






转载公众号 | 老刘说NLP
最近讲大模型说的太多,我们换个口味,讲讲事件图谱。
在前面的文章《数据资源:事件图谱构建中常用事件抽取、因果事件关系数据集的总结与思考》中,我们对现有的事件抽取、事件关系识别数据集进行整理,
包括11类事件抽取数据集和2类因果关系抽取数据集,其中,百度飞桨AIstudio中收录了关于事件抽取的一些数据集,从中,我们可以快速找到一个针对相应任务的标注数据集。
而在更多时候,我们需要有自己的事件抽取任务,因此,如何标注起自己的数据集,十分关键。
因此,本文主要围绕着事件标注这一主题,以DuEE句子级事件标注数据、DuEE-Fin篇章集事件标注数据两个开放评测数据出发,说明事件标注的基本内容,第三部分,以开源标注工具MarkTool进行事件标注进行实践,供大家一起思考。
一、DuEE句子级事件标注数据
DuEE1.0包含65个事件类型的17000个具有事件信息的句子(20000个事件)。65个事件类型中不仅包含「结婚、辞职、地震」等传统事件抽取评测中常见的事件类型,还包含了「点赞」等极具时代特征的事件类型。
1、事件本体的定义与示例
以DuEE1.0为例,event_schema.json中记录了结婚等65种事件的本体定义,
一个事件的本体由事件类型event_type,事件大类class以及事件的论元role_list构成,如下图所示,事件类型为"财经/交易-上市",事件大类为"财经/交易,包括时间、地点、上市企业以及融资金额等四个要素。
{
"event_type":"财经/交易-上市",
"role_list":[
{
"role":"时间"
},
{
"role":"地点"
},
{
"role":"上市企业"
},
{
"role":"融资金额"
}
],
"id":"e66035ff3b3a4c641f90bfa2dd035ac5",
"class":"财经/交易"
}
{
"event_type":"产品行为-发布",
"role_list":[
{
"role":"时间"
},
{
"role":"发布产品"
},
{
"role":"发布方"
}
],
"id":"141fdae3c2a8fab0b2fc0a684271a89a",
"class":"产品行为"
}2、事件标注的输出数据个格式与样例
同样的,以DuEE1.0为例,给出了11958条事件标注数据,1498条测试数据,下表显示了事件标注的数据结构。
