







我们是淘天业务技术内容AI团队,负责运用最新的生成式AI能力,挖掘淘宝核心用户场景(首页信息流、搜索、用增、消息等)的用户痛点问题,通过AIGC内容生成、智能交互等方式,改善用户购物体验,降低平台&商家经营门槛。团队主要研究可控内容生成、多模态大模型、人格化Agent等技术域,在图像生成、视频生成、多模态大模型等前沿技术领域有广泛的布局,并在巨浪、信息流、搜索等淘天核心内容业务场景进行深入的业务合作。团队近3年内团队已累计发表CCF-A类会议和期刊论文20余篇,包含CVPR、ICCV、NeurIPS、ICLR等业界顶会。
仅在刚公布的AAAI 2025,我们就一举斩获了4篇论文,涵盖参考图控制生成、图文联合生成、大语言模型等核心前沿技术领域。我们诚挚欢迎优秀人才关注和加入!下面介绍在即将过去的2024年,团队录用论文情况。
[1] Resolving Multi-Condition Confusion for Finetuning-Free Personalized Image Generation. In AAAI 2025.
中文标题:《缓解参考图生成中的多条件冲突问题》
作者:Qihan Huang, Siming Fu, Jinlong Liu, Hao Jiang, Yipeng Yu, Jie Song
下载链接:
https://arxiv.org/abs/2409.17920
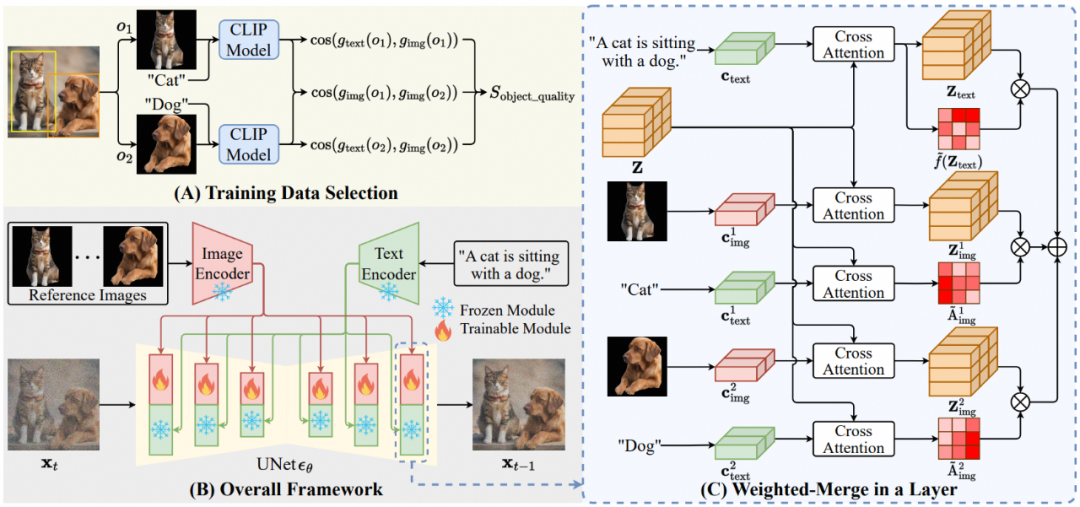
简介:传统个性化图像生成的方法在单张图像同时生成多个物体时,通常面临物体信息混淆的问题(比如,物体1的参考信息被加到物体2上)。为了解决这个目标混淆的问题,本文研究了潜在图像特征在扩散模型中与目标对象的不同位置的相关性,并因此提出了一种加权合并方法,将多个参考图像特征合并到相应的对象中。接下来,我们将这种加权合并方法整合到现有的预训练模型中,并在基于开源SA1B数据集构建的多目标数据集上继续训练该模型。该工作可以只在8卡上训练5小时就达到多物体参考图生成的SOTA性能。
[2] MARS: Mixture of Auto-Regressive Models for Fine-grained Text-to-image Synthesis. In AAAI 2025.
