







2、Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors(SBR)
论文地址:https://arxiv.org/abs/1807.00966
目前训练 CNN 模型需求少量的标注数据。但是标注少量的数据需求耗费很多的人力资源,并且人工标注往往不精确。如下图所示是在两张嘴的图片上标注 16 个关键点的地位,一个颜色表示一个关键点,我们给出了九个标注人员的标注后果,可以发现每个标注人员对关键点的定位方差很大。这些标注误差对训练和测试模型会有很大的影响。因而,就想能不能运用一种不需求人工标注的监视信息来训练 CNN 模型?基于这个目的,提出了 supervision be registration,应用视频里相邻帧间时序分歧性来作为监视信息。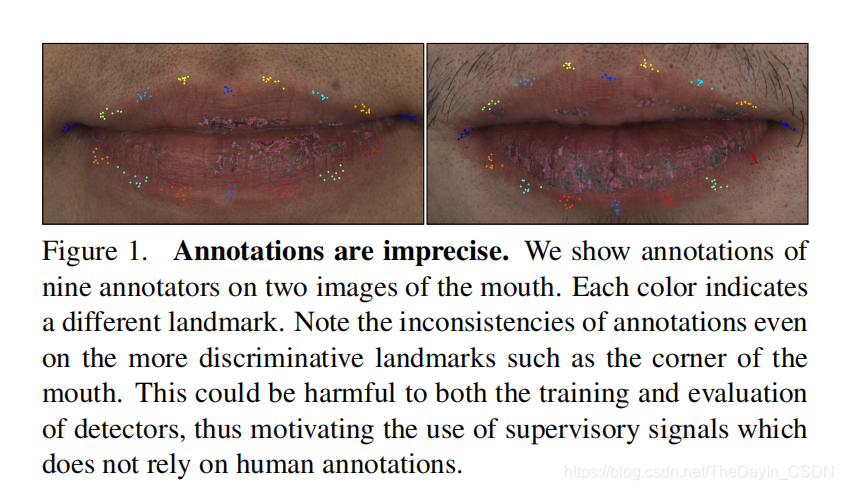
Supervision-by-Registration(SBR) 是一个训练人脸关键点检测器的算法框架,可以应用无监视的方式加强任何基于图像的人脸关键点检测器。SBR 应用了物体在视频中的运动比拟平滑的特性来提升一个现有的人脸关键点检测器。相比拟其别人脸关键点检测算法,SBR 不需求应用任何额定的人工标注信息就能提升检测器的功能。
SBR 运用的训练数据是有标注的图像数据和无标注的视频数据。在训练进程中,SBR 可以用无监视的方式从视频中提取监视信息来优化检测器(神经网络)。在测试阶段,运用 SBR 训练的模型,可以在图像或视频数据上到达具有更高的精度,并且能让在视频中检测后果愈加波动。
下图是 SBR 的框架表示图。
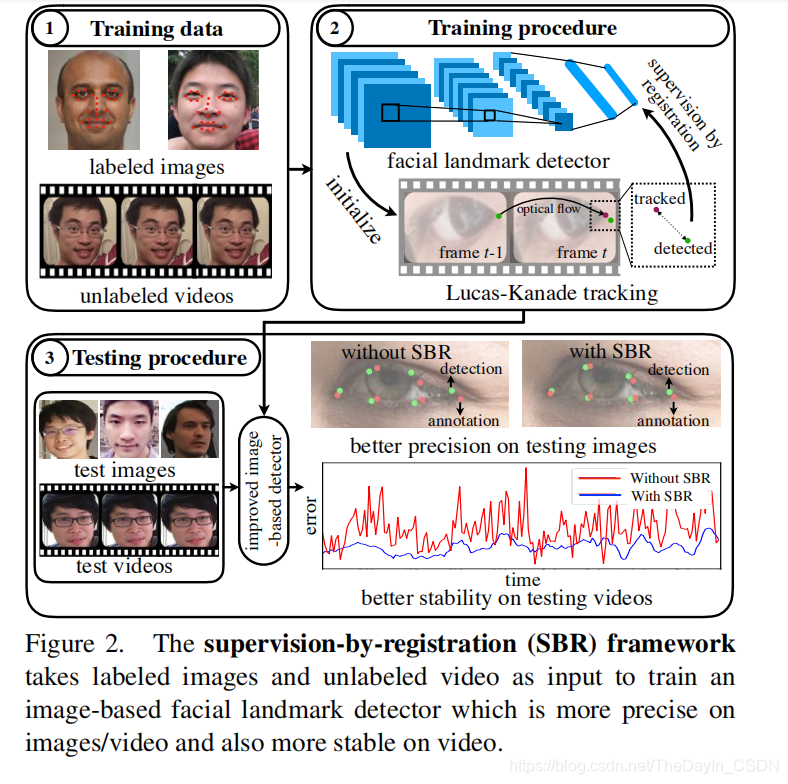