具体包括非结构化文本"text",事件列表"event_list",其中,事件列表中包括每一个发生的事件,并注明事件类型"event_type"、触发词"trigger"、触发词在原文中的索引位置"trigger_start_index"、事件大类"class"以及事件论元"arguments",
包括论元在原文中的索引位置"argument_start_index",论元的角色"role",论元的值"argument"以及论元的其他指称"alias"。
{
"text":"中国地震台网正式测定:09月08日06时36分在四川内江市资中县(北纬29.59度,东经104.82度)发生3.0级地震,震源深度9千米。",
"id":"0805c167d42e6558d5d999a905a3dac4",
"event_list":[
{
"event_type":"灾害/意外-地震",
"trigger":"地震",
"trigger_start_index":58,
"arguments":[
{
"argument_start_index":10,
"role":"时间",
"argument":":09月08日06时36分",
"alias":[
]
},
{
"argument_start_index":24,
"role":"震中",
"argument":"四川内江市资中县(北纬29.59度,东经104.82度)",
"alias":[
]
},
{
"argument_start_index":54,
"role":"震级",
"argument":"3.0级",
"alias":[
]
},
{
"argument_start_index":65,
"role":"震源深度",
"argument":"9千米",
"alias":[
]
}
],
"class":"灾害/意外"
}
]
}当然,一个句子中也可能描述多个事件,如下面的事件标注结果,句子 “北京时间今天凌晨4点在阿瑟阿什球场上演了男单冠军的争夺,对阵的双方分别是本届赛事2号种子纳达尔和赛会5号种子梅德韦杰夫,最终红土天王表现更加出色,以7:5、6:3、5:7、4:6、6:4赢得比赛,斩获职业生涯第19座大满贯冠军。!” 中提及了"竞赛行为-胜负"以及"竞赛行为-晋级"两个事件类型。
{
"text":"北京时间今天凌晨4点在阿瑟阿什球场上演了男单冠军的争夺,对阵的双方分别是本届赛事2号种子纳达尔和赛会5号种子梅德韦杰夫,最终红土天王表现更加出色,以7:5、6:3、5:7、4:6、6:4赢得比赛,斩获职业生涯第19座大满贯冠军。",