中文标题:《MARS:基于混合自回归模型的图文联合生成方法》
作者:Wanggui He, Siming Fu, Mushui Liu, Xierui Wang, Wenyi Xiao, Fangxun Shu, Yi Wang, Lei Zhang, Zhelun Yu, Haoyuan Li, Ziwei Huang, LeiLei Gan, Hao Jiang
下载链接:
https://arxiv.org/abs/2407.07614
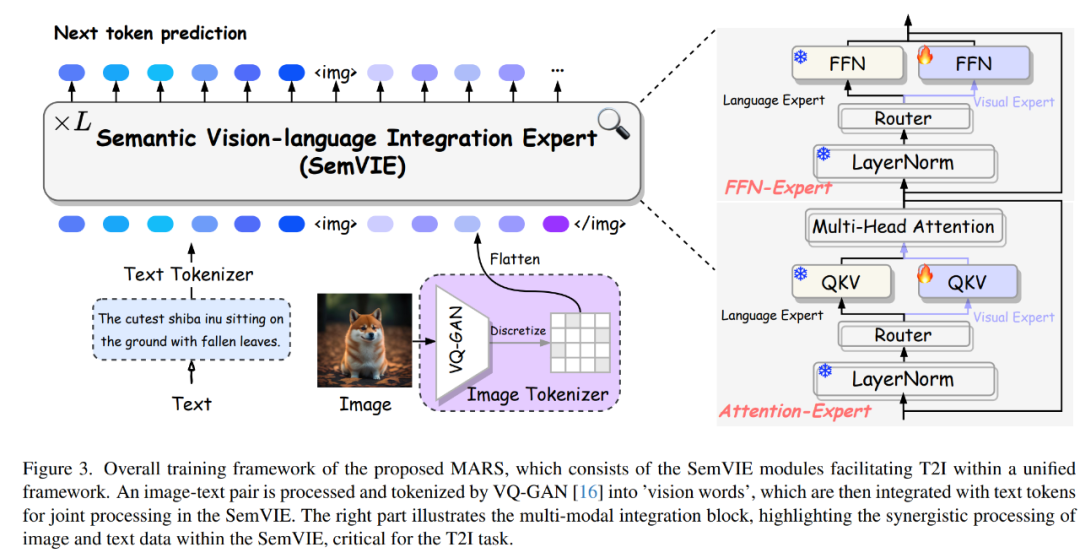
简介:自回归模型在语言生成领域取得了显著进展,它们采用next token predition的方式建模文本序列。为了构建统一的图文联合生成模型,即一个接受文本和图像输入和并同时能输出文本和图像的模型。我们将图片表示成离散token的形式,使得它可以像文本一样被预测。我们提出了MARS,这是一个新颖的在文本和图片两种模态上实现any2any范式的统一多模态生成模型。MARS通过创新性地集成了一个名为SemVIE的模块,该模块在预训练LLM的注意力机制中嵌入了视觉专家系统,旨在在保持NLP能力的同时,增强模型的视觉生成和理解能力。这种巧妙的集成赋予了MARS在T2I生成和图像-文本联合合成任务中更高的灵活性,并为其在更广泛任务中的应用奠定了基础。通过实施多阶段细化训练策略,MARS在遵循指令和生成高质量、细节丰富的图像方面的能力得到了显著提升。MARS在处理复杂自然语言输入方面表现出色,支持英文和中文的双语提示理解与执行。此外,MARS的SOTA性能已经通过MS-COCO基准测试、T2I-CompBench和人类评估等多样化的评估指标得到了充分验证。
[3] Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback. In AAAI 2025.
