






导语
大语言模型的推理能力突破正在重新定义检索增强生成(RAG)技术的边界。如何让模型不仅“检索知识”,还能“像人类一样思考”?这一问题催生了RAG与推理能力深度融合的研究。同济大学王昊奋团队联合复旦大学熊贇教授团队、Percena AI 团队联合推出的《Synergizing RAG and Reasoning: A Systematic Review》首次系统性地梳理了RAG与推理的结合机制,为RAG在复杂知识密集型任务中的应用提供了新的思路。
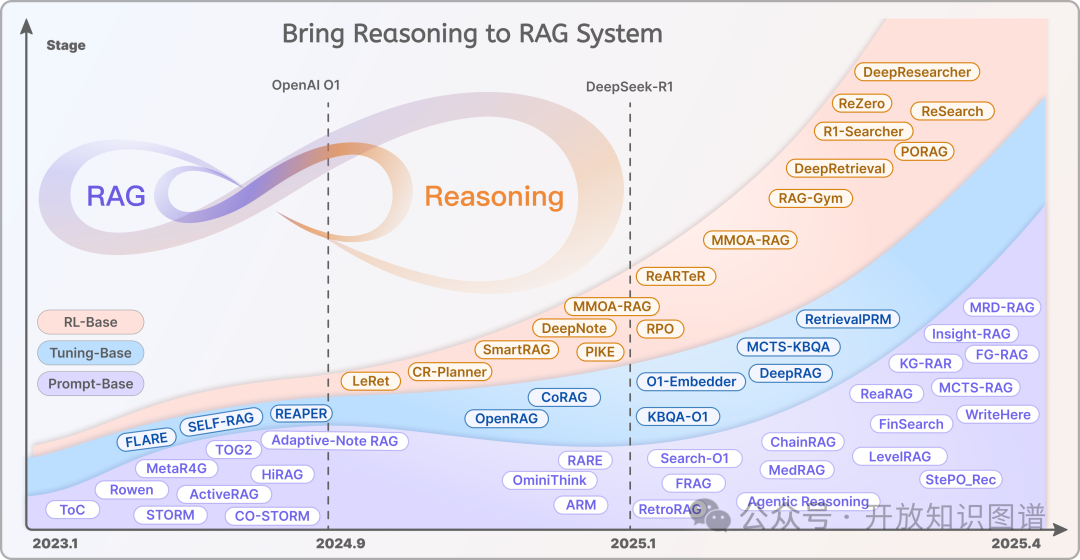
关于RAG-推理协同的研究可分为基于提示、微调和强化学习三类。随着test-time scaling技术的广泛应用,强化学习在提升RAG系统中的应用日益增多。
Overview
本文聚焦RAG与推理能力深度融合的最新进展,探讨如何让RAG突破单纯检索,具备多步逻辑思考能力,实现更复杂的任务。试图回答以下几个问题:
为什么要结合RAG与推理?融合后系统展现了哪些新潜力?
RAG与推理的协同模式有哪些?是预定义流程还是动态驱动?推理由谁发起?
如何实现二者深度协同?关键技术与优化策略有哪些?
推理增强带来了哪些评估挑战和成本?我们该如何平衡效果与资源消耗?
在实际应用中,如何根据场景需求设计合适的“RAG+推理”方案?有哪些实用建议和注意事项?
首先,什么是推理能力?
Reasoning/ Inference有什么区别?
