







笔记整理:陈少凯,浙江大学硕士,研究方向为知识图谱、RAG
链接:https://arxiv.org/abs/2402.07630
1. 动机
尽管现有研究在多种场景下融合了大型语言模型(LLM)与图神经网络(GNN),聚焦于诸如节点、边及图分类等传统图谱任务,或是解答小规模乃至合成图上的查询问题,但我们的创新成果开辟了一条新路径。我们精心设计了一款弹性十足的问答系统,专为应对复杂且源自现实世界的大规模图数据而生。这一框架赋予用户通过一体化对话界面与图数据直接“对话”的能力,标志着图形数据分析领域一次革命性的进步。
近期学术界的努力尝试将图形结构转化为自然语言表述,比如将节点与边转换为文本序列,以便借助LLM处理各类图相关任务。然而,这种方法遭遇了显著的扩展性瓶颈。当图形包含成千上万个节点与边时,转化成文本序列将导致标记数量激增,超出了多数LLM的输入容量限制。若为适配LLM而裁剪图形文本序列,又会不可避免地牺牲信息完整性和回复质量。为解决这一挑战,G-Retriever 应运而生,其内置的RAG(Retrieval-Augmented Generation)机制能精准定位并提取图形中的关键片段,从而高效处理大规模图形数据,确保信息无损传递的同时,大幅提升了系统的响应效率和准确性。
综上所述,我们的解决方案不仅解决了图形到文本转换的可扩展性难题,更在保持信息完整度的前提下,实现了对大型图数据的有效管理和深度理解。
2. 贡献
(1)提出了一个GraphQA的benchmark(集成了三个任务的数据集:常识推理,场景图理解,知识图谱推理),用于测试模型在回答图问题的相关能力,填补了研究空白。
(2)作者提出了G-retriever方法,结合了GNN、LLM、RAG,通过软提示进行高效微调以增强图理解能力。
(2)作者提出了一种基于PCST的图检索方法,并在多个领域证明了G- retriever的效率和有效性,以及缓解了图大语言模型的幻觉问题。
3. 方法
模型的整体架构如下:
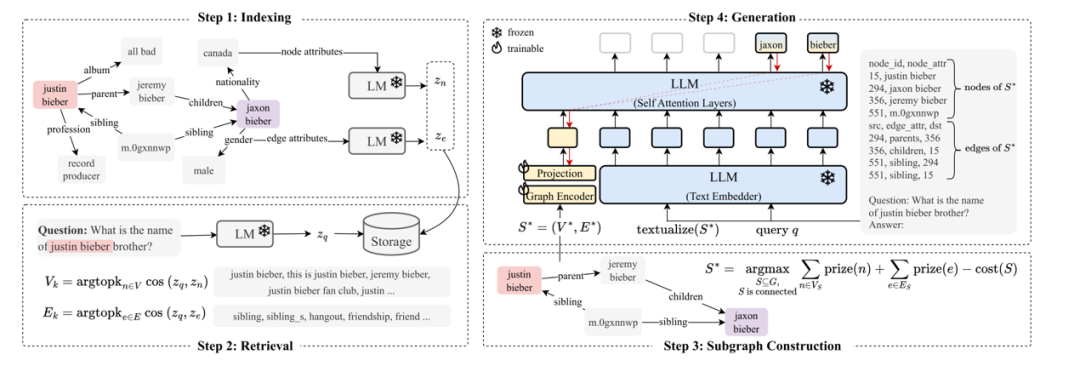
主要分为四个阶段,具体如下:
(1)索引阶段:使用预训练的语言模型生成节点和图的嵌入来初始化RAG,然后将这些嵌入存储在最近邻的数据结构中,然后输入到语言模型得到Zn,对于边也是一样的策略。
(2)检索阶段:对于检索,对查询采取与索引阶段相关的编码策略,来确保对文本信息的一致性处理。然后,识别与当前查询最相关的节点和边(即基于查询与每个节点或边的相似性,产生一组“相关的节点/边”)
(3)子图构建阶段:利用PCST算法构建一个尽可能包含多的相关节点和边的子图,同时保证图的大小是可管理的。核心目标是过滤掉与查询无关的节点和边,且保证图的大小转换成自然语言后是可以被输入到LLM中进行处理。
(4)生成阶段:对于检索到的子图,一方面利用GAT进行图编码,另一方面将检索到的子图转换为文本格式,和查询一起输出到LLM进行字编码;最后结合两边的输出,一起输入到LLM中,生成答案。
4. 实验
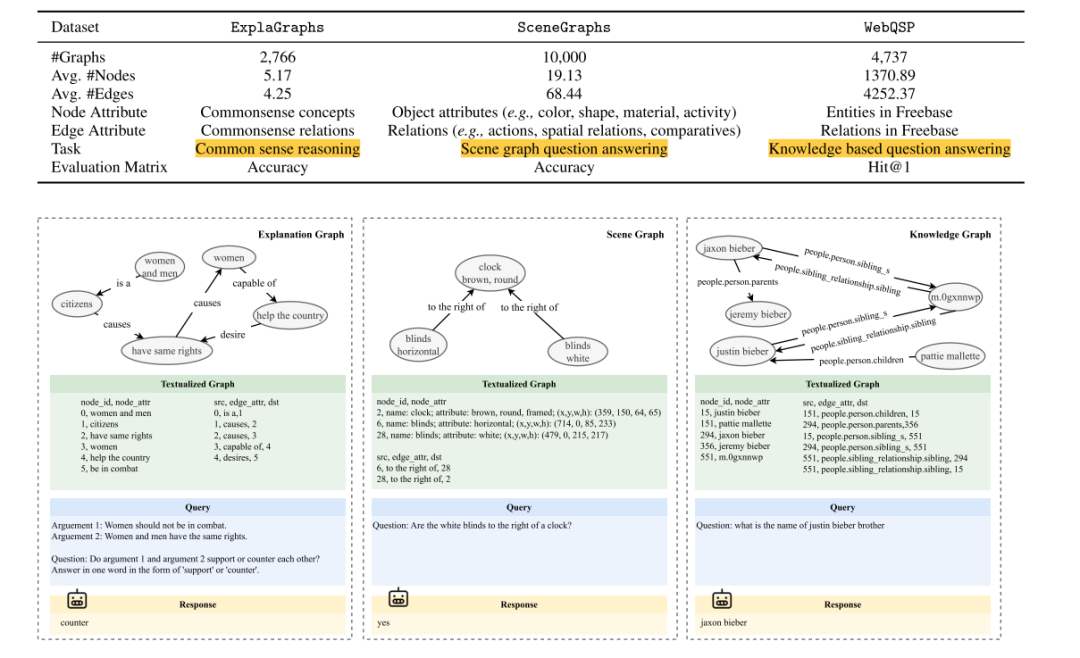
GraphQA Benchmark:
该Benchmark主要由三种任务的数据集(ExplaGraph数据集:常识推理任务、SceneGraphs数据集:场景图问答任务、WebQSP数据集:知识问答任务)一起标准化和处理成统一的数据格式。
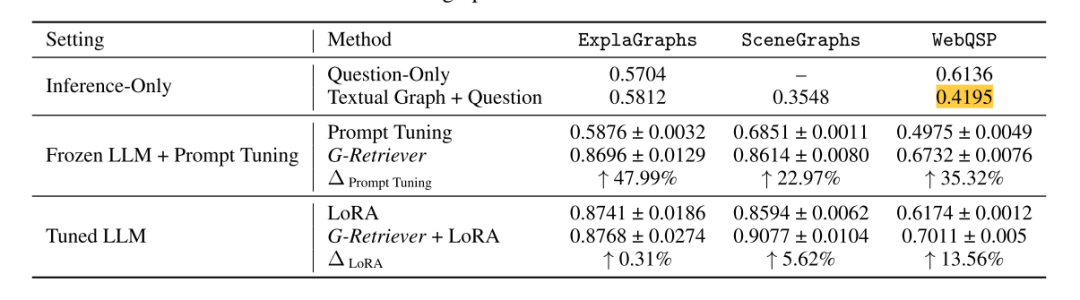
不同设置在ExplaGraphs、SceneGraphs和WebQSP数据集上的性能比较:
执行检索前后平均的token数和节点数:

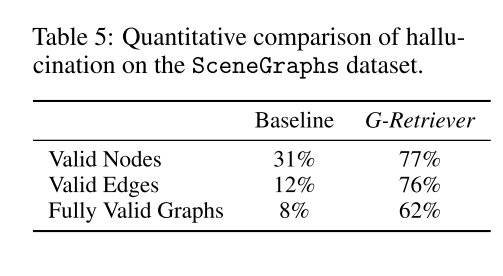
在SceneGraphs数据集上对幻觉进行定量比较:
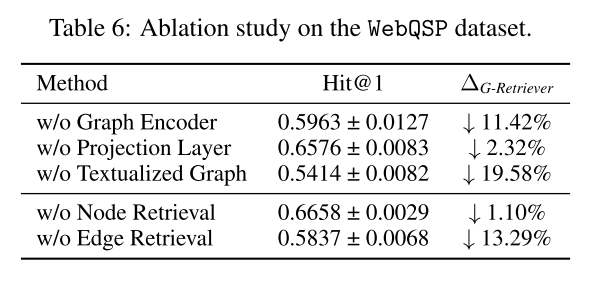
消融实验(架构层面和检索模块层面):
5. 总结
本文构建了一个新的GraphQA基准,用于现实世界的图问答,并提出了G-Retriever,一个擅长复杂和创造性查询的架构。实验结果表明,G-Retriever在多个领域的文本图任务中超过了基线,可以有效地扩展更大的图尺寸,并表现出对幻觉的抵抗力。此外,本文中的G-Retriever采用的是静态检索组件,未来研究发展中可以研究更加复杂的RAG系统,比如采用训练的检索组件。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 59
59

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









