







如何从0到1训练千亿大模型?
怎样提升大模型长文本能力?
抖音RAG技术方案选型
LLM在大数据、数据分析中落地探索
大模型在搜索、推荐、广告、金融等领域的应用
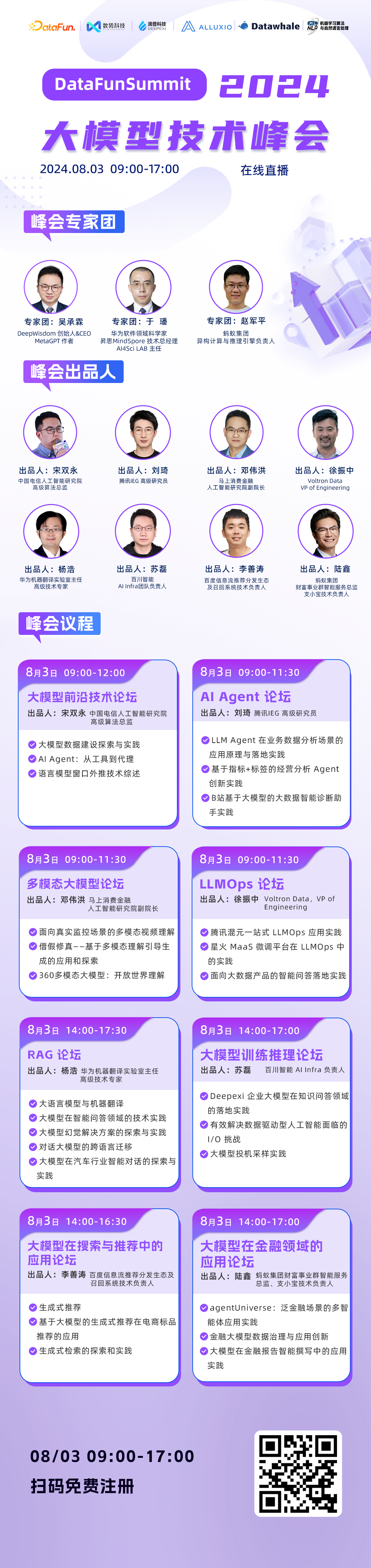
再好的大模型,也需要落地应用,才能产生价值。8月3日,09:00-17:00,DataFun将联合业内多位知名专家举办DataFunSummit2024:大模型技术峰会,并和大家一起探讨大模型技术的最新态势,分享各自的研究成果与实践经验,共同推动大模型技术在各个领域的深入应用。感兴趣的小伙伴欢迎识别二维码免费报名,收看直播:

扫码免费报名,收看直播
峰会日程

论坛介绍








详细介绍
① 大模型前沿技术 论坛
出品人:宋双永 中国电信人工智能研究院 高级算法总监
个人介绍:宋双永,博士毕业于中国科学院自动化研究所,目前任中国电信人工智能研究院高级算法总监,负责星辰语义大模型算法研发。曾就职于阿里达摩院、京东科技任算法总监,同时任中国自动化学会委员以及各类国际期刊会议的副主编、PC member及Session Chair等,已发表各类高水平学术论文70余篇。
桑基韬 北京交通大学 计算机科学系主任
个人介绍:北京交通大学计算机学院教授、计算机科学系主任、交通大数据与人工智能教育部重点实验室副主任。主要研究方向为社会多媒体计算、多源数据挖掘、可信机器学习等。曾获中科院院长特别奖、ACM中国新星奖,作为负责人先后承担相关方向的国家自然科学基金重点项目、(首批)新一代人工智能重大项目课题、北京市杰出青年基金和国家级青年人才计划,第一/二作者论文7次获得中国计算机学会推荐国际会议的主会论文奖项,以第二完成人获得中国电子学会自然科学一等奖和北京市科学技术奖。
演讲题目:AI Agent:从工具到代理
演讲提纲:预训练模型在大规模无标注的样本上学习到了通用知识,从而让任务解决范式从专用向通用发展。这种通用性不仅体现在不同的内容理解和生成任务上,还扩展到了思考和决策能力。将机器翻译、文本摘要等完成特定任务的算法作为工具,ChatGPT、Jasper等处理通用任务并具有自然交互能力的AI系统作为CoPilot,那么具有规划任务和使用工具能力的AI系统则被称为AutoPilot,也就是AI Agent。在CoPilot模式下,AI是人类的助手,与人类协同参与到工作流程中;在AI Agent模式下,AI是人类的代理,独立地承担大部分工作,人类只负责设定任务目标和评估结果。本次报告将介绍AI Agent的基本框架、相关技术和应用现状、以及对未来趋势的展望。
听众收益:
1. Tool、CoPilot、AutoPilot区别是什么?
2. AI Agent在C端和B端的应用形式以及目标分别是什么?
3. 从百模到千体,智能体应用爆发的趋势下互联网大厂、大模型创业公司等的竞争格局和商业模式是什么?
