







笔记整理:侯哲衡,东南大学硕士,研究方向为知识图谱问答、自然语言生成。
动机
对话资讯搜索是在智能问答中一个新兴研究领域。对话资讯搜索旨在根据通过用户查询自动询问资讯搜索式问题(information-seeking questions,ISQs)、记录寻求资讯者的响应并根据响应来确定寻求资讯者的需求。这一领域现有的工作主要集中于根据寻求资讯者的响应检索相关上下文生成答案,缺少根据用户查询自动生成ISQs相关的研究。
根据用户查询自动生成ISQ的主要挑战在于用户查询往往是短而有限的,需要额外的知识生成用户需要的答案。ISQ与澄清式问题(Clarifying questions)不同的是,澄清式问题所关注的仅限于查询中的实体,而ISQ需要系统深入挖掘查询中的实体在知识图谱中的相互联系。同时,这一研究缺少相对应的高质量数据集。为了解决上述问题,文章提出了一个资讯搜索式问题生成器(Information SEEking Question generator,ISEEQ)。资讯搜索式问题生成器的设计思路主要来源于对三个问题的探索:
1.知识图谱/知识库是否可以帮助上下文检索和问题生成?2.ISEEQ生成的ISQs是否语义清晰,逻辑连贯?3.ISEEQ 能否跨领域场景中生成 ISQ?
贡献
文章的贡献有:
1.首次提出资讯搜索式问题生成这一任务并提供一种解决思路;2.对于用户查询,引入知识图谱增强查询进行上下文检索的过程;3.通过引入强化学习,增强生成问题的多样性和可读性;4.引入两个评估指标:“语义关联性”和“逻辑连贯性”评估生成ISQs的质量;
方法
⒈ 任务定义
输入为一个任意领域相关的短查询 。输出是一串资讯搜索式问题 。
⒉ 模型框架
如下图1所示为本文提出的ISEEQ模型框架。

图1 ISEEQ模型框架
如图1所示,ISEEQ模型结合了基于BERT的解析器(蓝色),语义查询扩展模块(黄色)和知识感知上下文检索模块(绿色)帮助问题生成模型(橙色)生成的ISQ之间语义相关。问题生成模型则包含了 ISEEQ 两种变体:ISEEQ-RL 和 ISEEQ-ERL的结构。本文在强化学习环境中训练 ISEEQ,在生成 ISQ 的同时最大化语义关系和连贯性。
⒊ 语义查询扩展模块
本文借助常识知识图谱(CNetKG)扩展用户输入的短查询。首先使用 CNetKG 在用户查询描述 d 中提取实体集 。为此,文章使用预训练的基于自注意力编码器-解码器的选区解析器与 BERT 作为 ISEEQ 中的一致性编码器。解析器有条件的提取名词短语,这些名词短语捕获定义 IS 查询的候选实体。如果短语在 CNetKG 中有提及,则将它们称为实体 1。
然后在实体集 上,用深度优先搜索在 CNetKG 上执行多跳三元组(主体-实体、关系、对象-实体)提取。提取形式类似 和 的三元组,其中 。我们只保留那些 出现为主体实体的三元组。
通过这种启发式规则,可以(1)最小化噪音和 (2) 收集更多关于 中实体的直接信息。最后,文章通过注入提取的三元组来对输入 d进行文本化以获得一个知识增强的查询 。
⒋ 知识生成模块
给定知识增强的查询 ,知识增强模块从一个集合P中进行上下文检索并获取最优的K个上下文 。为此,文章对(Lewis et al. 2020)中描述的密集上下文检索器(DPR)进行了以下具体改进:(1)用于上下文p∈P 和k_d的 Sentence-BERT 编码器。我们使用 Sentence-BERT 创建 p∈P的密集编码,表示为 。同样, 的编码表示为 。(2) 结合SITQ (Simple locality sensitive hashing (Simple-LSH) and Iterative Quantization)算法,通过使用归一化实体分数(NES)来挑选top-K段落 。SITQ 是一种基于 MIPS 的快速近似搜索算法,用于检索和排列段落。这一算法可以被表示为一个分值,这个分值通过以下两个公式计算:


知识生成模块在训练集中的每个查询至少有一个生成 ISQ 时停止迭代。
⒌ 问题生成模型
ISEEQ 利用 和 作为奖励函数在强化学习中学习 QG。ISEEQ使用T5作为生成模型,Electra-base作为鉴别模型学习资讯搜索式问题。
奖励函数:
ISEEQ-RL和ISEEQ-ERL中的奖励函数被定义为:

ISEEQ-RL中的损失函数被定义为:

ISEEQ-ERL中的损失函数被定义为:


实验
⑴. 实验细节
本文在多个数据集上进行了实验,这些数据集的具体指标如下表所示:

图4 数据集指标
本文使用SQUADv2.0对模型进行微调。本文利用了Pytorch Lightning和Hugging Face transformer实现模型。模型参数使用python包ray进行调整,最终 , ,学习率设为1.17e-5。模型对每一轮迭代都进行了交叉验证,并根据不同的数据集迭代了100-120轮。
⑵. 实验结果
如下图3所示,与其他数据集相比,基于多上下文的问题生成比 TLMs-FT 中使用单上下文问题生成能产生更好的结果。

图3 ISEEQ与基线模型对比结果
另外,作者还进行了消融试验,测试了语义查询扩展模块的效果。效果如图4所示:

图4 语义查询扩展模块的消融试验
不仅如此,作者还通过人工评估测试了ISEEQ-ERL的效果,如图5所示:
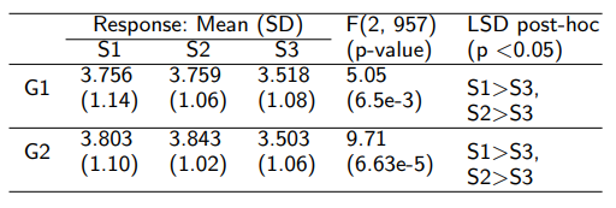
图5 人工评估
总结
本文提出了一种根据用户查询自动生成资讯搜索式问题的方法,引入强化学习有效增强了生成的多个问题之间的语义关联性和逻辑连贯性。人工评估和自动评估指标皆表明,ISEEQ模型效果非常不错。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









