






转载公众号 | 东南COIN
题目:AsdKB: A Chinese Knowledge Base for the Early Screening and Diagnosis of Autism Spectrum Disorder
作者:吴天星1、曹旭东1、朱益鹏1、吴飞跃1、龚天凌1、王宇翔2、景慎旗3
作者单位:1东南大学认知智能研究所,2杭州电子科技大学,3南京医科大学
论文:ISWC 2023
论文链接:https://link.springer.com/chapter/10.1007/978-3-031-47243-5_4
数据链接:https://github.com/SilenceSnake/ASDKB
开放许可协议:CC BY-SA 4.0
欢迎转载,转载请注明出处
01
摘要
为了方便地获得有关孤独症谱系障碍的知识并辅助进行早期筛查和诊断,我们构建了中文首个孤独症谱系障碍知识库AsdKB。该知识库的知识主要包括 1)疾病知识:来源于SNOMED CT和《ICD-10精神与行为障碍临床描述》中的疾病和症状描述,2)诊断知识:来源于DSM-5中的诊断标准以及社会组织和医疗机构推荐的筛查量表,3)专家知识:来源于医疗网站的孤独症相关医生和医院信息。AsdKB包含本体和实例,并且可以作为链接数据访问https://w3id.org/asdkb/。AsdKB的潜在应用是问答、辅助诊断和专家推荐,我们已经建立了一个原型系统,可在http://asdkb.org.cn/上访问。
02
动机
孤独症谱系障碍(ASD)是一种开始于0-3岁并可能影响终身的神经发育障碍。患有ASD的孩子不仅在社交互动方面存在问题,并可能表现出刻板重复的行为或兴趣。根据美国疾病控制与预防中心(CDC)最新的统计数据[1],在8岁的儿童中,大约有1/36的儿童被识别为患有ASD,这一比例相当高。然而,目前尚无定量的医学测试可用于ASD的诊断,专业医生只能依赖筛查量表的结果和一段时间的行为观察来做出诊断。这导致许多儿童直到较大年龄才能获得最终诊断,导致患病儿童无法获得他们所需的早期治疗。
在中国,对ASD儿童的筛查和诊断情况可能更为困难。《中国儿童发育障碍康复报告》(2020年)指出,中国的ASD发病率约为1%,ASD患儿数量超过三百万,但能够诊断ASD的专业医生数量仅约为500人,更不用说获得行为分析师认证的人数。这显然阻碍了ASD的及时诊断,因此我们思考是否可以应用人工智能技术来解决ASD的早期筛查和诊断问题。其中的关键问题在于如何从不同信息源中提取和整合与ASD相关的知识,以支持更高级别的智能应用。
03
贡献
为了解决这个问题,我们建立了AsdKB,一个用于孤独症谱系障碍早期筛查和诊断的中文知识库,涵盖了多个信息源,包括 SNOMED CT[2](医学术语集合)、ICD-10[3](世界卫生组织发布的疾病分类系统第10版)精神和行为障碍的临床描述、DSM-5[4](《精神障碍的诊断与统计手册》第5版)及CDC(美国疾病控制与预防中心)推荐的筛查工具等。
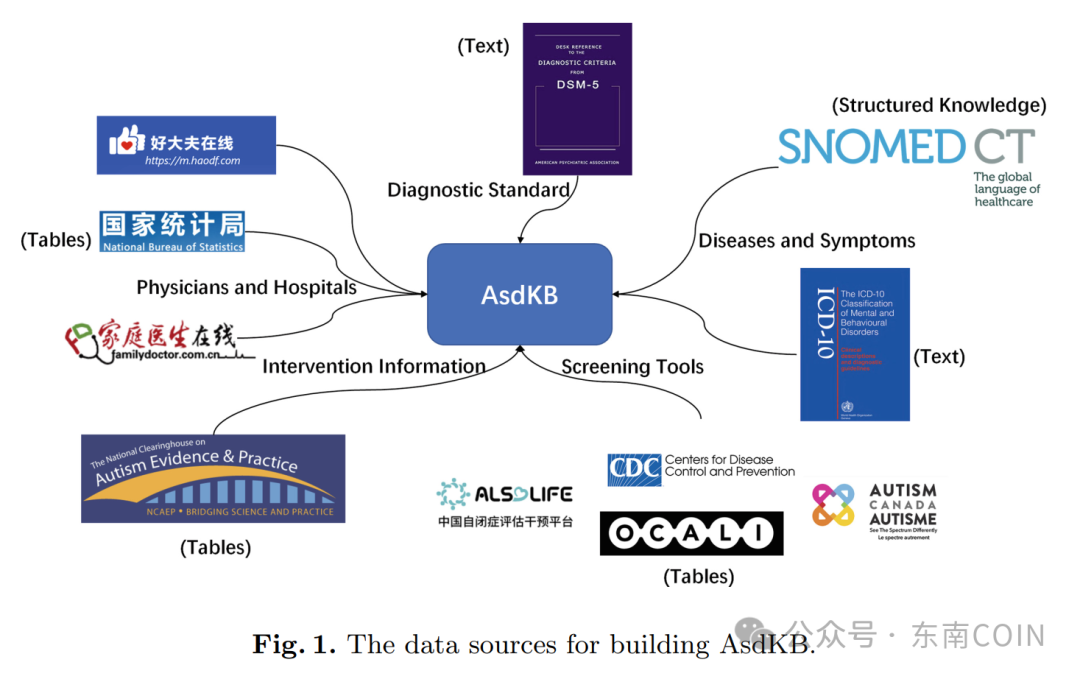
图1 构建AsdKB的数据来源图