赵宇 中国电信人工智能研究院 大模型数据负责人
个人介绍:赵宇,博士,现任中国电信AI研究院大模型数据算法负责人,深度参与电信TeleChat语义大模型基础研发,主持多项行业大模型建设工作。本科就读于清华大学计算机科学与技术系,博士毕业于清华大学自然语言处理与社会人文计算实验室,先后任职于IBM研究院和腾讯,曾多次在AAAI、IJCAI、ACL、SIGIR等会议发表论文,拥有丰富的自然语言处理和推荐系统研究经验。
演讲题目:大模型数据建设探索与实践
演讲提纲:
1. 从工程化视角看数据建设与模型训练的关系
2. 预训练数据配比方案设计与实践
3. 高质量微调数据筛选方法
听众收益:
1. 从零开始训练千亿参数大模型,需要做哪些数据准备工作?
2. 如何调整预训练数据配比,使模型具有更好的中文语言能力?
3. 如何高效筛选“有用的”微调数据?
姜鑫 北京智源人工智能研究院 研究员
个人介绍:姜鑫,北京智源人工智能研究院研究员,北京航空航天大学硕士,近年来主要从事大语言模型预训练与微调方向的研究工作,代表成果有 Tele-FLM、FLM-101B等。
演讲题目:语言模型窗口外推技术综述
演讲提纲:窗口外推技术是当下LLM的重要研究方向之一,报告梳理了大语言模型中绝对位置编码到相对位置编码方案的动机与演进过程,介绍了旋转位置编码(RoPE)并形象化剖析了基于RoPE的系列窗口外推技术原理与最新进展。
听众收益:
1. 为什么我们需要相对位置编码?
2. 什么是旋转位置编码?
3. 如何直观理解各窗口外推技术基本原理?
4. 窗口外推技术有哪些最新进展?

扫码免费报名,收看直播
② AI Agent 论坛
出品人:刘琦 腾讯IEG 高级研究员
个人介绍:毕业于大连理工大学,研究方向包括多媒体创作、领域大语言模型、AI Agents应用。在游戏领域大语言模型、游戏智能创编业务场景有丰富的算法实践经验。当前负责团队游戏领域大模型能力建设及应用,游戏短视频创作的算法开发和项目落地。
徐名业 腾讯IEG 应用研究员
个人介绍:徐名业,腾讯IEG应用研究员,博士毕业于中国科学院大学,曾在T-PAMI、CVPR等国际期刊或会议上发表论文10篇,Google 学术引用1000+。研究兴趣包括大模型应用、三维视觉等。
演讲题目:LLM Agent 在业务数据分析场景的应用原理与落地实践
演讲提纲:当前基于 LLM Agent 的方式构建各种应用已经成为热门的 AI 落地方向,特别是在大数据环境下,处理和分析业务数据的过程中,能够为企业提供高效且智能的数据处理方式和精确的业务洞察,从而实现更优质的决策支持。本次演讲将深入探讨 LLM Agent 在业务数据分析场景中的应用原理以及应用案例,并对 LLM Agent 在业务数据分析领域的前沿研究和未来发展趋势进行展望。
听众收益:
1. 如何借助 LLM Agent 的能力对数据报告进行分析
2. 了解 LLM Agent 在业务数据分析场景的能力边界
3. 了解业务数据分析的新范式
李飞 博士 数势科技 AI 负责人
个人介绍:负责数势科技智能算法的开发,包括 LLM Agent,RAG,内容推荐,文本生成,知识图谱挖掘等算法技术。英国纽卡斯尔大学博士,在智能算法领域学术与工作经验丰富。在学术研究方面,拥有 10 项智能算法相关专利并发表 4 篇国际期刊,曾主导由欧洲玛丽居里计划资助的国际项目,在研究期间,共发表了 3 篇期刊文章、1 篇会议文章和 1 篇 Chapter;在工作方面,曾任职京东零售数据中台,负责人工智能技术在营销领域的相关落地,多次获得优秀员工及集团战略项目奖,曾获 HICOOL 全球创业大赛二等奖。
演讲题目:基于指标+标签的经营分析 Agent 创新实践
演讲提纲:数据分析在企业运营中的作用愈发显著。通过有效的数据分析,企业可以洞察市场趋势、优化运营流程、提高决策质量,从而在竞争激烈的市场中占据优势。在这个过程中,LLM Agent 可以扮演重要的作用,它不仅能够理解用户的意图,连接分析的流程,还能基于和环境的交互实现分析问题的下钻,引导企业客户进行自助式的探查分析。本次演讲将深入探讨 LLM Agent 如何重塑企业分析流程以及一些应用案例,并对 Data Analysis 的未来发展趋势进行展望。
1. 企业数据分析的难点和挑战
2. 行业通用企业数据分析Agent的实现方案和不足
3. 指标和标签能力在搭建企业数据分析Agent时的技术创新点
4. 分析的规划器和记忆如何设计
4. 应用案例分享和探讨
5. 展望和思考
听众收益:
1. 如何基于指标+标签的分析 Agent 能力搭建企业分析平台
2. 了解分析的规划器和记忆的设计思路
