






 本文介绍了使用K-means算法对光伏时间序列进行聚类的方法,通过生成随机场景并对其进行聚类,实现大规模场景的削减,以便于调度优化和性能评估。
本文介绍了使用K-means算法对光伏时间序列进行聚类的方法,通过生成随机场景并对其进行聚类,实现大规模场景的削减,以便于调度优化和性能评估。
关键词:光伏聚类 K-means聚类 时间序列
编程语言:matlab
主题:基于k-means算法的光伏时间序列聚类
主要内容:
本代码研究大量随机场景下光伏序列聚类与削减问题,首先,生成大量光伏随机场景,其次,在此基础上,基于Kmeans算法,对该大规模场景进行聚类,从而实现大规模场景的削减,最后,依据削减后的场景,可进行调度和优化以及评估;
ID:4945665709723430
宇哥代码铺
基于k-means算法的光伏时间序列聚类
摘要:光伏能源已成为当今世界各国广泛关注的清洁能源之一。为了更好地管理和利用光伏能源,本文提出了一种基于k-means算法的光伏时间序列聚类方法。通过生成大量随机光伏场景,利用k-means算法对这些场景进行聚类,实现对大规模光伏场景的削减。通过削减后的场景,可以进行灵活的调度和优化工作,并对光伏系统的性能进行评估。
-
引言
光伏能源是一种可再生的、清洁的能源形式,具有广阔的应用前景。然而,由于光伏能源具有不稳定性和间歇性,如何更好地管理和利用光伏能源成为了一个重要的研究方向。光伏场景聚类可以将具有相似特征的光伏场景归类在一起,从而实现对光伏能源的有效管理和利用。 -
光伏聚类方法
2.1 光伏场景生成
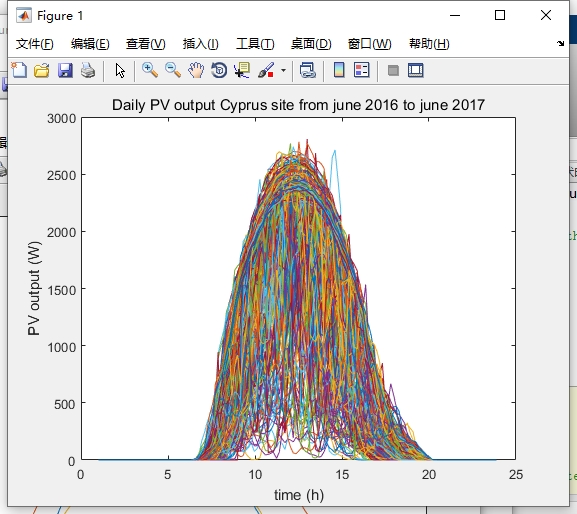
为了研究光伏时间序列聚类方法,我们首先需要生成大量的光伏场景。根据光伏系统的特性,我们可以生成具有不同特征的光伏场景,包括不同的光照强度、温度、云量等。通过模拟这些光伏场景,我们可以获得一个包含丰富多样的光伏时间序列数据集。
2.2 K-means算法
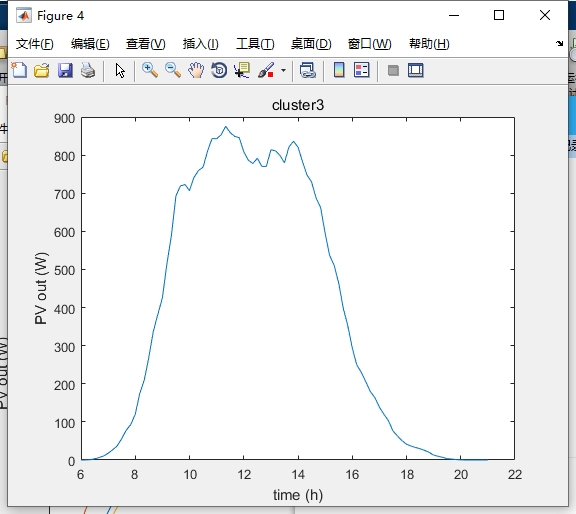
K-means算法是一种常用的聚类算法,可以将样本划分为不同的簇。在光伏场景聚类中,我们可以利用K-means算法将具有相似特征的光伏场景聚集在一起。聚类后的场景可以作为一个代表,用于对大规模光伏场景进行削减。
-
光伏场景聚类与削减实验
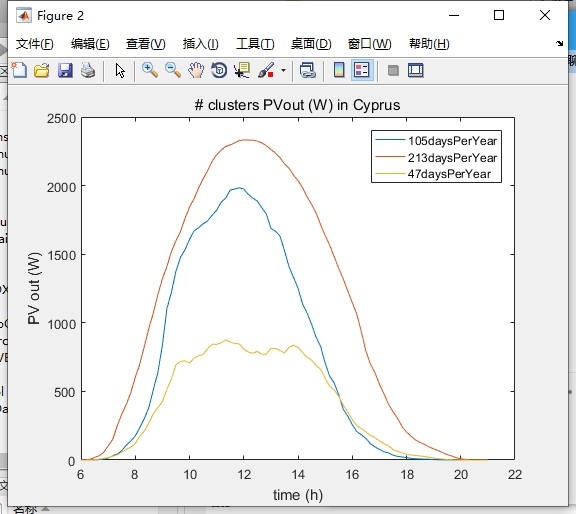