SBR 的训练进程包括两个损失函数。一个是检测器损失函数,另一个是时序配准损失函数。这两者可以互相补充让人脸关键点检测器愈加鲁棒。检测器损失函数作用于模型检测后果和人工标注上,优化使得在有标注的数据上,模型的检测后果和人工标注尽能够的接近。时序配准损失函数是优化在延续几帧内关键点检测后果的时序分歧性。详细来说,输出延续的两帧图像 t-1 和 t,经过同一团体脸关键点检测器后,可以失掉关于第 t-1 帧的检测后果和第 t 帧的检测后果,我们将第 t-1 帧的检测后果经过 Lucas-Kanade 算法跟踪到第 t 帧失掉后果,时序配准损失函数就是为了让在第 t 帧上跟踪失掉的后果和检测失掉的,尽能够分歧。值得留意的是,由于 Lucas-Kanade 算法不需求训练且有封锁解,我们将 Lucas-Kanade 算法写成了一个可求导的模块嵌入到 CNN 中。在训练的时分,检测器损失函数应用人脸外观信息经过人工标注学习关键点检测器;时序配准损失函数经过嵌入 Lucas-Kanade 模块保证了时序分歧性。梯度可以经过 Lucas-Kanade 模块传给检测模型使得检测后果在相邻帧上分歧。(关于不同的检测器,检测器损失函数能够有所不同,比方比拟经典的 CPM 和 Hourglass 运用 mean squared error 来优化检测器,也有一同些办法运用 L2 loss 优化。SBR 是一个通用的算法,可以作用于各种不同的人脸关键点检测器,提升他们的功能。)
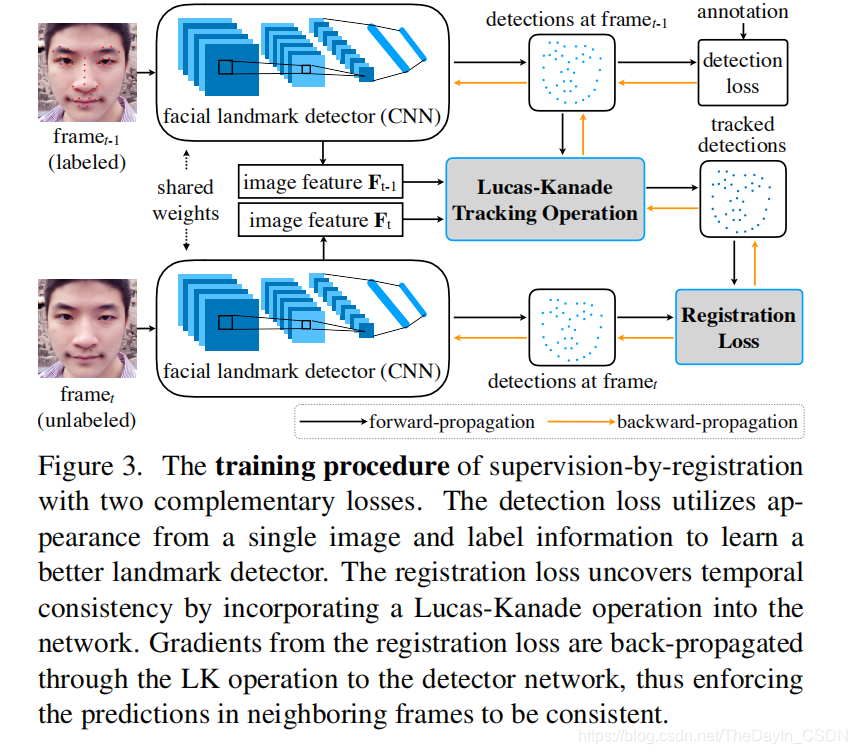
SBR 的中心是时序配准损失函数,依赖于 Lucas-Kanade 跟踪模块,所以跟踪的后果的好坏直接影响着 SBR 的效果。同时,检测器预测的坐标是 Lucas-Kanade 跟踪模块的初始化坐标,只要当这个初始坐标大致精确的时分跟踪才有意义。所以运用需求留意两点,(1)当检测器在标注图片初始化好之后在开端运用 SBR 训练。(2)选择无标注的视频时需求留意视频的分辨率/人脸大小/遮挡等条件来保证 Lucas-Kanade 跟踪模块可以成功跟踪。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









