







最近参与了部门消息服务的架构升级和稳定性保障,以此文简单总结下当建设和负责维护中间件稳定性时必备的SLA基础知识,一并调研了目前国内外商业化的云消息中间件产品SLA相关情况,最后附上个人在维护消息中间件和支持不同业务场景时的一些通用性粗浅思考,有不恰当的地方欢迎大家探讨交流。

SLA基础概念
无论你是一名个人云开发者,正在众多云服务提供商的套餐和支持方案中进行比较和选择;或是作为企业的采购负责人,评估外部供应商提供的服务系统是否满足企业业务需求和发展目标;亦或是公司内部服务平台的技术运维人员,需要评估系统的实际性能和边界条件,以判断其是否能够满足内部业务部门的要求并提供相应的保障承诺.......所有这些场景都离不开一个关键概念:服务等级协议(SLA,Service-Level Agreement),而你打开任意一家云服务厂商的官网,你都能在产品页面中找到一份公示的SLA。
在上述场景中,显然具备三个核心组成要素,即围绕SLA的上下游存在着两类角色,分别是服务提供方(SP,Service Provider)和服务客户(SC,Service Consumer),如下图所示:

图1 SP -> SLA -> SC
形式上来说,SLA是指系统服务提供者对客户的一个可量化服务承诺和协议,它是将服务质量评估从经验模型向量化模型转变的关键工具。SLA通常明确列出了服务可用性、数据可靠性、响应时间等服务特性指标及其定义,服务提供方基于这些指标对客户做出量化承诺。此外,SLA 中还详细说明了服务提供方未满足承诺时的补偿操作(后果),例如提供额外支持、优惠折扣或钱款赔偿。通常,SLA 是在客户和外部服务提供商之间达成,但同一公司内的不同部门也可以相互签订 SLA,此时未满足SLA承诺的后果一般不涉及经济赔偿,而侧着于业务责任划分。
需要注意的是,SLA 的生命周期并不像图 1 所示的那样呈现单向、一次性或静态的特征。相反,它是一个双向、持续且动态的反馈和调整过程。在这个过程中,客户的需求可以通过 SLA 反向推动服务提供者进行系统设计和迭代决策。实际上,围绕 SLA 的生命周期,图 1 可以进一步优化为图 2 所示的形式:
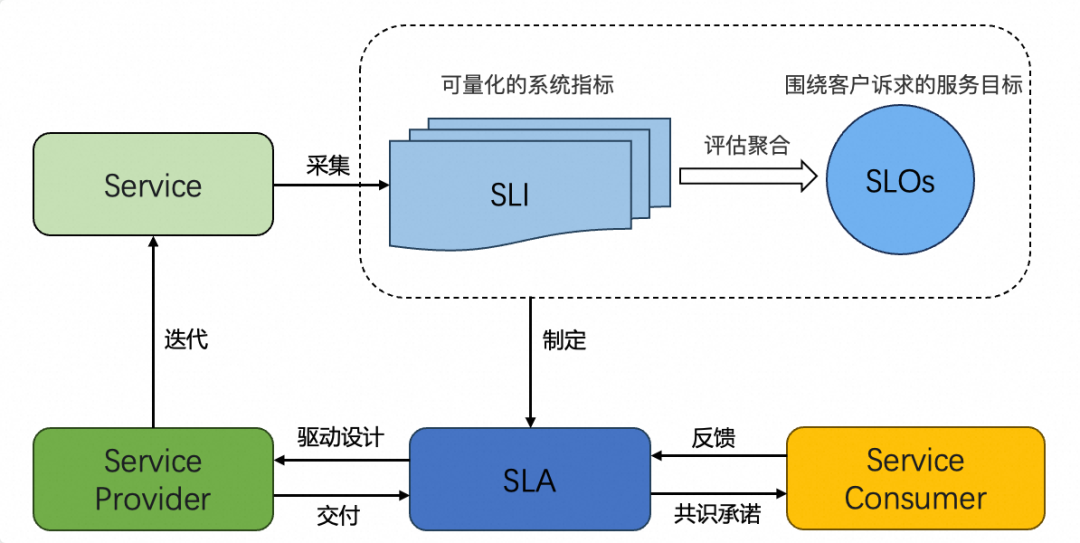
图2 SLA生命周期
为了完全理解上图,我们需要了解一些SLA中的特别概念:
▐ 1. SLA常见概念
SLI(Service Level Indicator)服务等级指标:SLI指定了SLA中所提供服务某一维度的可量化指标,且必须具有清晰严谨的定义和计算方式。比如,对于某一网站的单实例服务器,一个简单的SLI定义是由客户端所发出合法的请求得到正常响应的百分比,合法的定义是请求参数和资源类型能够被服务端约定的协议解析成功,正常响应的定义是请求结果中不包含超出协议约定的错误或非预期数据。
SLO(Service Level Object)服务等级目标:SLO明确了SLA中所提供服务某一维度的期望状态,是围绕SLI构建的目标。SLO是客户感知和判断服务质量最为直观的方式,常见的说法如“XX 可用性达到几个 9”就是一种 SLO。规范来说,SLO有指标范围和实现时间要求,这意味着在特定时间窗口内(通常是服务周期),涉及的 SLI 必须达到预定的指标标准,并且在该时间段内的实现比例应达到预期。如果未能达到SLO,则应触发SLA中定义的后果,一般为对SLA中服务提供方的惩罚以及对客户的补偿方案。
例如,在单实例工作负载小于 10,000 TPS 的条件下,指定服务的平均请求响应时间应小于 85 毫秒,且响应有效率需超过 95%。承诺在一个月的服务周期内,这些指标的达成时间比例应超过 99.9%。若未满足上述服务等级目标,则将提供相当于服务费总额 20% 的代金券作为补偿。
因此,可以简单理解为:SLA = SLO + 后果 = SLI + 实现指标和时间占比要求 + 后果。可以看出,服务SLA是众多云厂商获取客户青睐和信任的有效竞争手段和必要承诺。通过明确服务质量的量化指标、期望目标以及未达成目标时的补偿措施,SLA 有助于建立客户与服务提供商之间的信任关系,并在竞争激烈的市场中提升服务商的竞争力。

图3 服务SLA的重要性
此外,部分云厂商也提出了一些其他概念:
SLA规则:是在SLA指标(SLI)的基础上,添加了判断条件,以触发告警或停止压测。这些规则可以帮助在服务性能偏离预期时及时识别问题,确保服务稳定性。
SLA模板:是SLA规则的集合,可包含一个或多个SLA规则。SLA模板通常与行业、业务类型绑定。通过使用 SLA 模板,组织可以快速应用符合其特定需求的服务等级协议规则集,从而提高管理效率和一致性。
SLA拓扑,也称为SLO拓扑,指的是当服务足够复杂,链路中涉及多个子服务及其SLO,评估和计算整体服务 SLA 所需的依赖路径关系。
▐ 2. SLA基本要素组成
基于以上概念,当你作为某项服务系统的提供方起草一份规范的对外SLA时,通常需要包含但不限于以下内容:
协议概述:概述中应明确 SLA 的起始和结束日期、参与协议各方的详细信息,以及所涉及服务的简要说明。例如,协议可能会详细列出服务提供商和客户的联系信息和角色定义。
服务描述:这一部分应对 SLA 涵盖的所有服务进行详细描述,包括关键概念定义。例如,可以包括服务的周转时间、支持的技术和应用程序、计划的维护周期,以及相关流程和程序。
服务等级目标:明确协议中关于特定服务等级指标(SLI)的目标,例如服务可用性或平均响应时间。协议双方同意使用数据支持的关键服务指标来评估这些目标的达成,例如保证 99.9% 的服务可用性。
故障恢复流程:详细说明故障告警和恢复流程,概述供应商在发生服务故障时应遵循的机制和流程。这部分可能包括约定的响应时间(RTO)和恢复时间目标(RPO)。例如,故障报告后 1 小时内开始响应,4 小时内完成数据恢复。
