






转载公众号 | 知识图谱科技

这篇论文探讨了如何通过知识图谱(KG)增强大型语言模型(LLMs)的推理能力。
大型语言模型 (LLM) 在自然语言理解和生成方面表现出卓越的能力。然而,他们经常与复杂的推理任务作斗争,并且容易产生幻觉。最近的研究表明,在利用知识图谱 (KG) 提高 LLM 性能方面取得了可喜的结果。KG 提供实体及其关系的结构化表示,提供丰富的信息源,可以增强 LLM 的推理能力。在这项工作中,我们开发了不同的技术,将 KG 结构和语义紧密集成到 LLM 表示中。我们的结果表明,我们能够显著提高 LLM 在复杂推理场景中的性能,并使用 KG 为推理过程奠定基础。我们是第一个用编程语言表示 KG 并使用 KG 微调预训练 LLM 的公司。这种集成有助于更准确和可解释的推理过程,为 LLM 更高级的推理功能铺平了道路。
[2412.10654] Thinking with Knowledge Graphs: Enhancing LLM Reasoning Through Structured Data
https://arxiv.org/abs/2412.10654
核心速览
研究背景
研究问题:这篇文章要解决的问题是如何利用知识图谱(Knowledge Graphs, KGs)来增强大型语言模型(Large Language Models, LLMs)在复杂推理任务中的表现,并减少其生成文本的幻觉现象。
研究难点:该问题的研究难点包括:LLMs在处理复杂推理任务时表现不佳,容易产生非事实性、无意义或连贯性差的文本;如何有效地将KGs的结构和语义信息融入到LLMs的表示中。
相关工作:该问题的研究相关工作有:使用图神经网络(GNNs)将KGs编码为嵌入向量,作为LLMs的软提示;通过语义解析将自然语言查询转换为结构化查询语言(如SPARQL);将KG实体的关系和属性编码为自然语言文本或结构化数据。
研究方法
这篇论文提出了使用编程语言代码来表示知识图谱,并将其紧密集成到LLMs中,以提高其在复杂推理任务中的表现。具体来说,
知识图谱定义:知识图谱由实体集E、关系集R和三元组集T组成,其中三元组表示实体之间的关系。
知识图谱表示:为了与LLMs的提示和微调兼容,知识图谱可以用不同的方式表示。
自然语言表示:使用自然语言描述三元组,例如“The composer of ‘It Goes Like It Goes’ is David Shire”。
JSON表示:使用JSON格式存储结构化数据,例如
{"composer":{"It_Goes_Like_It_Goes":"David_Shire"},"spouse":{"David_Shire":"Didi_Conn"}}。
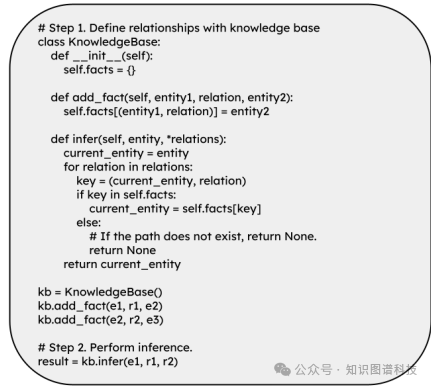
编程语言代码表示:使用Python等编程语言的数据结构表示三元组,例如静态字典或动态添加到预定义的数据结构中。
实验设计
数据集:使用了两个数据集进行实验。
数据集1:从Wikidata提取的两跳关系,分为八个等大小的分区,选择分区2作为训练集,分区4作为测试集。
数据集2:同样从Wikidata提取的两跳关系,但实体和关系不同,选择组合关系进行训练,开发数据集用于测试。
数据集3:数据集1的扩展,增加了一跳关系,形成三跳关系。
模型:选择了Meta发布的最新开源模型Llama-3.1-8B-Instruct和Llama-3.1-70B-Instruct进行实验。
微调:使用LoRA进行参数高效的微调,优化语言模型目标,预测每个token的概率分布。
提示设计:设计了三种类型的实验,包括零样本提示、一样本提示和有上下文的提示。
结果与分析
实体关系表示对LLMs多跳推理的影响:
一样本提示结果:Python表示的实体关系在一样本提示中表现优于自然语言文本和JSON表示。
微调结果:微调后的LLMs在使用Python表示的实体关系时表现更好。
模型对更长推理路径的泛化能力:
三跳推理:所有微调后的LLMs在三跳推理中的表现均有所提高,使用Python表示的实体关系的模型表现最佳。
上下文学习对多跳推理的帮助:
有上下文的提示:在有上下文的提示中,使用Python表示的实体关系的模型表现显著优于基线模型,甚至超过了更大的基线模型。
总体结论
这篇论文提出了一种新的知识图谱表示方法,即使用编程语言代码,并将其集成到LLMs中,以提高其在复杂推理任务中的表现。实验结果表明,使用Python表示的实体关系能够显著提高LLMs的多跳推理能力和减少幻觉现象。未来的工作将进一步研究更复杂的推理任务和编程语言表示的影响。
论文评价
优点与创新
新颖的知识图谱表示方法:论文提出了使用编程语言(Python)来表示知识图谱,这种方法能够无缝地将结构化知识整合到语言建模过程中。
提高推理准确性:通过将知识图谱紧密集成到LLMs中,论文的方法显著提高了LLMs在复杂任务上的推理准确性,并有效地将推理过程与知识图谱相结合,减少了生成幻觉的机会。
编程语言表示的优势:编程语言的表示方式不仅存储了结构化数据,还包含了推理过程,提供了一种更受控和明确的方式来指导LLMs进行推理。
实验验证:论文通过多个数据集和实验设计,验证了不同知识图谱表示方法对LLMs推理性能的影响,展示了编程语言表示在多跳推理任务中的优势。
适用性广泛:编程语言表示方法可以轻松推广到更复杂的推理场景,并且适用于预训练和微调阶段。
不足与反思
复杂推理任务的挑战:论文指出,准确衡量LLMs推理性能,特别是在两跳和三跳组合关系之外的复杂推理任务,具有挑战性。
未来工作方向:未来的研究将探索更复杂的实体关系表示及其对更复杂推理案例的影响,包括在预训练和微调阶段评估编程语言表示的性能影响。
关键问题及回答
问题1:论文中提出的使用编程语言代码表示知识图谱的具体方法有哪些?这些方法在实验中的表现如何?
