






光伏出力聚类 K-means聚类 时间序列
编程环境:matlab
主题:基于k-means算法的光伏时间序列聚类
主要内容:
该程序是关于大量随机场景下光伏序列聚类与削减的问题,首先,生成了大量光伏随机场景(如图1),其次,在此基础上,基于Kmeans算法,对该大规模场景进行聚类,从而实现大规模场景的削减(图2),最后,依据削减后的典型场景,可作为调度和优化以及评估数据;生成场景保证典型性的同时缩短了模型计算时间。
ID:4829676357984880
浅唱幸福~Q
基于k-means算法的光伏时间序列聚类
摘要:随着光伏发电技术的不断发展,光伏电站的规模越来越大,光伏发电场景也变得越来越复杂。为了有效管理和优化光伏电站的运行,需要对光伏时间序列进行聚类与分析。本文基于k-means算法,对大规模光伏场景进行聚类和削减,以提高典型场景的表征能力和计算效率。
-
引言
随着光伏技术的发展,光伏电站的规模越来越大,光伏发电的场景也日益复杂。为了实现对光伏电站的有效管理和优化,需要对光伏时间序列进行聚类和分析。聚类分析可以将具有相似特征的光伏场景归为同一类别,从而提高对光伏电站运行状态的理解和预测能力。本文基于k-means算法,对大规模光伏场景进行聚类和削减,以便于后续的调度优化和评估分析。 -
光伏时间序列数据的生成与预处理
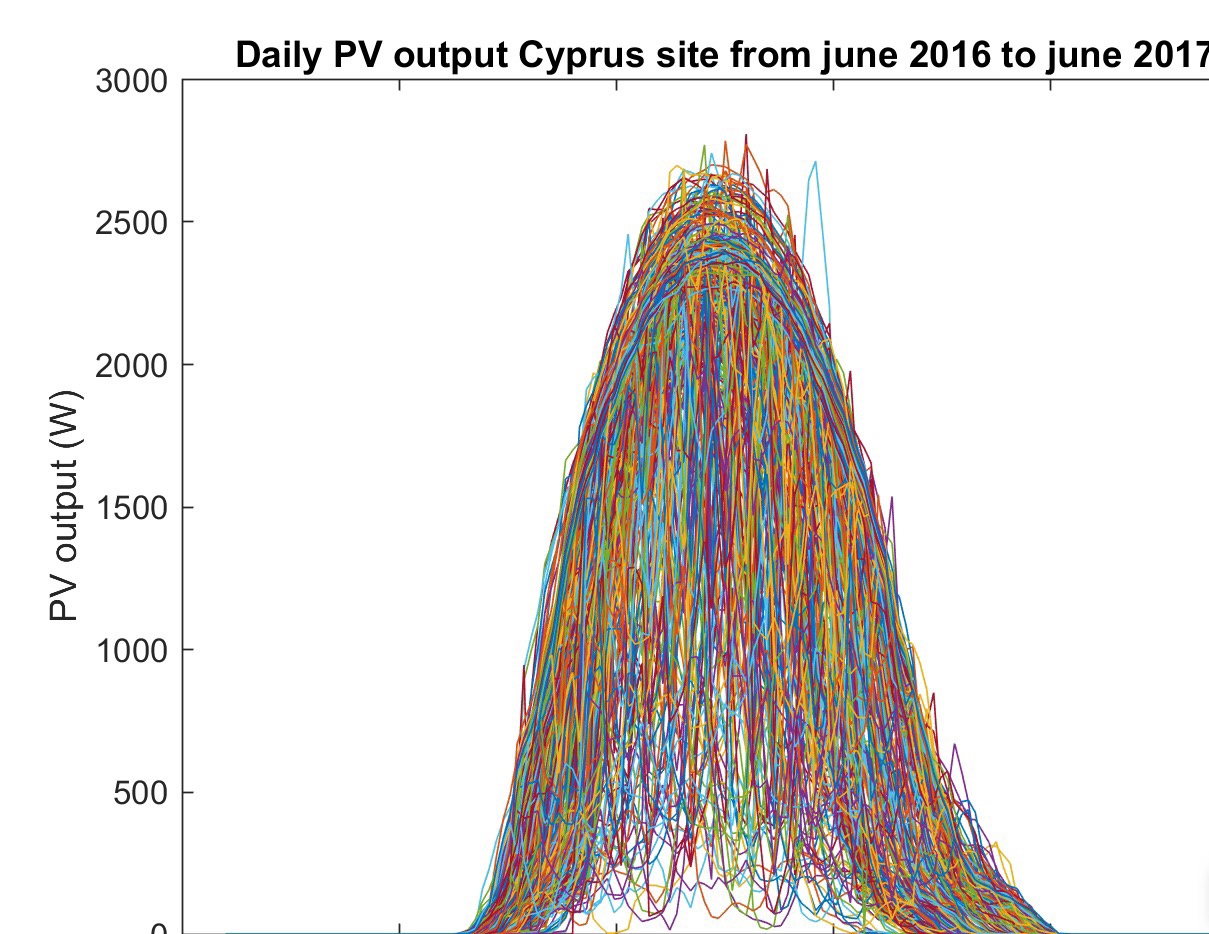
