






转载公众号 | 知识图谱科技
综合Generational 撰写的论文以及本文作者的实践观点。本文论文是对知识Copilot、检索增强生成和用户体验的广泛探索。主要的观点是,对于知识密集型任务,根据行业场景和数据情况以及成本交付周期等,如何选择搭建KG-RAG或者文档RAG,另外如何使用Agent的 RAG 和搭建良好用户体验的人机协同产品。
什么是Knowledge Copilot(知识助手)?
知识Copilot是用户的思维伙伴,专门用于从知识库中检索信息,通过上下文进行推理并综合回应。它远不止于将基础模型包装成生成复制品或诗歌的外壳。例如,一个商业分析师综合最新的市场新闻需要网络访问。研究人员可能需要找到相关的论文用于引用。诸如图像生成和共情对话之类的功能虽然有价值,但在知识Copilot的主要功能——思考和研究方面,它们是次要的。
我首先写这个主题,是因为它让我着迷。从2016年开始,我一直在尝试使用传统的自然语言处理技术()来打造自己的知识Copilot。其次,这有助于我们成为更快、更好、更理智的知识工作者。最近的研究(https://www.microsoft.com/en-us/research/uploads/prod/2023/12/AI-and-Productivity-Report-First-Edition.pdf)显示,借助Copilot进行的研究任务可以加快完成速度约50%,而不会影响质量。它消除了翻阅文件和网页以查找特定信息的繁琐过程。
在检索、推理和综合信息的三元组中,检索是基础。它为后两者奠定了基础。检索还解决了基础模型的一个关键局限性:它们的信息往往过时,而且它们并不知道一切。尽管它们的数以亿计的参数包含广博的知识,但这种丰富可能会导致“幻觉”或不准确。因此,能够只检索所需的上下文信息是一个知识Copilot有效性的重要决定因素。
因此,让我们深入了解检索增强生成(RAG)和知识图谱(KG)。
KG-RAG
检索增强生成结合了检索式和生成式AI模型。首先从数据集中检索相关信息,然后利用这些数据来告知类似GPT的生成模型,从而利用更准确和特定于上下文的信息增强响应。这提高了AI根据初始训练数据中不包含的外部事实提供明智答案的能力。