具体而言,我们首先构建本体,以涵盖来自各个来源的有关孤独症谱系障碍筛查和诊断的重要概念。利用该本体作为架构,我们进一步提取和整合有关疾病、诊断、专家等方面的事实知识。此外,我们使用Web包装器和自然语言处理技术,用于处理不同格式的数据,对它们进行提取、翻译,对齐等操作。AsdKB中的所有类、属性和实例都通过w3id中的可永久解引用的URI进行标识。所有数据都可以在Zenodo上作为RDF转储文件获得,并且可以在Github上访问AsdKB项目的基本信息。
同时,我们还基于AsdKB建立了一个包含问答、辅助诊断和专家推荐三个部分的原型系统,并讨论了如何用该系统支持ASD的早期筛查和诊断。可以在http://asdkb.org.cn/ 上访问并试用。
04
本体简介
孤独症谱系障碍知识库的建立首先需要一个完备的本体结构。我们依照Ontology Development 101[5]的7步法进行本体构建。
首先,我们明确了本体的领域和范围,以确保本体涵盖与孤独症谱系障碍早期筛查和诊断相关的关键知识。其次,考虑了现有的本体,我们重用了rdf:type、rdfs:label和owl:equivalentClass等属性关系。接着,通过阅读来自CDC、DSM-5、ICD-10、SNOMED CT和其他网络来源的ASD材料,我们选取了一系列重要概念级术语,涵盖了疾病、症状、筛查量表、诊断标准以及专家知识等方面。在此基础上,我们定义了本体中的类别和类别层次结构,例如疾病类别和诊断类别,并创建了相应的子类关系。随后,我们为每个类别添加属性,包括数据属性和对象属性,以捕捉各类关联信息。最后,我们通过定义每个属性的范围,明确了它们的值类型。实例的创建则是作为事实知识提取的下一步。总体而言,本体构建的这一过程确保了AsdKB知识结构完备,有助于更好的支持应用。
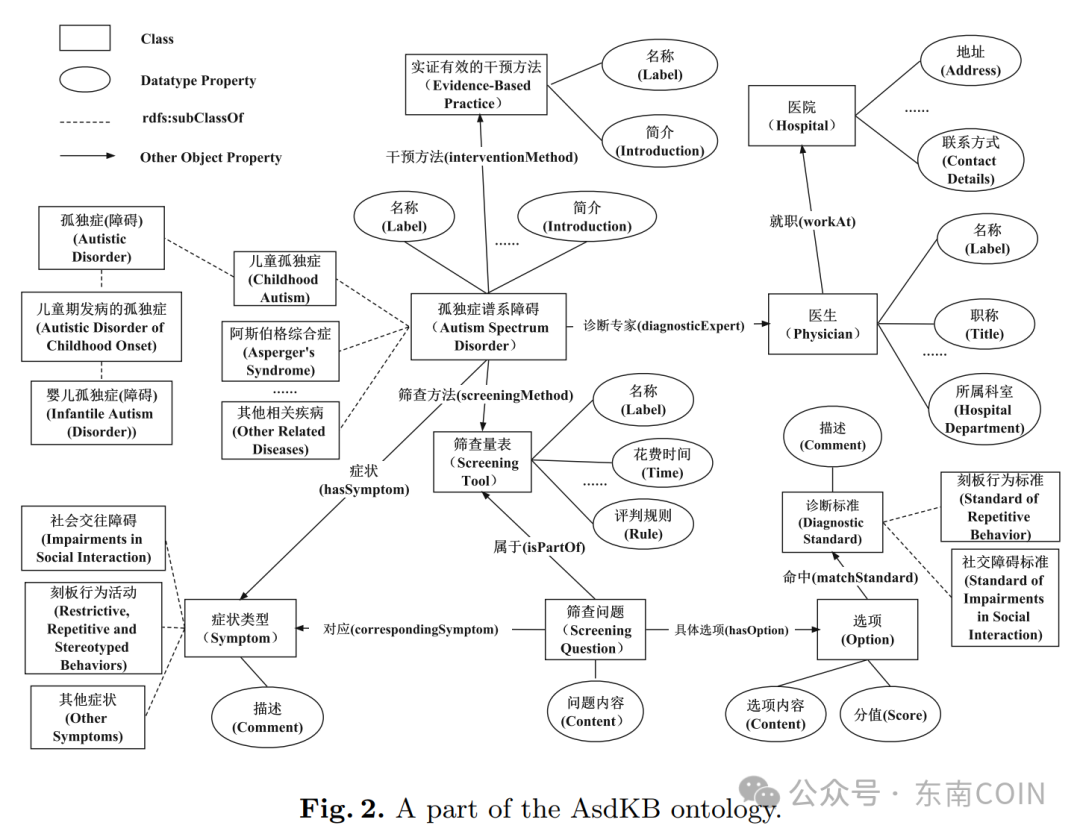
图2 AsdKB的部分本体图
最终的本体包含32个类、25个数据类型属性和16个对象属性。类层次结构中类的最大深度为4。
05
实例抽取
孤独症谱系障碍实例的抽取是一个复杂而多层次的过程,根据不同的知识类别划分为疾病知识抽取、诊断知识抽取、专家知识抽取以及其他知识抽取四个部分。总计提取了6,166个实体,形成了69,290个三元组。该过程涉及从多元异构数据抽取知识,并对这些信息进行整合和处理,以构建一个全面而深入的ASD知识库。
疾病知识抽取:我们为AsdKB本体中的疾病和症状类型进行实例抽取。疾病实例,例如“非典型雷特综合症”,是从SNOMED CT中获取的。SNOMED CT为树状结构的医学术语库,疾病实例对应于其中ASD的叶节点。同时我们提取了每个疾病实例的属性值,包括Label(实例名称)、SCTID(SNOMED CT中的术语ID)、ICD-10 code(ICD-10类别)和Synonym(疾病的同义表述)。此外,我们通过设计正则表达式,我们从《ICD-10精神与行为障碍临床描述》中提取了Introduction(疾病实例的简要描述)、Patient Groups(患病群体,例如,“儿童”或“女孩”)和Pathogeny(遗传因素,例如,“遗传和环境因素”)的值。我们通过Google翻译和手动校对获得了属性的中文版本。总共,我们收集了49个与ASD相关的疾病实例及其属性信息。