3. 了解具体行业用户在落地搭建分析 Agent 中的难点和解决思路
郭跃鹏 bilibili 大数据架构师
个人介绍:Apache Griffin CO-Founder,从事大数据相关的基础架构业务如数据质量,大数据安全,大数据引擎等基础生态服务。现任哔哩哔哩大数据架构师。
张巍 bilibili 架构师
个人介绍:曾经负责携程OLAP平台建设,平安银行数仓工具平台建设,离线OLAP平台建设。当前负责B站大数据基础架构离线计算和工具平台的建设。
演讲题目:B站基于大模型的大数据智能诊断助手实践
演讲提纲:
1. 当前离线计算诊断的现状
· 介绍当前离线计算诊断面临的主要问题和挑战
· 分析传统离线计算诊断方法的局限性
2. 引入大模型的背景
· 解释大模型在人工智能领域的兴起及其重要性
· 探讨大模型在各行业中的应用实例
· 强调大模型在提升计算诊断效果方面的潜力
3. 大模型在B站离线诊断中的应用
· 具体介绍B站在离线诊断中应用大模型的案例
· 分享实际应用中的经验和成果
· 分析大模型应用过程中遇到的挑战及解决方案
4. 介绍未来大模型在B站大数据基础架构中场景的探索和展望
· 潜在的大数据诊断场景以及方案
观众收益:
1. 知识库的构建实战指南
· 提供构建高效知识库的步骤和技巧
· 分享实际操作中的注意事项和经验教训
2. 通过LLM提效降本离线诊断的方法
· 介绍如何利用大模型(LLM)提高离线诊断的效率
· 探讨大模型在降低诊断成本方面的实际案例
3. 离线诊断相关的Agent开发
· 指导如何开发适用于离线诊断的智能Agent
· 分享Agent开发过程中的关键技术和实用工具
③ 多模态大模型 论坛出品人:邓伟洪 马上消费金融 人工智能研究院副院长
个人介绍:马上消费金融AI研究院副院长,作为领域主席参与 OpenCV等开源项目的研发工作,长期致力于多模态大模型和计算机视觉系统的理论研究和实用化落地,在 CVPR、TPAMI 等顶级会议和期刊上发表100多篇文章,谷歌学术引用16000多次,曾获北京市优秀博士学位论文奖、北京市科技新星项目、国家级青年人才项目,2023年入选斯坦福“全球前2%顶尖科学家”和科睿唯安“全球高被引科学家”榜单。
谢春宇 360 多模态团队负责人
个人介绍:360多模态团队负责人。硕士毕业于北京航空航天大学,先后工作于MSRA、360,主要技术方向为多模态大语言模型、图像搜索、开放世界目标检测等。在KDD/IJCAI/ACMMM/FSE等多个计算机领域会议发表论文,技术成果助力360智慧生活、搜索、商业化等多个业务取得突破性进展。
演讲题目:360多模态大模型:开放世界理解
演讲提纲:数字世界日益增长的多模态数据,驱动了大模型从单一模态到多模态的转变。在多模态大模型发展的热潮中,涌现了大量如LLaVA、InternVL、Cambrian等优秀的开源工作,为技术的不断发展和迭代助力。360多模态团队持续跟进业界前沿进展,并重点探索图像感知和开放世界理解能力,在无数的技术实践中为360集团各个业务赋能。
听众收益:
1. 多模态大模型的发展历程
2. 360多模态团队的技术思考
3. 360内部多模态的落地实践
马宇翔 蚂蚁集团 高级算法专家
个人介绍:多年算法综合领域落地从业经验,目前负责蚂蚁企业信用部算法工作。
演讲题目:借假修真——基于多模态理解引导生成的应用和探索
演讲提纲:
1. 解决什么问题
2. 多模态理解和生成的技术原理
3. 实践场景介绍
4. 挑战与解决思路
5. 未来演化方向推导
听众收益:
1. 多模态技术:目前多模态理解和生成还未完成大一统背景下的技术现状
2. 实际案例:通过具体案例理解技术应用的细节和挑战。
3. 多模态理解引导生成的技术细节:掌握针对实践中的常见问题与应对策略。
4. 趋势展望:接下来在多模态统一大模型的方向可以做哪些事情。
袁彤彤 北京工业大学 讲师
个人介绍:2020年毕业于北京邮电大学信息与通信工程学院,2020年至今任北京工业大学讲师。
演讲题目:面向真实监控场景的多模态视频理解
演讲提纲:
1. 监控视频的多模态数据集
2. 多模态监控视频内容理解小模型
3. 多模态监控视频内容理解的大模型
4. 研究趋势和应用前景分析
听众受益:分享的内容涉及监控视频、大/小多模态模型,多种视觉文本任务,整体上比较全面。

扫码免费报名,收看直播
④ LLMOps 论坛
出品人:徐振中 Voltron Data,VP of Engineering