安全标准:协议须明确约定双方采取的安全标准和措施,例如数据私密性、权限控制和安全审查流程,以确保服务的安全性。
排除条款:此部分描述双方商定的所有排除和豁免情形。例如不可抗力事件或第三方故障导致的中断不在服务承诺范围内。
惩罚与补偿:此部分明确规定未能履行 SLA 义务时的后果,例如给予客户相应的服务费退款或代金券作为补偿。
终止流程:双方可能会在某个时间点想要终止协议。除了任一方要求的通知期以外,SLA 还会清楚地规定允许终止或使协议失效的各种情形。
变更与审查流程:服务提供商能力、工作负载和客户要求会随着时间的推移而变化,因此需要定期审查服务商提供的 SLA 。有关服务商或客户要求的任何重大更改,需要被记录在协议当中,确保透明与合规,从而SLA 能够整合服务提供商产品或服务的最新功能来满足当前的客户需求。
签名:该协议由双方授权的利益相关者审查文档中有关各事项后进行签署,在协议生效期间约束所有相关方遵守协议条款。
▐ 3. SLA常见指标
3.1 服务可用性(Availability)
在各类系统服务的 SLA 中,服务可用性是最常见的指标之一。服务可用性指的是服务提供商在特定时间段内保持其服务可供使用的时长。这一指标通常以特定时段(称之为服务中周期)来衡量,并需要明确界定何为"服务不可用"。例如,SLA 可能规定服务提供商的系统在每天内必须保持 99.5% 的可用性,这意味着每24小时,服务不可用的总时长不应超过 7.2 分钟。在计算服务可用性之前,先介绍如下几个定义:
平均故障间隔时间(MTBF):是指服务相邻两次故障之间的平均时间
MTBF = 总运行时间 / 故障次数
平均故障修复时间(MTTR):是指服务发生故障后,从故障发生到恢复完毕的平均时间。
MTTR = 故障恢复总时间 / 故障次数
平均正常运行时间(MTTF):是指服务在无故障状态下能够持续运行的平均时间。该指标通常只用于不可修复的系统,也即代表了服务的期望寿命。
从而,可以计算得出服务可用性,图 3 给出了一个简单的例子:
Availability = MTTF /(MTBF + MTTR)
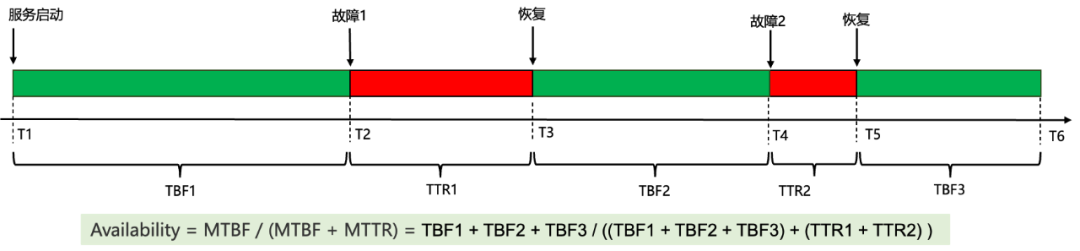
图4 可用性计算简化案例
在大多数云产品的对外SLA中,一般以服务周期为评估单位,因此服务可用性采用了一种对客户更直观的表达方式来申明:
服务可用性 =(服务周期总时间 - 服务周期服务不可用时间)/ 服务周期总时间 * 100%
其中,服务不可用的具体定义取决于不同产品的SLA声明。基于以上计算原则,服务可用性SLO中服务周期选取与不可用时长的关系可由下表列出:
可用性级别 | 可用时长百分比 | 不可用时长/年 | 不可用时长/月 | 不可用时长/周 |
1个九 | 90% | 36.5天 | 72小时 | 16.8小时 |
2个九 | 99% | 3.65天 | 7.2小时 | 100.8分钟 |
3个九 | 99.9% | 8.76小时 | 43.2分钟 | 10分钟 |
4个九 | 99.99% | 52.56分钟 | 4.32分钟 | 1分钟 |
5个九 | 99.999% | 5.25分钟 | 25.92秒 | 6秒 |
6个九 | 99.9999% | 31.5秒 | 2.5秒 | 0.6秒 |
3.2 数据可靠性(Reliability)
通常针对存储系统设置,指的是数据在存储、传输和处理过程中保持准确性和完整性的能力。被视为可靠的数据将承诺不会丢失、损坏或被未经授权的修改。更细致的又可以分为数据持久性、数据一致性、数据可用(访问)性等等:
数据持久性:指的是数据在存储后能被长期保存的能力,不会因为断电或系统崩溃等问题而丢失。
数据一致性:指的是在数据存储和处理过程中,数据在多副本或多系统之间的状态保持一致的能力。
数据可用性:指的是用户能够访问和使用数据的能力,与服务可用性类似。高数据可用性意味着系统即使在系统发生部分故障或维护期间,在需要时也总是能够提供数据访问。
举个例子,某云服务厂商的对象存储服务承诺可提供99.9999999999%(12个9)的数据持久性,这意味着,存储一万亿个对象大概只会有1个文件是不可读的。一般来说,数据可靠性可宽泛定义为数据在系统中确认存储成功后不丢失/不损坏的概率。影响数据存储的原因可分为三类:
硬件级故障:例如磁盘损坏、电源故障、内存故障以及网络设备失效等
软件级故障:例如消息队列中的实现bug/死锁可能导致数据未能正确传递或处理,在某些情况下,消息可能未实际写入内存或磁盘,但系统已经向客户端发送了成功确认(ACK)
人为故障:例如错误配置、数据误删除、运维误操作或执行脚本不当等
数据可靠性计算相对服务可用性计算复杂很多,需要依据专门的量化模型计算。如果仅考虑硬件级故障,可参考如下模型来量化一个存储系统的年度数据可靠性:
Reliability = Func(N,R,MTTR,CopySets,D,AFR)
其中,N是存储系统磁盘的总数;R(Replications)是单块磁盘配置的副本数;MTTR为磁盘故障平均修复时间;CopySets(副本数据复制组)是分布式存储系统中对一份数据的所有存储副本的分组集合,这里取CopySets的模,例如一份数据写入到了p1,p2,p3盘,那么{p1, p2, p3}就是一个CopySet,当该CopySet损坏,则这份数据丢失。CopySet可以用于衡量数据副本存储的离散分布程度,且满足:
N/R <= |CopySets| <= C(N, R)
