







一、MIPS 5段流水总览
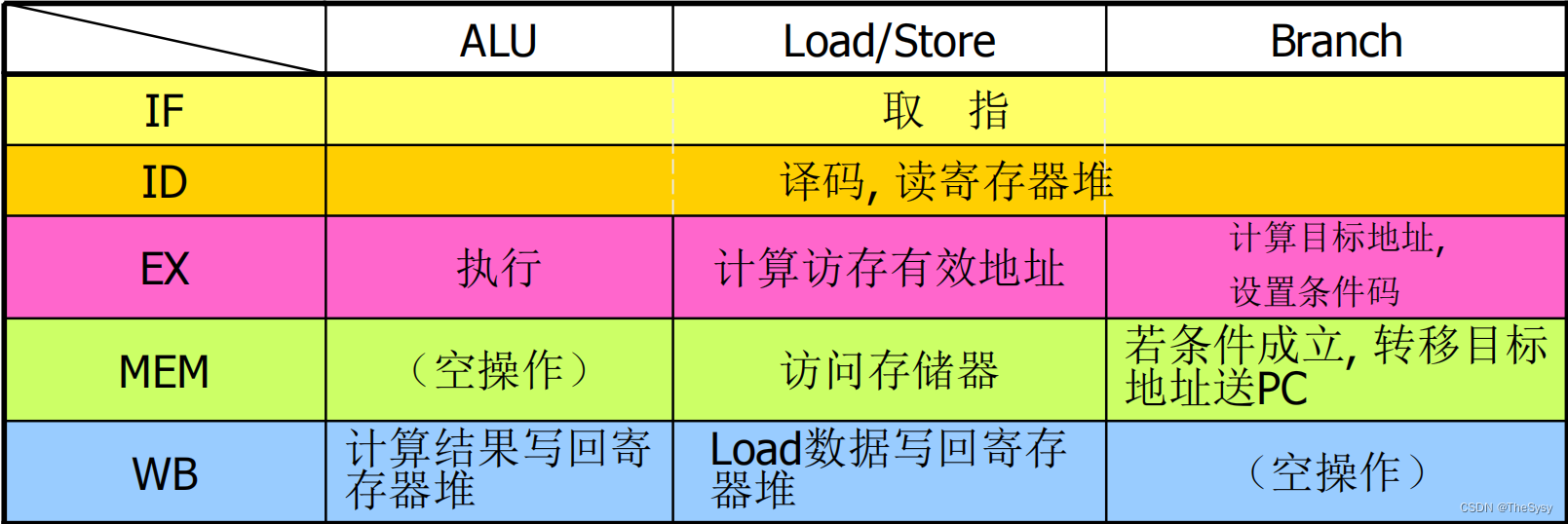
分五段流水:取指,译码,执行,存储器访问,写回
三种指令:算数逻辑操作,存储器访问操作,分支跳转指令
二、流水线例子
1、取指
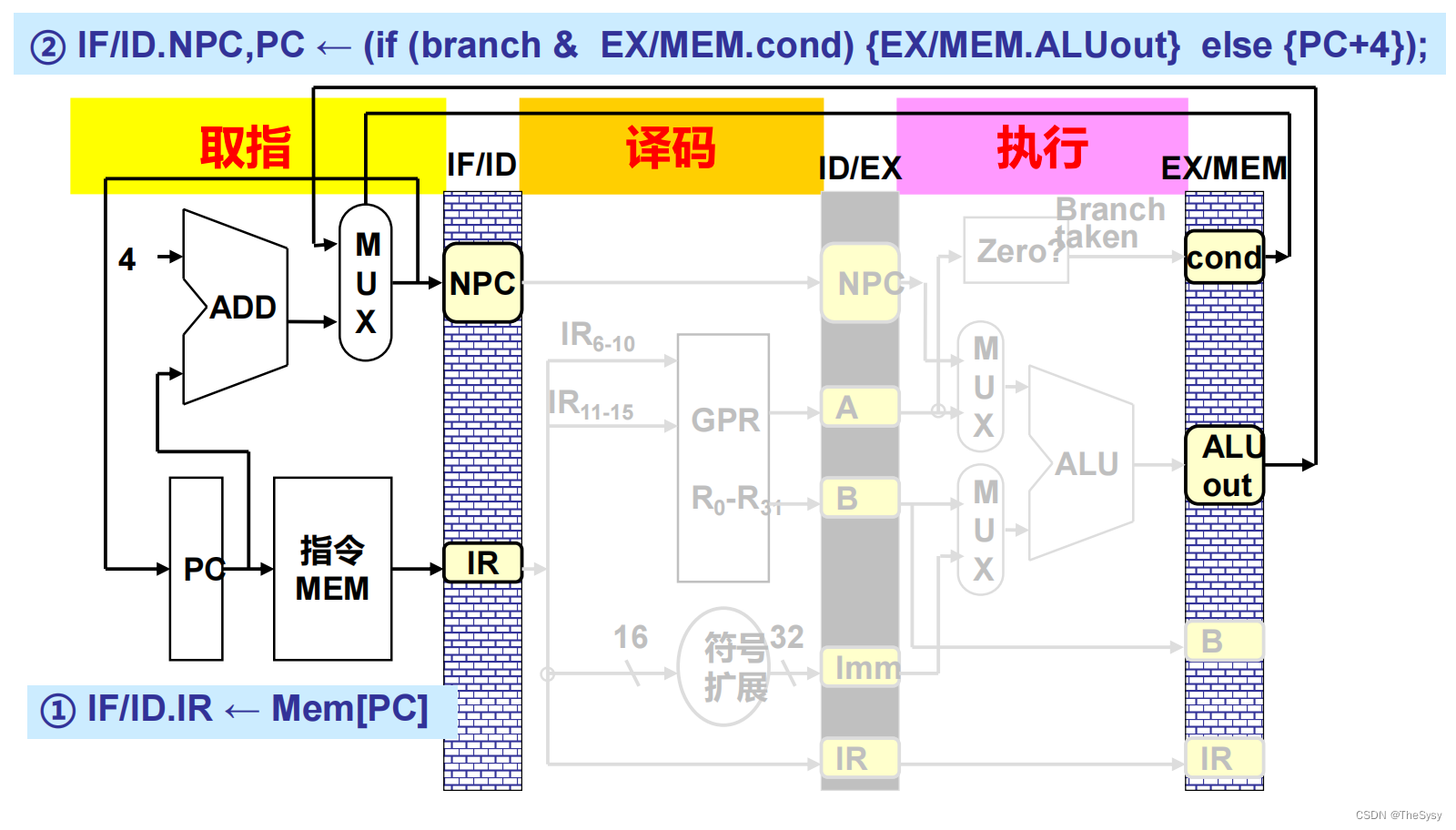
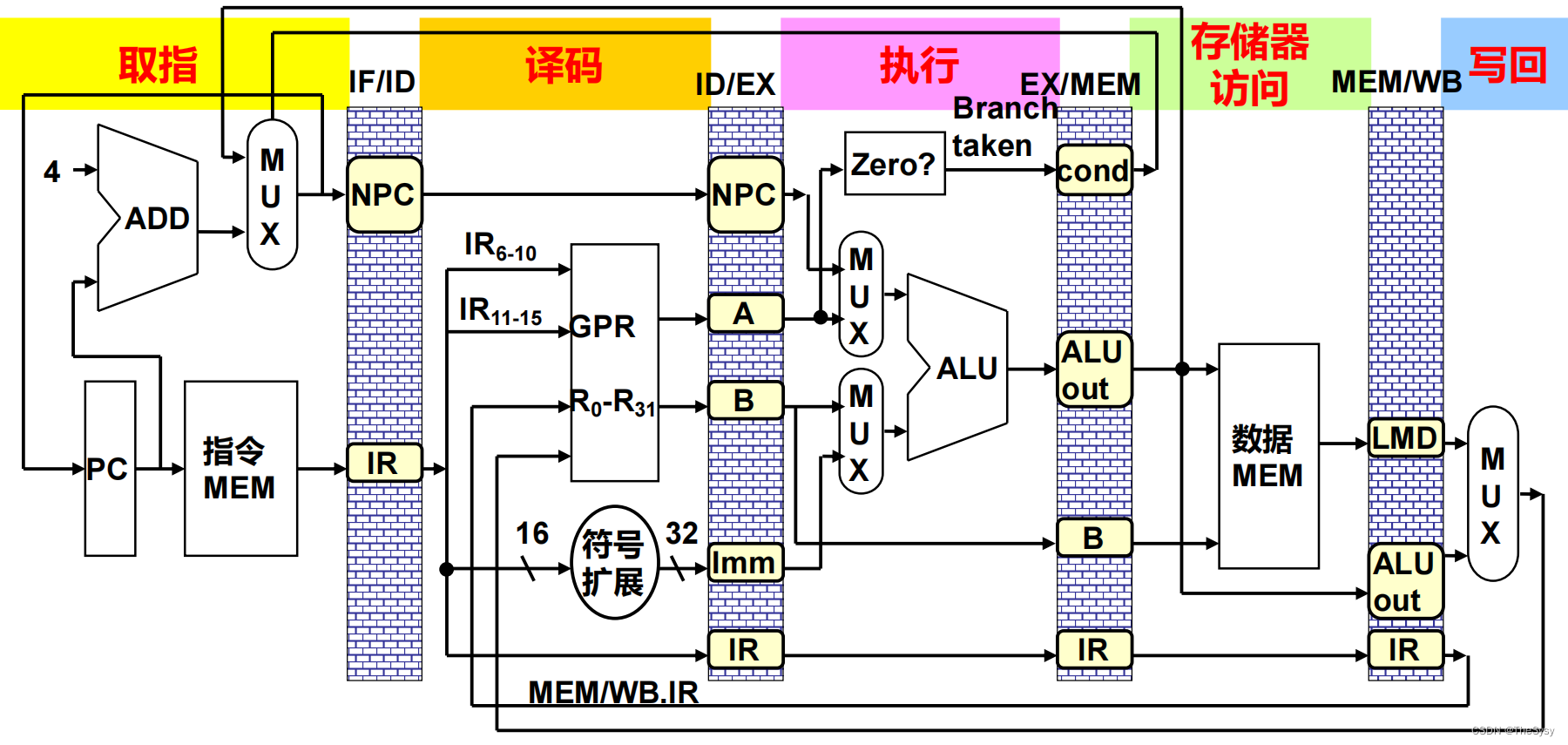
首先第一步要从内存中把当前PC的指令取出来,放到锁存器IR里,然后看上面,把当前PC地址送到加法器+4生成下一条指令的地址,但是因为也可能有跳转指令,下一条该执行的指令不是PC+4,所以需要把PC+4和后面流水段产生的跳转地址送进多路选择器(MUX),确定下一条PC(NPC),压入锁存器。
2、译码

MIPS指令遵循一定的格式,看着两个例子
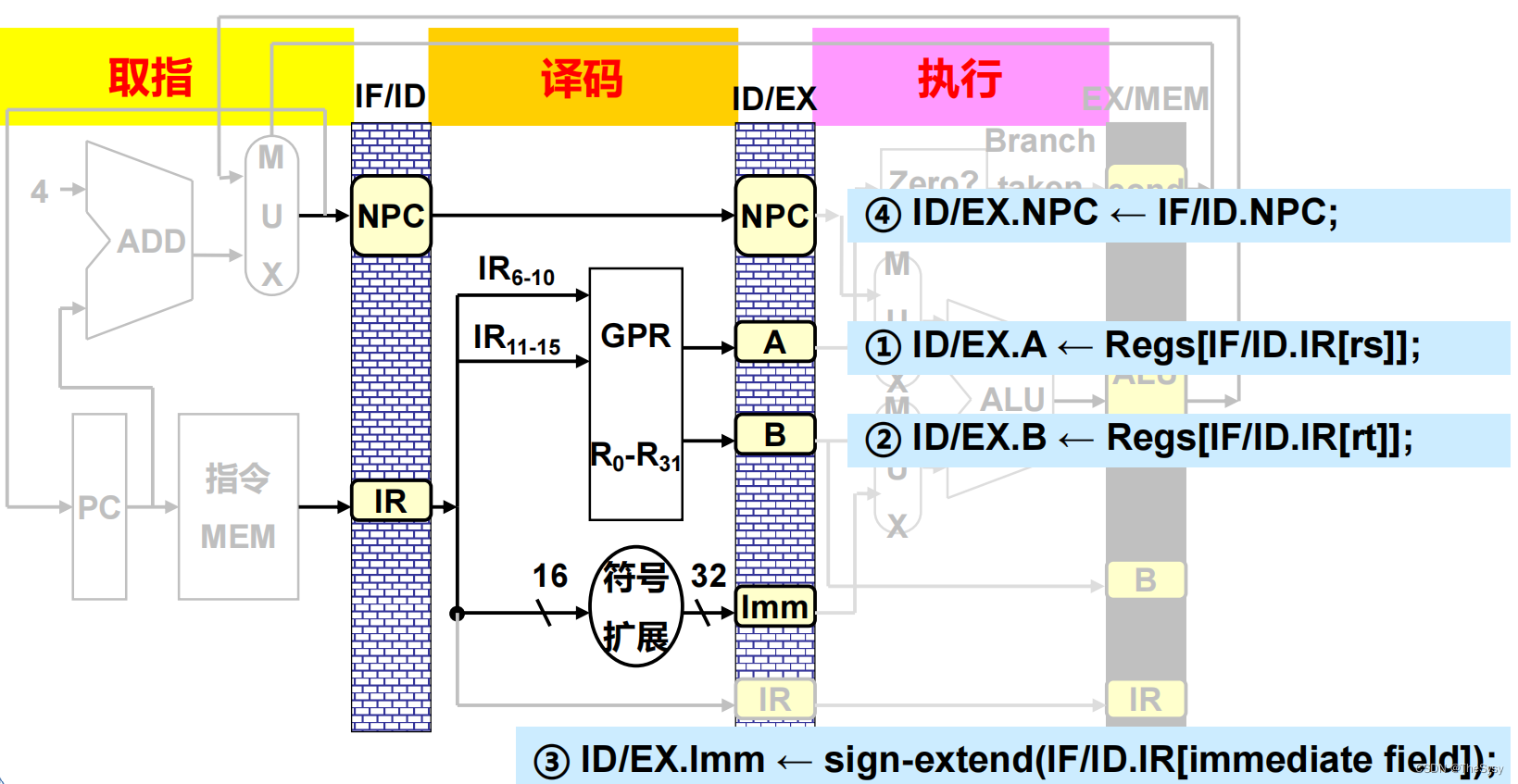