推理(Reasoning)是一种结构化、多步动态过程,强调将复杂问题拆解为多个中间状态,通过逻辑和证据的反复迭代,实现新的知识合成与问题重新表述。它不同于推断(Inference),后者通常指一步到位的条件概率计算,缺少多阶段的状态管理和错误修正。推理作为一种高阶的认知过程,协调多步调用生成更具深度的解决方案。
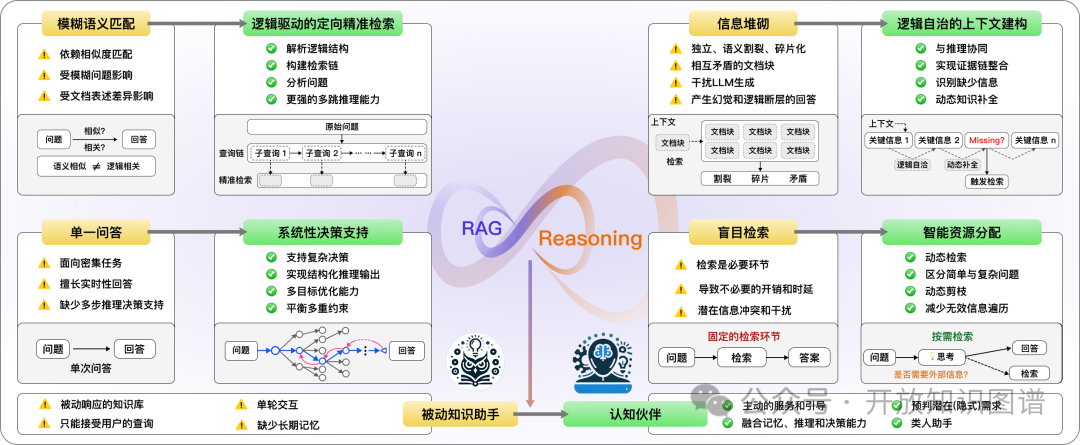
RAG与推理结合的新特点
从模糊匹配到逻辑驱动检索
传统RAG依赖语义相似度,容易受措辞变化影响。结合推理后,系统能基于因果和条件关系深度分析查询,动态优化检索策略,支持更精准的多跳检索。
从信息堆积到逻辑连贯的证据整合
推理增强系统通过逻辑验证和因果推断过滤矛盾信息,构建连贯的上下文,实时补全知识空缺,避免信息碎片化。
从单轮问答到系统性决策支持
整合推理使系统能够生成结构化的推理链,平衡多目标约束,支持复杂决策制定,如医疗诊断和工程规划。
从无差别检索到按需智能资源分配
系统根据问题复杂度动态调整检索策略,减少不必要的信息获取,提高响应效率。
从被动工具到主动认知助手
增强型推理系统能够通过提出澄清性问题和预测隐性需求来主动为用户服务。这种转变使得整合记忆、推理和决策的类人式助手成为可能。
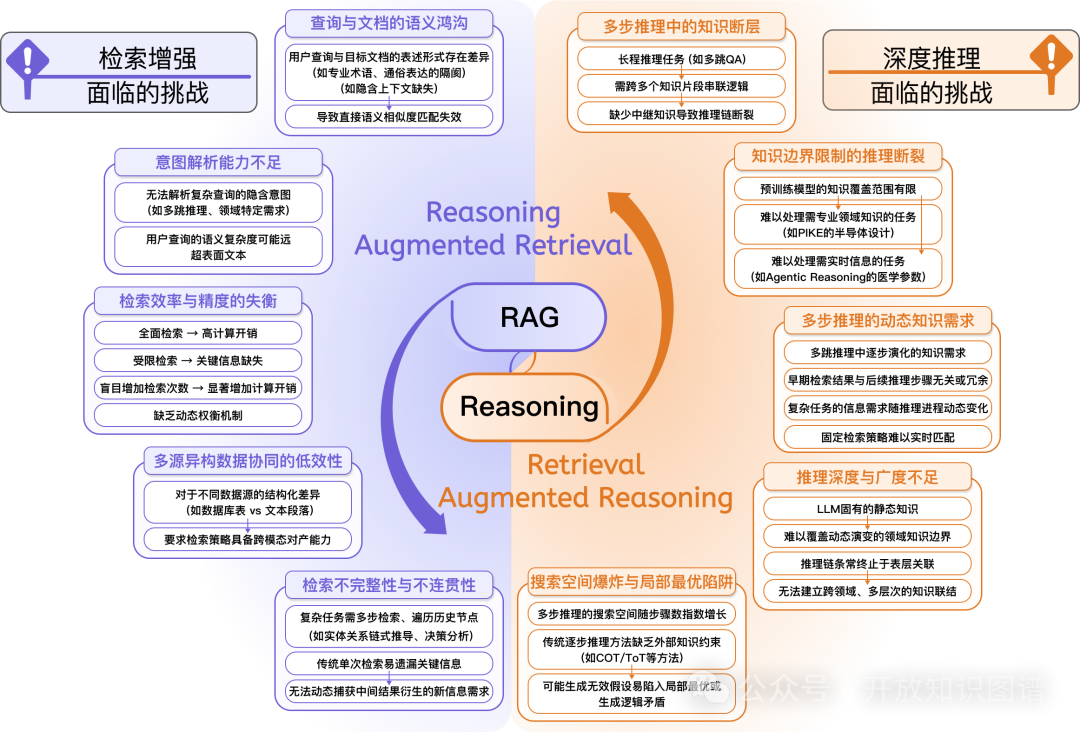
为什么需要RAG+Reasoning?