个人介绍:目前,我在一家初创公司 Voltron Data 担任 VP 职务。之前在 Claypot AI 担任联合创始人兼 CTO,于今年初被目前公司收购。目前专注于 Composable Data Ecosystem 开源软件和实时机器学习平台产品的工程执行和技术策略。在过去的工作中,我取得了以下成就:2015年至2021年,我从零开始构建了 Netflix 的实时数据基础设施,支持2000多个内部用例,每天处理数拍字节的数据(相当于数十万亿事件)。2012年至2015年,我开发了微软 Azure 数据中心管理系统的弹性内核,助力其在云计算早期扩展至50万台服务器。2007年至2012年,我为 MSN/Bing 视频构建了分布式处理管道,使其成为 YouTube 的竞争对手。工作之余,我喜欢在赛道上骑摩托车,对我来说,这是一个不断平衡计算风险和突破极限的追求。
甘蓉 腾讯混元产品经理
个人介绍:腾讯混元产品经理,主要负责混元模型训练、推理的一站式 LLMOps 平台的产品设计工作,并支持腾讯各产品应用混元大模型,将 AIGC 落地各产品线,包括微信公众号、搜狗输入法、腾讯会议等近百个业务落地。
演讲题目:腾讯混元一站式 LLMOps 应用实践
演讲提纲:
1. LLMOps 流程痛点
2. 混元一站式解决方案
3. 混元 LLMOps 的应用
听众收益:
1. 洞察 LLMOps 研发领域的挑战与核心痛点
2. 掌握前沿的平台解决方案设计与实施策略
3. 探索如何将这些解决方案巧妙地融入实际业务场景,以实现业务价值最大化。
尹丰彬 阿里云 算法工程师
个人介绍:毕业于西安交通大学,在阿里云计算平台主要负责日志异常检测,大模型智能问答相关算法研究。
演讲题目:面向大数据产品的智能问答落地实践
演讲提纲:借助大模型的理解和涌现能力,我们致力于打造高效且准确的智能问答系统,帮助用户解决使用过程中的问题。
1. 阿里云大数据智能运维背景
2. 大模型在智能运维领域的机遇与挑战
3. 基于检索增强的智能问答
4. 基于工具增强的自助诊断
5. 总结与展望
听众收益:
1. 如何高效部署私域问答系统
2. 提升检索效果的几种方式
3. 如何抑制模型幻觉
杨彦波 科大讯飞 MaaS 研发负责人
个人介绍:讯飞星辰 MaaS 平台研发负责人,负责 MaaS 平台建设。星火开源应用生态贡献者, 负责星火大模型开源应用,以及 SDK 生态建设。开源项目 Sealos 核心贡献者,开源项目 AIGES 核心贡献者。国内第一批 Kubernetes 用户, 热爱开源,常活跃于 K8s,Sealos,Volcano,Argo 等开源社区。
演讲题目:星火 MaaS 微调平台在 LLMOps 中的实践
演讲提纲:
1. MaaS 产品介绍:模型选择、Prompt 工程、数据集准备、模型训练、模型评估、模型部署
2. LLMops 标准流程
① LLMops 流程图
② 关键技术剖析:基座选型、数据集格式统一、训练调度、Lora 动态加载方案、数据增强
3. 案例:Function Call 场景、Json 响应微调
听众收益:
1. 如何通过 MaaS 平台快速微调,开源,星火模型
2. 大模型微调数据准备
3. Function Call 微调心得
⑤ RAG 论坛
出品人:杨浩 华为机器翻译实验室主任、高级技术专家
个人介绍:杨浩,博士。华为文本机器翻译实验室主任、高级技术专家,北京邮电大学计算机博士,在机器翻译等人工智能相关领域有十年以上研发经验。有多篇ACL/EMNLP/ICLR等顶会论文和国内外专利,带领团队获得 WMT/IWST/CCMT等多项冠军。现负责多语言盘古大模型,盘古同传翻译等方向,希望和大家共同探讨大模型翻译训练,RAG,推理加速和评估等前沿方向和落地应用。
肖桐 东北大学/小牛翻译 教授
个人介绍:肖桐,博士,东北大学教授、博士生导师,东北大学计算机学院人工智能系主任,东北大学自然语言处理实验室主任,小牛翻译(NiuTrans)联合创始人。于东北大学计算机专业获得博士学位。2006—2009年赴日本富士施乐、微软亚洲研究院访问学习,并于2013—2014年赴英国剑桥大学开展博士后研究。在国内外相关领域高水平会议及期刊上发表学术论文100余篇,并撰写专著《机器翻译:基础与模型》。作为项目技术负责人,成功研发了NiuTrans、NiuTensor等开源系统,在WMT、CCMT/CWMT、NTCIR等国内外评测中30余次获得冠军。2016年获得中国中文信息学会“钱伟长中文信息处理科学技术奖”一等奖,2021年获得中国计算机学会CCF-NLP青年新锐奖。
演讲题目:大语言模型与机器翻译
