







本文介绍了一种全新的基于扩散模型的面部局部替换方法,能够从多个参考图像中提取面部特征并进行无缝融合,生成高保真度的人脸图像。该方法解决了现有面部替换技术中存在的挑战,比如如何高效且有效地将多个参考图像的特征融合在一起,如何保持特征之间的协调性,并在保持高保真度的前提下实现高效融合等问题。该方法在面部局部替换技术领域具有广泛的应用前景。

NeurIPS介绍
神经信息处理系统大会(Conference on Neural Information Processing Systems,NeurIPS)是 CCF-A类会议,她与 ICML、ICLR 并列为机器学习三大顶级会议。今年的 NeurIPS 2024 会议总共收到了 15671 篇有效投稿,最终录用率为 25.8%。我们团队的论文《FuseAnyPart: Diffusion-Driven Facial Parts Swapping via Multiple Reference Images》被NeurIPS 2024 录用并评为 Spotlight(Spotlight 的历史录稿率约 3%)。本论文提出了一种全新的基于扩散模型的面部局部替换方法,能够从多个参考图像中提取面部特征并进行无缝融合,生成高保真度的人脸图像。
论文地址:https://arxiv.org/abs/2410.22771
代码地址:https://github.com/Thomas-wyh/FuseAnyPart

论文背景面部局部替换技术是一种可以将来自源图像的某些面部特征区域替换到目标图像中的技术。相比传统的全脸替换,这种技术在保持目标图像大部分内容不变的情况下,通过仅对某些感兴趣区域进行修改,可以实现更精细和个性化的角色设计,这在虚拟角色生成、娱乐、隐私保护等方面有广泛的应用。
然而现有的面部替换技术大多集中在全脸的交换,如基于GAN(生成对抗网络)的方法和基于扩散模型的方法。GAN方法通过从源图像中提取身份特征并将其注入生成模型中来完成全脸替换,但在源图像与目标图像的面部形状差异较大时,这些方法可能无法完全传递身份特征。而且,GAN模型的训练需要设置大量的损失函数来保证图像的质量、身份和面部特征的一致性,这使得训练过程复杂且耗时。另一方面,基于扩散模型的全脸交换方法尽管在生成高分辨率复杂场景方面展示了很强的能力,但它们主要关注的是全脸的替换,缺乏对面部局部特征的精细控制,无法独立地对某些特定面部部位(如眼睛、鼻子、嘴巴)进行替换。因此,我们团队着手开发面部局部替换技术。
面部局部替换的主要技术挑战之一是如何高效且有效地将多个参考图像的特征融合在一起。例如,当需要融合不同来源的眼睛、鼻子和嘴巴时,如何合理地保持这些特征之间的协调性并确保最终生成的面部图像在视觉上自然一致,这是一个复杂的问题。同时,由于需要结合多个不同的参考图像,面部部位交换面临计算复杂度的增加。因此,如何在保持高保真度的前提下实现高效融合,也是一个需要解决的难题。
为了解决这些挑战,我们提出了FuseAnyPart,一种全新的基于扩散模型的面部部分替换方法,能够实现多个源图像中的面部特征的无缝融合,以实现个性化定制的面部图像生成。