RAG的局限:缺乏对复杂意图的深入理解,检索策略静态且难适应多步推理,难以高效平衡准确与速度,对多模态、动态知识整合能力不足。
Reasoning的挑战:推理空间庞大,容易陷入局部最优;缺乏有效的外部知识验证机制和中间状态监督,透明度差且计算资源消耗高。
协同目标
围绕两方面,推动RAG与推理的融合:
推理增强检索(Reasoning-Augmented Retrieval, RAR):通过逻辑分析重构查询,动态调整检索策略,突破语义鸿沟。
检索增强推理(Retrieval-Augmented Reasoning, ReAR):实时补充外部知识,构建闭环验证机制,提升推理的深度和准确性。
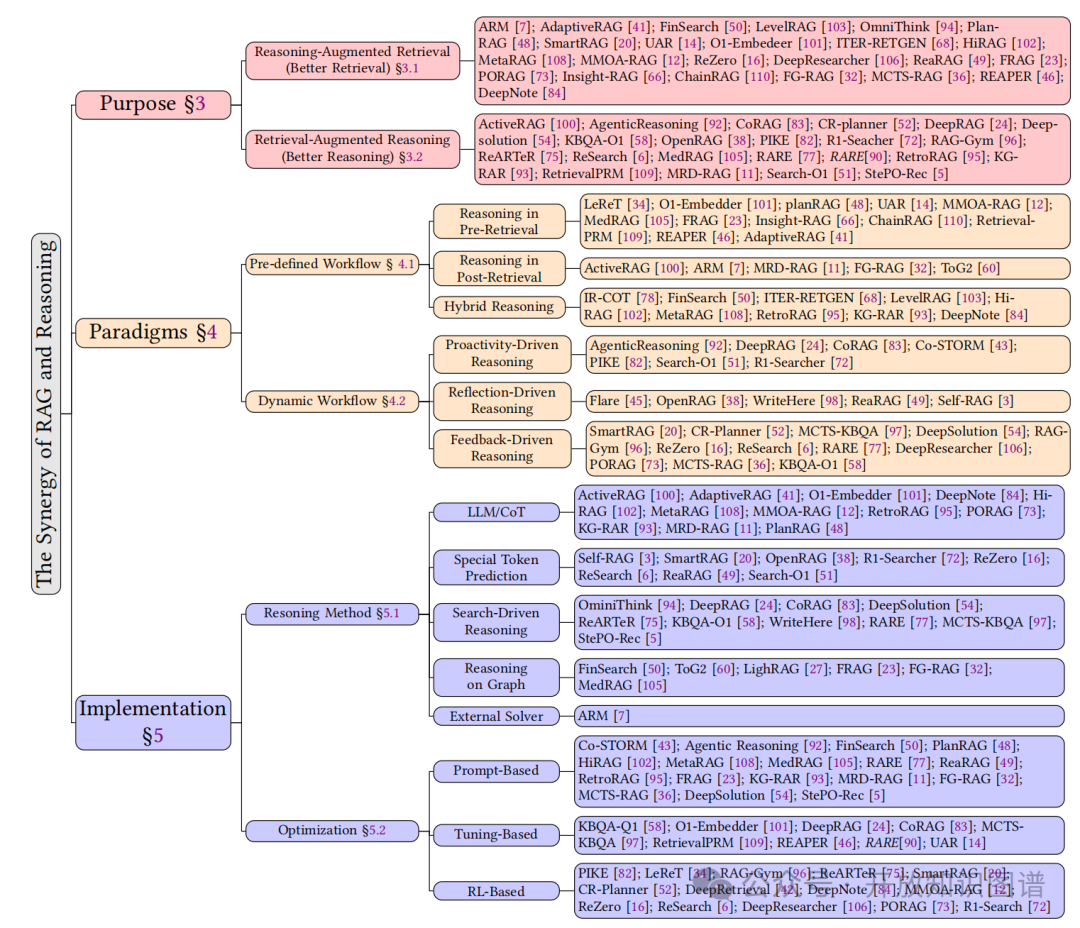
典型的协同模式有哪些
两类主流架构:
1. 预定义工作流:
预检索推理:先分解复杂问题再检索(如PlanRAG的业务规则提取)。
后检索推理:对检索结果进行逻辑验证与知识融合(如ActiveRAG的冲突消解机制)。
混合模式:迭代式“检索-推理-再检索”循环(如ITER-RETGEN的生成反馈优化)。
2. 动态工作流:
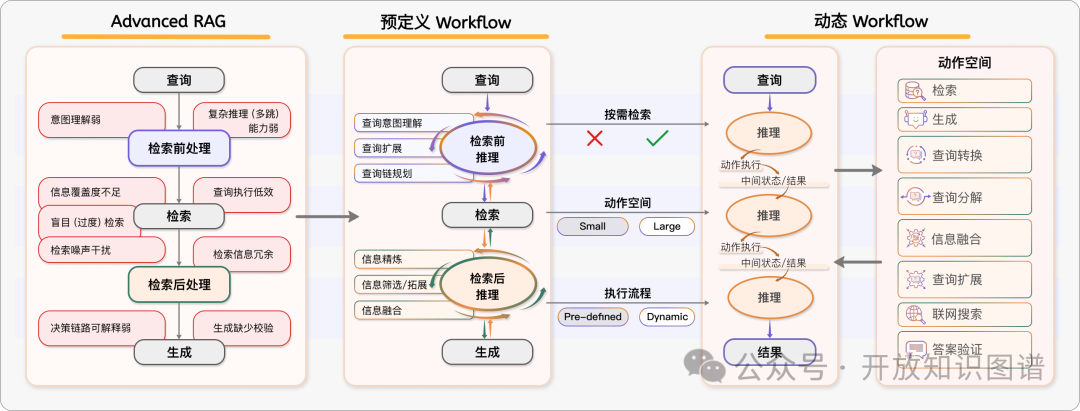
主动性驱动:模型自主触发检索(如Agentic Reasoning的实时API调用)。
反思性驱动:基于中间结果自评估调整策略(如Self-RAG的置信度阈值控制)。
反馈驱动:外部奖励模型引导优化(如RAG-Gym的多维过程监督)。
如何实现协同与优化?
