







笔记整理:朱渝珊,浙江大学博士,研究方向为知识图谱快速表示学习、大规模知识图谱预训练
链接:https://linkinghub.elsevier.com/retrieve/pii/S0950705122013417
1、动机
知识图谱(KGs)由许多形如(h,r,t)的三元组组成,其中h、r和t分别表示头实体、关系和尾实体。知识图谱可应用于若干知识驱动任务,如问答、对话和信息检索系统。由于KG的不完整性,知识图谱补全(knowledge graph completion, KGC)成为了一个重点研究方向,旨在通过发现知识图谱中的缺失信息并对其进行补全。在所有实体和关系都已知且可训练的前提下,KGC方法可以分为两种类型:基于嵌入的方法和基于文本的方法。前者通过评分函数学习知识图谱的结构信息,后者通过预训练语言模型编码文本描述等附加文本来学习实体和关系的文本信息。然而,随着知识的不断增长,出现了大量的新实体,这导致了知识图谱对新实体的扩展需求。开放世界知识图谱学习任务被形式化地定义为一种将新实体扩展到已有知识图谱的任务,因为这些新实体无法被训练,成为零样本学习问题。现有模型通常合并可用的实体名称和实体描述构建基于文本的嵌入,然后通过传统的KGC模型(如TransE、RotatE和ComplEx)来学习KG结构,将嵌入转换到图向量空间。尽管目前使用预训练语言模型(PLM)初始化文本嵌入的KGC方法(KG-BERT、SimKGC和MEM-KGC)表现出优越的性能,但KG-BERT和SimKGC需要大量负样本和对比学习训练策略,它们面临的一大挑战是效率低下。MEM-KGC利用了掩码语言模型(MLM)的分类过程,在保证性能的前提下也增加了运行时间,本文针对开放世界KGC的特点,对MEM-KGC进行了扩展,提出了一种新的模型,高效地完成知识图谱对新实体的扩展。
2、方法
给定一个不完整的三元组(h,r),其中h是一个新实体,我们可以通过在KG中存在的所有实体中选择一个可以连接新实体的实体来扩展KG。换句话说,该任务可以解释为一个分类过程,从固定数量的实体中对实体进行分类。因此,定义两个任务:实体描述预测(EDP)是一个辅助任务,用给定的文本描述预测相应的实体,不完全三元组预测(ITP)是一个目标任务,为给定的不完全三元组(h,r)预测一个合理的实体。
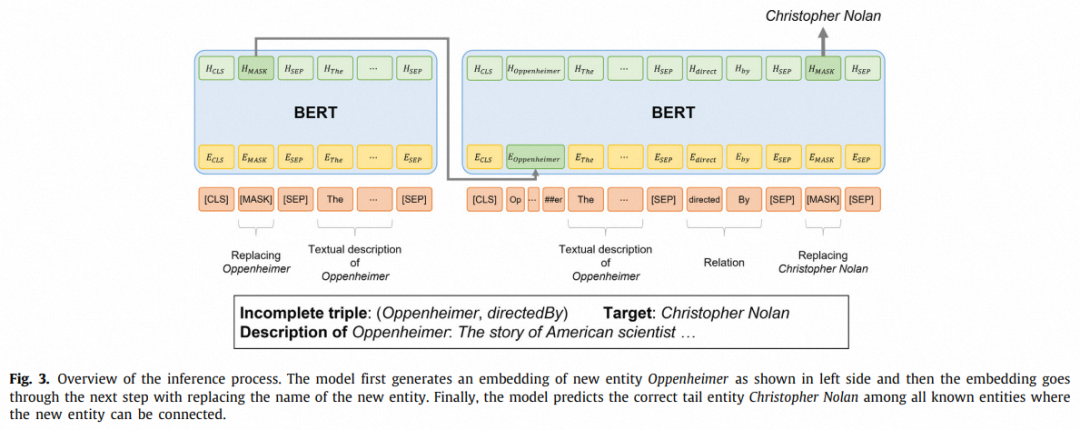
EDP和ITP两个任务通过pipeline框架运行,如上图所示。对给定的不完整三元组(h,r), EDP的输入为头实体h文本描述的单词token序列拼接一个[MASK] token。EDP的输出(最后一层[MASK]对应的隐藏状态) 会作为ITP的输入中头实体的嵌入。ITP模块的输入为头实体token、头实体描述的词token序列、关系token、代表尾实体的[MASK] token的拼接,其中头实体token的嵌入被替换为。ITP的输出(最后一层[MASK]对应的隐藏状态)被用于分类预测尾实体。
该模型基于多任务深度神经网络(MT-DNN)架构,同时执行两个任务。EDP中使用预测头实体,ITP中使用预测尾实体。两个任务联合训练。此处EDP模块的重要性在于,由于开放世界KGC的挑战是在推理中为给定的输入处理新实体,新实体token都未经训练,只使用ITP模块进行开放世界KGC会使得新实体的token可能不能被很好地微调,训练EDP模块使其能基于新实体文本描述生成的新实体嵌入,用EDP生成的新实体嵌入替换ITP中新实体的token嵌入可以很好地解决这个问题。
3、实验
数据集:
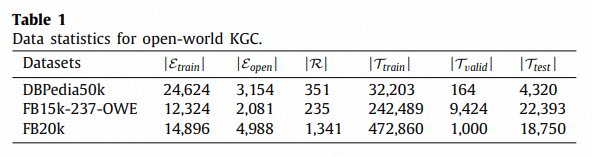
与现有的开放世界KGC模型进行性能比较:
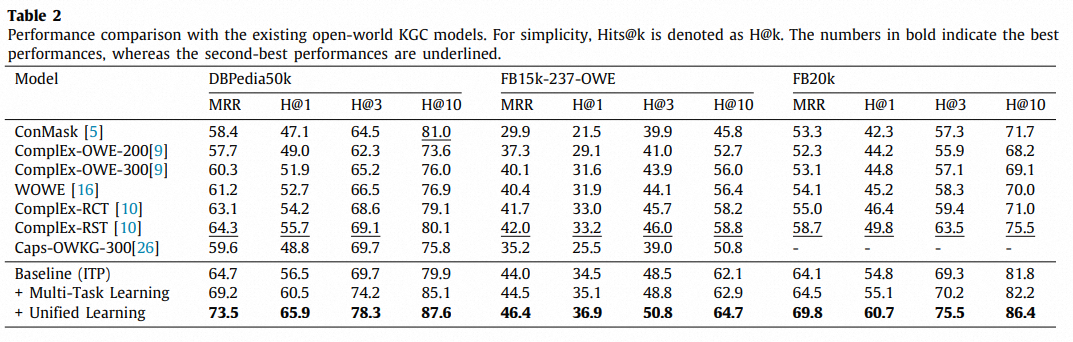
封闭世界KGC模型与基于PLM模型的性能比较:

在开放世界KGC和基于PLM模型上的性能比较:
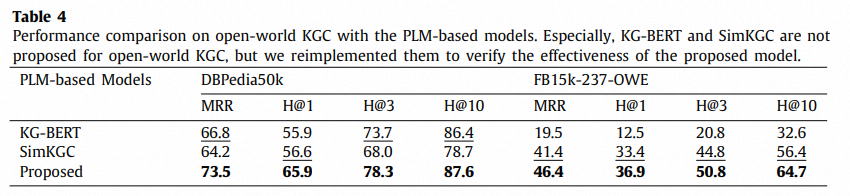
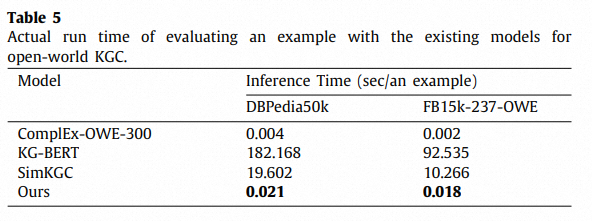
运行效率对比:
4、总结
本文提出了一种有效的开放世界KGC模型。采用MLM过程和MT-DNN架构相结合的预训练语言模型,称为统一学习方法。该模型在三个基准数据集上取得了新的最先进的性能。通过与其他基于预训练语言模型的模型(如KG-BERT和SimKGC)对比,证明了该模型的有效性和高效性。不足之处在于,文中使用的数据集实体数量不算大(万级),因此可以很容易地采用多分类方法。然而,可能存在一个问题是无法扩展到具有数百万实体的现实世界的知识图谱。因此,可伸缩性对于处理大量实体而不降低性能和效率非常重要。此外,本研究只注重利用语义信息来扩展知识图谱,而结构信息可以联合用于分类。目前一些潜在的研究引入神经网络或自编码器来表示知识。因此,未来的研究之一可能是联合利用语言模型和图神经网络来捕捉KGs的语义和结构信息。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。














 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