在症状类型实例抽取方面,我们从《ICD-10精神与行为障碍临床描述》的文本中获取症状表述。首先人工选取了部分关键字,然后将文档按照段落分割,并利用TF-IDF[6]算法来识别关键字,标注了一部分的症状实例以训练提取模型。我们将抽取看作序列标注任务,使用BioBERT[7]进行编码和BiLSTM[8]进行文本上下文特征捕捉,最终通过CRF[9]完成序列标注,从《ICD-10精神与行为障碍临床描述》中提取症状实例。在标注过程中将症状实例自然地分类到预定义的症状类别,包括“社交互动障碍”、“限制性、重复性和刻板印象行为”以及“其他症状”。通过训练模型的筛选高质量结果,积累了标记数据,重复这一过程以提高模型的效果。最终,我们通过Google翻译获取了每个症状实例的中文描述。在整个过程中,我们总共收集了65个症状实例。

图3 症状三元组示例图
诊断知识抽取:在诊断知识方面,我们抽取了诊断标准、筛查量表、筛查问题以及相应选项的实例知识。诊断标准的实例来自DSM-5的中文版本,采用了类似提取症状实例的过程。与症状实例不同,诊断标准的实例不涉及ASD患者的具体行为,例如,AsdKB中的诊断标准实例表达为“眼神接触、手势、面部表情、身体定位或言语语调等方面的缺乏、减少或不合规的使用”,对应于多个症状实例:”不会进行对视“、“很少微笑”。我们总共收集了43个诊断标准实例。
我们从社会组织和医疗机构的网站包括CDC(美国疾病控制与预防中心)、ALSOLIFE(ASD评估与干预平台)和OCALI(俄亥俄州孤独症和低发病率中心)等中提取关于筛查工具、筛查问题和选项的实例,及其相应的属性值。AsdKB中的筛查量表,具有属性Introduction(基本信息和说明)、Author(作者)、User(填写量表的人,例如父母或老师)、Age(适用于筛查目标的年龄)、Time(填写量表所需的时间)、Rule(筛查原则和详细信息)和Screening Boundary(完成量表后的筛查边界得分)。我们提取了20个筛查量表的实例,其中包括15个英文筛查量表和5个中文筛查量表,如ABC[10]、CARS2[11]、M-CHAT[12]等。在这里,我们使用Google翻译将英文量表翻译成中文,并进行了手动校对。
同时我们还在筛查问题实例和症状实例之间建立了correspondingSymptom关系,在选项实例和诊断标准实例之间建立了matchStandard关系。这两种关系(即对象属性)有助于解释筛查结果。AsdKB可以告诉用户当前问题调查的是什么具体症状,以及当前选项是否与某个诊断标准相匹配,从而帮助用户更好地理解筛查问题并为筛查结果提供解释。为了识别correspondingSymptom关系,我们首先使用FNLP[13]对筛查问题实例和症状实例进行中文分词。去除停用词后,我们比较两个词序列之间的字符串相似性,以决定是否存在correspondingSymptom关系。提取matchStandard关系的方法与correspondingSymptom关系类似,唯一的区别是还需额外考虑每个选项的Score属性。如果一个选项的分数最高或最低,这意味着当前筛查问题的结果是异常的(这取决于筛查量表的设计),异常结果有助于识别matchStandard关系。
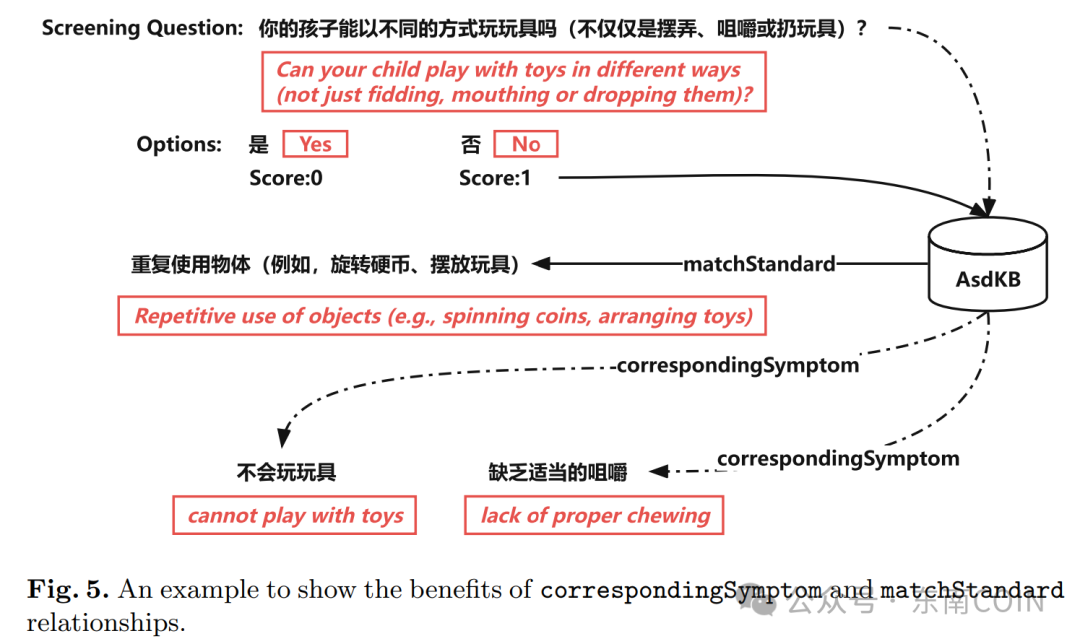
图4 展示correspondingSymptom与matchStandard关系作用的例子
专家知识抽取:我们从网络中提取了专业医生实例及其所在医院实例。我们选择了好大夫在线(www.haodf.com)和家庭医生在线(www.familydoctor.com.cn)作为数据来源。我们通过搜索“孤独症”“自闭症““孤独症谱系障碍““广泛性发育障碍“等关键词来搜索相关的医生。从信息框表格中抽取医生的相关信息,我们总共收集了499个医生实例。同时根据抽取到的医生,我们定位了医生工作的医院,作为医院实例。我们总共收集了270个医院实例。