核心技术与优化策略:
推理过程实现:
思维链(CoT):显式分解多步逻辑(如医疗诊断中的症状-检验-结论链)。
特殊令牌预测:通过“[检索]”“[验证]”等控制符动态调度工具(如SmartRAG的检索触发机制)。
图推理与外部求解器:结合知识图谱路径约束(如ToG2.0的实体关系扩展)与数学求解器(如ARM的混合整数规划)。
优化策略:
提示工程:结构化模板引导推理路径(如FinSearch的时序依赖建模)。
参数调优:领域适配的轻量微调(如Open-RAG的MoE架构)。
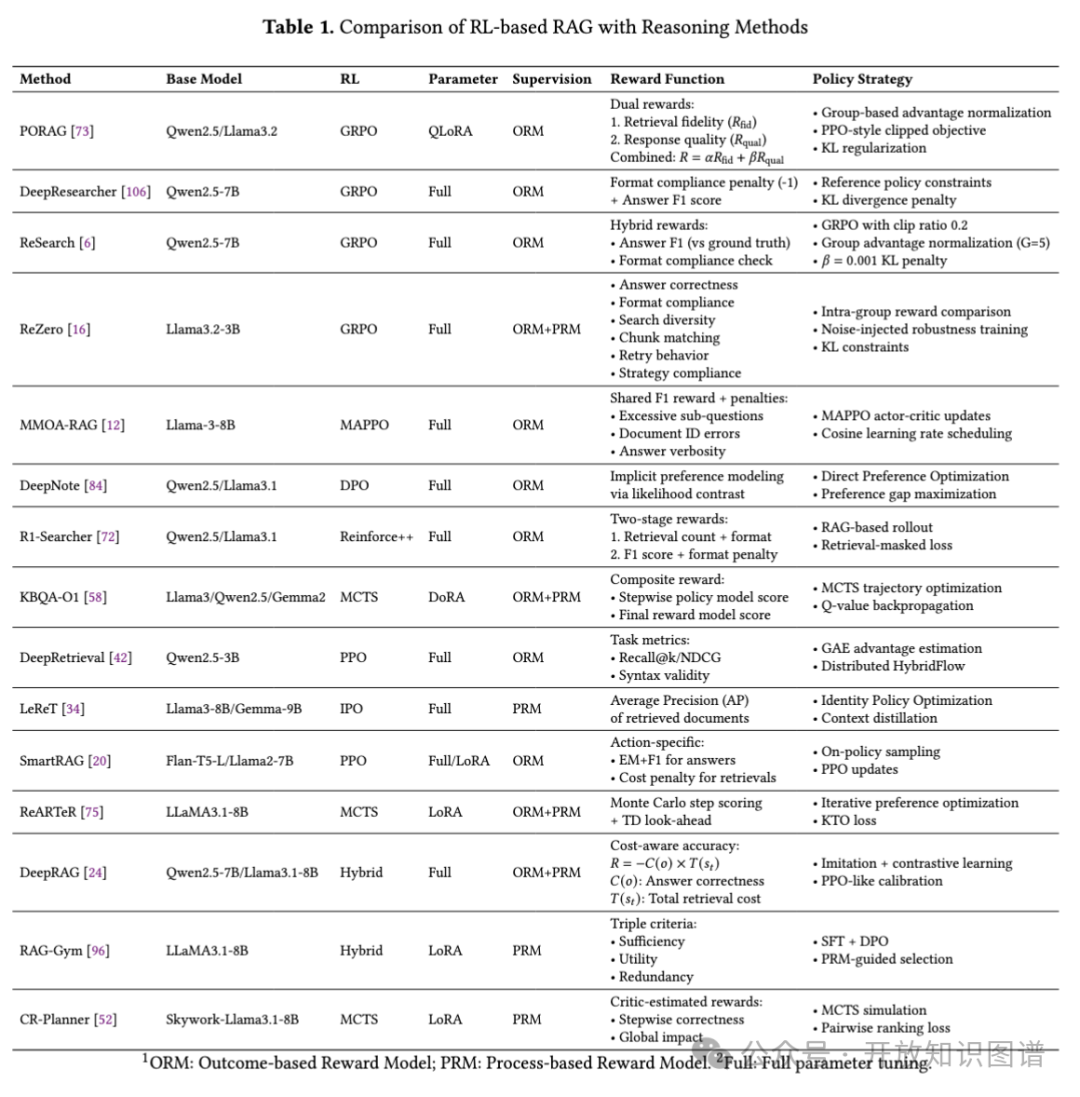
强化学习:基于过程奖励(PRM)与结果奖励(ORM)的策略优化(如PORAG的双奖励模型)
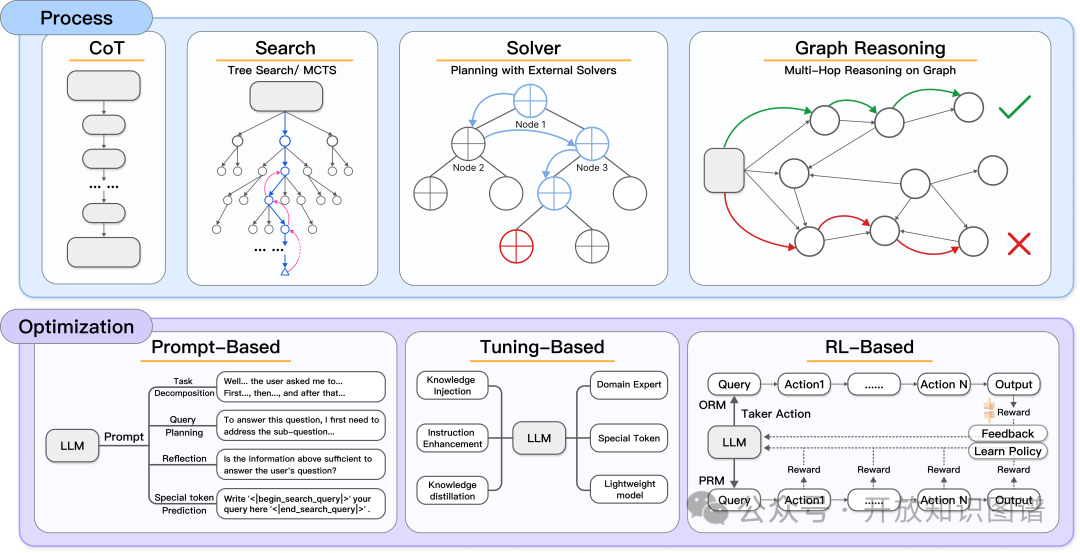
强化学习(RL)在DeepSeek-R1等先进推理模型中取得了显著的性能提升,推动了基于RL的RAG推理系统。与聚焦于LLM本身的推理优化不同,基于RL的RAG系统在奖励函数设计上具有自己的特点。引入检索次数约束和文档长度惩罚等参数。