最近,知识图谱辅助LLMs变得越来越流行。这使LLM的回答基于真实数据,并有助于进行更复杂的推理。在本文中,我们关注来自书籍和文件等非结构化数据中提取的知识图谱,而不是来自结构化数据的知识图谱。
知识图谱表示通过人和计算机可读的实体(人物、物品、事件)、关系(配偶、作者、参与者)和属性(年龄、日期)从文件中提取的综合表示。
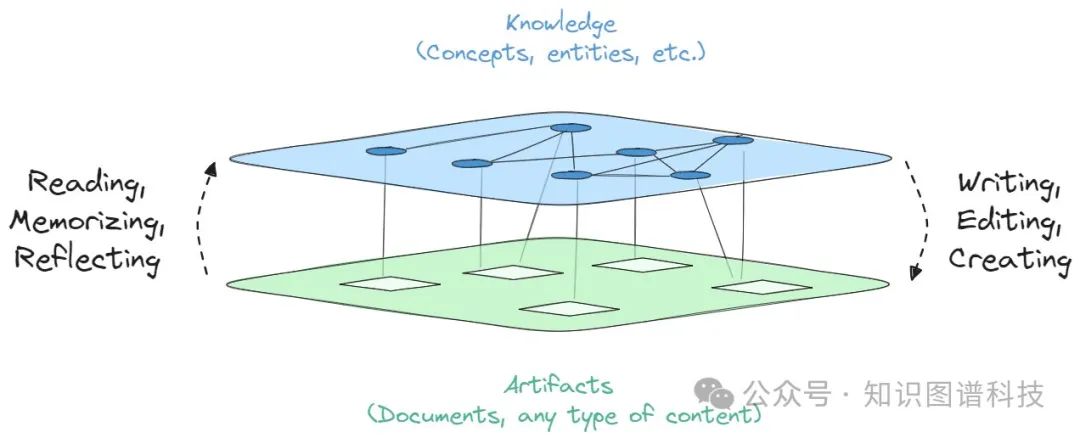
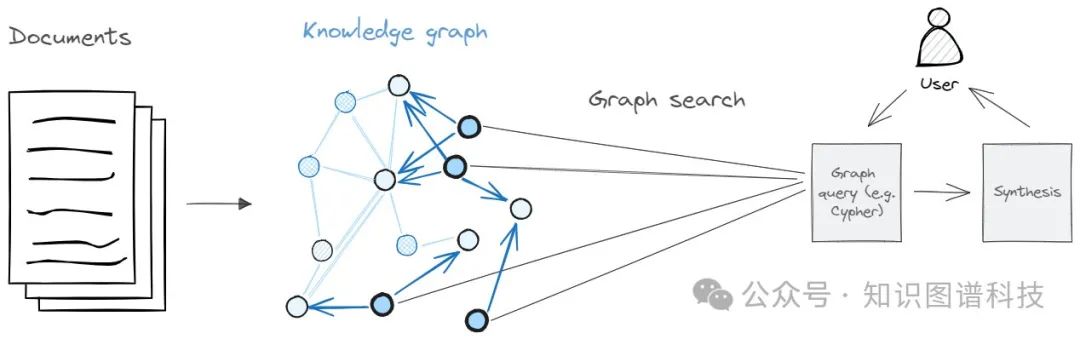
改为从 KG 中直接检索信息,而不是检索文档。为了探索这一点,我构建了一个 KG-RAG,并以构建 KG 为起点。创建 KG 有一个已建立的流程。
实体抽取:从非结构化文本数据中识别和提取实体,如人物、组织和概念。
关系提取:提取实体之间的关系。
共指消解:共指消解确定文本中两个或多个表达式是否指的是同一个实体(即他/她指的是正确的实体)。
KG 融合/构建:与现有的知识图谱融合(大量的匹配/查找查询)。否则,创建一个以实体和关系为节点和边的图。
传统上,工程师们必须为每个步骤拼接一系列定制模型的管道。但我选择使用 GPT-4 Turbo 作为单一模型来完成所有任务。我在一个提示中指示模型根据 Paul Graham 的一篇长文创建 KG。以下是创建的 KG 的快照。


结果非常全面,包含了约100个实体和数百个关系。KG-RAG可以回答文本块/文档照顾办法无法回答的问题。例如,它能够识别到由Jessica Livingston的合作伙伴(Paul Graham)撰写的书籍,但文档照顾办法却不能,并且有时会以Jessica撰写的书(一本关于初创公司创始人的采访汇编)的方式回答,有时甚至会出现幻觉。
有了KG-RAG,我还可以追溯Jessica→约会→Paul→撰写→书籍→(Hackers & Painters, On Lisp)的逻辑关系。让我们假设文档RAG能够提取正确的文本块并做出正确回答。用户仍然需要阅读检索到的文本以验证和推断相同的逻辑路径。