为了进行光伏场景的聚类分析,首先需要生成大量的光伏时间序列数据。这些数据需要包含不同的光伏发电场景,如不同天气条件、不同季节、不同地理位置等。在本文中,我们使用了matlab编程环境来生成光伏时间序列数据。
图1:光伏随机场景示例
在生成数据之后,还需要进行一些预处理操作,以消除数据中的噪声和异常值。常见的预处理操作包括平滑处理、数据归一化和缺失值处理等。这些操作可以提高聚类算法的准确性和稳定性。
- k-means算法介绍
k-means算法是一种常用的聚类算法,它可以将具有相似特征的样本归为同一类别。算法的核心思想是通过最小化样本与其所属类别中心点之间的距离来确定类别。具体步骤如下:
步骤1:随机选择k个初始类别中心点。
步骤2:将每个样本分配到与其最接近的类别中心点。
步骤3:更新每个类别的中心点,使其成为该类别样本的平均值。
步骤4:重复步骤2和步骤3,直到类别中心点不再发生变化或达到最大迭代次数。
k-means算法的优点是简单易懂且计算效率高,但缺点是需要事先确定类别个数k,并且对初始中心点的选择较为敏感。
- 基于k-means算法的光伏时间序列聚类
在本文中,我们将k-means算法应用于光伏时间序列的聚类分析。具体步骤如下:
步骤1:选择合适的类别个数k。根据光伏电站的规模和复杂性,可以通过经验或者试验来确定合适的k值。
步骤2:将光伏时间序列数据作为输入,通过k-means算法进行聚类。
步骤3:根据聚类结果,将每个光伏场景划分到相应的类别中。
步骤4:计算每个类别的中心点,作为典型场景来表示该类别。
步骤5:根据典型场景,进行调度优化和评估分析。
