







笔记整理:秦铭,浙江大学博士生,研究方向为科学交叉场景下大模型的研究与应用
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/28924
发表会议:AAAI 2024
1. 动机
近年来,通过自监督学习从大规模蛋白质和分子数据库中获得的分子和蛋白质表示在药物发现中发挥了重要作用。然而,这些方法往往仅限于单一数据模式,未能利用分子和蛋白质之间的丰富关系知识。本文提出一种多模态知识图谱(MKG)来增强表示学习,以便更有效地预测药物与蛋白质的相互作用。与仅依赖序列或SMILES数据的传统方法相比,所提出的知识增强表示学习在多项药物发现基准测试中取得了显著的性能提升。
2. 贡献
本文的主要贡献包括:
(1)多模态知识图谱的发布:构建并公开了包含超过3000万个三元组的多模态知识图谱,将药物和蛋白质的多种属性融入表示中,以支持药物发现研究。
(2)基于知识的多模态表示学习框架:利用不同来源的知识图谱和图神经网络(GNN)构建蛋白质和药物的表示,超越了现有基准的预测效果。
(3)针对部分连接图谱的表征学习方法:通过集成多图表征并研究了其对模型的适应性,展现了在不同预训练目标下的鲁棒性。
3. 方法
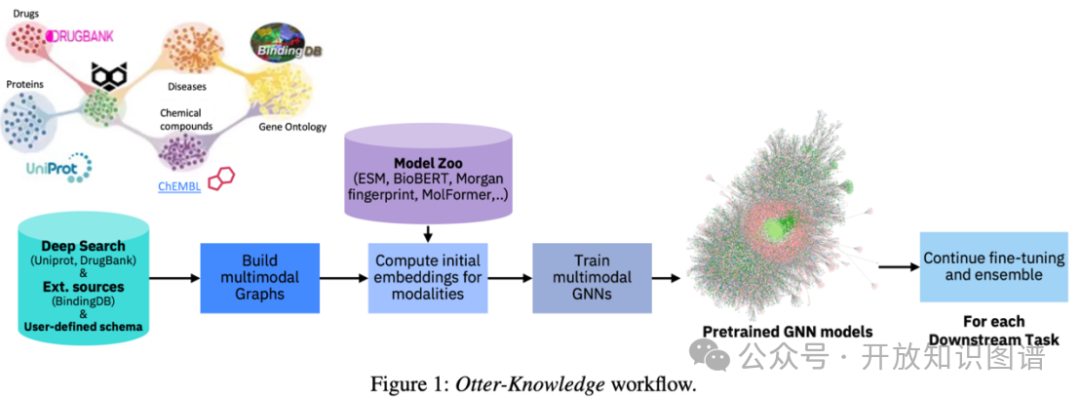
多模态知识表示学习框架
整体流程包括:构建多模态知识图谱(MKG)、生成初始嵌入表示、并通过GNN优化这些嵌入。每个节点均分配一种模式(如文本、图像、蛋白质序列等),并通过不同预训练模型进行嵌入计算。GNN框架结合了数据和对象属性,使得表示学习适应未见的节点和属性,进一步增强了模型的跨模式推理能力。