这样就可以来看译码的过程了,首先辨认出该操作类型,然后把两个操作数压入下一级锁存器,如果有立即数,那就把立即数经过符号扩展之后,压入下一级锁存器。然后这一步没有用到NPC,就继续推入下一级锁存器,指令IR也会在后面的步骤用到,所以也推入下一级锁存器。
3、ALU执行、存储器访问、写回
到刚才那两步,算术逻辑运算和存储器存取指令还没有区别,到执行时就不同了
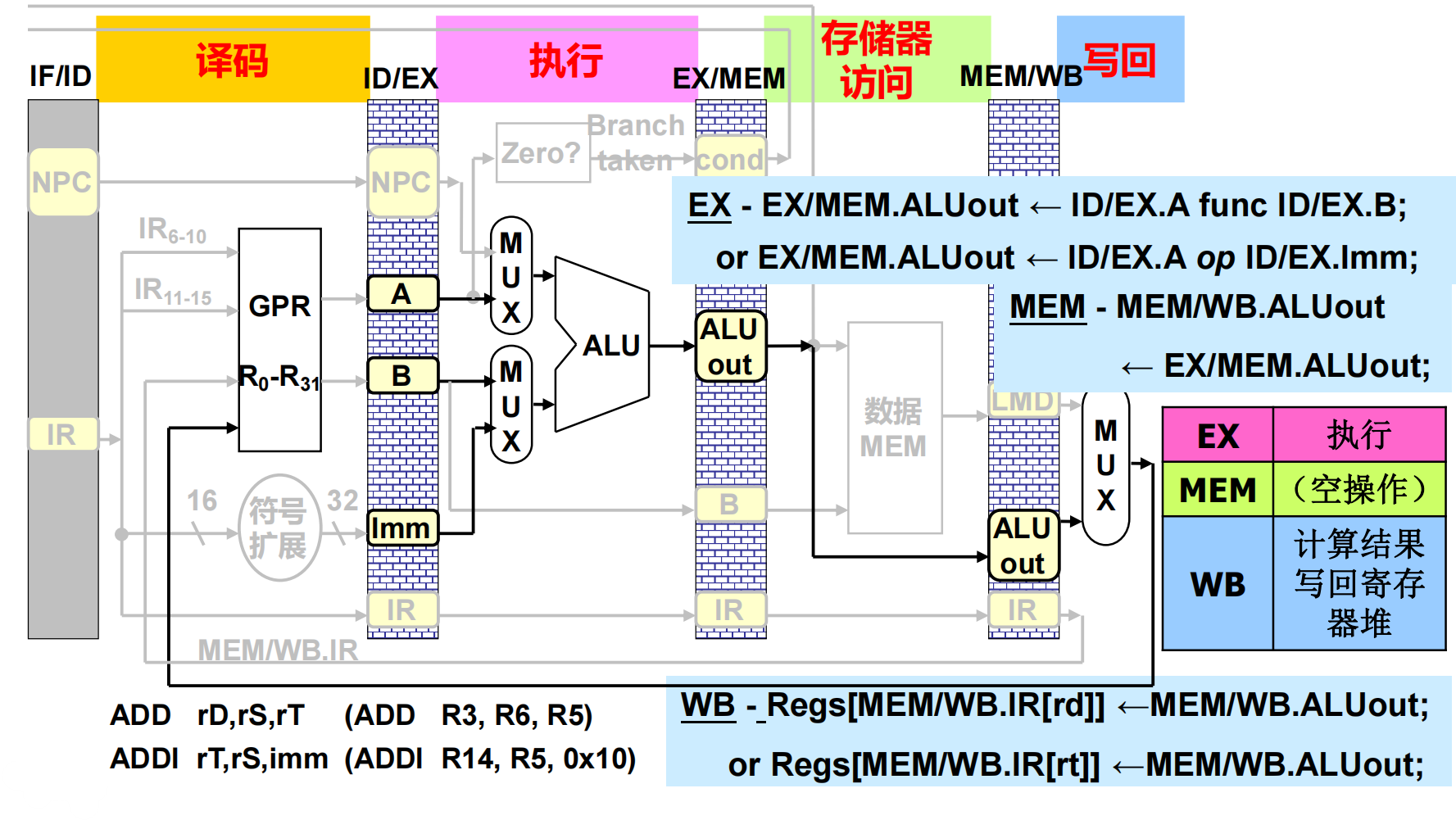
对于ALU操作来说,ALU操作的第一个操作数从ID/EX的A中取到,第二个操作数从B或者下面的立即数中取到,执行完ALU操作后,把结果压入下一级锁存器,由于不涉及存储器访问操作,所以存储器访问这一步是空操作,直接把结果压入再下一级锁存器,再根据先前一直往后压的IR,来选择写回到哪个寄存器中,在写回步执行寄存器堆访问,把计算结果写回到寄存器堆。
4、存取指令执行、存储器访问、写回
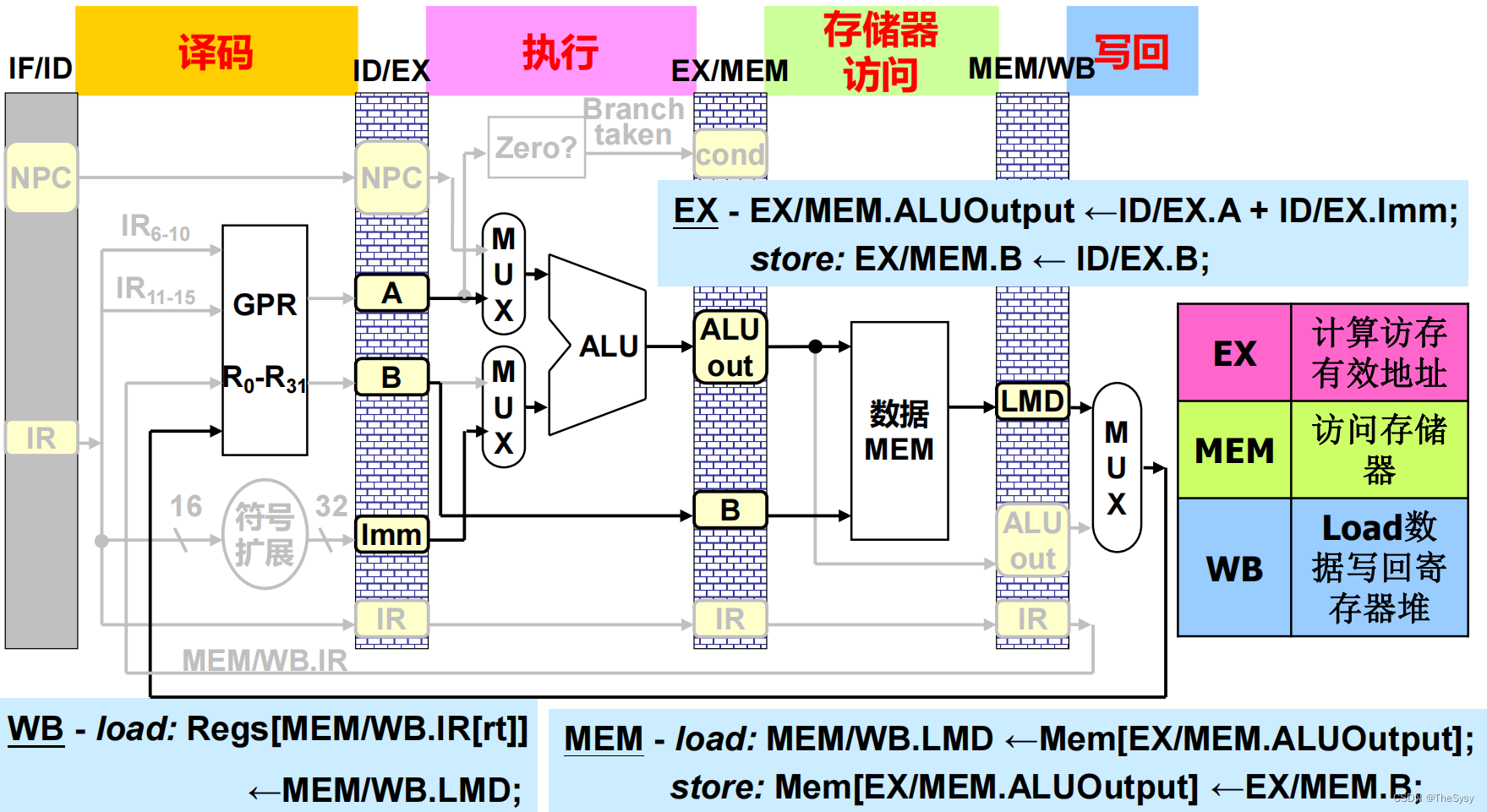