演讲提纲:大语言模型的崛起极大推动了自然语言处理技术的进步。其中最为具意义的是,这些模型以统一的框架解决了众多不同的问题,展现出卓越的通用性和泛化能力。在机器翻译领域,我们不禁会问:大语言模型是否会取代传统的机器翻译方法?当前的趋势似乎在证明这一点。许多机器翻译领域的传统难题,如交互翻译、结构化输入、长文本翻译,都可以用大语言模型更好的解决。但是,另一方面,我们发现大语言模型和神经机器翻译模型本质上是相通的,从模型结构、多语言学习、Scaling laws等方面二者都显示了一定的统一性。在本次报告中,我们首先通过一个例子展示,基于类似于RAG的方式,大语言模型可以充分利用高质量翻译知识;进一步,通过结合结合这两类模型的架构甚至可以得到更加强大、高效的翻译模型。我们乐观的期待,机器翻译可以在大语言模型发展浪潮下得到更大的发展。
听众收益:大语言模型和机器翻译在本质上是统一的。
柴春燕 字节跳动 技术负责人
个人介绍:柴春燕,拥有超过十年的大型互联网研发与管理经验。在金融、零售、云计算行业业务架构设计、中台化建设、大数据应用,以及人工智能大模型等领域积累了丰富的实践经验。曾先后在微软、百度、金山云、平安、京东等知名企业担任技术要职。目前,作为技术总监,在字节跳动继续深化专业领域,引领技术创新。
演讲题目:大模型在智能问答领域的技术实践
演讲介绍:结合智能客服场景案例,深入解析大模型技术在智能问答领域的应用与技术实践。具体内容包括:
1. 智能问答场景痛点
2. 大模型技术方案选型
3. 技术架构设计
4. 技术挑战与优化策略
听众收益:
1. 理解大模型技术在智能问答领域的基本原理
2. 了解大模型在智能问答应用中的挑战及解决方案
3. 了解大模型在智能问答领域技术的最新趋势和未来发展方向
4. 通过案例分享,获得实际应用的洞见和灵感
孙林 360算法高级研究员,大数据协同安全技术国家工程研究中心大模型专委会主任
个人介绍:孙林,现任360算法高级研究员,大数据协同安全技术国家工程研究中心大模型专委会主任,负责360智脑基础大模型研发管理工作,曾先后供职于腾讯、贝壳找房,任数据智能中心总经理,知识图谱标准联盟副秘书长。拥有十多年人工智能技术研发和多元化团队管理经验,长期深耕于自然语言处理、大模型、搜索引擎、知识图谱等领域。
演讲题目:大模型幻觉解决方案的探索与实践
演讲提纲:大模型作为新质生产力,有着巨大市场规模的应用前景,但在实际应用过程中,大模型会产生与现实不符的响应,即大模型幻觉问题,从而导致模型输出的内容不可信,这成为了当下大模型规模化应用的拦路虎。本次分享首先介绍了大模型产生幻觉的原因,给出了360在大模型应用落地过程中针对幻觉问题的解决方案,及相应的实践案例。
听众收益:
1. 大模型幻觉产生的原因和危害
2. 缓解大模型幻觉问题的解决方案
3. 360实践应用探索
耿祥 华为机器翻译实验室 研究员
个人介绍:华为机器翻译实验室研究员,南京大学博士研究生,导师为黄书剑老师。获得 WMT2022 年和 2023 年机器翻译质量评估比赛英-德语向全部子任务的冠军,超过 COMET-QE 版本。目前关注于大模型和机器翻译领域的研究,在泰语和阿拉伯语的对话能力和安全性上使用 8B 参数模型超过 ChatGPT。
演讲题目:对话大模型的跨语言迁移
演讲提纲:LLM 在低资源语言上对话能力不足、安全性差,那么如何将一个经过 RLHF 训练的 chat LLM 迁移到低资源语言上呢?以往工作关注于迁移 base LLM,在迁移同时或之后进行指令微调,因此指令微调注入的对话知识不会被迁移所影响。而 chat LLM 的对话和安全相关知识已经融入到模型参数中,在无法获得相关标注数据的情况下,进一步的迁移训练有可能会导致灾难性遗忘,反而表现不出对话和安全方面的能力。本工作中,我们提出了 TransLLM 框架。
TransLLM 将迁移问题建模为翻译思维链(TCOT),通过翻译任务桥接高资源和低资源语言,同时利用开源数据增强模型的基础能力,从而有效迁移对话能力。为了缓解灾难性遗忘,我们使用 LoRA 技术进行学习并冻结模型原有参数,同时使用 chat LLM 自己生成数据进行知识蒸馏(recovery KD)。以此让模型学会:利用冻结参数中的知识执行英语任务,从而保持原先模型具有的能力;利用更新参数中的知识进行迁移目标语言的任务。
实验中我们尝试将 LLaMA2-chat-7B 迁移至泰语(TH)。在只使用单轮数据的情况下,我们在多轮对话评测集 MT-Bench-TH 的第一轮对话和第二轮对话中与 ChatGPT 相比分别超出 35% 和 23.75% 。在不使用任何安全数据的情况下,TransLLM 对有害泰语问题的拒绝率达到 94.61%,高于 ChatGPT 的 79.81% 和 GPT-4 的 85.96%,接近 LLaMA2-chat 对英语有害问题的拒绝率 99.23%。
听众收益:
1. 如何将对话大模型中的高资源语言知识迁移到其他语言?