预训练与集成学习
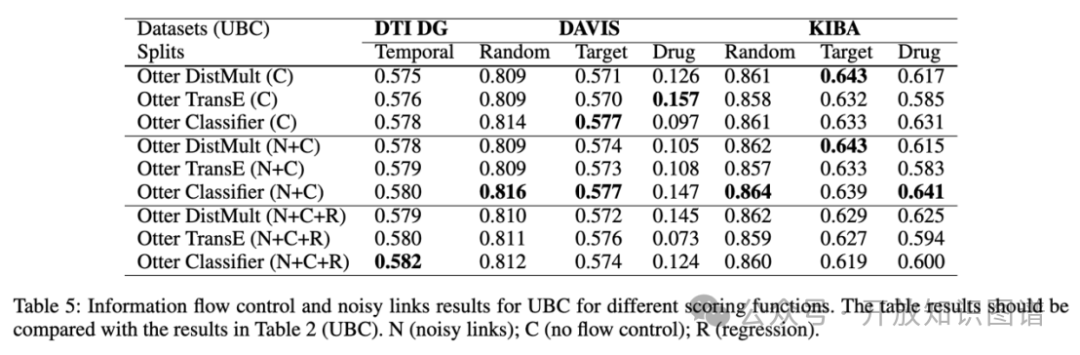
GNN的编码器模块使用了线性变换和多关系卷积层来处理图中的不同边类型,而解码器模块则用于预测实体之间的链接和数值属性的回归任务。采用多种评分函数(如DistMult、TransE、分类器)和集成学习,以增强对多模态知识图谱的适应性。此外,通过自动扩展(GAS)处理大规模数据,以减少计算资源需求。
数据集
预训练使用了多个数据源(如UniProt、BindingDB、DrugBank等)构建的知识图谱,并生成了大量的三元组用于GNN训练。不同数据库的整合通过一种集成方法进行,以避免多数据源间结构对齐的复杂性。
4. 实验
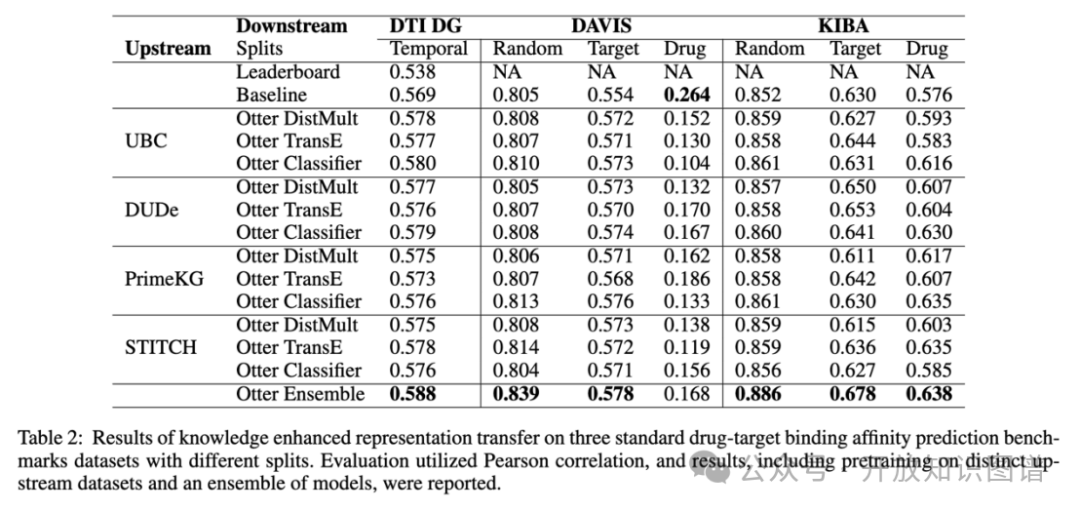
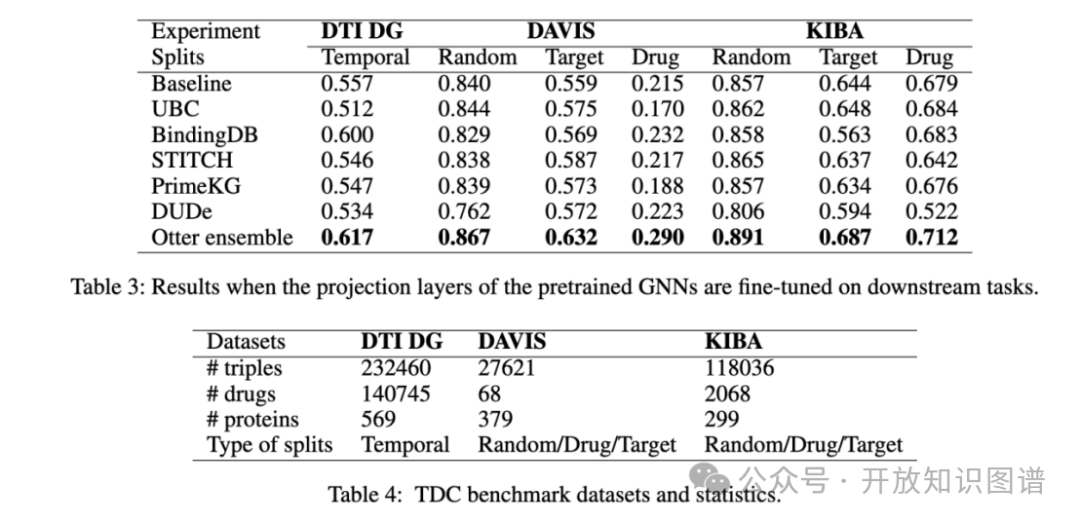
实验在药物-靶标结合亲和力预测任务中测试了所提出的框架,使用了三个数据集:DTI DG、DAVIS和KIBA,分别测试方法的泛化能力和不同分割方式的表现(如随机分割、药物分割、靶标分割等)。结果表明,知识增强的多模态表示在测试集上的表现显著优于基线方法,特别是在见过的和未见的药物和靶标预测任务中展现了更好的效果。

5. 总结
本文提出了一种用于药物发现的多模态知识图谱增强的表示学习框架,并在多个基准测试上取得了较好的效果。未来研究方向包括探索额外的模式(如分子和蛋白质的3D结构)、处理动态数据输入模式、以及跨任务的表征学习方法的泛化能力。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