在执行段,需要通过基址+偏移来计算要存或取的内存地址,基址从A中出,偏移从立即数中出,计算完结果放下一级锁存,这时候存和取也要分开来讨论,如果是取,那么有了地址,直接在存储器访问段访问存储器,取出地址,通过一直压过来的IR来选择写回的寄存器存进去就好了。如果是存,那么B就会放要存的数据,在存储器访问段,通过ALU算出来的地址,和B中的数据,去写存储器,然后写完就完了,写回段是空操作。
三、相关
下面简要描述一下相关这个概念。
冲突来源于相关,总的有两种相关,一种数据相关,一种控制相关。
数据相关:简单的三大类,1、写后读,一条读指令紧跟在写指令后面,这会产生冲突。2、写后写,这不会产生冲突,两个写都在写回段,这两段是按顺序的。3、读后写,这也不会冲突。
控制相关:典型的就是if-then结构。
四、冲突
现在讨论三种冲突
1、结构冲突
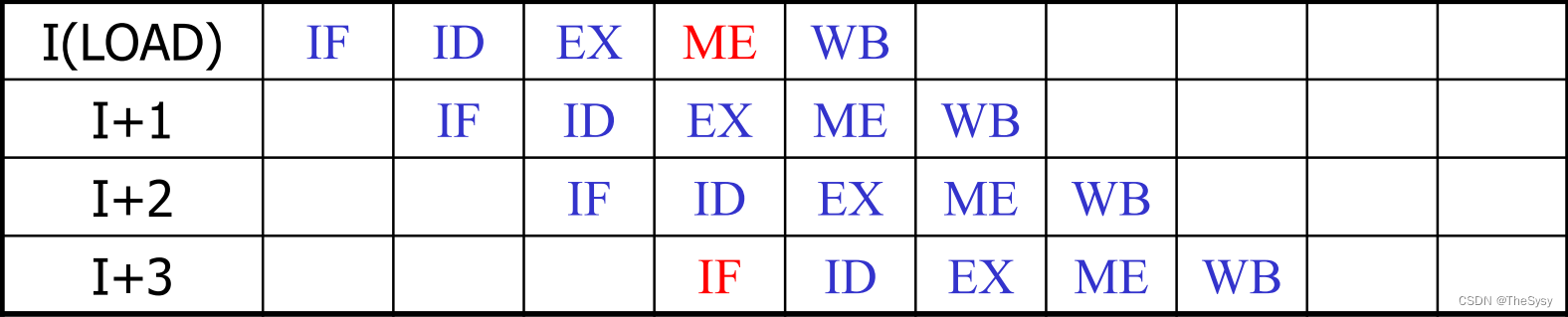
典型的结构冲突,第一条load的存储器访问,和第四条的取指冲突了,因为取指也要访问存储器。
这就有两种解决办法,第一种那就牺牲速度,在取指前面加一个stall,停顿一个周期。
另一种就是哈佛结构,把指令cache和数据cache分离,走两条总线,就可以同时访问了。