"id":"05b2a8c83ed2cc733271ca3e85c40a37",
"event_list":[
{
"event_type":"竞赛行为-胜负",
"trigger":"赢",
"trigger_start_index":93,
"arguments":[
{
"argument_start_index":0,
"role":"时间",
"argument":"北京时间今天凌晨4点",
"alias":[
]
},
{
"argument_start_index":36,
"role":"胜者",
"argument":"本届赛事2号种子纳达尔",
"alias":[
]
},
{
"argument_start_index":48,
"role":"败者",
"argument":"赛会5号种子梅德韦杰夫",
"alias":[
]
}
],
"class":"竞赛行为"
},
{
"event_type":"竞赛行为-夺冠",
"trigger":"冠军",
"trigger_start_index":111,
"arguments":[
{
"argument_start_index":0,
"role":"时间",
"argument":"北京时间今天凌晨4点",
"alias":[
]
},
{
"argument_start_index":36,
"role":"冠军",
"argument":"本届赛事2号种子纳达尔",
"alias":[
]
}
],
"class":"竞赛行为"
}
]
}二、DuEE-Fin篇章集事件标注数据
DuEE-fin是百度最新发布的金融领域篇章级事件抽取数据集,包含13个事件类型的1.17万个篇章,同时存在部分非目标篇章作为负样例。事件类型来源于常见的金融事件,数据集中的篇章来自金融领域的新闻和公告。
对于篇章而言,一个篇章也可能论述多种事件类型下的多个事件。如下信息所示,一个事件标注样本包括原文本"text"、事件列表"event_list",其中包括具体的触发词"trigger"、事件类型"event_type"、论元角色"role"以及论元值"argument"。
{
"text": "原标题:华通医药(12.740,-0.30,-2.30%)超26亿并购重组明日上会 股票停牌来源:新京报\n新京报讯(记者 王卡拉)华通医药拟发行股份购买浙农集团股份有限公司(简称浙农股份)100%股权事宜又有新进展。6月10日晚间,华通医药发布公告,中国证监会上市公司并购重组审核委员会将于6月11日上
