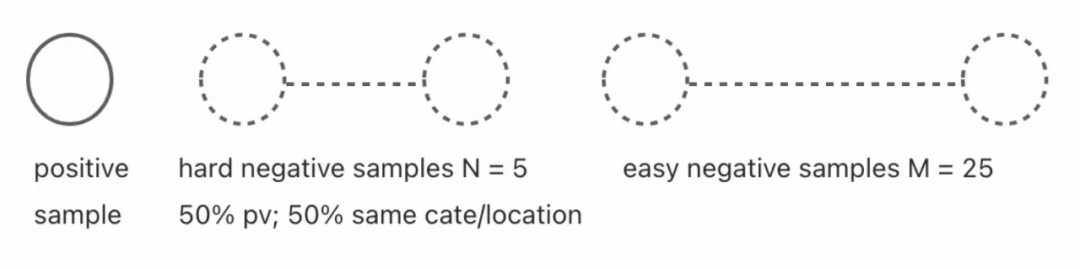
正负样本构成
▐ 线上效果
MIND上线首猜场景后,相比于对照组,曝光订阅UV转化率、曝光拍下UV转化率、曝光uv拍下价值等核心指标均有明显提升。
分析此次实验发现,用户历史行为类目和全新类目的拍下GMV均有较大涨幅,但是全新类目拍下宽度没有增长,说明模型对同一类目下商品的精准度更高,但是没有带来更多新类目的成交。

商品相似度索引范式
我们调研了PDN框架,PDN算法可以深度建模I2I的关系,同时对于用户历史行为商品也能做到细粒度的偏好建模。
▐ PDN算法概述
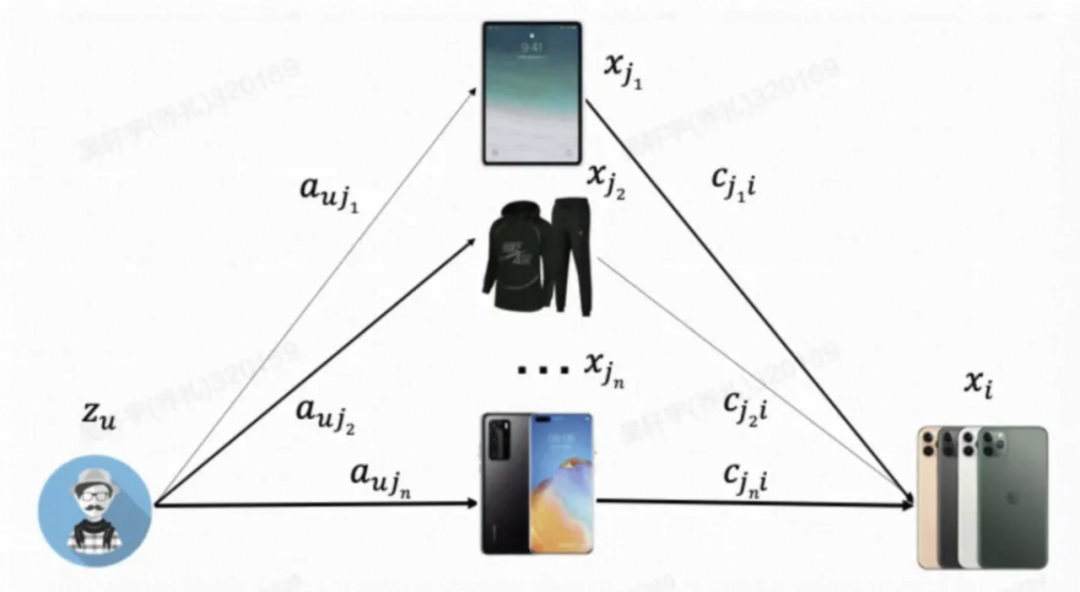
二度图(来源于文献3)
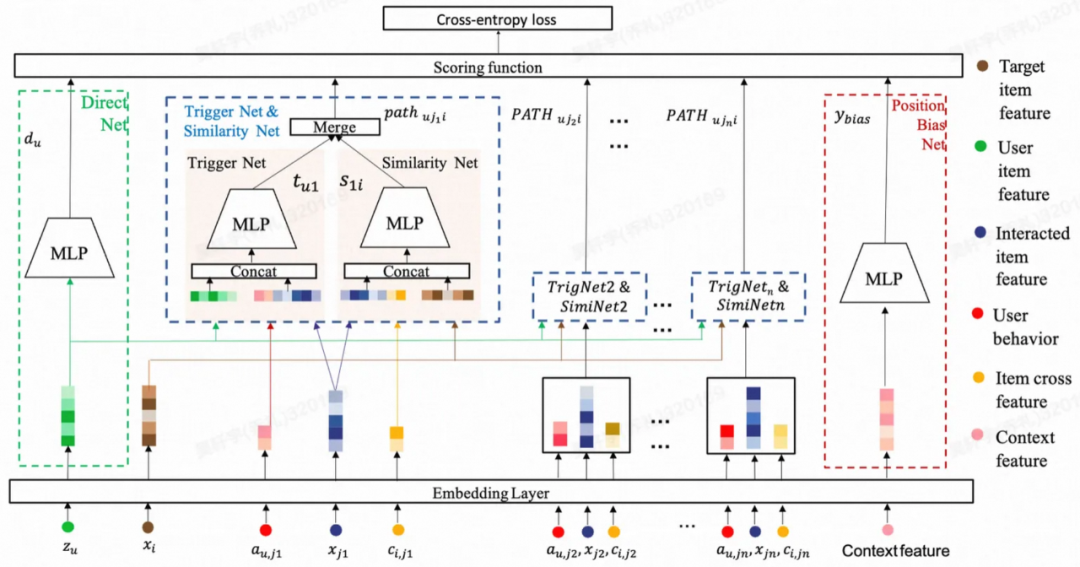
PDN模型结构(来源于文献3)
PDN将推荐问题解耦为二度图,第一跳表示用户对于已交互商品的兴趣程度,第二跳表示交互商品和目标商品的相似度。特征层面,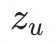 表示用户的用户信息,
表示用户的用户信息,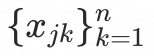 表示用户交互过的n个商品的商品信息,
表示用户交互过的n个商品的商品信息,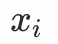 表示目标商品的商品信息,
表示目标商品的商品信息,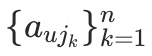 表示用户对第k个交互商品的行为信息,
表示用户对第k个交互商品的行为信息,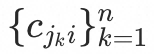 表示第k个交互商品和目标商品的相关性信息。模型包含Embedding Layer、Trigger Net (TrigNet)、Similarity Net (SimNet)、Direct & Bias Net 四个模块。