中文标题:《大型视觉语言模型中的幻觉的检测和缓解方法》
作者:Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
下载链接:
https://arxiv.org/abs/2404.14233
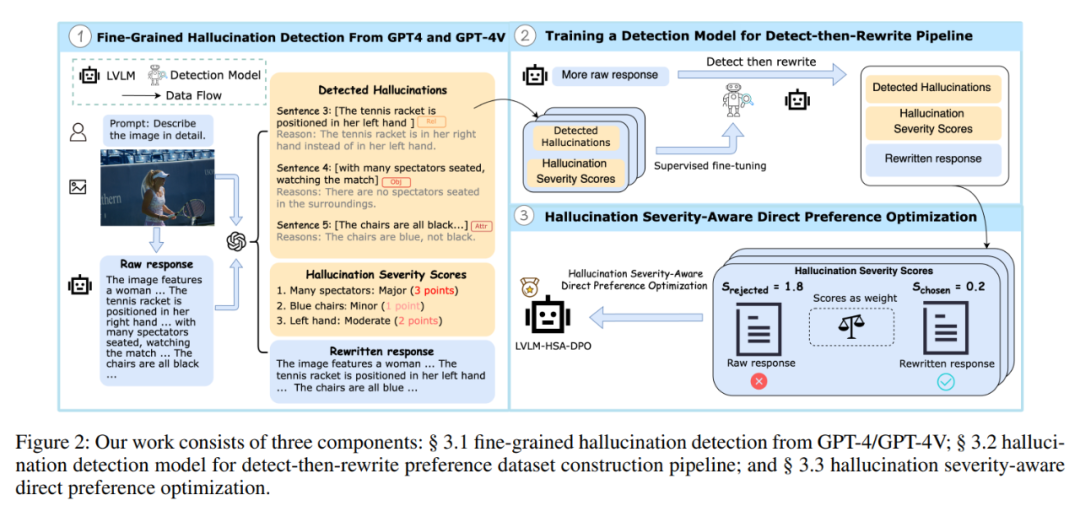
简介:本文探讨了大型视觉语言模型(LVLMs)在生成响应时面临的幻觉现象,即生成内容与上下文不一致的问题。为了解决这一挑战,作者提出了一种通过细粒度AI反馈来检测和减轻幻觉的方法。具体而言,研究者生成了一个句子级别的幻觉标注数据集,训练了相应的检测模型,并提出了检测-重写流程以构建偏好数据集。此外,作者引入了幻觉严重性感知的直接偏好优化(HSA-DPO),优先减轻严重幻觉。实验结果表明,该方法在MHaluBench上达到了新的最高标准,超越了GPT-4V和Gemini,并在AMBER和Object HalBench上分别降低了36.1%和76.3%的幻觉率,显著提升了模型的准确性和可靠性。
[4] D2-DPM: Dual Denoising for Quantized Diffusion Probabilistic Models. In AAAI 2025.
中文标题:《量化扩散概率模型的双重去噪》
作者:Qian Zeng, Jie Song, Han Zheng, Hao Jiang, Mingli Song
下载链接:暂无
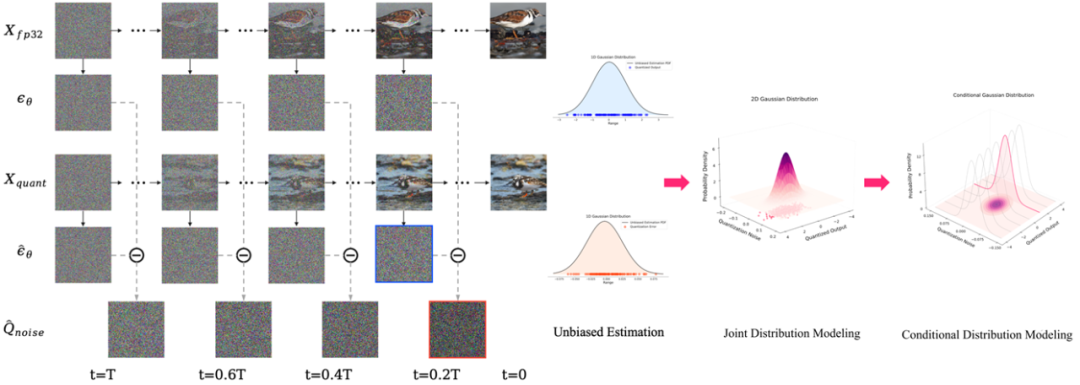
简介:本文通过实证研究分析了量化噪声的高斯属性,并通过建立量化输出与量化噪声的联合分布实现了量化噪声的条件概率建模,最后结合采样方程设计了两种量化噪声校准器。本文提出的D2-DPM是一种双重去噪机制,旨在精确减轻量化噪声对噪声估计网络的不利影响。具体而言,我们首先将量化噪声对采样方程的影响分解为两个组成部分:均值偏差和方差偏差。均值偏差改变了采样方程的漂移系数,影响了轨迹趋势,而方差偏差则放大了扩散系数,影响了采样轨迹的收敛性。因此,所提出的D-DPM旨在在每个时间步去除量化噪声,然后通过逆扩散迭代去除带噪声的样本。实验结果表明,D-DPM在生成质量上表现优越,其FID值低于全精度模型,同时实现了3.99倍的压缩和11.67倍的位运算加速。
[5] FuseAnyPart: Diffusion-Driven Facial Parts Swapping via Multiple Reference Images. In NeurIPS 2024. Spotlight.