2、数据冲突
当两条相关的指令离得太近时,就会由于流水线的重叠,而导致原先的读写顺序改变,而导致问题。
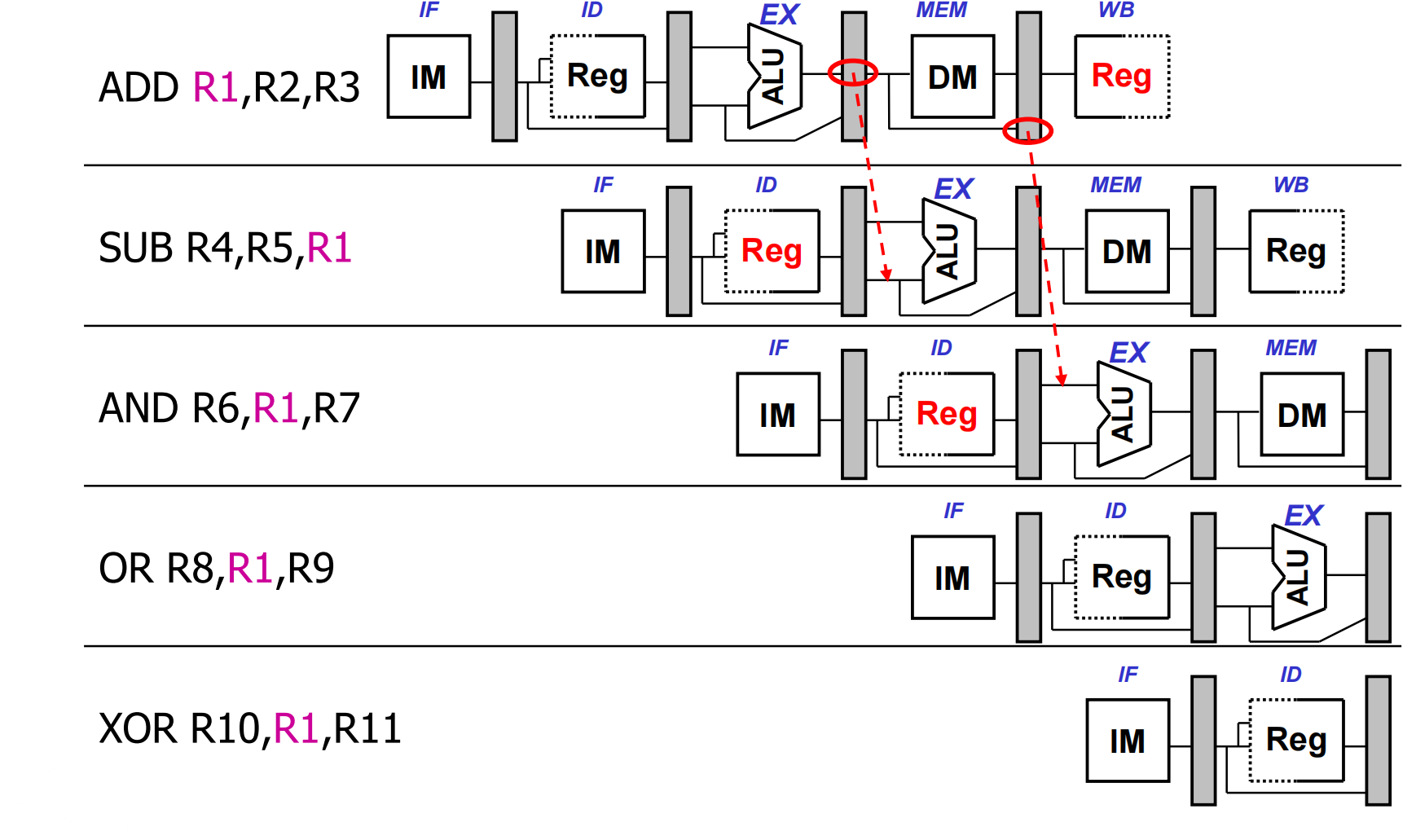
看这个例子,第一条指令写了R1寄存器,但是结果正常要在WB写回之后才有,最极端的就是下面三条指令都要读R1寄存器,这时候就会产生问题。先看最远的第五条,第五条读寄存器堆的动作会在第一条写回之后执行,那就没问题。
然后看第四条,第四条读寄存器堆的操作会和第一条写回在同一个周期执行,那么这时候就有问题了,这两个不能同时执行,那怎么办,改进的方法就是可以通过改进硬件,让第一条指令在前半个时钟周期写回,让第四条在后半个时钟周期读,这样就可以了。
然后看第三条,第三条要访问寄存器堆的时候,结果才刚从ALU算出来,还得最起码一个半时钟周期才行,那就得另寻他法,不访问寄存器堆了,反正我是在执行段才用上这个数,那就通过定向传送技术,把第一条的结果,从MEM/WB段锁存中接两条线分别接到ALU的两个输入上。考虑这样一个问题,为什么不能从ALU的结果那接一根线过来,因为第三条指令执行的时候,ALU的结果已经不是第一条的结果了,是第二条的结果。