午审核华通医药并购重组事项,为避免引起公司股票和可转换公司债券价格异常波动,公司股票及可转债将自2020年6月11日开市起停牌,待收到并购重组委审核结果后,公司将及时公告并申请复牌。\n6月2日,华通医药发布此次并购重组的草案,公司拟发行股份购买浙农控股、泰安泰、兴合集团、兴合创投、汪路平等16名自然人合计持有的浙农股份100%股权,交易作价26.67亿元。本次交易的交易对方浙农控股系华通集团控股股东,通过华通集团间接控制华通医药26.23%股权,为上市公司的关联方。同时,上市公司向浙农控股发行的股份数预计超过本次交易后上市公司总股本的5%,因此构成关联交易。\n根据协议,浙农股份2019年、2020年、2021年和2022年经审计的税后净利润分别不低于2.12亿元、2.27亿元、2.45亿元和2.59亿元。但浙农股份资产负债率较高,2016年末、2017年末、2018年末、2019年末,浙农股份的资产负债率分别为69.57%、67.90%、69.87%和59.57%。",
"event_list": [
{
"trigger": "并购",
"event_type": "企业收购",
"arguments": [
{"role": "收购方", "argument": "华通医药"},
{"role": "被收购方", "argument": "浙农集团股份有限公司"},
{"role": "收购标的", "argument": "100%股权"},
{"role": "披露时间", "argument": "6月10日晚间"}
]
},
{
"trigger": "购买",
"event_type": "企业收购",
"arguments": [
{"role": "收购方","argument": "华通医药" },
{"role": "收购标的", "argument": "100%股权"},
{"role": "交易金额", "argument": "26.67亿元"},
{"role": "被收购方", "argument": "浙农股份"},
{"role": "披露时间", "argument": "6月2日"}
]
}
],
"id": "1a7527e1e7b2abd1b1977a2e373281ee",
"title": "华通医药超26亿并购重组明日上会 股票停牌"