由于医生和医院实例是从不同的来源提取的,我们使用启发式方法进行实例匹配。例如:给定两个医院实例,如果它们的Address(地址)和Contact Details(联系方式)属性中至少有一个值相同,则将它们视为相同医院。给定两个医生实例,如果它们的workAt(工作医院)属性的值是等效的,且Name(姓名)和Title(职称)属性的值分别相同,那么这两个实例被确定为同一个医生。
其他知识抽取:我们还抽取了ASD的干预方法实例和中国行政区实例。干预方法实例是实证有效的干预方法,包括“离散训练法”、“社交技能训练”、“基于同伴的指导和干预”等。而结合专家知识中的医院实例,一个潜在的应用是向医生寻求诊断方面的帮助。为了找到目标地区的专业医生,我们从国家统计局提取了中国行政区划的实例。
06
AsdKB质量分析
AsdKB包含6,166个实体以及69,290个三元组。所有类URI在命名空间http://w3id.org/asdkb/ontology/class/中,实例URI在命名空间http://w3id.org/asdkb/instance/中,都是可访问的。为了评估AsdKB的质量,我们设计了两种评估方法:准确性评估和任务评估。
准确性评估:由于没有可用的真实数据集,也无法人工评估所有三元组。因此,我们采用了一种随机评估策略。我们首先随机选择了100个分布在不同类和实例中的实体,并获得了关于这些实体的全部732个三元组。这些样本可以反映整个知识库中三元组的分布情况。然后我们进行手动标记以评估样本的准确性。通过评估样本的准确性来估计整个AsdKB的准确性。
有五位研究生参与标记过程。我们提供了三个选项,分别是“正确”、“不正确”和“未知”来标记每个样本。每个学生标记完所有样本后,我们计算平均准确性。最后,我们使用和YAGO[14]、Zhishi.me[15]和Linked Open Schema[16]一样的评估方式,通过计算α=5%时的Wilson区间将我们对子集的发现扩展到整个知识库。对于随机选择的732个三元组,平均“正确”票数为712,因此准确性为97.02% ± 1.21%,这证明了AsdKB的高质量。
任务评估:除了AsdKB中三元组的准确性,我们还尝试评估AsdKB在回答与真实世界相关的孤独症谱系障碍问题的有效性。因此,我们从医疗网站“好大夫在线”和“家庭医生”中收集了100个关于ASD的常见问题(例如,“孤独症的临床表现有哪些?”和“哪些干预方法有效?”)。我们将AsdKB存储在图形数据库Neo4j[17]中,并邀请五位研究生手动编写Cypher语句(Neo4j的图形查询语言)进行查询,以检查返回的查询结果是否能回答问题。根据上述评估,AsdKB能回答81个问题,即覆盖率达到81%,这反映了AsdKB的实用性。
07
原型系统
问答系统:我们基于AsdKB实现了一个自然语言问答(QA)系统,期望该系统能够回答关于ASD的各种常识和事实性问题。AsdKB存储在Neo4j中,因此我们的目标是将每个自然语言问题转化为一个Cypher查询,查询图数据库并返回答案。我们采用两种策略来设计QA系统。第一种策略是手动编写常见的ASD相关问题以及对应的Cypher查询语句。如果用户查询与我们的模板匹配,我们就构造并执行相应的Cypher查询,从而获取答案。如果用户查询不匹配我们的模式,我们使用第二种策略,该策略应用了将自然语言问题转化为形式查询的方法[18],采用语义查询图建模,以生成Cypher查询。