下游评估任务
一方面,以多跳问答(Multihop QA)和开放领域问答(ODQA)为主的知识密集型任务仍然是当前的评测主流,常用的数据集集中在HotpotQA、2WikiMultihopQA和MuSiQue等。然而,传统评测方法存在局限难以充分反映真实场景的复杂性,且缺乏对中间推理步骤的监督和多维度评估指标。
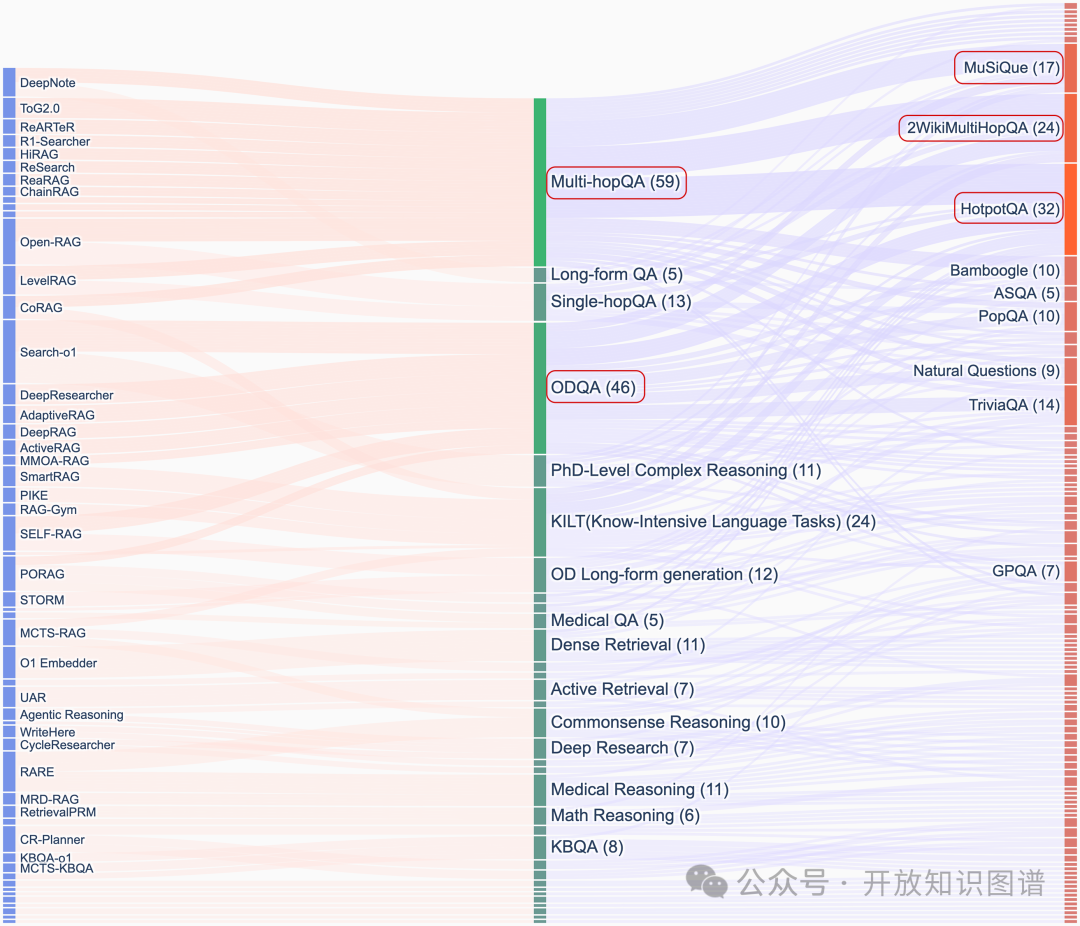
另一方面,我们也可以看到新型任务的兴起,例如
深度研究(Deep Research):开放式长文本生成(如科研报告撰写需整合多模态数据与动态检索)。
专家级推理:跨学科复杂问题(如USACO竞赛编程的算法验证与定理证明)。
评估体系革新:提出分层指标(基础性能-逻辑连贯性-应用价值)与动态环境模拟(如金融时序数据以及游戏模拟场景)。
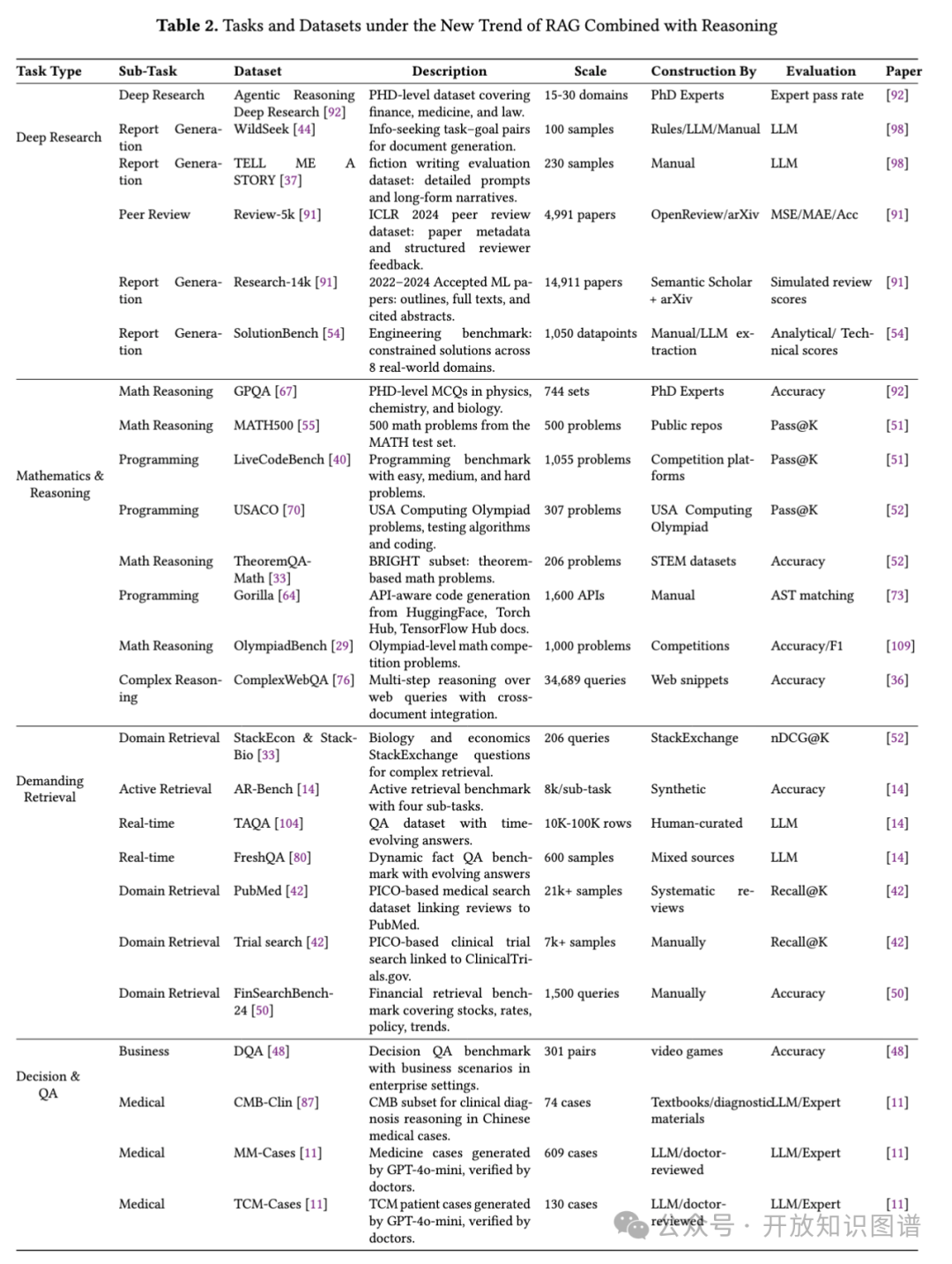
成本与风险