然后看第二条,一样的道理,我们还是用定向传送技术,从ALU的结果上接两根线接到ALU的两个输入上。
这还没完,再看这样一个load/store的例子
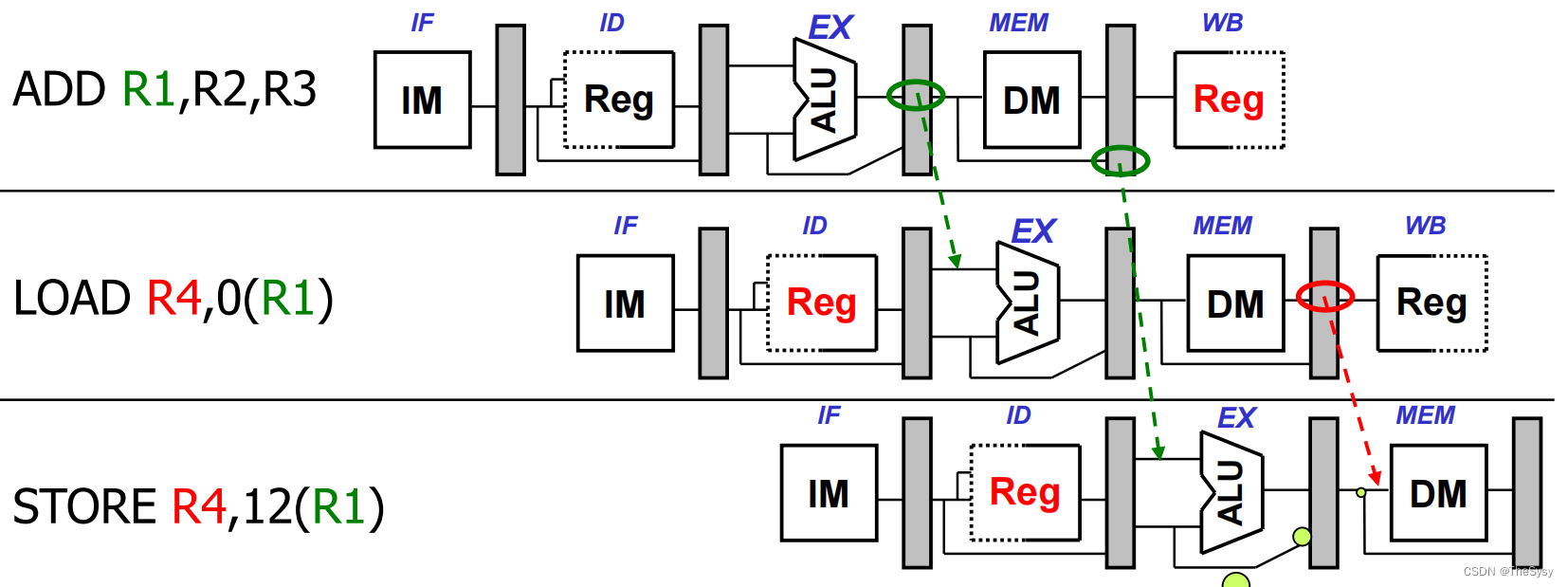
对于第二条,load的时候,在计算要访问的内存地址时,用到了上一条指令算出来的R1,这个可以解决,就是刚才说的把ALU的结果接到ALU的输入上。
但是第三条,store指令要存的数据,是刚刚LOAD上来的,刚刚load上来的数,正常只有在写回到寄存器之后才能读,但这显然不行,我们看看该怎么办,可以从MEM/WB锁存器中把刚刚load上来的数,接根线接到存储器访问这一步的数据入口,考虑要不要再接一根到地址入口,这个问题的关键在于,内存访问的地址,是否可以不通过ALU中的偏移计算来得到,也就是像这样的指令STORE R3,(R4)是否存在,因为在这个情况下,R4可能是上一条load指令的直接结果。