通过基于k-means算法的光伏场景聚类方法,我们对生成的光伏场景进行聚类和削减实验。首先,我们将生成的光伏场景数据集分成若干个簇,每个簇包含一组具有相似特征的光伏场景。然后,我们可以选择一个代表性的光伏场景作为每个簇的代表,削减数据集的规模。通过削减后的数据集,我们可以更加高效地进行调度和优化。 -
光伏系统调度与优化
通过削减后的光伏场景数据集,我们可以进行光伏系统的调度和优化工作。根据削减后的数据集,我们可以预测光伏系统在不同时间段内的发电能力,从而合理安排用电计划。同时,我们还可以通过优化算法对光伏系统进行性能优化,如最大化光伏发电量、最小化光伏系统的损失等。 -
性能评估与结果分析
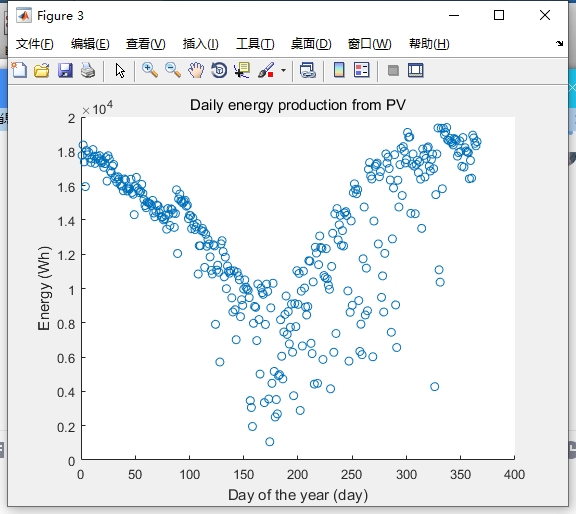
为了评估基于k-means算法的光伏时间序列聚类方法的性能,我们可以对聚类和削减后的数据集进行性能评估。通过比较削减前后的数据集,我们可以评估算法在数据集规模和特征保持上的效果。同时,我们还可以通过实际应用中的光伏系统数据进行验证,验证聚类结果的可靠性和应用性。 -
结论和展望
本文提出了一种基于k-means算法的光伏时间序列聚类方法,实现了对大规模光伏场景的削减。通过削减后的场景,可以进行光伏系统的灵活调度和优化,并对光伏系统的性能进行评估。未来,我们可以进一步研究和改进聚类算法,提高聚类结果的准确性和可靠性。同时,我们还可以探索其他算法和方法,如深度学习方法在光伏时间序列聚类中的应用。
参考文献:
[1] Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer.
[2] Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
[3] Jain, A. K., Murty, M. N., & Flynn, P. J. (1999). Data Clustering: A Review. ACM Computing Surveys, 31(3), 264-323.
[4] MacQueen, J. (1967). Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, 281-297.
以上相关代码,程序地址:http://matup.cn/665709723430.html















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