2. 如何缓解大模型训练后的灾难性遗忘?
3. 如何使用 7B 参数大模型在泰语多轮对话和安全评测集上取得超过 ChatGPT 的性能?
吴文祥 易车 大数据架构师
个人介绍:拥有多年大数据领域专业经验,擅长于大数据平台架构设计和大模型应用实施。自2020年加入易车,负责大数据与AI平台的构建,包括离线计算和AI智能对话系统。目前,我专注于大数据与大模型融合技术的研究,致力于推动技术革新和应用实践。
演讲题目:大模型在汽车行业智能对话的探索与实践
演讲提纲:
1. 易车智能对话产品的技术架构概览
- 介绍易车智能对话产品的技术框架及其核心组件。
2. 汽车领域知识库的构建与RAG优化
- 探讨汽车领域知识库的构建过程,以及RAG优化实践经验
3. 智能引导策略的挑战与应对策略
- 分析智能引导策略在实际应用中遇到的主要挑战,并提出有效的优化措施。
4. 构建大模型智能对话的评估体系
- 阐述如何建立一个全面的评估体系,以衡量和提升大模型智能对话系统的性能和效果。
听众收益:
1. 大模型与汽车产业的融合实践
- 探索大模型技术如何与汽车产业紧密结合,提供创新解决方案。
2. 智能问答系统的挑战解析
- 深入理解智能问答系统中大模型所面临的主要挑战,及其对用户体验的影响。
3. 案例剖析:大模型应用的难点与挑战
- 通过具体案例分析,揭示大模型在实际应用中遇到的难点和挑战,提供解决思路。
4. 高效知识库构建的实践经验分享
- 分享在汽车领域构建高效知识库的实践经验,探讨如何优化知识库结构和管理策略

扫码免费报名,收看直播
⑥ 大模型训练推理 论坛
出品人:苏磊 百川智能 AI Infra 负责人
个人介绍:先后在 IBM、腾讯、华为等公司任职技术负责人。聚焦于 HPC 和 AI 基础设施领域,覆盖解决方案设计和全栈算力优化。多次完成从0到1的企业级技术创新产品孵化和商业交付,获得数个高性能计算、集群调度领域相关中美技术专利。
肖彬 百川智能 高级专家
个人介绍:北京理工大学本硕,先后在搜狗负责推荐架构,在字节跳动负责智能推荐平台训推架构,目前在百川智能负责大模型推理架构研发。
演讲题目:大模型投机采样实践
演讲提纲:百川智能在投机采样上的一些实践,从模型结构设计到工程落地的实战经验,包含 draft model 的选型,模型结构设计,工程性能优化等。
听众收益:
1. 设计对推理轻量化的结构,低代价同时提升命中率
2. 投机在大 batch 场景的影响
3. 工程落地性能优化
王宇阳 Alluxio 高级工程师
个人介绍:多年分布式对象存储和 HDFS 存储的核心设计、开发及维护经验。目前主要负责 Alluxio S3 协议和底层存储等方面的研发和优化工作。
演讲题目:有效解决数据驱动型人工智能面临的 I/O 挑战
演讲提纲:随着人工智能技术的飞速发展,数据已成为推动 AI 进步的核心动力。在这一背景下,快速地处理和访问大规模数据集对于 AI 模型的训练和部署显得尤为关键。但是,I/O 的性能瓶颈经常成为制约效率和限制 GPU 资源充分利用的主要障碍。在本次研讨活动中,我们将展示如何利用 Alluxio 构建一个高效的数据访问层,以应对 I/O 挑战并显著增强 GPU 的使用效率。结合多个实际案例和详实的实验数据,参与者将掌握在 Alluxio 中缓存数据集和模型的技巧,并认识到这种优化能带来多大的性能提升。具体包括:
1. 分析 I/O 挑战的常见形式及其对 GPU 使用效率和整体性能的具体影响
2. 探讨如何将高效的数据访问层与机器学习流程无缝结合,减少 I/O 延迟
3. 讨论提升 AI 工作负载性能的缓存策略
4. 探索未来提升数据访问效率和加速 AI 工作负载的发展方向
听众收益:听众将获得对数据驱动型 AI 工作负载所面临的 I/O 问题的深刻理解,并将学习到如何有效运用 Alluxio 来解决这些问题。我们将重点介绍来自互联网、汽车、AI 制药等行业数字化转型领先企业的实际操作经验,以及我们的解决方案如何正面影响 GPU 的使用效率和整体性能表现。