其中C是组合计算符,当数据存储分布越分散随机,那么同时损坏 R 个盘时会完全丢失某份数据的概率就越高,而 |CopySets| 越接近N/R,那么发生损坏时丢失的数据量越高,恢复时间和成本也会攀升,因此CopySet的生成策略十分考验技巧;D(Distributions)是预设的故障概率分布模型,常见有二项分布、泊松分布等;AFR(Annualized Failure Rate)是磁盘的年故障率,其定义为:
AFR = 1 / (MTBF / (24 * 356)) * 100%
从模型组成因子的定义直观来看,AFR、MTTR和CopySets的模与数据可靠性负相关,而磁盘总数和副本数与可靠性正相关。但实际情况并没有这么简单,每项因子对可靠性的贡献可能并不是线性或连续的,因子之间也并不完全独立,例如AFR与MTBF相关,而MTTR也受Replications和CopySet分布策略的影响。由于可靠性模型的具体推导计算过程超出本文篇幅,感兴趣的读者可以移步参考文献[4][5]。
3.3 请求错误率(Error Rate)/成功率(Success Rate)/可用率(Availability Rate):
这三个指标在大多数服务中是客户使用感知最为明显的,通常关注的粒度为服务的接口级别,而服务可用性则是更多侧重评判服务整体的质量。一个常见的场景是,客户端定时监控某项服务请求的错误率,以此衡量服务的某项功能或者子集是否低于SLA中的预期目标。
以错误率计算方式为例:
错误率 = 1 - 成功率 = 时间片内导致系统产生错误的请求数 / 该时间片内的请求总数 * 100%
可用率:可用率在语义上不同于成功率,它要求服务请求的响应正确且有效,并且通常会排除非服务端导致的错误,例如客户端非法参数、权限拦截,服务外部前置链路的限流等等。
这三个指标通常以时间片进行周期计算,例如每1分钟错误率、每5分钟成功率等等
3.4 吞吐量(Throughput):
指单位时间内系统能处理的请求数量,体现系统处理请求的能力,这是目前最常用的性能测试指标。吞吐量指标一般包括QPS(Query Per Second,每秒处理请求数),TPS(Transaction Per Second ,每秒处理事务数)等。
QPS指系统每秒能处理的请求(查询)数,通常用于衡量服务器能抗多少流量:
QPS = 时间片内请求总数 / 时间片秒数
TPS指系统每秒能处理的事务数。这里事务是指一个完整的业务处理和响应过程,可能对系统发起多个QPS中定义的请求:
TPS = 时间片内事务总数 / 时间片秒数
以上计算通常针对网站或者业务系统,对于数据库(例如MYSQL)等其他类型服务而言,除了有更区别细化的定义,还会关心 IOPS(Input/Output Per Second,磁盘每秒读写次数)等SLI。
3.5 响应时间/延迟(Latency):
指系统在收到用户的请求到响应这个请求之间的时间间隔,系统的延迟指标通常与服务的性能、吞吐量等指标相关。该指标通常会以时间片平均或者百分比的方式计算,并且与采点方式、点位选择强相关:
平均值:此方法通过计算所有请求的平均响应时间,判断是否低于设定阈值。但这只能作为一种较为宏观的评估方式,对于波动型的系统状态或者对半的响应时间分布情况,会掩盖许多问题。
百分比:我们也经常会在SLA中看见p95或者是p99这样的延迟声明,其中p指的是percentile(百分位)。当系统的p95 延迟为1秒,意味着 95% 的请求响应时间小于 1 秒,而剩余 5% 的请求则超过 1 秒。
3.6 其他
此外,SLA中通常还会涉及如下指标:
故障频率和恢复:通常涉及服务可用性中提到的MT类型指标,例如代表故障平均恢复时长的MTTR等,部分SLA会单独针对这些指标做出承诺,以便故障发生时客户能有明确的修复耗时预期。
服务支持:通常包含服务提供商提供的技术支持、客户服务等方面的指标。例如,在运营云服务时,可要求服务提供商提供24小时客户服务、及时响应客户请求等。例如,某云服务商提供8:00-24:00的在线服务支持,并提供全天24小时的服务热线。
安全性:为了证明服务提供方会采取预防性措施来减少非安全操作和数据泄露,可量化、可控制的安全指标(如加密可靠性、防病毒更新和补丁等)是许多云服务厂商都必须面对的问题。
业务绩效目标:该指标通常关联服务提供方或者客户业务方的绩效标准。在公司内部的双方合作部门SLA签订中,常见的形式是服务周期内xx业务无x级以上故障。
其他特殊服务/中间件的定制指标
▐ 4. 制定SLO时需要考虑什么
4.1 制定并量化统计SLI
在制定服务等级目标(SLO)时,准确统计和量化服务等级指标(SLI)是首先考虑的。如何有效采集和计算SLI,将直接影响SLO的合理性和可达成性,一般需要考虑如下方面:
了解客户群体:明确服务的目标客户群体,在制定 SLI 时,需要提供简明、清晰且无歧义的定义,使客户能够快速理解并达成共识。我们不应追求 SLI 的数量和复杂度,而应重点关注客户真正关心的业务价值和服务使用体验。例如,对于电商平台,下单成功率就是一个关键 SLI。
反映系统性能和架构:SLI 指标应该反映系统的实际性能和可用性,同时采集和计算过程尽量减少对系统的侵入,对于通用型指标可以组装为SLI规则和模版。例如,选择可以通过现有监控工具轻松获取的响应时间或错误率指标。
计算和采集:优先选择可以简单采集且能够正确、准确量化的指标。SLI 的统计可以在用户端(Client-side)和服务提供方(Server-side)进行,常见的统计方式包括客户端埋点数据上报、服务端日志采集分析、探针巡检、时序数据库指标采集等。目前各大厂或云服务厂商都有成熟的中间件或产品方案,例如ARMS;或是基于开源的Prometheus、HertzBeat等等二次开发搭建,进行在线或离线的指标采集和计算聚合。然而,无论采用何种方式,指标采集过程都应避免对服务性能和可用性产生负面影响。确保监控工具和策略设计规范,避免在采集数据时影响服务质量本身。