考虑另一个问题,
LOAD R4,0(R1)
STORE R2,12(R4)
这种情况下就连定向传送都救不了了,因为刚刚load上来的R4的值,还需要进ALU加偏移算完才能去寻址,这样就必须stall一拍了。
还有一种技术,静态调度,来解决数据冲突,通常是编译器来完成,看这个例子。
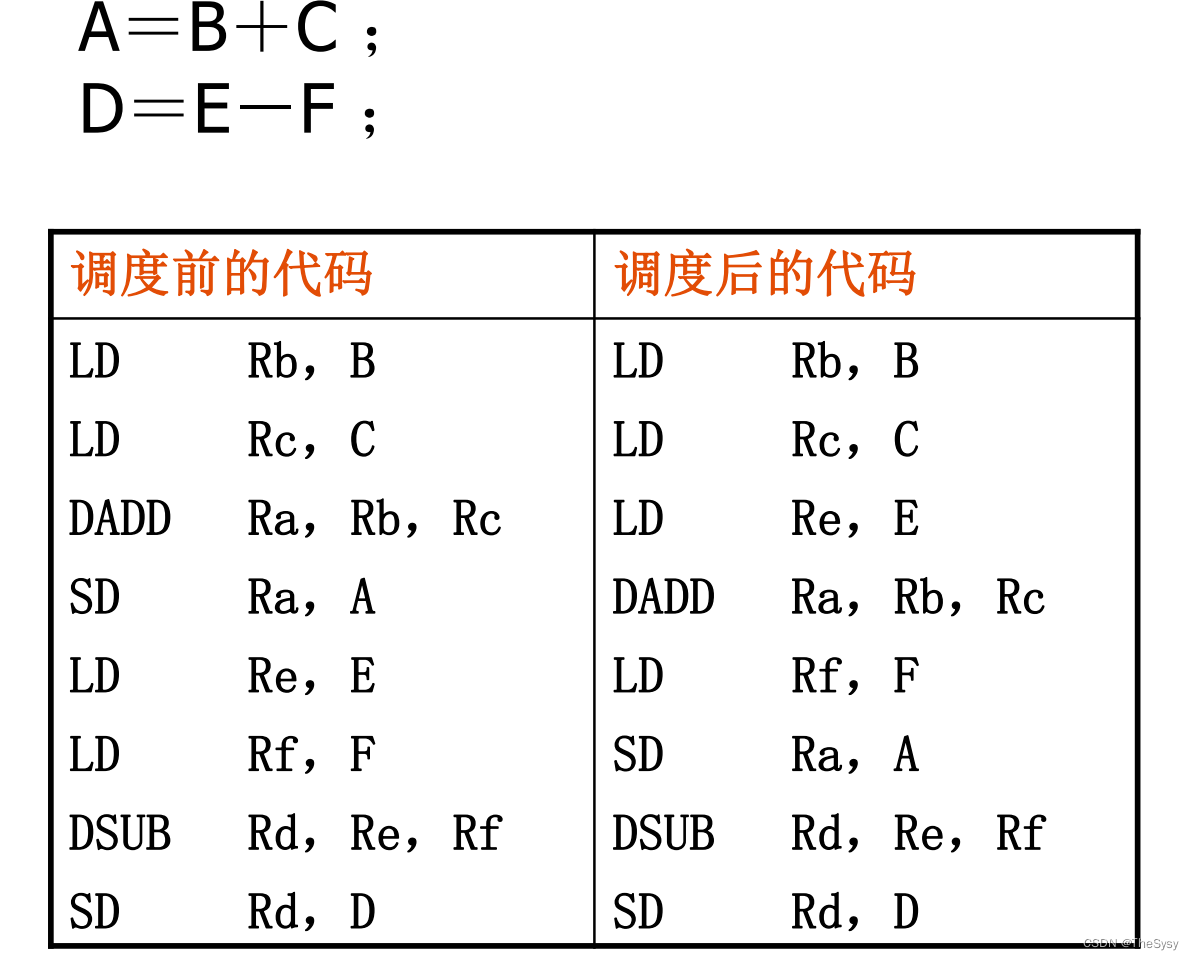
调度前就是一步一步的,先把B、C load上来,然后add,写入a,store回内存,然后再load E、F,然后sub,写入d,然后store回内存。
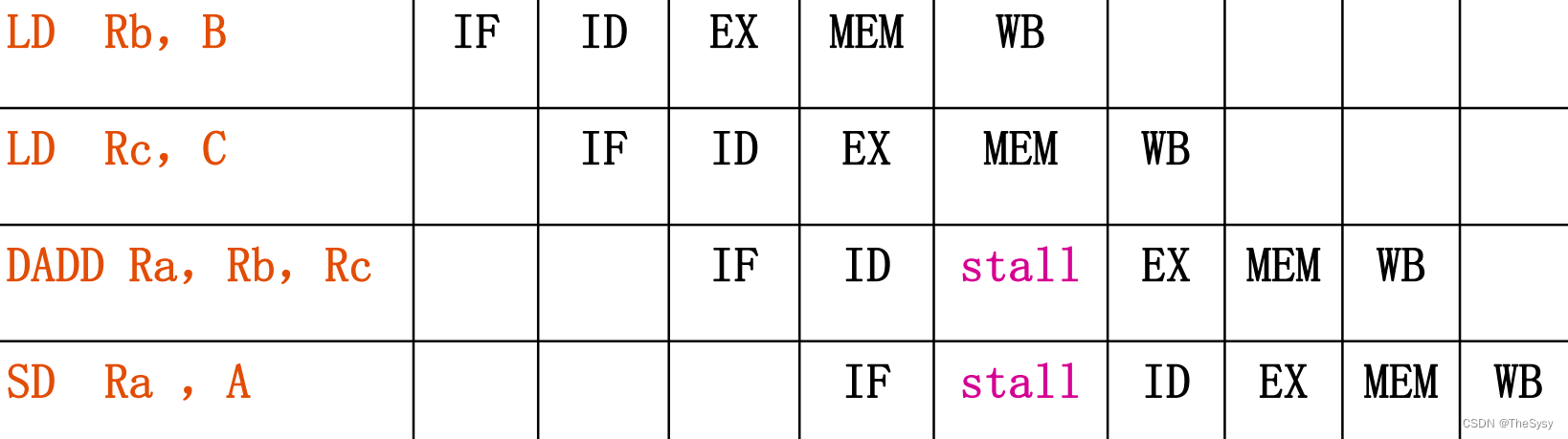
这样你在第三条加的时候就会出现问题,就需要stall了,因为执行的时候ALU需要上一条内存访问load进来的c的值。那我这个时候就把后面的load E提到这里进行,不久不需要stall了,这就是静态调度的思路。
3、控制冲突
就是遇到跳转指令时,该怎么办。
1)就stall