张敢 滴普科技 基础模型研究部总监
个人介绍:超过十年的企业服务研发与管理经验,曾先后负责大数据基础组件、搜索引擎、大模型应用的技术研发工作,目前主要在北京滴普科技负责基础模型和语料加工的技术创新,践行 LLMOps 和 Data-Centric AI。
演讲题目:Deepexi 企业大模型在知识问答领域的落地实践
演讲提纲:本次分享主要介绍滴普科技在企业大模型微调 + RAG 的落地实践,如何通过解决实践中出现的问题,提升垂直领域知识问答的准确率,包括模型微调、RAG 召回率、语料加工等方向。具体包括:
1. 滴普企业大模型方案
2. 模型微调
3. RAG 提升
4. 未来规划
听众收益:
1. 企业大模型在实践中都有哪些常见问题?
2. 垂直领域知识问答的准确率该如何提升?
3. RAG 该如何提升?

扫码免费报名,收看直播
⑦ 大模型在搜广推中的应用 论坛
出品人:李善涛 百度信息流推荐分发生态及召回系统技术负责人
个人介绍:北京邮电大学硕士,百度信息流推荐分发生态及召回系统技术负责人,在推荐系统领域有十余年的探索和工业实践,对推荐产品的生态优化建模,大规模召回系统的评估和调优,用户及资源冷启动等方向,有这丰富的实战经验。
柴斌 NVIDIA 加速计算专家
个人介绍:中国科学院大学硕士,于2023年加入 NVIDIA DevTech 团队,主要从事 GPU 倒排和向量索引、GPU Spark 大数据加速、LLM 大语言模型训练、推荐系统等优化工作。加入 NVIDIA 之前,曾在百度和 Hulu 从事信息流推荐算法和机器学习平台研发。
赵新博 NVIDIA 加速计算专家
个人介绍:赵新博于2022年加入 NVIDIA DevTech 团队,专注于推荐系统在 GPU 上的训练与推理的分析与优化工作,他参与开发了模型吞吐量分析工具,帮助客户有效提升了 GPU 资源使用率与模型吞吐量。
演讲题目:生成式推荐
演讲提纲:近期,Meta 的生成式推荐工作在各大搜广推业务引起了强烈的反响。本次演讲将介绍 NVIDIA 加速计算专家团队在这方面的研究工作。
听众收益:
1. Meta 论文的主要内容概述
2. HSTU 结构的计算、显存开销等性能分析
3. 针对 HSTU 结构的性能优化方案设计
冯少雄 小红书 社搜精排 LTR 负责人
个人介绍:博士毕业于北京理工大学。在 ICLR、AAAI、ACL、EMNLP、NAACL 等机器学习/自然语言处理领域会议/期刊上发表数篇论文。主要研究方向为大语言模型推理评测蒸馏、生成式检索、开放域对话生成等。现负责小红书社区搜索精排 LTR,原负责向量召回(长尾和个性化)。
演讲题目:生成式检索的探索和实践
演讲提纲:
1. 常见检索范式
2. 生成式检索
3. 生成式密集检索:记忆机制的双刃剑效应
4. 生成式检索在实际业务中的应用
听众收益:
1. 生成式检索的常见范式
2. 生成式检索的优势和问题
3. 生成式检索的未来发展方向
张超 京东健康 推荐团队负责人
个人介绍:西安交大计算机硕士,曾参与或负责手机百度 Feed 流、腾讯视频推荐、京东健康推荐等项目建设,获16年百度骄傲最佳个人,21年京东集团技术金像奖(个人)提名奖,现为京东健康推荐团队负责人。
演讲题目:基于大模型的生成式推荐在电商标品推荐的应用
演讲提纲:
1. 生成式推荐系统的代表性工作总结
2. 京东健康电商推荐背景与挑战
3. 生成式推荐在电商标品场的落地
听众收益:
1. 大模型技术范式如何落地传统电商推荐
2. 传统推荐与生成式推荐的比较

扫码免费报名,收看直播
⑧ 大模型在金融领域的应用 论坛
出品人:陆鑫 蚂蚁集团财富事业群智能服务总监、支小宝技术负责人
个人介绍:陆鑫,现任蚂蚁集团财富保险事业群智能服务部技术负责人,蚂蚁财富科技公司CTO,目前带领蚂蚁金融大模型核心研发团队,支撑智能金融助理支小宝和智能金融业务助手支小助两个系列产品线的落地。曾在百度、美团点评等科技公司任职,在金融智能、搜索、计算广告、智能对话等多个领域有丰富经验。
赵泽伟 蚂蚁集团 AgentUniverse多智能体框架架构师