表示第k个交互商品和目标商品的相关性信息。模型包含Embedding Layer、Trigger Net (TrigNet)、Similarity Net (SimNet)、Direct & Bias Net 四个模块。
Embedding Layer将模型用到的特征转化为embedding。
Trigger Net建模第一跳,即用户对于已交互商品的兴趣程度。用户对商品j的喜爱程度的计算方式为:

Similarity Net建模第二跳,即交互商品和目标商品的相似度。商品j和目标商品的相似度为:
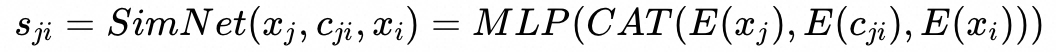
Direct & Bias Net分别建模位置偏差position bias和用户偏差user bias,使得Trigger Net和Sim Net学习出来的东西是和用户、position无关的。
最终,通过融合两跳的打分,得到每条路径下用户与目标商品相关性的评分。整合所有路径,就能得到用户对于商品的最终打分。具体计算方式为:
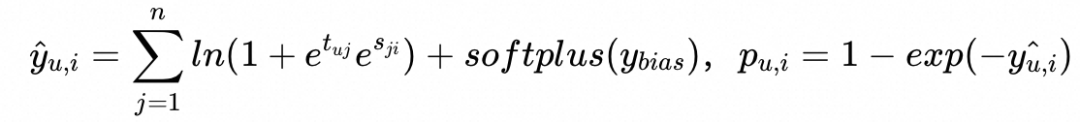
最后采取交叉墒计算损失。
▐ 大资产适配
特征
特征主要包含五个模块:用户静态特征、用户行为context特征、交互商品特征、交互商品和目标商品间统计特征、目标商品特征。
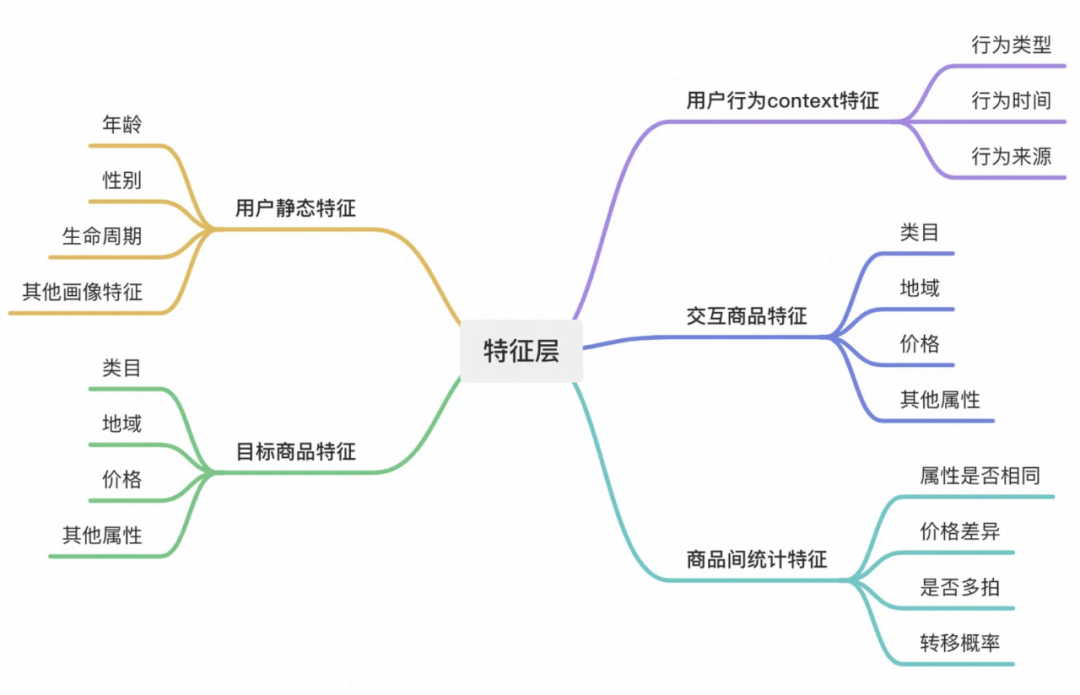
模型特征总结
在特征优化的过程中,我们发现在增加用户与目标拍品的交叉特征(如对目标拍品所属类目的偏好分等)后,虽然模型的loss下降,能够预测得更好,但是I2I的效果却显著变弱了,原因是这类交叉特征给了模型一条不通过二度图就能预测的捷径,弱化了I2I间关系的学习的必要性。相对的,商品间的转移概率特征作为站内用户已有行为的先验概率统计,能够显著提升I2I的效果。