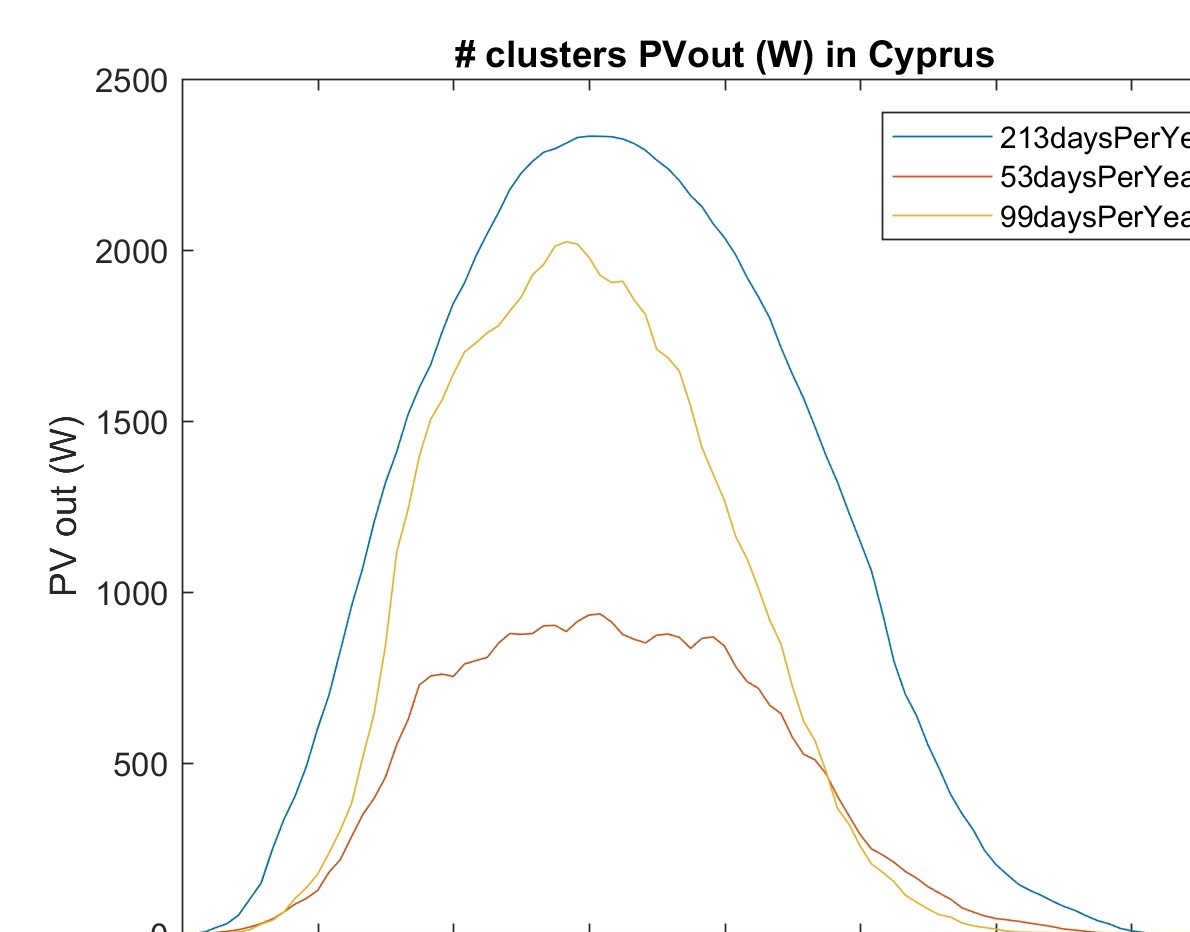
图2:光伏场景聚类结果示例
通过对大规模光伏场景的聚类,可以将复杂的场景削减为少数几个典型场景,从而提高后续调度优化和评估分析的计算效率。同时,典型场景的表征能力也更好,可以更好地反映光伏电站的运行状态。
- 结论与展望
本文基于k-means算法对光伏时间序列进行了聚类分析,实现了光伏场景的削减和典型场景的提取。通过该方法,可以更好地对光伏电站的运行状态进行理解和预测。未来的研究可以进一步优化聚类算法,提高光伏场景的表征能力和计算效率。
参考文献:
[1] Hastie T, Tibshirani R, Friedman J. The elements of statistical learning: data mining, inference, and prediction. Springer Science & Business Media, 2009.
[2] Lloyd S. Least squares quantization in PCM. IEEE transactions on information theory, 1982, 28(2): 129-137.
相关的代码,程序地址如下:http://matup.cn/676357984880.html
















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