我们还检测每个问题的意图,以确定用户是否想进一步填写筛查量表。如果用户表现出意图,系统将直接提供辅助诊断的链接,以帮助用户跳转筛查量表页面。意图识别被建模为二元分类任务,我们使用BERT对用户的问题进行编码,然后训练一个SVM[19]分类器来预测用户是否需要进行筛查。
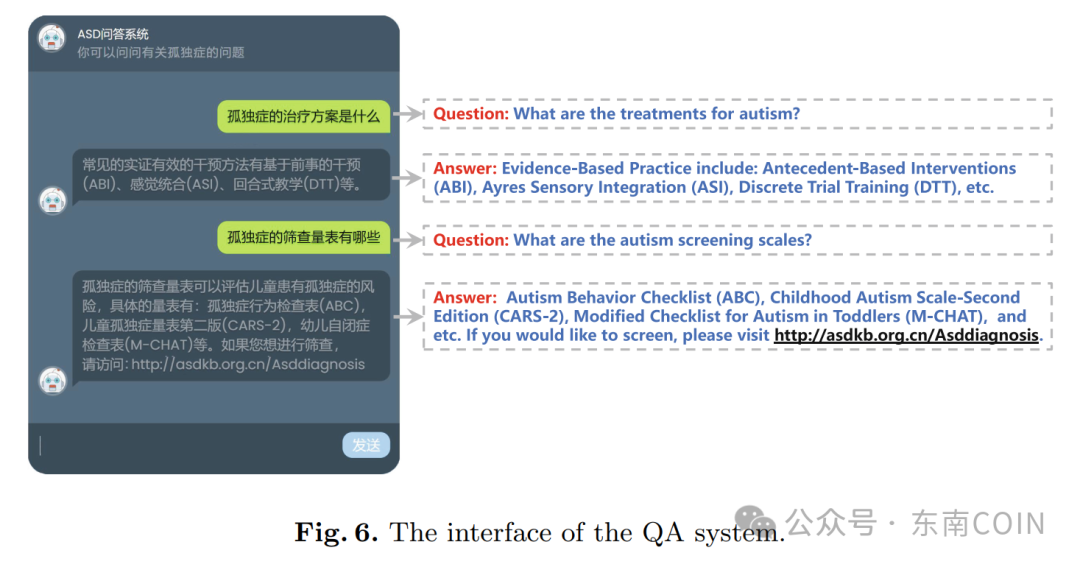
图5 问答系统展示图
辅助诊断系统:我们基于AsdKB开发了一个辅助诊断系统。该系统为用户提供筛查量表,评估其患有孤独症谱系障碍的风险。只要筛查量表的筛查结果显示患有风险,系统就会提示用户寻求专业的医学评估,并使用我们的专家推荐系统推荐专家。
在填写筛查量表之前,用户可以根据自己的情况选择适当的条件,系统将返回相应的筛查量表并附有简要介绍。完成一个筛查量表后,系统将根据所有选项的总分和筛查边界给出筛查结果(即是否有风险)。

图6 辅助诊断流程展示图
专家推荐系统:如果我们的辅助诊断系统报告用户存在患有孤独症谱系障碍的风险,那么用户就可能有寻找ASD诊断专家的需求。因此,我们设计了一个基于AsdKB的专家推荐系统,实现了对专家的多维度检索。用户可以通过选择复选框或直接点击地图上的位置来选择目标区域。推荐结果是一个医师列表,包括他们的姓名、职称、医院科室、医院、医院地址和专业领域。
推荐分为两个步骤:候选医师生成和候选医师排序。在候选医师生成中,我们使用AsdKB中医院位置信息匹配用户选择的行政区划,工作在这些医院的医师成为候选人。如果行政区划没有候选医师返回,我们将通过纬度和经度的距离计算考虑周围行政区划中的更多医院。在候选医师排序中,我们考虑了三个方面。首先,职称越高,排名越高。其次,医院级别越高,排名越高。最后,用户反馈中的点赞数减去点踩数越高,排名越高。

图6 专家推荐展示图
08
总结和展望
我们通过从不同格式的数据源中提取和整合知识,构建并发布了名为AsdKB的孤独症谱系障碍的中文知识库。据我们所知,AsdKB是目前最全面的ASD知识库,能够支持ASD早期筛查和诊断的不同应用,如问答、辅助诊断和专家推荐等。然而,我们的工作仍然存在局限性,我们计划在未来解决这些问题。
AsdKB的质量方面:在我们对AsdKB的初步评估中,我们发现知识库中包含的实体质量很高。但是,在自动提取过程中还存在错误。这些错误来源于各种因素,如原始数据源的质量不足、数据格式的差异以及我们的整合方法准确性有待提升。为了解决这个问题,我们计划引入众包技术来持续修复AsdKB中现有的错误,并研究自动错误检测方法,以确保在知识更新过程中的知识准确性。
AsdKB的应用方面:我们已经探索了AsdKB的多种应用,包括问答、辅助诊断和专家推荐。集成的原型系统已经证明了AsdKB在ASD早期筛查和诊断中发挥关键作用的潜力。我们将在原型系统中使用更多基于用户日志数据的机器学习模型,进一步提高问答和辅助诊断的准确性。此外,我们计划使用AsdKB分析真实的电子病历,以协助医生进行ASD诊断。通过分析病历中的症状表现和其他相关信息,AsdKB可以辅助医生做出更准确的诊断,并为ASD患者提供个性化的治疗建议。
参考文献