尽管KG-RAG有其优势,也有相应的限制,原因如下:
1,对于超出LLM上下文窗口的大型语料库,工程师们必须构建一个带有定制模型的KG流水线。虽然有通用的现成模型,但它们仍然需要进行微调以适应特定领域。
2,像GPT-4 Turbo或Anthropic Claude这样的大型上下文LLM的提示工程可以简化KG的构建。但根据我的测试,结果对提示非常敏感。稍微调整几个词,结果就会有实质性的不同。
3,KG-RAG没有我们对Copilot要求的泛化能力。它只能回答KG中包含的内容,因此高度依赖一个已经复杂且不稳定的过程。
4,从概念上甚至可以说在哲学上,知识是流动的。对于任何一个主题,都有很多不同的观点。大多数人在学校中接触到完全相同的材料,但最终得出不同的结论。如果你问一个人什么是牛,你会得到不同的答案。对于大多数人来说,它是一种产奶和产肉的动物。对于孩子来说,它是一种黑白相间、产奶的动物。对于屠夫来说,它是一种以高价出售的收入来源。我们知道什么是牛,但有很多表达方式,它们都是正确的。
根据行业场景,数据情况和成本以及需要实施的周期来评估KG_RAG和文档RAG两者的结合。
有时候文档RAG是知识Copilot的更适合的方向,文档RAG办法成功的原因是通过将其向量化,具有足够的泛化能力以成为协作模型。KG-RAG在概念上更吸引人,在专业性要求较高以及合规性很强的领域,例如医药领域更合适。但通用的文档RAG是知识Copilot的可行路径。那么哪种文档RAG是最好的呢?有十几种策略可供选择,从简单的RAG到复杂的多智能体设置。为了回答这个问题,我测试了几种代表不同概念方法的RAG策略。
最适合知识协作的RAG
要评估RAG策略,我使用了我熟悉的文本,因为我想要手动评分结果,而不是按行业惯例用GPT-4进行自动化评分。今年我写了八篇代际文章,大约有13,000个单词。
评分方法很简单。每个RAG策略的基本得分为10分。我设计了10个问题,需要复杂的推理或对文章的深入理解。对于每个RAG策略的回答,我评估其"正确性"。如果回答错误或未找到正确信息,我扣除1分。如果答案部分正确,我扣除0.5分。(对于工程师们:是的,我在混合检索和LLM生成的评估)