个人介绍:AgentUniverse多智能体框架架构师、蚂蚁财富投研业务架构师,毕业于上海大学电子与通信工程专业。先后在阿里集团业务平台事业部和蚂蚁财富投研团队任职,近年来专注于金融投研领域和大模型应用技术领域的相关工作,致力于将两者有机结合,探索AGI在金融与泛金融场景中的新应用和可能性。
演讲题目:AgentUniverse:泛金融场景的多智能体应用实践
演讲提纲:泛金融场景因其高度的复杂性、动态性和不确定性,一直是AI及其相关技术的应用热点。随着大模型与智能体技术的快速发展,多智能体协同模式在在解决复杂泛金融场景问题方面展现出巨大的潜力。在实际的业务发展过程中,agentUniverse通过使用多智能体协同范式,克服众多技术落地难点取得阶段成果。本演讲将深入探讨多智能体协同范式在泛金融场景中的技术应用并分享经产业验证的优秀真实案例。具体包括:
1. 大模型时代下的多智能体协同机制
2. 泛金融场景下的智能体应用构建新模式
3. 一种仿金融专家多智能体协同范式PEER介绍
4. 案例分享:基于PEER范式的投研领域智能助手
5. 多智能体协同范式在金融产业的未来展望
听众收益:
1. 理解多智能体协同机制的优势以及如何解决泛金融产业问题
2. 理解多智能体协同机制在泛金融产业落地过程中的挑战与难点
3. 理解一种仿金融专家多智能体协同范式PEER如何提高泛金融类任务效果
4. 理解面向未来多智能体协同机制在泛金融产业中如何发挥更大的作用
李杨 恒生聚源 数据中心AI生产部技术经理
个人介绍:2016年硕士毕业于南京航空航天大学交通信息工程及控制专业,过往先后在阿里巴巴集团淘系技术部、新浪微博从事CV、多模态、推荐算法的研发工作。2023年2月起,开始在上海恒生聚源数据服务有限公司担任AI生产部技术经理,聚焦金融数据领域AI技术研发、产品化和应用场景落地。在文档智能理解、数据生产大模型、多Agent金融场景服务方面取得多项技术突破和应用场景落地,在提升数据生产效率和数据质量的同时,也为金融数据消费场景的智能化转型贡献力量。
演讲题目:金融大模型数据治理与应用创新
演讲提纲:
1. 引入金融大模型的重要性和技术创新在金融行业中的应用,简述数据治理在金融大模型发展中的核心作用。
2. 介绍金融大模型的基本概念、架构和关键技术要素,讨论大模型在金融领域的应用潜力和挑战,
3. 详细介绍多模态学习在金融文档处理中的应用和技术创新,展示如何整合文本、图像和结构化数据,提高金融文档的理解和处理能力。
4. 阐述Agent技术在金融数据生产、质量控制中如何支持中的角色和功能,展示Agent技术在智能投顾、个性化金融服务、客户服务中的应用案例。
5. 对比传统行业和金融行业在数据治理上的差异,包括数据的规模、复杂性、实时性等。阐明技术相似性和差异,包括数据预处理、预测分析和个性化服务等。
7. 描述在实施大模型技术时遇到的技术挑战,如模型透明度、数据偏见等。讨论数据治理策略如何帮助应对这些挑战,确保技术的健康发展,促进社会责任治理水平提升。
听众收益:
1. 如何应用金融大模型技术、多模态文档理解技术生产和处理金融数据
2. 了解数据治理的背景、方法和价值
3. 了解金融数据消费场景和AI应用前景
向俊夫 吾道科技 技术负责人
个人介绍:毕业于南京大学。曾任职于富士通,主要负责自然语言处理相关工作。现任职于吾道科技,负责 NLP 和大模型应用。
演讲题目:大模型在金融报告智能撰写中的应用实践
演讲提纲:
1. 大模型在金融报告中的应用现状
2. 大模型驱动的智能金融报告撰写
3. 技术实现与挑战
听众收益:
1. 大模型在金融报告中的当前应用情况
2. 大模型是如何用于金融报告智能撰写的
3. 实施过程中可能遇到的技术挑战及解决思路
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 2506
2506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