静态字典表示:将知识图谱的三元组表示为静态字典,例如:
relationships ={ 'composer': {'It Goes Like It Goes': 'David Shire'}, 'spouse': {'David Shire': 'Didi Conn'} }这种方法简单直观,但在表示多跳推理时较为繁琐。
动态字典表示:在预定义的数据结构中动态添加三元组,例如:
classKnowledgeBase: def__init__(self): self.facts ={} defadd_fact(self, entity1, relation, entity2): self.facts[(entity1, relation)] = entity2 definfer(self, entity, *relations): current_entity = entity for relation in relations: key =(current_entity, relation) if key in self.facts: current_entity = self.facts[key] else: returnNone return current_entity这种方法支持多跳推理,并且可以通过类和方法的定义使代码更具可读性和可扩展性。
预定义Python类表示:使用预定义的Python类来表示知识图谱,例如:
classKnowledgeBase: def__init__(self): self.facts ={} defadd_fact(self, entity1, relation, entity2): self.facts[(entity1, relation)] = entity2 definfer(self, entity, *relations): current_entity = entity for relation in relations: key =(current_entity, relation) if key in self.facts: current_entity = self.facts[key] else: returnNone return current_entity这种方法通过类的继承和方法的重写,可以进一步扩展功能,例如添加属性和验证关系。
实验结果表明,使用Python代码表示的实体关系在一次提示中的表现优于自然语言文本和JSON表示,微调后的Python表示表现更好。具体来说,动态Python表示的一次性提示性能比零样本提示高出约78%,而静态Python表示的性能比零样本提示高出约60%。
问题2:论文中使用了哪些数据集进行实验?这些数据集的构建方法和特点是什么?
数据集1:从Wikidata提取的两跳关系,分为八个等大小的分区,选择分区2作为训练集,分区4作为测试集。数据集的特点是每个桥接实体(bridge entity)在训练集和测试集中不重叠,关系对(relation pairs)的重叠率约为99%。
数据集2:同样从Wikidata提取的两跳关系,但实体和关系与数据集1不同。选择组合关系进行训练,开发数据集用于测试。数据集的特点是关系类型与数据集1一致,便于比较推理性能。
数据集3:数据集1的扩展,增加了一跳关系,形成三跳关系。具体来说,数据集1中的每个实体都增加了对应的三跳关系,形成新的三跳关系。数据集的特点是训练集和测试集之间的桥接实体重叠最小,但关系重叠率高。
这些数据集的构建方法确保了实验的公平性和可重复性,同时也使得实验结果更具说服力和普遍性。
问题3:论文中如何评估不同知识图谱表示方法对LLMs推理性能的影响?具体的实验设计和结果是什么?
无上下文的LLMs推理:包括零样本提示、一次性提示和微调后的零样本提示。实验结果显示,Python表示的实体关系在一次提示中的表现优于自然语言文本和JSON表示,微调后的Python表示表现更好。例如,在数据集1上,动态Python表示的一次性提示性能比零样本提示高出约78%。
有上下文的LLMs推理:使用检索增强生成(RAG)应用进行实验。实验结果表明,微调后的Python表示模型在有上下文的情况下表现出色,甚至超过了更大的基线模型。例如,在数据集1上,微调后的Python表示模型在有上下文的情况下准确率达到了96.4%。
模型对更长推理路径的泛化:测试微调后的模型在更长推理路径上的表现。实验结果显示,所有微调后的模型在三跳推理中的表现均优于未微调的基线模型,Python表示的模型表现最佳。例如,在数据集3上,微调后的Python表示模型在三跳推理中的准确率达到了96.4%。
通过这些实验设计,论文全面评估了不同知识图谱表示方法对LLMs推理性能的影响,证明了编程语言代码表示在提高LLMs多跳推理能力和减少幻觉现象方面的有效性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