作为基准,我还评估了GPT-4 Turbo的上下文窗口和OpenAI的GPT中的原生RAG的性能,使用这些文章作为知识库。有关使用的库和模型的详细信息,请参见附录。现在,让我们探索每个RAG策略及其基本逻辑。
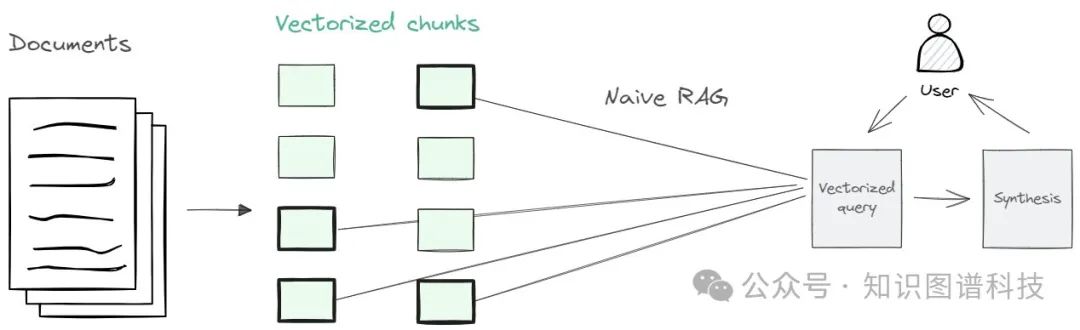
简单/Naive RAG:此策略接受输入并检索一组具有最相似向量的文档。
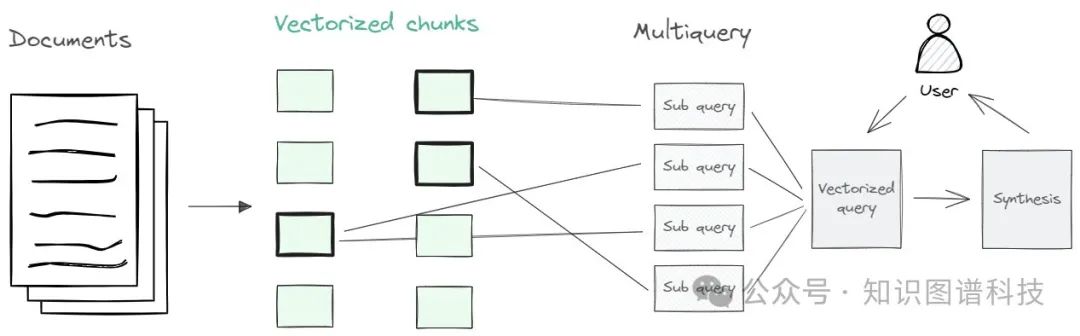
多查询RAG:根据用户的初始查询生成多个查询。对于每个生成的查询,检索出最相关的文档。我们的想法是,通过将查询分解为不同的查询,我们可以更好地捕捉各种观点。这里的方法是转换用户查询。
假设性问题RAG:这种方法创建了可以从每个文本块回答的问题。然后将用户的查询与最相似的问题进行匹配,并检索相关的“父”块。意图是将用户的查询与假设性问题进行对齐,预期在它们的嵌入中获得更接近的匹配。这里的方法是进一步转换文档。
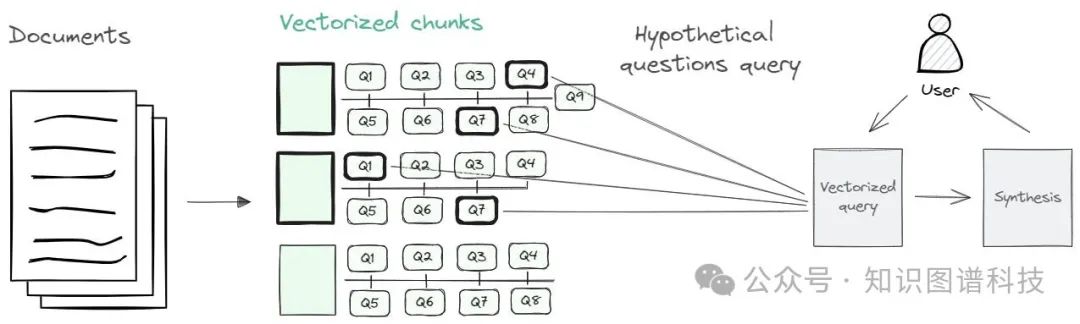
ReAct(即推理和行动):该策略中的代理程序迭代地检索片段,并反思是否有足够的信息来做出回应,或者是否需要更多的查询。这仿佛通过文本片段来遍历知识图谱的过程。
结果与洞见
问答电子表格
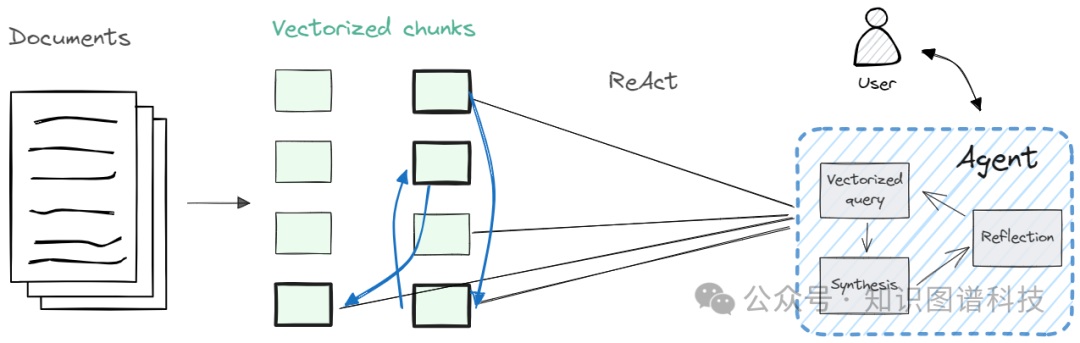
对于简单的用例和较小的语料库,朴素的RAG足够好。但如果语料库很大,更先进的RAG策略可能会更好。
就最佳“准确性”而言,代理效果最佳。一个ReAct代理会不断获取信息并进行反思,从而实现可追踪的思维过程,类似于人类知识工作。例如,当查询微软Copilot的定价与Intercom Fin的定价时,ReAct首先会检索一组文件块。如果缺少有关Intercom定价的信息,它将专门寻找与Intercom相关的额外块。
如果代理不可行,请使用多查询方法。虽然多查询和假设性问题的RAG得分相似,但我推荐使用多查询(或修改查询而不是语料库的方法)。测试和诊断查询比遍历整个语料库更可行。您将在下一部分中看到使用此方法的产品。