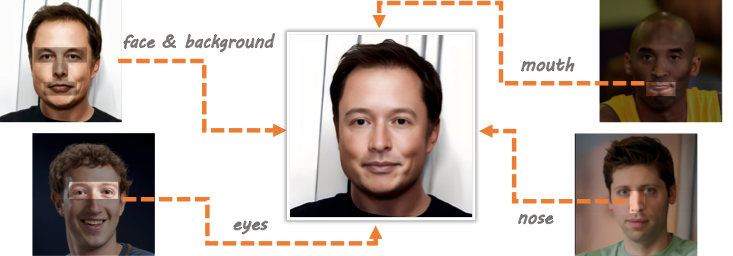
图1 FuseAnyPart 效果示意图
模型方法FuseAnyPart的核心创新在于如何有效地在扩散模型的潜在空间中进行特征融合,具体包括两个主要模块:基于掩模的融合模块和基于加法的注入模块。
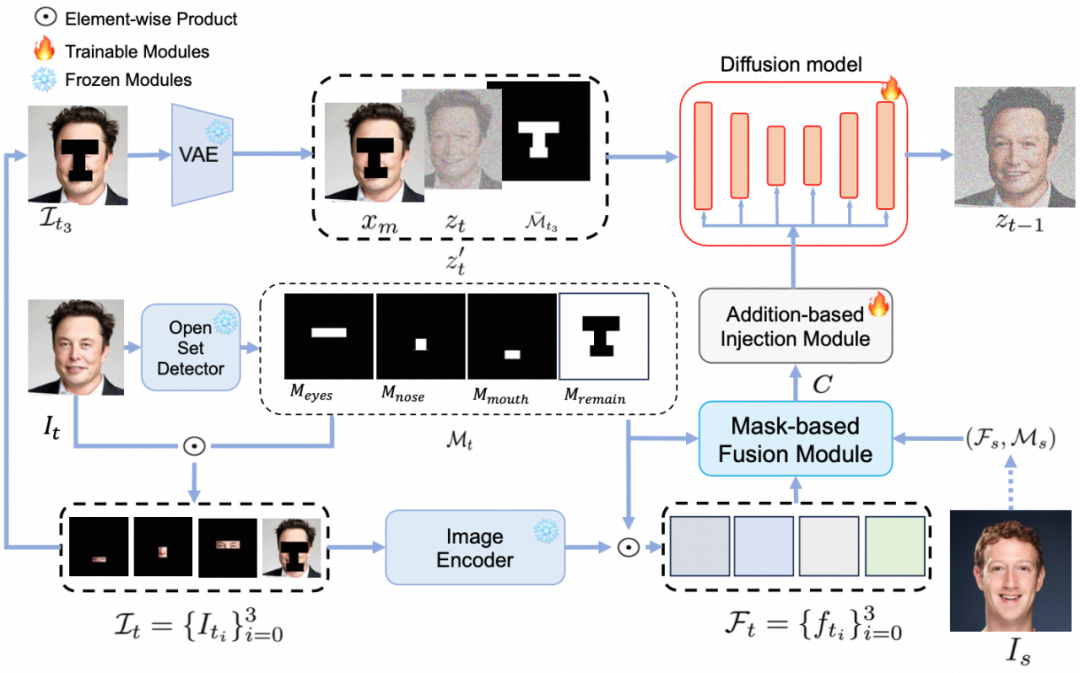
图2 FuseAnyPart 流程图
▐ 基于掩模的融合模块 (Mask-based Fusion Module)
FuseAnyPart首先利用开放集检测模型(例如Grounding-DINO)来生成不同面部器官的掩模,包括眼睛、鼻子、嘴巴等。这些掩模用于标识图像中的不同区域。然后通过一个预训练的图像编码器(例如CLIP)提取这些区域的特征。在这里,FuseAnyPart提取的是编码器倒数第二层的未压缩特征图,而非更为抽象的全局特征。这些特征包含更丰富的空间信息和细节,能更好地表示面部局部区域。
基于生成的掩模和区域特征,FuseAnyPart在潜在空间中进行特征拼合。具体来说,它将来源图像的某些区域特征替换目标图像中的相应区域。最终融合后的特征被聚合并输入到多层感知器(MLP)中,生成用于指导生成网络的条件特征图。
▐ 基于加法的注入模块 (Addition-based Injection Module)
传统的基于交叉注意力的融合机制通常在将多模态特征(如文本和图像)融合时有效,但在对齐细粒度的面部区域特征时表现欠佳。因此,FuseAnyPart引入了基于加法的注入模块,以直接将融合后的图像特征注入到扩散模型的UNet网络中。

图3 Addition-based Injection 模块
在UNet中,将融合后的特征直接添加到潜在特征中,而不是通过交叉注意力的方式。这种方式能更直接地保持细粒度特征的空间一致性,且减少了新增参数的数量,降低了计算负担。注入过程公式化为: , 其中
, 其中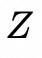 是UNet中的潜在特征,
是UNet中的潜在特征,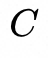 是融合后的面部特征图,
是融合后的面部特征图,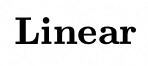 是一个线性层,
是一个线性层, 函数用于将注入的特征调整到与
函数用于将注入的特征调整到与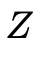 匹配的尺寸,
匹配的尺寸,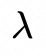 是权重因子。
是权重因子。
这种加法注入方法具有两个显著优势:首先,潜在特征和条件特征图都具有位置信息,通过直接加法方式,可以保证新增特征与原始特征在位置上的一致性;其次,相比于交叉注意力机制,加法注入方法减少了计算复杂度,并且能在较少训练数据的情况下依然实现良好的性能。