中文标题:《FuseAnyPart:扩散模型驱动的基于多参考图的面部局部替换技术》
作者:Zheng Yu, Yaohua Wang, Siying Cui, Aixi Zhang, Wei-Long Zheng, Senzhang Wang
下载链接:
https://arxiv.org/abs/2410.22771
简介:FuseAnyPart 是一种新颖的基于扩散模型的面部局部替换技术,它可以基于多张人脸参考图进行细粒度高可控地进行新人物形象合成。FuseAnyPart 核心创新在于如何有效地在扩散模型的潜在空间中进行特征融合,为此提出了基于掩模的融合模块和基于加法的注入模块,以确保合成自然度高、可控性强的人脸图像。FuseAnyPart 可以实现更精细和个性化的角色设计,这在虚拟角色生成、娱乐、隐私保护等方面有广泛的应用。
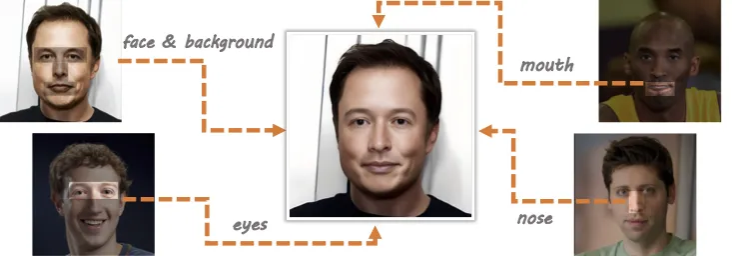
业务场景:在当前业界AIGC人像生成技术上,存在人脸生成效果趋同、差异性不够显著、人脸不够真实的技术难题,影响到人像生成在业务领域的应用。在组内业务方面,需要结合差异性和真实性更高的人脸生成,构建虚拟人形象和视频换衣模板库的模特形象,用于巨浪、主搜等业务场景。当前,FuseAnyPart 正应用于巨浪外投营销视频场景的虚拟人形象的构建,产出的虚拟人讲解营销视频获得巨浪业务的好评。
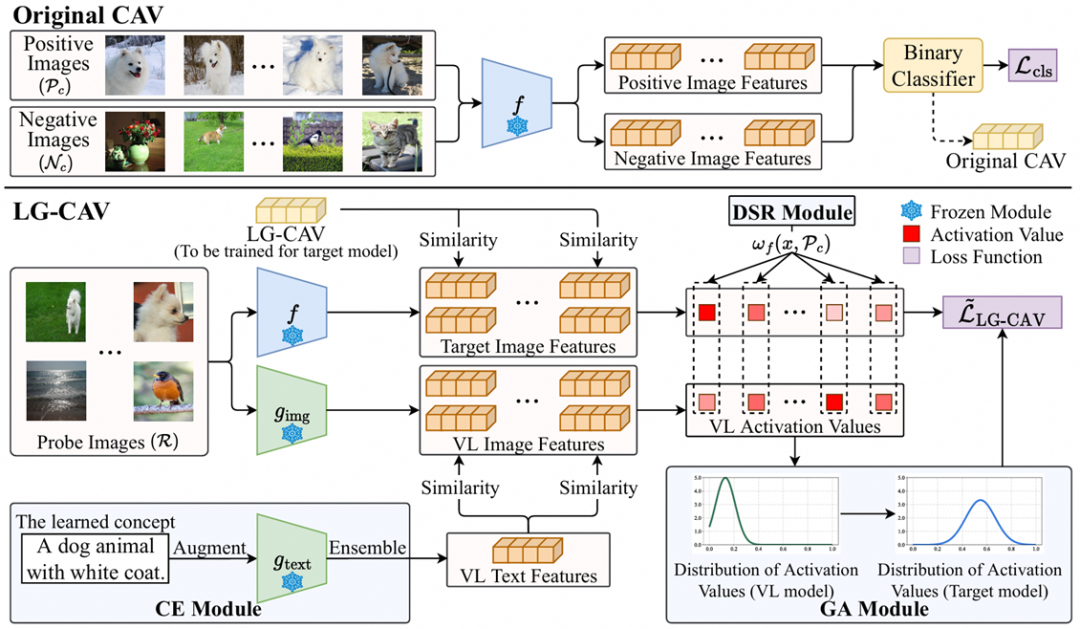
[6] LG-CAV: Train Any Concept Activation Vector with Language Guidance. In NeurIPS 2024.