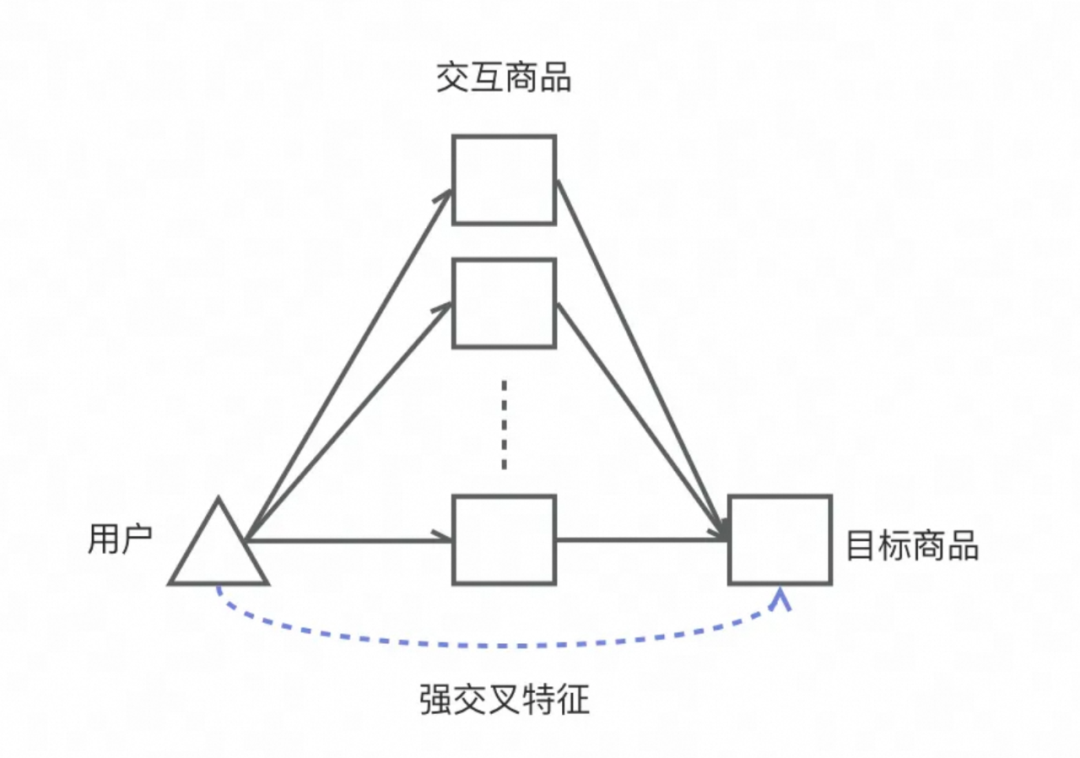
强交叉特征损害二跳路径学习
负样本的构建
基于MIND的样本优化经验,我们继续采用了全局随机负采样、曝光未点击、同类目/地域采样三类负样本。结论与之前一致:加入每种难负样本后都能带来相应的增益,并且单纯只用难负样本的效果很差。我们在此基础上对采样方式做了一些升级。之前的采样方式为均匀采样,对于热门和长尾商品的采样概率是相同的,导致负样本中长尾商品的数量远大于正样本,使其打分偏低。我们将采样方式改为根据用户行为频率采样,以缓解马太效应的影响。
▐ 线上serving
由于PDN的作者团队在线上使用时发现trigger net筛选交互商品的收益较小,最终只用了similarity net生成了索引表,也取得了很好的效果。此次我们只用了相似商品索引表的方式上线。
因为商品池很大,我们无法对所有商品对进行相似度打分,我们通过两路生成候选相似商品。
第一路根据已有的I2I相似分计算规则,通过类目、地域、价格相似分,尽可能多的把潜在相似商品囊括进来。第二路根据MIND产出的商品向量,在向量维度召回相似的商品。融合两路后使用similarity net产出商品间的相似分。
线上serving时,实时取到用户最近的50个交互商品作为trigger,通过索引表拿到相似拍品集合后,返回相似分最高的N个商品。
▐ 线上效果
实验组中,我们用PDN产出的索引表替换了原有的I2I索引表,保持其他逻辑不变,验证效果。
在首猜资产推荐场景上线后,相比于对照组,曝光订阅UV转化率,曝光交保UV转化率,曝光拍下UV转化率,曝光UV拍下价值等核心指标均有明显提升。
通过对实验数据的分析,我们发现此次实验GMV的增长主要源于突破了原有的相似商品对于价格的限制,模型发现起拍价相差较大的品也会有很强的相关性,对于这部分高价相似拍品的召回是提升的主要因素。用户历史行为类目由于I2I准度提升,带来的成交增长明显,而全新类目带来的成交稍降,接下来需要对用户的新兴趣进行持续探索。