下面考虑最简单的解决办法,我还是正常取PC+4,那么什么时候我可以知道到底要不要跳转呢,要到ME段之后,先前要进行条件的判断和跳转地址的计算,所以要stall两拍,如果条件成功,需要跳转,那我这前面这个PC+4就白取了,需要等stall两拍之后再重新取指,如果条件失败,那就是不用跳转,那就可以在stall两拍之后直接译码执行。这样如果条件成功失败各50%概率的话,期望就是stall2.5拍。

2)改进流水
那怎么办呢,我们想着,如果这个条件的判断和跳转地址的计算可以提前出来就好了。我们就改进了流水,看下图,首先在译码段添加了一个全加器,因为我们发现,地址的计算并不需要ALU那么复杂的功能,只要加减法就够了,然后又在这段添加了条件的判断,这段是怎么实现的?
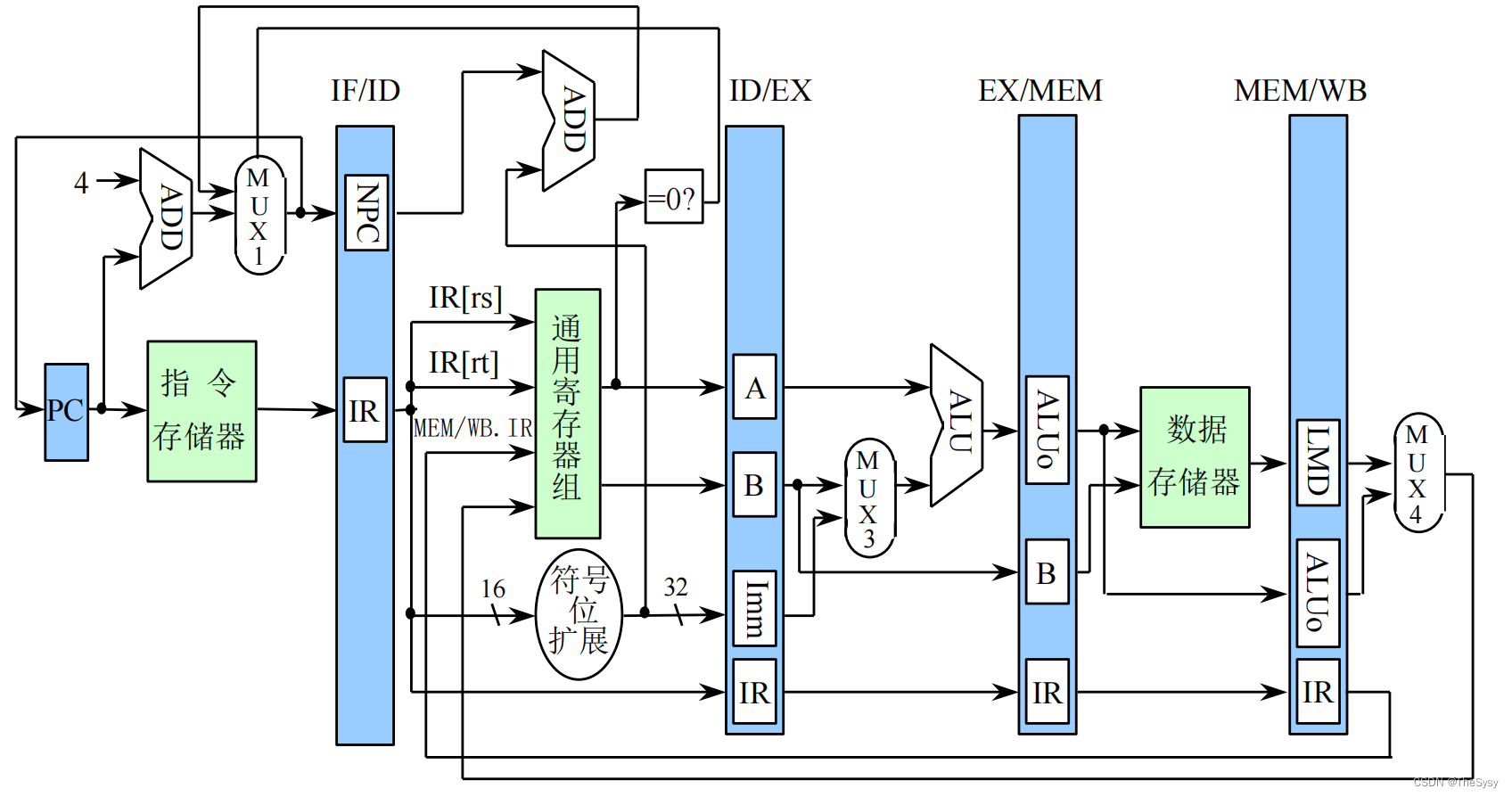
这样我们就把条件的判断和跳转地址的计算提前到了译码段执行,这样剩下执行、存储器访问、写回段甚至都没用了,就是说同时还解放了一部分流水。

这样我们就只用stall一拍就可以了。
3)软件预测(编译器)