中文标题:《LG-CAV: 基于语言指引的概念激活向量训练》
作者:Qihan Huang, Jie Song, Mengqi Xue, Haofei Zhang, Bingde Hu, Huiqiong Wang, Hao Jiang, Xingen Wang, Mingli Song
下载链接:
https://arxiv.org/abs/2410.10308
简介:传统视觉模型的训练过程通常处于黑盒状态,难以被人类直接理解和控制。借助于预训练多模态模型(如CLIP模型),我们提出了一种使用自然语言指引进行视觉模型优化的方法。该方法使用多模态模型将人类语言转换为视觉模型中的概念向量(LG-CAV),然后通过纠正视觉模型中的错误的概念关系来优化视觉模型。实验表明,LG-CAV在表达视觉模型内部概念上达到了比现有方法更高的准确率,并可以有效提高ImageNet上预训练模型的准确率。
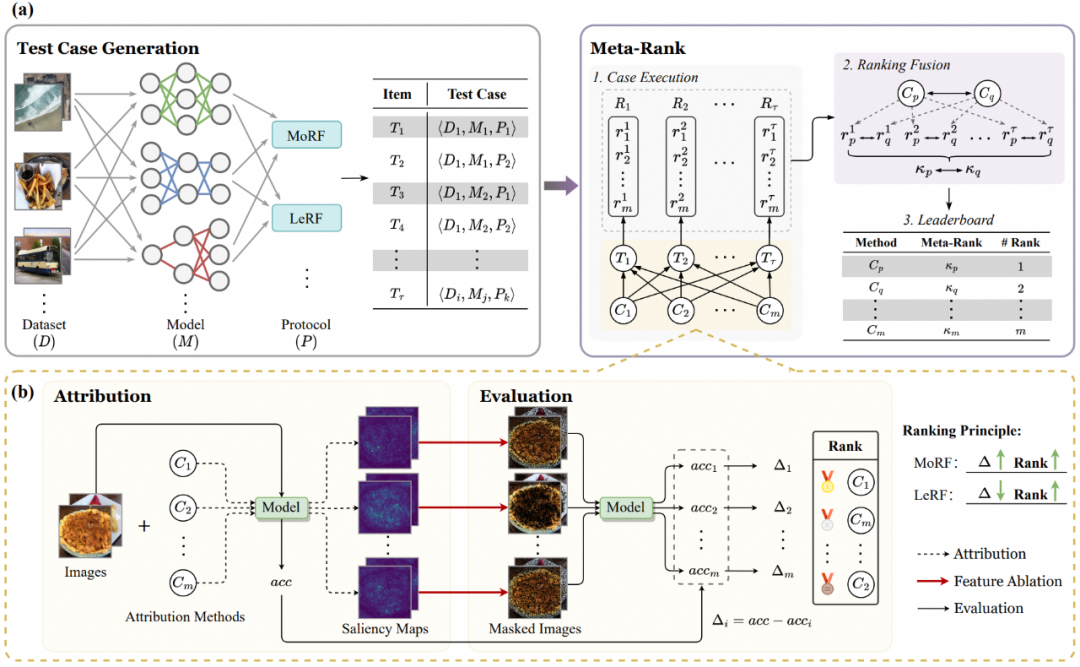
[7] On the Evaluation Consistency of Attribution-based Explanations, In ECCV 2024.