4.2 SLO计算和聚合模型
SLO的通用计算模型一般由SLI、服务周期、服务拓扑链路组成。根据服务自身场景定义出不同维度的SLI并采集计算后,可以汇集出SLO的情况。SLO的计算和聚合规则通常如下:
小周期评判:将服务周期(通常是自然月)拆分为多个小周期,以“服务可用性99.95%”这一SLO为例来说,周期性地计算小周期中的服务可用时长是否达成99.95%占比,如果未达到,则标记此周期不可用。考虑到SLI的数据分析粒度和趋势平滑性,小周期的设定时长通常不高于30s。
计算达成时间占比:计算整个服务周期N内,达标小周期时间的占比,从而得到服务的实际SLO水位:
SLO = ∑ SLI达标小周期时长 / 服务周期总时长
SLO拓扑聚合:如果服务涉及到多条链路,每条链路可拆分多个子服务,并对应有其SLI、SLO,则需要聚合出服务的总SLO
-
串联型:服务拓扑链路中,各服务是串型依赖关系,某一子服务出现不可用,将导致整个服务不可用。以服务可用性为例,串联服务可用性计算公式为:
串联服务可用性 = 子服务1可用率 * 子服务2可用率 * ....
-
并联型:服务拓扑链路中,不存在单点依赖,某一子服务不可用不影响整体服务可用性。以服务可用性为例,串联服务可用性计算公式为:
并联型服务可用性 = 1 - (子服务1不可用率 * 子服务2不可用率 * ...)
-
混合型:目前多数云产品都是以混合型的方式提供产品SLA,服务链路中同时存在串联和并行拓扑。此时,服务可用性计算依赖具体的拓扑链路分析,如图4所示。可以看出,拓扑链路中横向增加单点依赖子服务会导致SLA降低,而纵向增加并行冗余服务,则会提高SLA,同时冗余的维护成本也会相应增加。
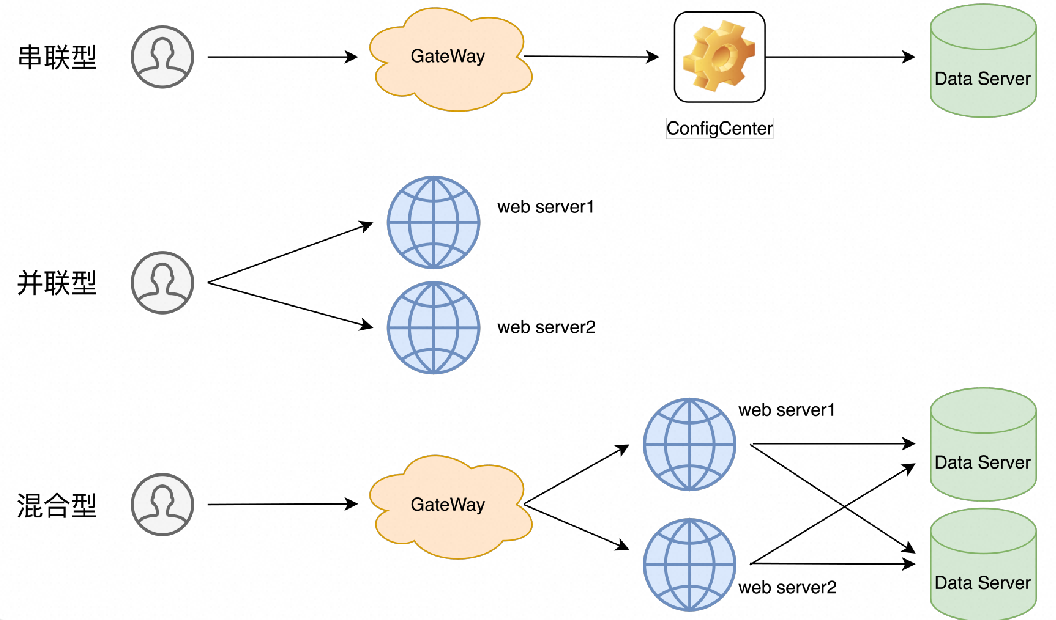
图5 SLA拓扑类型举例
集群SLO计算:多数时候服务以集群形式对客户提供访问,假定集群中每个实例在流量路由和SLO链路上是完全独立的,则可分开计算每个集群的SLO。对于单个集群,假设集群由N个实例节点组成,则可参照小周期的方式计算特定时间片内的集群SLO:
集群SLO = 1 - ∑ SLI未达标实例数 / 集群总实例数
当然,以上只是一个简化的模型,真正的服务链路场景要复杂得多,因此需要因地制宜进行SLO的建模和计算。
4.3 设定SLO阈值和分级告警
在梳理出系统需要关注哪些SLI和量化SLO后,需要考虑一个现实的问题,SLO的阈值应该如何设置?一般而言,SLO阈值确定需要包括但不限于以下规则:
灵活应对变化:首先要认识到,阈值设置不存在银弹,并没有“一劳永逸”的解决方案。由于服务系统的状态和客户需求会随时间发生变化,SLO 阈值应是一个动态调整修正的过程。这意味着需要不断监测和修正,以确保其始终贴合实际情况。
基于实际性能分级设定阈值:确定 SLO 阈值时,应基于系统的当前实际性能水平。设定阈值时不能过于保守,以免低于系统能力,也不能过于激进,做出难以实现的承诺。在设定阈值前,应对系统进行充分的测试和验证,以了解其在长期和高压力条件下的表现。此外,应留有一定的安全空间,使内部的实际 SLO 略高于向外承诺的 SLO。一般来说,需要根据业务实际情况设定warning,critical和urgent三级告警,并配置相关触发动作。
结合客户场景进行优化:SLO 阈值的设定需考虑服务的实际客户业务场景、基数和业务价值,而不仅仅是基于系统当前性能和指标达成的小数点数位。例如,在电商交易场景中,如果系统支持单日 99.99% 的订单成功率,而这意味着100w订单中就有 100 笔失败订单,需要分析这些失败订单的发生原因、时段和用户影响,判断是否需要调整 SLO 并升级系统架构。同样,对于网站请求延时指标,若设定 p99 延时为 1 秒,而在 1 亿次请求中有 10 万次超过 1 秒,如果这些请求对应的是延时敏感的用户群,则尽管符合 SLA 的阈值设定,SLO 可能仍需优化。
4.4 错误预算
设定完SLO阈值,在系统开始提供服务之后,SRE团队通常需要密切关注一个重要指标:错误预算(Error Budget ),它不仅反映了服务SLO的履行情况,还对团队的开发策略起着关键调节作用:
错误预算量化了在特定时间范围内可接受的服务失效或不符合服务水平目标(SLO)的程度,其计算方式依赖于SLO:
-
计算方式:服务周期窗口总值 *(1 - SLO)
例如,对于服务可用性99.99%这一SLO,则服务周期内错误预算为:服务周期总时间 * (1 - 99.99%)
协调与平衡:错误预算为团队提供了在服务维护和功能开发之间做出平衡的依据。若错误预算未被耗尽,团队可以在保证可靠性前提下进行更多的创新和功能开发,否则团队需避免任何可能突破 SLO 的功能升级或变更,以规避风险。

图6 错误预算如何平衡服务的稳定性和迭代
监控与反馈: 定期监控和评估错误预算的使用情况,确保团队能够及时应对服务质量的偏差,并及时做出相应的改进措施。例如,服务投入生产环境不足一周就消耗了30%的错误预算,那么开发团队需要及时对服务架构的合理性做出审视,至少要提前做好突破SLO的兜底应对链路,再寻求合适时机对服务进行敏捷的升级变更。
4.5 考虑成本和收益
当系统平稳持续运行一段时间后,客户业务诉求可能会(一定会)迎来变化。当判断决策需要为此调整SLO时,应当谨慎考虑投入成本和收益的比例关系。需要提高SLO阈值标准时,通常需要分析当前系统现状无法满足的原因:
历史技术债:系统当前架构设计存在既有缺陷
新的诉求和挑战:客户基于场景协商提出了更高要求
同时,系统地梳理成本投入项:
基础设施成本: 评估主要系统和服务所需的硬件、软件和网络资源,包括云服务费用和维护成本。
人力资源成本: 计算与服务交付相关的人员成本,包括运维团队的工资、培训费用以及人员流动带来的潜在成本。
运营成本: 分析系统投入生产运行中的开销,如监控工具、备份兜底链路等。
过程中尽量遵循一个原则:增加维护资源和成本来提高服务质量带来的收益应大于将资源投入到其他地方带来的收益。例如,对于公司内部服务于业务的中台服务,服务可用性从99.99%提高到99.999%所需要的资源和带来的业务价值、服务业务数的增量之比,是决定该服务是否投入资源进行提升改造的核心判断准则。当效益比过低,则应当考虑其他达成业务目标的路径。当资源有限时,应当划分不同级别的业务,对重点业务倾斜资源进行高SLA保障。同时也要考虑不同客户/业务群体需求水位不一致、服务费存在差别(对外商业化时)的客观情况,提供分档位的SLA。
云消息产品SLA调研与拟定在明确基础SLA定义要素和基本准则后,为了对要维护的消息中间件服务进行SLA制定和保障,笔者分别调研了主流云厂商用于商业化的消息产品公示SLA、部分阿里内部消息云服务的监控SLI情况,以作为参考。本节所有调研内容均截止于2024年12月。
▐ 1. 主流云厂商消息产品SLA中使用的服务指标(SLI)和水位
服务可用性
截止到2024年12月,笔者调研了海外2家主流云服务厂商和国内8家云服务厂商的核心消息云产品,所有数据均来自于各家云产品官网开放公示的SLA协议,已模糊化所有关键名称、版本信息,所有描述均以消息服务/实例代指,我们先在下表进行对比:
云消息产品归属 | 服务可用性 | |||
承诺指标水位 | 服务周期 | 服务不可用定义 | 排除豁免情形条款枚举 | |
国内厂商A | 基础版99.95% 升级版99.99% | 自然月 | 当某一分钟内,客户所有试图与指定的消息实例建立连接失败,或调用指定API进行消息生产、消息消费和消息确认的请求均失败 | 因下述原因导致的服务不可用时长,不计入服务不可用分钟数: (1)因客户自身原因引起消息投递延迟,包括但不限于客户消费处理慢导致消息堆积; (2)因客户自身原因引起定时消息误差,包括但不限于服务器时钟不一致、时区不一致所引起的误差; (3)预先通知客户后进行系统维护所引起的,包括割接、维修、升级和模拟故障演练; (4)任何服务所属设备以外的网络、设备故障或配置调整引起的; (5)客户的应用程序或数据信息受到黑客攻击而引起的; (6)客户维护不当或保密不当致使数据、口令、密码等丢失或泄漏所引起的; (7)客户的疏忽或由客户授权的操作所引起的; (8)客户未遵循服务产品使用文档或使用建议引起的; (9)不可抗力引起的。 |
国内厂商B | 99.95% | 自然月 | (1)当某一分钟内,客户所有试图调用消息队列 指定实例下 Topic 的 API的连续尝试均失败;(2)消息投递延迟超过 5 分钟以上。 | |
国内厂商C | 99.95% | 自然月 | 在某一分钟内,客户端所有试图调用消息队列指定的 API 进行消息生产/发布、消息消费以及消息确认的请求均失败。 | |
国内厂商D | 99.95% | 自然月 | 因服务提供方原因分布式消息服务完全中止,连续超过一分钟则视为该分钟内分布式消息服务不可用,低于一分钟的不可用时间不计算在内。 | |
国内厂商E | 99.95% | 自然月 | 当某一分钟内,因服务提供方原因消息实例服务完全中止,连续超过一分钟则视为该分钟内消息服务不可用,低于一分钟的不可用时间不计算在内。 | |
国内厂商F | 99.95% | 自然月 | 当某一分钟内,客户所有试图调用消息队列指定 Topic 的 API的连续尝试均失败,或者消息投递延迟超过 5 分钟以上,以及定时消息误差超过 5 分钟以上,则视为该时间段内指定 Topic 的服务不可用。 | |
国内厂商G | 99.95% | 自然月 | 当某一分钟内,客户所有试图与指定的消息队列实例建立连接的连续尝试均失败,或者消息队列消息投递延时超过5分钟,以及定时消息误差超过5分钟,则视为该分钟内该消息队列实例服务不可用。 | |
海外厂商H | 99.9% | Monthly |
| (i) caused by factors outside of our reasonable control, including any force majeure event or Internet access or related problems beyond the demarcation point of the applicable Included Service; (ii) that result from any voluntary actions or inactions from you; (iii) that result from you not following the best practices described in the applicable Included Service’s Developer Guide on the our Site; (iv) that result from your equipment, software or other technology; or (v) arising from our suspension or termination of your right to use the applicable Included Service in accordance with the Agreement |
海外厂商I | 99.9% | Monthly |
| |