}不过,这份数据中并没有标注出论元位于所在文本中的索引位置,需要进一步进行回标。
三、基于开源工具MarkTool进行事件标注
MarkTool是一款基于web的开源通用文本标注工具,支持大规模实体标注、关系标注、事件标注、文本分类、基于字典匹配和正则匹配的自动标注以及用于实现归一化的标准名标注,同时也支持文本的迭代标注和实体的嵌套标注。
地址:https://github.com/FXLP/MarkTool
我们在本文中进行事件标注实践,具体步骤如下:
1、事件本体定义
定义第一类事件类型及其论元。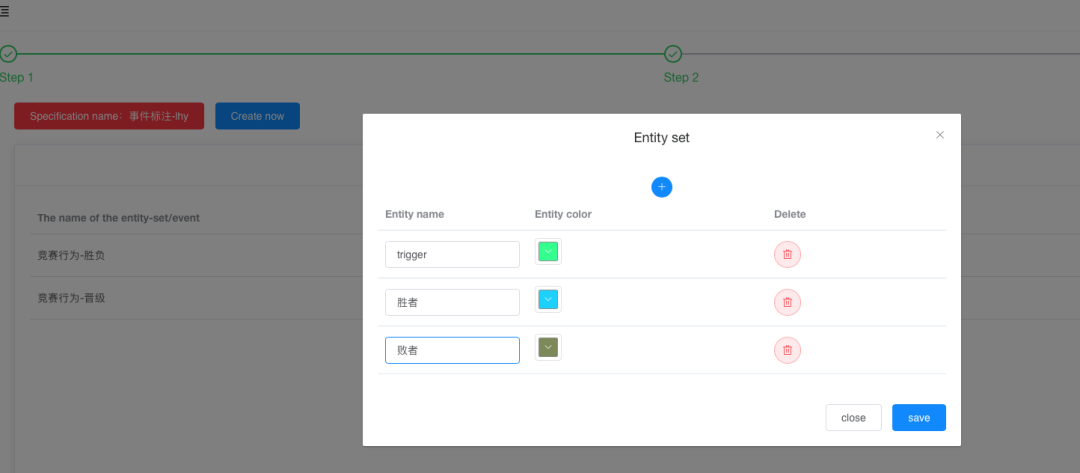 定义第二类事件类型及其论元。
定义第二类事件类型及其论元。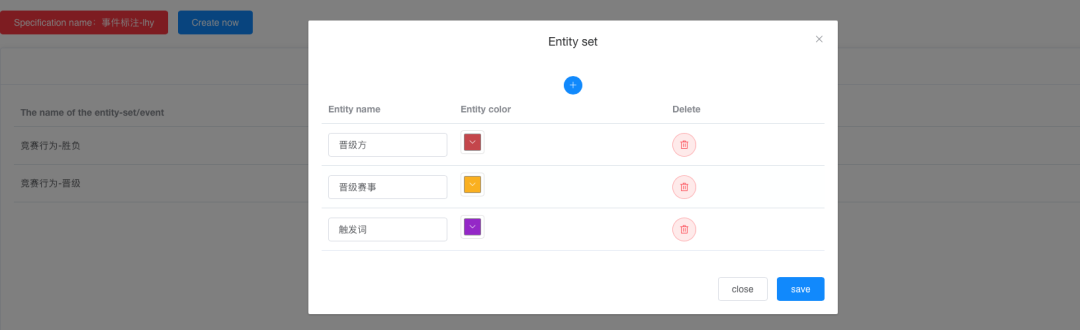
2、标注数据上传
选择需要标注的文本数据,进行标注。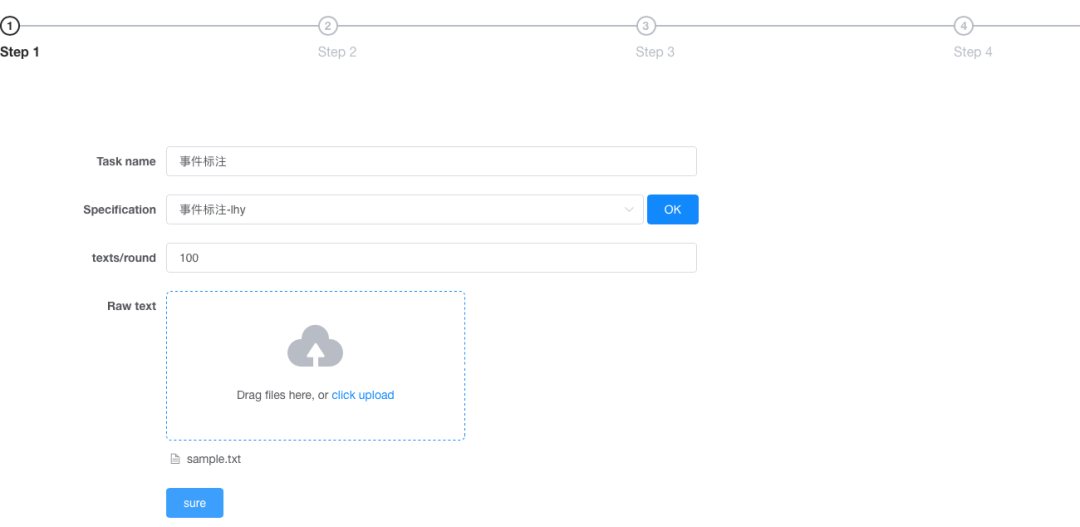
3、标注过程
新建第一个标注事件类型,生成事件ID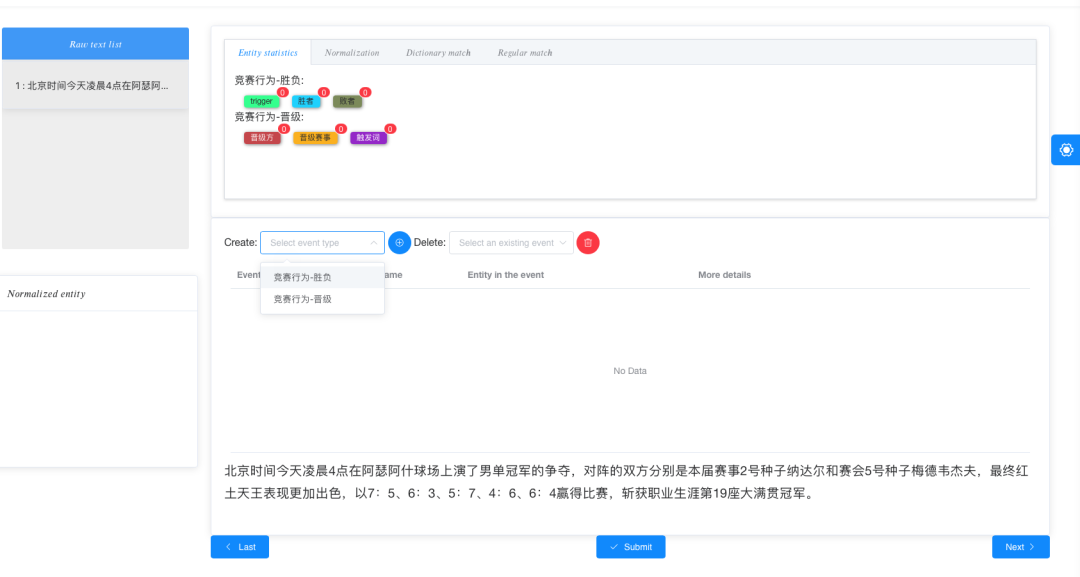
标注事件论元,选中标记的文本片段,并选择其所担任的事件角色。
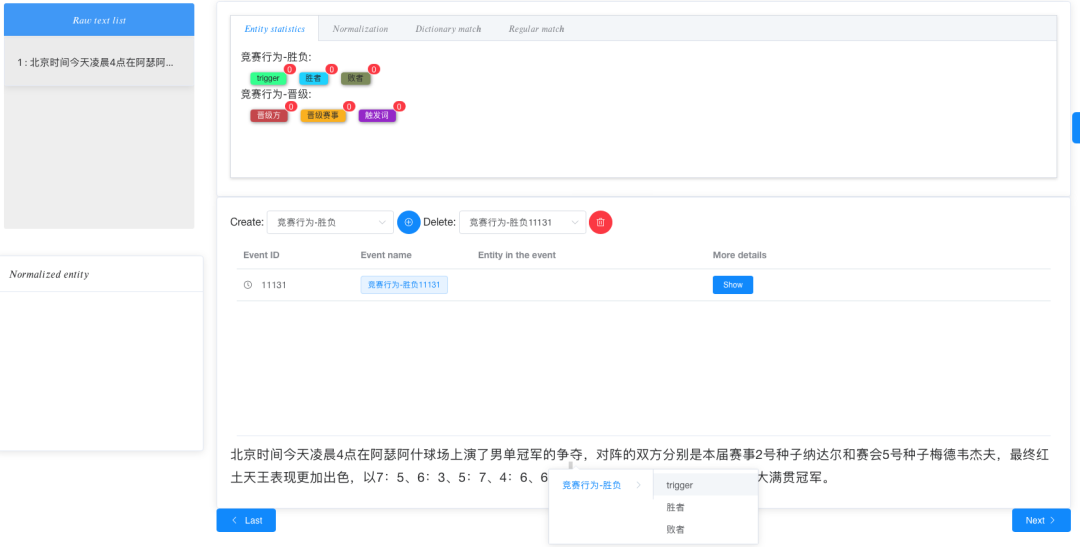
依存标注相应的事件论元角色:
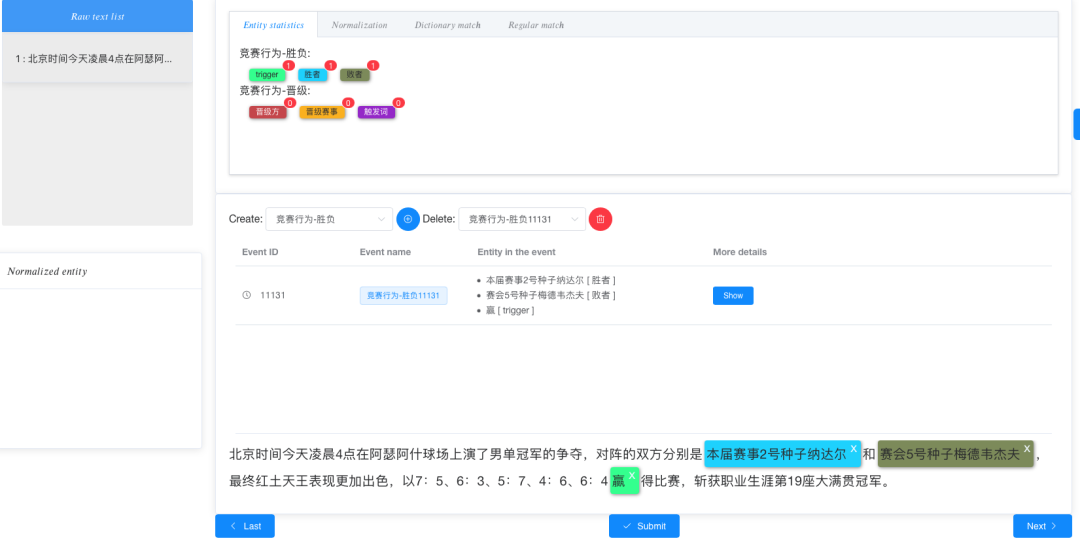
从中我们发现,在标注结果中,我们分别得到了不同事件的论元结果。同样的,新建第二个标注事件类型,生成事件ID,并展开标注。
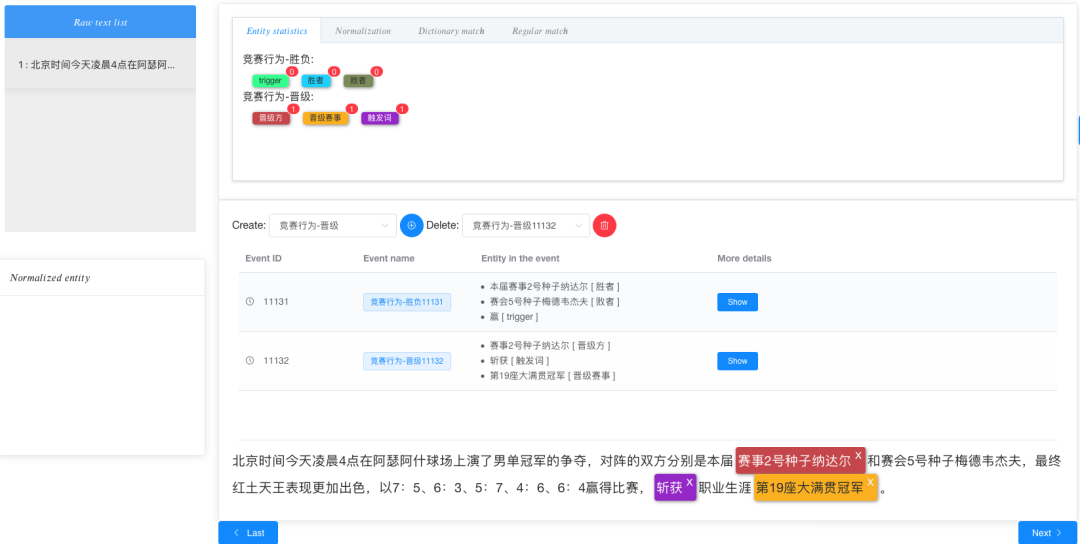
在标注完所有事件后,提交标注结果,即可完成一个事件标注。
总结
本文主要围绕着事件标注这一主题,以DuEE句子级事件标注数据、DuEE-Fin篇章集事件标注数据两个开放评测数据出发,说明了事件标注的基本内容,第三部分,我们以开源标注工具MarkTool进行事件标注进行了实践,从中可以进一步地了解事件标注的具体过程。
实践与理论相结合,将会有更为深入的体会和收获,愿大家一起动手起来。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。














 5618
5618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