上下文长度并不是唯一决定因素。扩展上下文长度是发展的一个活跃领域,Anthropic的Claude拥有一个具有15万字上下文窗口(约500页)的生产模型。但是用整个语料库填充提示会导致性能变差。像人类一样过度加载信息可能起到反作用。
最后,OpenAI的GPT模型烦人地啰嗦。请提示它将响应长度限制在几百个词以内。对此进行一种愤世嫉俗的看法是,OpenAI有财务激励让其模型变得啰嗦。
人机交互同样重要
话虽如此, Agent不是知识Copilot的解决方案。类似ReAct的Agent在幕后进行多次检索。这样做在大规模的情况下可能会变得缓慢和昂贵。更为关键的是, 那些对中间结果进行反思的Agent将失去上下文。它可能会产生幻觉或限制自己只能使用LLM的存储知识。当我测试一种名为FLARE的高级代理策略时, Agent立即假设Microsoft Copilot没有可用的定价信息, 因为GPT-4的知识截止日期是2023年4月。
人类应该在每个转折点上引导Copilot。但是不断输入更多上下文和指导可能会很繁琐。想象一下总是不得不输入"请仅搜索前五个谷歌搜索结果"或输入像RAG这样的缩写。人机交互在通过Copilot帮助人类方面起着至关重要的作用。下面我们将通过Perplexity和Bing的全新深度搜索来举例说明优秀的人机交互。
1,提出澄清问题。这将引导检索到正确的领域进行搜索。例如, RAG有不同的含义: 一个字面上的布条, 项目管理中的红/黄/绿, 检索增强生成, 重组激活基因等等。
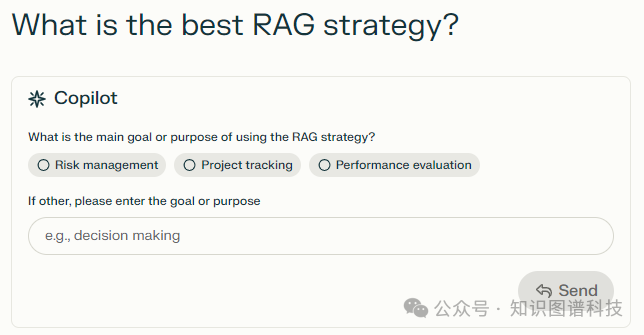
问Perplexity “什么是最好的RAG策略?”
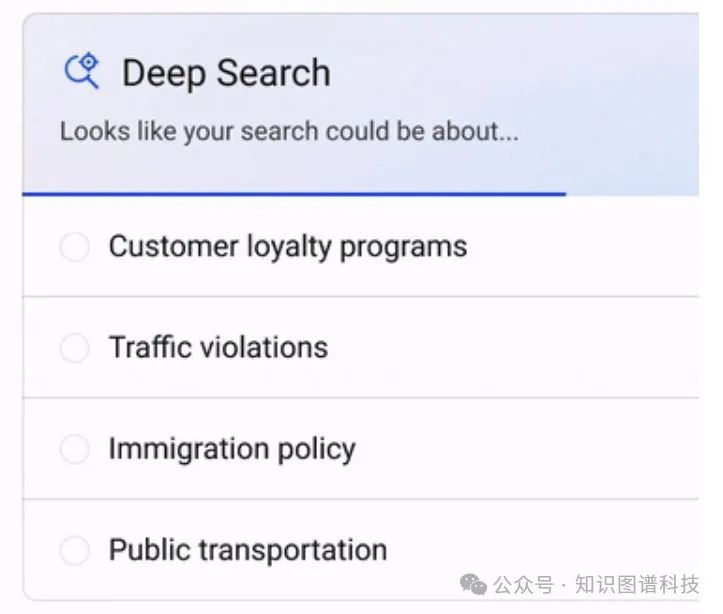
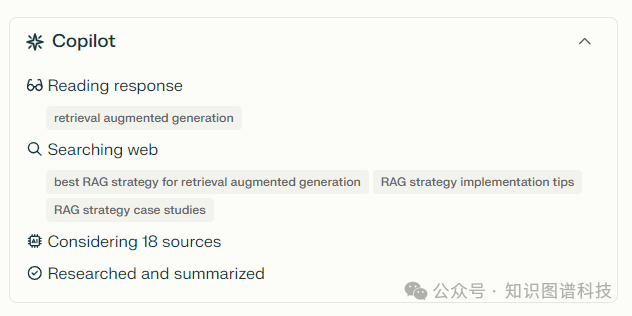
展示步骤。能够看到副驾驶的操作及RAG的工作方式对于了解情况很有帮助。如果结果看起来不对,这为用户提供了一定程度的审计能力,使他们能够调整查询。这种透明度有助于与副驾驶建立信任。注意,Perplexity可能正在使用某种形式的多查询RAG。