总结,大部分厂商的云消息产品在对外发布的SLA协议中均使用了服务可用性这一指标,服务周期一般是自然月(与付费周期一致),并采用了同一计算公式计算到分钟级别,从单实例或客户账户维度进行统计计算:
服务周期总分钟数 = 服务周期内的总天数 × 24(小时)× 60(分钟)
服务可用性 =(服务周期总分钟数 - 服务周期不可用分钟数)/ 服务周期总分钟数 × 100%
从对比可知,截止2024年12月,国内大多数云消息服务厂商将服务可用性SLO定在了99.95%这一水位,按照1.3节的服务可用性表格计算,意味着对单个客户来说,每个月最多有21.6分钟的错误预算,超出客户将可发起SLA约定中的赔偿流程。此外,部分厂商定制化后的消息产品将可用性SLI定义到了更细级别,可供参考,以下均按时间片进行小周期计算:
发送可用性计算方式:小周期时间内业务调用发送接口成功ACK的消息数 / 周期内总消息数
消费可用性计算方式:(小周期时间 - 周期内消费组积压且此时无客户端消费时间)/ 小周期时间
集群可用性计算方式:(小周期时间 - 周期内broker机器宕机时间)/ 小周期时间
数据可靠性
截止到2024年12月,部分云消息产品的公开SLA中提及了数据可靠性相关的指标或描述,但未明确提及计算方式:
云消息产品归属 | 数据可靠性 |
国内云厂商A | 99.99999999% |
国内云厂商C | 99.999999% |
国内云厂商J | —— |
国内云厂商K | 99.99999% |
其中,上述部分产品SLA中对于数据可靠性的描述片段如下:
云厂商J消息产品 依赖机器本地磁盘存储,不承诺数据可靠性,只保证消息尽量不丢失。可能会导致消息丢失的原因如下:
物理机故障和文件系统故障会导致积压消息丢失。(已写入消息队列,但还未消费的消息会因为物理机和文件系统的故障导致这些数据无法恢复)
机器掉电会导致未刷盘的消息丢失。(已写入内存,但还未持久化到磁盘的数据会因为机器的掉电而丢失)
云厂商K消息产品 依赖于云存储 Y 服务存储消息,提供99.99999%的数据可靠性。但以下场景导致的消息丢失将列入排除豁免条款:
消息投递次数超过系统的限制
系统 BUG 或误操作导致云存储 Y 的数据库数据被删除
可以看出,消息产品的数据可靠性极大依赖于存储介质/服务的可靠性SLA,部分软件或客户人为故障被纳入了排除条款。如果不考虑消息服务的软件层面和部署模式,要达到更高的数据可靠性就意味着对硬件存储介质和存储服务的要求更高,相应的也需要付出更多成本。尽管部分云消息服务产品SLA中未提及可靠性指标和计算方式,但一般都可参考1.3节SLA常见指标-数据可靠性计算模型进行量化估算。
▐ 2. 阿里内部部分云消息产品SLI监控的视角参考
笔者还调研了集团内使用的几款消息服务SLI和SLO情况,以下表格涉及的指标项来源于集团内部服务SLA管理平台,这里隐去服务名、具体数值、计算采集方式和带有业务属性的监控项,只列出部分属于纯粹消息中间件属性的通用型SLI,不代表服务完整情况。通过下表可以一窥集团内主要消息服务对稳定性的一些关注视角,从而作为参考。这里将它们分为系统性能SLI和可用性SLI两大类:
性能SLI | 可用性SLI |
消息发送RT | 消息发送成功率 |
消息接收RT | 消息接收成功率 |
总生产RT | 总消费成功率 |
总消费RT | 总生产成功率 |
总消费QPS | 探针成功率(细分) |
总生产QPS | 客户端建联成功率 |
推送QPS | 客户端建联RT |
发送QPS | 控制台页面可用性 |
普通消息投递延迟(探针) | |
延迟消息投递延迟(探针) |
▐ 3. 拟定一份SLA
总结完SLA的基础概念和调研了国内外云消息产品的SLA后,依据1.2节和2.1节的内容,我们可以尝试拟定出一份消息服务的SLA草稿,如下:
XX消息服务等级协议
本SLA的生效日期为xxxx年xx月xx日
本服务等级协议(Service Level Agreement,简称 “SLA”)规定了xx方向xx方提供的xxx版消息服务(简称“消息服务”)的服务可用性等级指标及赔偿方案。xxx版消息服务是指xxxxx(服务范畴介绍)。
1. 基本定义
消息实例:消息实例是虚拟化的独立运行的消息队列运行环境。
服务周期:一个服务周期为一个自然月。
服务周期总分钟数:按照服务周期内的天数 ╳ 24(小时)╳ 60(分钟)计算。
服务不可用分钟数:当某一分钟内,客户所有试图与指定的消息服务实例建立连接的尝试均失败,或调用指定API进行消息生产、消息消费以及消费确认的请求均失败,则视为该分钟内该消息实例服务不可用。在一个服务周期内,消息实例不可用分钟数之和即服务不可用分钟数。
月度服务费用计算:按一个自然月中,客户就单个消息实例所支付的月度服务费用总额,如果客户一次性支付了多个月份的服务费用,则将按照所购买的月数或使用量比例分摊计算月度服务费用。
2.服务等级目标
2.1 服务可用性
服务可用性以单个实例为维度进行统计,按照如下方式计算:
服务可用性 = (服务周期总分钟数-服务不可用分钟数)/服务周期总分钟数×100%
我方承诺消息服务的单实例服务可用性不低于xx.xx%。
2.2 排除条款
因下述原因导致的服务不可用时长,不计入服务不可用分钟数:因客户自身原因引起消息投递延迟,包括但不限于客户消费处理慢导致消息堆积;因客户自身原因引起定时消息误差,包括但不限于服务器时钟不一致、时区不一致所引起的误差;我方预先通知客户后进行系统维护所引起的,包括割接、维修、升级和模拟故障演练;任何我方所属设备以外的网络、设备故障或配置调整引起的;客户维护不当或保密不当致使数据、口令、密码等丢失或泄漏所引起的;客户未遵循我方产品使用文档或使用建议引起的;其他不可抗力引起的;..............