将推理整合到RAG系统中既不轻松,也非纯粹有利。近期趋势在夸大其优势的同时,淡化了成本和风险。性能与成本之间的权衡至关重要。
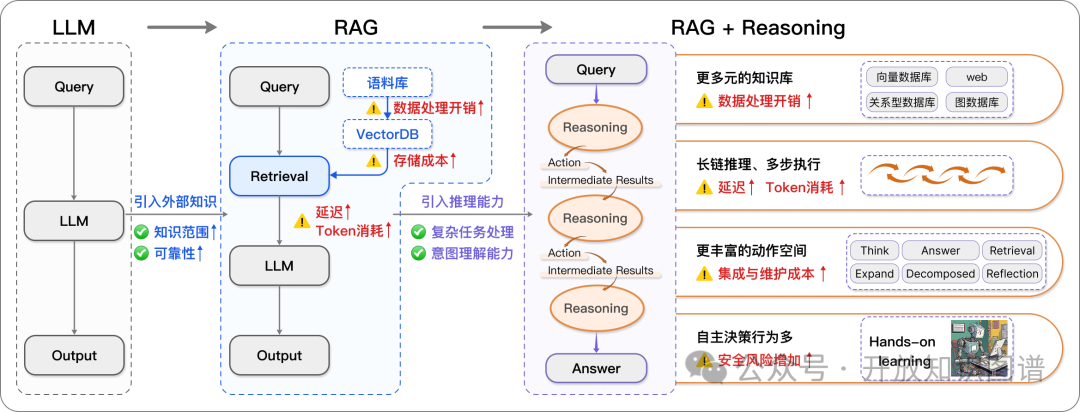
从LLM到RAG,再到RAG + 推理,伴随着不可避免的“隐形税”。尽管这一成本常被性能提升所掩盖,但它对于评估这些方法的整体实用性和效率至关重要。
从RAG到RAG + 推理的升级则增加了多步推理能力,使系统能够处理复杂任务、自主决策,并通过复杂推理提供更具上下文感知的回答。但这也带来了更长的响应时间、更高的token消耗和处理需求,同时系统集成和维护复杂度增加。推理层的自主性还带来不透明性、不可预测性以及更高的安全和可靠性风险。这些挑战凸显了在现实应用中采用RAG + 推理时,必须审慎权衡效果与成本之间的关系。
隐性成本:
计算资源非线性增长(多步推理的负载激增)。
令牌膨胀(迭代路径探索的API成本飙升)。
检索效率边际递减(动态策略的延迟累积)。
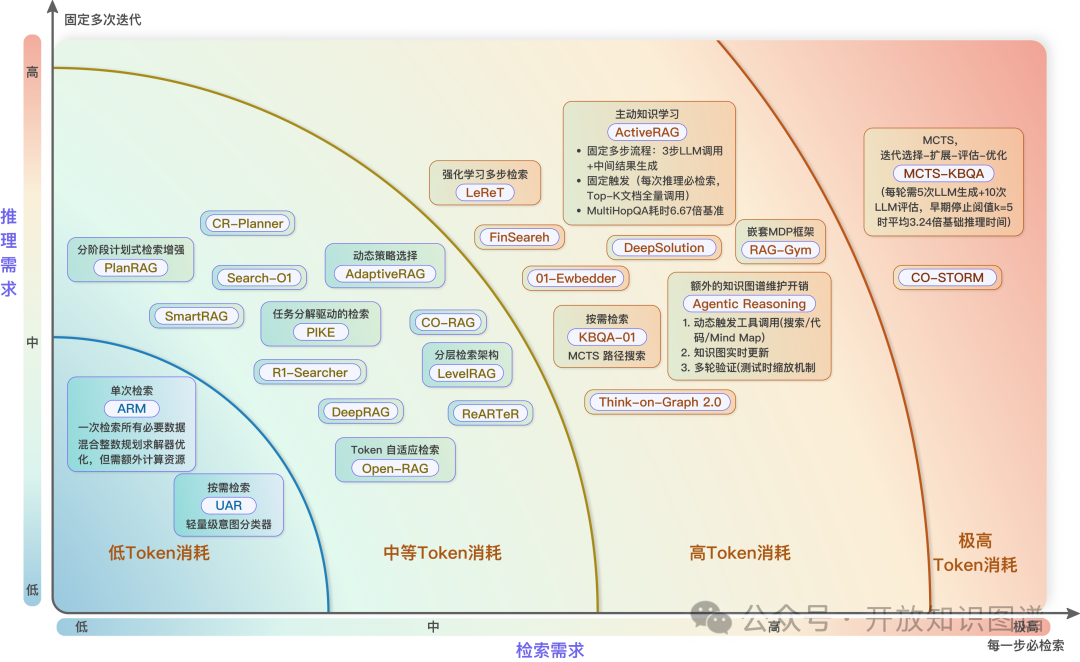