总结和反思
在过去一年,我们通过引入集团内的优秀的召回工作,做了更加贴合大资产场景的优化,取得了不错的效果。增长主要源于对于用户已有兴趣的深度挖掘。通过分析实验数据,我们发现活跃用户的曝光类目数量有所减少,信息茧房正在形成。而在未来一年,活跃用户的发现性召回对于资产推荐场景的价值是一个急需探索的方向,我们期望通过曝光更多相关类目,提升用户留存和下拉深度,最终带来GMV的增长。同时,目前新用户的召回比较单一,如何更好留住新用户也是重要的课题。

参考文献
Multi-interest Network with Dynamic Routing for Recommendation at Tmall:
https://arxiv.org/pdf/1904.08030
https://zhuanlan.zhihu.com/p/467495253
Path-based Deep Network for Candidate Item Matching in Recommenders:
https://arxiv.org/abs/2105.08246
Large Scale Product Graph Construction for Recommendation in E-commerce:
https://arxiv.org/pdf/2010.05525

团队介绍
我们是淘天集团-阿里拍卖算法团队,专注于特色资产(房产/土地/股权/债权等)的商品理解和人货匹配。我们基于集团庞大的数据资源和海量拍卖行为数据,挖掘用户的全域行为,借助大模型融合多源异构数据进行资产搜索、推荐、广告,以及潜客挖掘、资产拍下率预估、资产询价、资产商品理解等,帮助业务拓展优质供给、提升GMV和营收。
¤ 拓展阅读 ¤


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