3. 赔偿方案
如消息服务未达到2.1节中的承诺且不处于2.2节中的排除情形,客户须在承诺未达标月份的N日(赔偿发起有效期)内,根据本节条款发起赔偿流程,以下计算按照单消息实例纬度进行:
当X% ≤ 服务可用性 < Y% ,以xx形式赔偿月度服务费的xx%
..........
4.变更与终止
我方有权对本SLA条款作出修改。如本 SLA 条款有任何修改,将提前通知使用方。如您不同意对SLA所做的修改,您有权停止使用消息服务,如您继续使用则视为您接受修改后的SLA。
消息中间件SLA思考心得▐ 3.1 从消息生命周期链路考虑SLI的关注视角
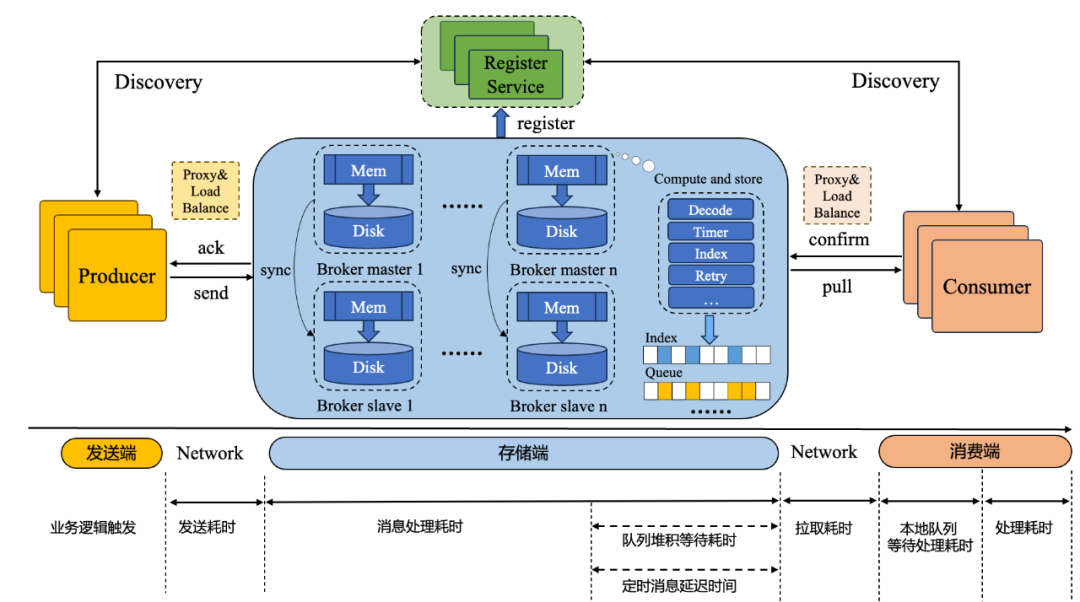
图7 一般的消息生命周期链路
图7 绘制了通用型消息中间件的一般消息生命周期链路,综合上述调研和SLA基本原则,我们可知维护一款消息中间件产品应该关注哪些服务指标。从业务使用方的角度无非分两类,也是业务使用方感知最明显的两类,需要重点关注:
发送端视角:发送成功率,单机发送QPS,单机发送吞吐,发送RT,
消费端视角:消费成功率,单机消费QPS,单机消费吞吐,消费RT(消息处理到消费的耗时),
以上可归类为面向消息服务使用方的服务可用性(可监控到发送端与消费端各api的可用性、成功率),而在消息存储端,SRE需要关注一些服务基础项:
数据可靠性、消息存储时间、消息写入耗时、消息处理延时、消息队列堆积、确认队列长度、内存提交rt、刷盘rt等等
对于不同业务集群和高级消息特性支持集群,应设计单独的监控指标,以保障业务的平稳运行
对内部SRE和外部客户提供消息的轨迹(trace)查询等控制台功能
以数据可靠性为例,它主要考虑三部分:从消息发送模式上来说,同步模式比异步模式更为可靠,因为其保证消息落盘之后才返回给客户端ACK,但代价是性能相对低下;从存储方式来说,各类消息中间件产品多数采用云/磁盘文件存储方式,因此其数据可靠性多数取决于存储磁盘的可靠性,因此大多数云消息服务SLA中提到数据可靠性时,都离不开其依托的存储服务SLA;此外,一般消息集群支持多种集群模式部署(包括一主多备、多主多备、RokectMQ的DLedger模式等等),均通过数据冗余的方式提高了数据可靠性。但是,类似基于Raft协议或DLedger这类定制改造的集群架构模式,为了保障数据可靠性和数据一致性,通常需要在性能和资源消耗方面有一定牺牲。所以,在制定消息服务的数据可靠性SLI和SLO时,应该基于实际业务价值和资源情况做出合适的取舍。
特别的,对于一些高级消息特性,例如顺序消息、定时消息、事务消息等需要根据场景设计SLI,例如定时消息的定时误差,顺序消息的可用性等。在顺序消息场景下,以RocketMQ为例,其会将顺序关系的消息路由到一台broker上进行存储和消费,因此单台broker不可用将会影响整个消息集群的顺序消息可用性,其保障要求要比普通消息集群的可用性更为严苛。此外,由于消息中间件本身带有存储属性,但服务本身对消费者侧的管控和治理能力偏弱,可能经常出现由于消费者侧原因导致的消息堆积与消息失败重投case:
对于消息堆积场景,消息服务需要重点保障数据存储的可靠性,确保消息完整不会丢失(或是给出明确的存储最大时长SLI),同时应向客户提供明确的Metrics指标(消费速率、堆积量等SLI)反映各队列的堆积情况,以便其进行消费速率和策略的调整。同时,消息也不保证提供无限制的堆积存储,应建立自身的存储保护和清理机制,对SLA消费方明确声明消息存储的最大冗余存储时间,以便其规划设计业务策略。
对于消费失败重投场景,消息服务则需要在SLA中明确定义消息的最大重投次数、重投策略和间隔
最后,除了面向服务质量的SLI,消息服务机器资源的基础性能指标也需要通过Sunfire等监控服务密切关注,包括CPU水位、FullGC次数、内存使用率、磁盘IO次数、网络RT、线程负载等等。
▐ 3.2 建立高效的 SLI 数据采集、SLO 监控报警及故障复盘机制
在消息运维的日常工作中,精确的 SLI 数据采集和及时的 SLO 监控报警是"生命线"。一套好的SLI采集和SLO报警机制能够及时call报问题和故障定位,让运维同学及时响应。不正确的采集监控,不仅可能掩盖问题,还会误导和阻碍故障的定位和复盘。所以,总结起来要做到如下四点:
SLI 数据采集的优化:在完成消息服务相关的 SLI 确认后,需结合系统当前的性能和架构,确保采集频率的合理化和数据打点的精准性。举例来说,对于消息延迟和吞吐量等关键指标,应设定适当的采样间隔和波动容忍度,以确保分析结果能够准确反映系统运行状态。
SLO 异常响应策略:当消息服务或上下游变更引发 SLO 异常时,尽量做到采用 "1-5-10" 响应,即在 1 分钟内识别故障,5 分钟内进行响应与初步定位,并在 10 分钟内尝试恢复服务。面对紧急情况,优先考虑回滚到稳定版本或是隔离/屏蔽问题机器(例如从服务发现模块中屏蔽问题broker,阻断流量),以迅速恢复服务可用性,而不是花费时间在故障根因分析上,这能够有效缩短消息服务的停机时间。
故障复盘及预防措施:一旦故障恢复,需立即进行详细复盘,分析原因并制定防护措施。对于服务的隔离和限流策略,应重点关注上游业务的异常流量对消息服务的影响。通过在接口层增加熔断和限流机制,防止因异常流量导致的进一步 SLO 波动。