中文标题:《可解释归因方法的一致性研究》
作者:Jiarui Duan, Haoling Li, Haofei Zhang, Hao Jiang, Mengqi Xue, Li Sun, Mingli Song, Jie Song
下载链接:
https://arxiv.org/abs/2407.19471
简介:基于归因的解释在可解释人工智能领域日益受到关注,我们推出了Meta-Rank,这是一个用于在图像领域评估归因方法的开放平台。目前,Meta-Rank使用四个不同的数据集对六种著名模型架构下的八种典范归因方法进行评估,并采用了最相关优先(MoRF)和最不相关优先(LeRF)两种评估协议。本文揭示了评估过程中的多个关键见解,并强调了未来在更广泛模型和数据集上进行严格评估的必要性。
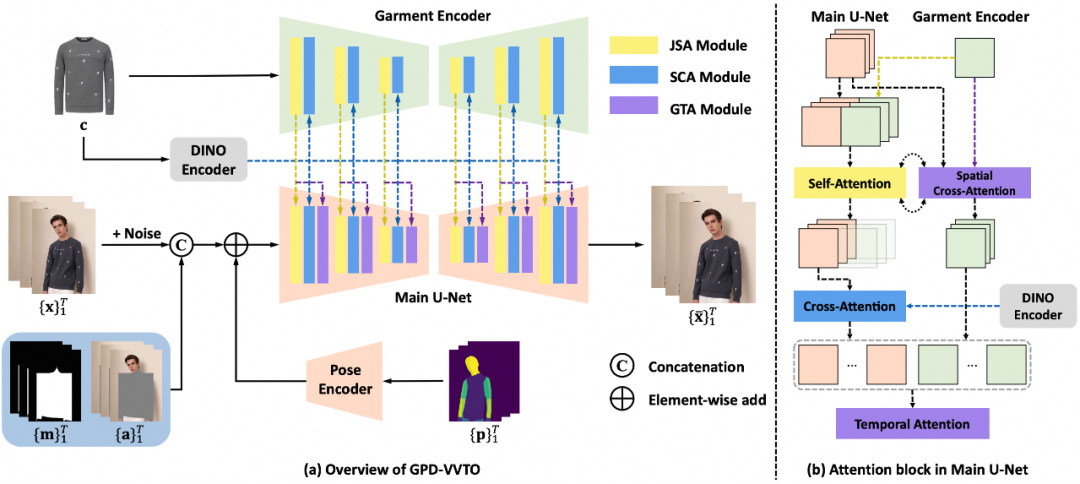
[8] GPD-VVTO: Preserving Garment Details in Video Virtual Try-On. In ACM MM 2024.
中文标题:《GPD-VVTO:保持服饰细节的视频虚拟换衣》
作者:Yuanbin Wang, Weilun Dai, Long Chan, Huanyu Zhou, Aixi Zhang, Si Liu
下载链接:
https://dl.acm.org/doi/pdf/10.1145/3664647.3680701
简介:本文提出了一个端到端的视频换衣模型GPD-VVTO,该方案能够在视频上实现细节丰富、时序一致的换衣效果。GPD-VVTO 架构主要是由一个 UNet 骨干网络所构成。这个特定的网络会将视频噪声潜在表示、无服装视频潜在表示以及二值遮罩序列当作输入内容。与此同时,它还会整合 DensePose 序列所携带的姿态信息。通过服装编码器能够分别提取出服装的局部纹理特征,而借助 DINO 编码器则可以提取出服装的全局语义特征。并且,通过 JSA、SCA 和 GTA 这三个注意力模块,可以将这些提取出来的特征注入到主网络当中,从而得以实现服装细节的迁移。GPD-VVTO在VITON-HD、DressCode等开源图像换衣任务以及VVT和淘内自建视频换衣任务上表现均优于现有工作。
内容AI团队招聘优秀算法同学和研究型实习生!
欢迎投递简历至 xy.jiang@taobao.com
¤ 拓展阅读 ¤


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