RAG+Reasoning实践指南
然而,这种“RAG+Reasoning”并非万能公式,如何因地制宜地设计系统?
行业场景特征解析
查询阶段:强调意图理解的复杂性与高级推理需求;不同行业在抽象程度和具体性上存在差异,部分需快速捕捉深层意图,另一些需复杂推理。
检索阶段:关注系统对多样且动态知识源的适应性,涵盖多领域数据与快速更新信息;面临频繁更新和知识碎片化挑战,需有效整合支持生成阶段。
生成阶段:要求高质量输出,严格控制幻觉现象,尤其在医疗、法律等敏感领域;满足实时或延迟响应不同需求。强调可解释性与可追溯性,保障系统可信度,是核心评估指标。
设计原则,避免误区
针对不同任务设定“做”和“不做”,比如预测类任务推荐分解子任务和知识图谱约束,避免无验证的推理跳跃;实时变化场景建议基于动态提示工程,轻量缓存优先,避免模型长时间微调拖慢系统响应;高风险领域必须确保多层审查和规则过滤,禁止自主执行高风险决策。
未来机遇
构建冷热分层索引与动态上下文管理,提升数据检索效能与时效性;
跨机构、多领域知识库的融合共享,打通信息孤岛,强化推理基础;
探索事件驱动、时空感知和多模态融合技术,赋能复杂场景的精准响应;
引入风险传播建模与决策拦截机制,为高风险场景保驾护航;
推动边缘与云端协同,实现实时智能的敏捷计算能力。

总结
RAG与推理技术的协同应用正处于快速发展阶段,展现出强大的技术潜力和广泛的应用价值。尤其在金融、医疗、法律和智能助理等关键领域。未来的研究方向值得关注,包括基于图结构的知识整合、多模态与多模型的协同推理架构,以及利用强化学习等先进技术,进一步优化检索与推理的整体工作流。
了解更多
论文全文:Synergizing RAG and Reasoning: A Systematic Review (arxiv:2504.15909)
论文链接:https://arxiv.org/abs/2504.15909
相关资源和论文汇总请见OpenRAG平台:OpenRAG
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