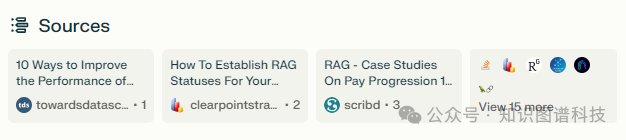
3. 引用来源。尽管大多数副驾驶产品都有这个功能,但简单的用户体验功能,如显示标识和参考标题,可以提高体验。标识立即传递出信息的可信度和上下文。
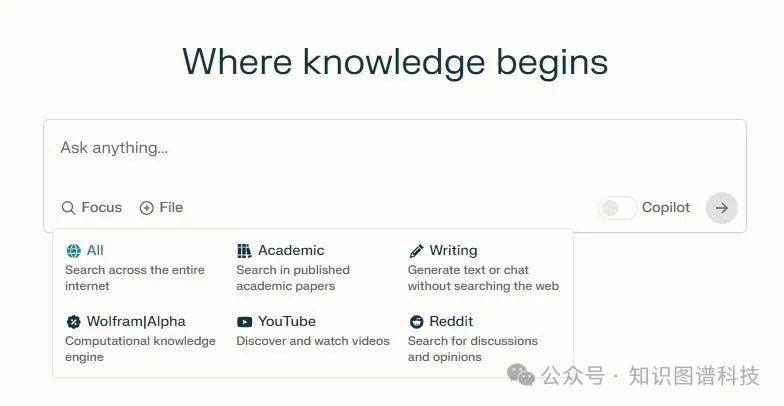
限制搜索范围。限制搜索范围并设置上下文可能是有效的。如果我想了解最新的闲聊,我应该搜索Reddit。如果我想阅读最新的RAG论文,我应该搜索Google学术。
RAG之后,下一步是什么?
之前,我们注意到检索是知识协同机器人的基础。还有推理和合成。但这些将留待以后的文章。
精选阅读:
Commercial: An Introduction to Google Gemini
Social: Early LLM-based Tools for Enterprise Information Workers Likely Provide Meaningful Boosts to Productivity
Technical: Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
附录
语料库:过去一年中我撰写的八篇关于“世代”的文章,总计约13,000字
使用的库:
Unstructured 用于处理和加载文章
LlamaIndex 和 Langchain 作为框架用于分割、查询和合成回答
Chroma 和 Neo4j 作为数据存储
切块场景
较小的块(约500字)以模拟大量块构成的大型语料库场景,使得检索正确信息更加困难
较大的块(约1,000字)以增加检索正确信息的机会
使用的模型
GPT-4 Turbo(gpt-4-1106-preview)
Ada Embedding(text-ada-embedding-002)
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。















 2763
2763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