我们甚至还可以更进一步,我们可以不stall,在这一拍取PC+4,这样等下一拍结果出来之后,如果不跳转,那就血赚,顺着执行就好,如果跳转,那就再取指,相当于stall了一个周期,这样总的算下来,如果还是各50%,那期望就是stall了半拍。
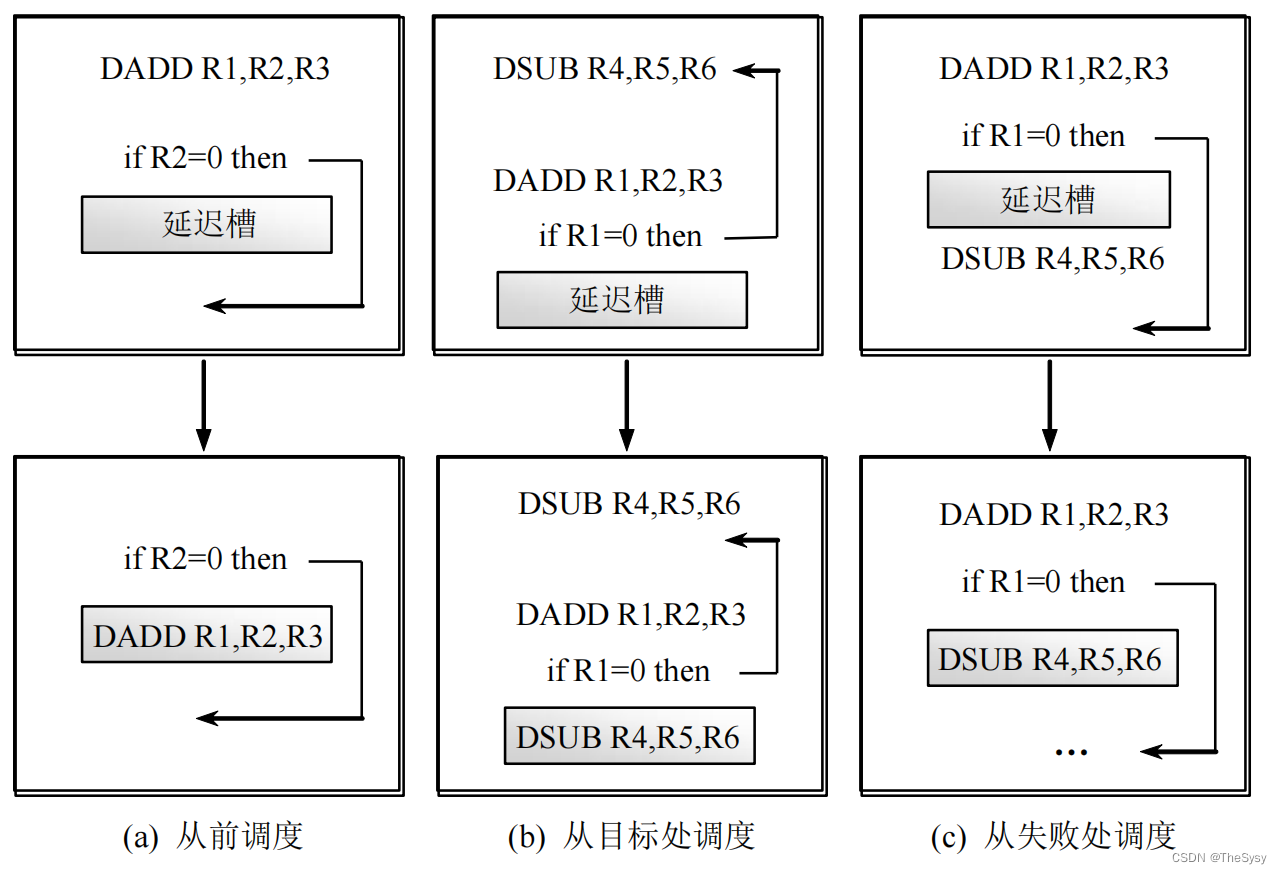
还可以怎么样,我可以延迟分支,我在跳转指令紧跟这的那条插一条别的指令,这样不就相当于一条都没有stall吗。这有三种插法,第一种就是从跳转之前取一条下来,这样只要保证逻辑不出问题,就没有stall了。第二种是从跳转成功的那部分取一条过来,执行这条,也是同样要保证如果不跳转,逻辑不能出问题,但是这种就类似于前面的了,如果跳转不跳转是50%,那就还是相当于期望是半拍。第三种是从跳转失败的那部分取一条过来,这个就跟上面第二种同理,如果跳转了的话逻辑不能出问题,而且期望也不是0拍。















 3533
3533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