做好监控报警的治理和优化:报警的设置应注重服务核心链路与关键功能的覆盖率,而非监控项数量的堆积,应定期review当前系统的监控告警,并对不再适用的监控项治理或下线。阈值设定上,避免过度敏感,防止产生大量非关键警报噪音,导致运维人员疲劳和忽视真正需要注意的问题。同时,阈值也不应过于苛刻,以至于故障在早期发生时被忽略,直到被放大。适当的自适应阈值和动态调整机制,可以帮助在流量高峰时段前及时发出警报,以提前识别潜在风险。
▐ 3.3 动态调整和前瞻性规划 SLO
在确定 SLI 后,我们需要深入理解 SLA 是怎样与当前系统状态和业务场景相匹配的,并需要评估当前的 SLO 是否真正满足业务的需求。仅仅依赖于现有的系统状态和业务场景制定 SLO 会导致它过时,因此需要开发和运维同学具备前瞻性和灵活性,具体来说:
预见未来业务需求拓展: 在制定 SLA 时,应将潜在的业务增长和变化纳入考量。另一方面也需谨慎评估接入业务需求的合理性,对于消息服务中台来说,评估方案成本与 SLO 的实际可行性也是必不可少的。
灵活调整能力: 为了应对不断变化的业务环境,SLO 应具备动态调整的能力。通过定期审视历史数据和运维成本,可以根据业务的变化及时优化服务水平目标。这种灵活性不仅能够帮助我们保持对业务需求的敏感性,还能有效优化开发人力资源的分配和使用。
适应技术升级:随着开源消息中间件不断演进,新技术和新架构的出现为消息服务提供了更多可能性。定期审视现有消息服务的特性和支持能力,确保它在消息中间件的技术演进中保持架构合理性和服务可持续性。例如,定期关注 Kafka、RocketMQ 等新架构特性和最佳实践,考虑是否有可借鉴的模式来提高已有服务的性能和可靠性。
▐ 3.4 对外和对内SLA的差异
通过前面调研可知,在制定 SLA时,外部和内部协议之间存在一些差异:
对外 SLA 的严谨性:对外SLA由于涉及公司间的商业利益,一般表述比较严谨,协议组成要素完整,特别是关于SLI的计算和不满足SLO时的经济赔偿方案,并且包含正式、规范的反馈和评估机制,以维护良好的客户信任关系和商业信誉。
对内 SLA 的灵活性和协作性:内部 SLA 通常是公司内部不同团队之间的约定,服务提供方的SLA是消费方制定其业务保障SLA的基础,如果提供方SLO被打破,则会涉及业务责任上的划分认定。同时,对内SLA反馈机制可以更加灵活,通常依赖于中台团队与接入业务团队之间的协作与沟通。
总之,不论是对内还是对外商业化,一份完整、定义清晰、监测和评估机制建设完善的SLA对服务所链接的双方都是可靠的保障,避免双方在合作过程中对服务的认知和度量没有“拉齐”。
▐ 3.5 以SLA驱动消息中间件的迭代交付
当一个产品提到SLA,通常意味着它是一个平台型、长期的、服务性质的产品,有着持续的客户需求和来自上游产品的稳定性依赖。回到消息服务建设自身,建设和运维平台消息服务,本质上就是在为消息服务链接的上、下游客户双方交付一份SLA,让所有接入方对消息服务"宕机不可用概率多大、数据可不可靠、性能如何、支持什么特性"有一个清晰可量化的认知。所以,为了更好地承接业务发展和服务业务客户,消息服务这类基础中间件服务的迭代形态最终要以SLA来驱动规划。对于这样一个串联起消息发送方和消费方的平台型中间件,其稳定性建设不可轻视:如何给到接入业务明确的SLA标准和运行数据支撑,构建消息功能代码<->测试<->SLI采集<->SLO告警<->SLA交付的双向反馈链路,早于业务发现问题和隐患,确定服务重点优化方向,是需要我们未来持续投入保障的建设重点和挑战。

参考文献
[1] https://aws.amazon.com/what-is/service-level-agreement/?nc1=h_ls
[2] https://learn.microsoft.com/zh-cn/training/saas/saas-foundations/
6-service-level-agreement-service-level-objective
[3] https://newrelic.com/blog/best-practices/best-practices-for-setting-slos-and-slis-for-modern-complex-systems
[4] https://www.ruilog.com/notebook/view/b9072993a920.html
[5] Cidon A, Rumble S, Stutsman R, et al. Copysets: Reducing the frequency of data loss in cloud storage[C]//2013 USENIX Annual Technical Conference (USENIX ATC 13). 2013: 37-48.
[6] https://en.wikipedia.org/wiki/Poisson_distribution
[7] https://juejin.cn/post/7165326932299481101?spm=ata.21736010.0.0.
a9537536Zv0yNm&from=search-suggest
[8] https://www.dynatrace.com/news/blog/7-steps-to-identify-and-
implement-effective-slos/
[9] https://rocketmq.apache.org/zh/
¤ 拓展阅读 ¤


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