[1]Maenner, M.J., et al.: Prevalence and characteristics of autism spectrum disorder among children aged 8 years- autism and developmental disabilities monitoring network, 11 sites, United States, 2020. MMWR Surveill. Summ. 72(2), 1 (2023)
[2]Donnelly, K.: SNOMED-CT: the advanced terminology and coding system for eHealth. Stud. Health Technol. Inform. 121, 279 (2006)
[3]World Health Organization: The ICD-10 Classification of Mental and Behavioural Disorders: clinical descriptions and diagnostic guidelines. World Health Organization (1992)
[4]American Psychiatric Association: Diagnostic and Statistical Manual of Mental Disorders: DSM-5, vol. 5 (2013)
[5]Noy, N.F., McGuinness, D.L.: Ontology development 101: a guide to creating your first ontology. Technical report, Standford University (2001)
[6]Leskovec, J., Rajaraman, A., Ullman, J.D.: Mining of Massive Data Sets. Cambridge University Press, Cambridge (2020)
[7]Lee, J., et al.: BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36(4), 1234–1240 (2020)
[8]Graves, A., Schmidhuber, J.: Bidirectional LSTM networks for improved phoneme classification and recognition. Neural Netw. 18(5–6), 602–610 (2005)
[9]Lafferty, J.D., McCallum, A., Pereira, F.C.: Conditional random fields: probabilistic models for segmenting and labeling sequence data. In: Proceedings of ICML, pp. 282–289 (2001)
[10]Krug, D.A., Arick, J., Almond, P.: Behavior checklist for identifying severely handicapped individuals with high levels of autistic behavior. Child Psychol. Psychiatry Allied Disciplines (1980)