实验结果
数据集: 模型在CelebA-HQ数据集上训练,并在FaceForensics++数据集上评估。CelebA-HQ包含3万张高分辨率人脸图像,FaceForensics++则用于测试。
▐ 定量对比
在生成质量和相似度方面,FuseAnyPart相对于其他方法取得了更好的Frechet Inception Distance (FID) 和器官相似度 (OSim) 指标,验证了其优越性和稳健性。实验指标如图下所示。
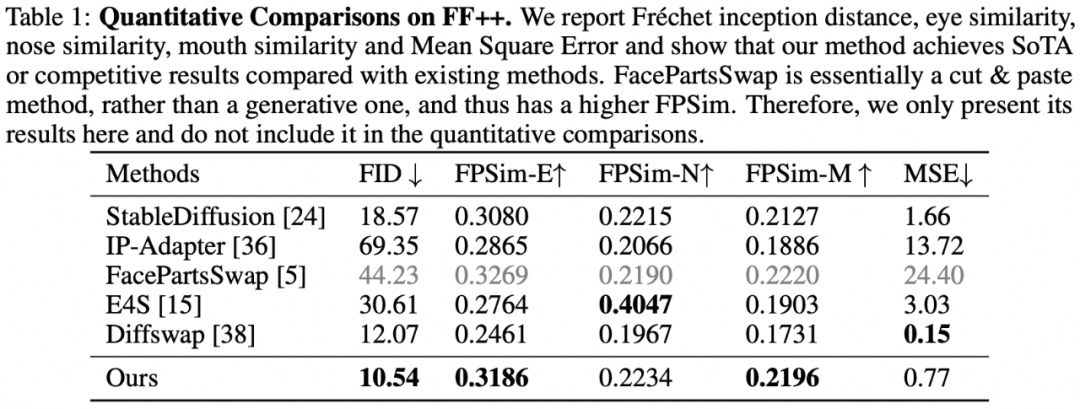
图 4 FuseAnyPart 的定量对比实验
▐ 定性对比
实验结果显示,FuseAnyPart在单部位、多部位替换和不同风格下的多部位替换任务中均优于现有方法(例如FacePartsSwap、E4S、DiffSwap等),生成的图像在视觉上更加自然和协调。对比效果如下图所示。

图 5 FuseAnyPart 的定性对比实验
FuseAnyPart 在跨种族跨年龄的人像合成上也可以取得较好的表现,效果如下所示:

图 6 FuseAnyPart 在跨种族跨年龄人像合成上的效果

应用现状与展望
FuseAnyPart 专注于高可控多参考图人脸合成,可以用于新人物形象的合成。在当前业界AIGC人像生成技术上,存在人脸生成效果趋同、差异性不够显著、人脸不够真实的技术难题,影响到人像生成在业务领域的应用。在组内业务方面,需要结合差异性和真实性更高的人脸生成,构建虚拟人形象和视频换衣模板库的模特形象,用于巨浪、主搜等业务场景。当前,本论文对应技术正应用于巨浪外投营销视频场景的虚拟人形象的构建,产出的虚拟人讲解营销视频获得巨浪业务的好评,已于10月底完成小规模实验,在视频点击率 CTR 上有显著提升。
在未来的工作中,我们将在搜集到业务数据集上微调 FuseAnyPart,进一步提升 FuseAnyPart 的合成效果;计划在构建丰富的合成人脸数据库,应用于虚拟人、图像换衣、视频换衣等业务上。

团队介绍
我们是淘天集团-内容AI团队,一支专注于通过AIGC驱动商业创新的技术团队。我们依托淘天集团丰富的业务形态和海量的用户与数据,致力于为消费者提供创新的在线体验,为商家提供高效的场景化内容创作工具。我们持续以技术驱动产品和商业创新,不断探索和衍⽣互联⽹新技术,团队累计发表CCF-A类顶会和顶刊(如NeurIPS、CVPR、ECCV、ICCV、TPAMI、TIP等)论文20余篇。我们的技术域涵盖多模态大模型、视频生成、图像生成、大语言模型等多个领域,欢迎相关领域人才加入,一起共创未来。
¤ 拓展阅读 ¤


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