[11]Schopler, E., Van Bourgondien, M., Wellman, G., Love, S.: Childhood Autism Rating Scale-Second Edition (CARS-2). Western Psychological Services, Los Angeles (2010)
[12]Wright, K., Poulin-Dubois, D.: Modified checklist for autism in toddlers (M-CHAT): validation and correlates in infancy. Compr. Guide Autism 80, 2813–2833 (2014)
[13]Qiu, X., Zhang, Q., Huang, X.J.: FudanNLP: a toolkit for Chinese natural language processing. In: Proceedings of ACL, pp. 49–54 (2013)
[14]Hoffart, J., Suchanek, F.M., Berberich, K., Weikum, G.: YAGO2: a spatially and temporally enhanced knowledge base from Wikipedia. Artif. Intell. 194, 28–61 (2013)
[15]Wu, T., et al.: Knowledge graph construction from multiple online encyclopedias. World Wide Web 23, 2671–2698 (2020)
[16]Wu, T., Wang, H., Qi, G., Zhu, J., Ruan, T.: On building and publishing linked open schema from social web sites. J. Web Semant. 51, 39–50 (2018)
[17]Webber, J.: A programmatic introduction to Neo4j. In: Proceedings of SPLASH, pp. 217–218 (2012)
[18]Zou, L., Huang, R., Wang, H., Yu, J.X., He, W., Zhao, D.: Natural language question answering over RDF: a graph data driven approach. In: Proceedings of SIGMOD, pp. 313–324 (2014)
[19]Hearst, M.A., Dumais, S.T., Osuna, E., Platt, J., Scholkopf, B.: Support vector machines. IEEE Intell. Syst. Appl. 13(4), 18–28 (1998)
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









