







MySQL优化二
1. 索引优化案例
单表优化
建表
create table article(
id int unsigned not null primary key auto_increment,
author_id int unsigned not null,
category_id int unsigned not null,
views int unsigned not null,
comments int unsigned not null,
title varchar(255) not null,
content text not null
);

插入数据
insert into article(`author_id`,`category_id`,`views`,`comments`,`title`,`content`) values
(1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(1,1,3,3,'3','3');

需求:查询category_id为1且comments大于1的情况下,views最多的article_id
修改前:

修改后:

双表优化
建表
商品类别表
create table class(
id int unsigned not null primary key auto_increment,
card int unsigned not null
);
图书表
create table book(
bookid int unsigned not null auto_increment primary key,
card int unsigned not null
);

随机数



建立左连接
查看性能

优化

左连接 左表是一定要全班扫描的 所以给右表加上索引就OK了(也可以两个表都加 想要性能更好,不过没必要)
如果是右连接 给左表加上索引就OK(也可以两个表都加 想要性能更好,不过没必要)
建立内连接

查看性能

优化


如果是建立内连接 给两个表都加上索引会大大优化性能
2. Join语句优化
我们在使用数据库查询数据时,有时一张表并不能满足我们的需求,很多时候都涉及到多张表的连接查询。今天,我们就一起研究关联查询的一些优化技巧。在说关联查询优化之前,我们先看下跟关联查询有关的几个算法:
为了方便理解,首先创建测试表并写入测试数据,语句如下:
CREATE TABLE `test_join` ( /* 创建表t1 */
`id` int(11) NOT NULL auto_increment,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
COMMENT '记录更新时间',
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.1 关联查询的算法
- Nested-Loop Join 算法
- Block Nested-Loop Join 算法
Nested-Loop Join 算法
一个简单的 Nested-Loop Join(NLJ) 算法一次一行循环地从第一张表(称为驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动表)里取出满足条件的行,然后取出两张表的结果合集。
我们试想一下,如果在被驱动表中这个关联字段没有索引,那么每次取出驱动表的关联字段在被驱动表查找对应的数据时,都会对被驱动表做一次全表扫描,成本是非常高的(比如驱动表数据量是 m,被驱动表数据量是 n,则扫描行数为 m * n )。
好在 MySQL 在关联字段有索引时,才会使用 NLJ,如果没索引,就会使用 Block Nested-Loop Join。我们先来看下在有索引情况的情况下,使用 Nested-Loop Join 的场景(称为:Index Nested-Loop Join)。
因为 MySQL 在关联字段有索引时,才会使用 NLJ,因此本节后面的内容所用到的 NLJ 都表示 Index Nested-Loop Join。
select * from t1 inner join t2 on t1.a = t2.a;
怎么确定这条 SQL 使用的是 NLJ 算法?

从执行计划中可以看到这些信息:
- 驱动表是 t2,被驱动表是 t1。原因是:explain 分析 join 语句时,在第一行的就是驱动表;选择 t2 做驱动表的原因:如果没固定连接方式优化器会优先选择小表做驱动表。所以使用 inner join 时,前面的表并不一定就是驱动表。
- 使用了 NLJ。原因是:一般 join 语句中,如果执行计划 Extra 中未出现 Using join buffer (***);则表示使用的 join 算法是 NLJ。
sql1 的大致流程如下:
- 从表 t2 中读取一行数据;
- 从第 1 步的数据中,取出关联字段 a,到表 t1 中查找;
- 取出表 t1 中满足条件的行,跟 t2 中获取到的结果合并,作为结果返回给客户端;
- 重复上面 3 步。
在这个过程中会读取 t2 表的所有数据,因此这里扫描了 100 行,然后遍历这 100 行数据中字段 a 的值,根据 t2 表中 a 的值索引扫描 t1 表中的对应行,这里也扫描了 100 行。因此整个过程扫描了 200 行。
在前面,我们有说到:如果被驱动表的关联字段没索引,就会使用 Block Nested-Loop Join(简称:BNL),为什么会选择使用 BNL 算法而不继续使用 Nested-Loop Join呢?
Block Nested-Loop Join 算法
Block Nested-Loop Join(BNL) 算法的思想是:把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比,如果满足 join 条件,则返回结果给客户端。
我们一起看看下面这条 SQL 语句:

在 Extra 发现 Using join buffer (Block Nested Loop),这个就说明该关联查询使用的是 BNL 算法。
我们再看下 sql2 的执行流程:
- 把 t2 的所有数据放入到 join_buffer 中
- 把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比
- 返回满足 join 条件的数据
在这个过程中,对表 t1 和 t2 都做了一次全表扫描,因此扫描的总行数为10000(表 t1 的数据总量) + 100(表 t2 的数据总量) = 10100。并且 join_buffer 里的数据是无序的,因此对表 t1 中的每一行,都要做 100 次判断,所以内存中的判断次数是 100 * 10000= 100 万次。
下面我们来回答上面提出的一个问题:
如果被驱动表的关联字段没索引,为什么会选择使用 BNL 算法而不继续使用 Nested-Loop Join 呢?
在被驱动表的关联字段没索引的情况下,比如 sql2:
如果使用 Nested-Loop Join,那么扫描行数为 100 * 10000 = 100万次,这个是磁盘扫描。
如果使用 BNL,那么磁盘扫描是 100 + 10000=10100 次,在内存中判断 100 * 10000 = 100万次。
显然后者磁盘扫描的次数少很多,因此是更优的选择。因此对于 MySQL 的关联查询,如果被驱动表的关联字段没索引,会使用 BNL 算法。
2.2 优化关联查询
关联字段添加索引
通过上面的内容,我们知道了 BNL、NLJ的原理,因此让 BNL变成 NLJ ,可以提高 join 的效率。我们来看下面的例子
我们构造出两个算法对应的例子:
Block Nested-Loop Join 的例子:
Index Nested-Loop Join 的例子:
对比一下两条 SQL 的执行计划: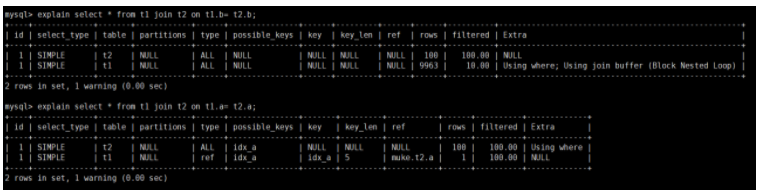
小表做驱动表
前面说到,Index Nested-Loop Join 算法会读取驱动表的所有数据,首先扫描的行数是驱动表的总行数(假设为 n),然后遍历这 n 行数据中关联字段的值,根据驱动表中关联字段的值索引扫描被驱动表中的对应行,这里又会扫描 n 行,因此整个过程扫描了 2n 行。当使用 Index Nested-Loop Join 算法时,扫描行数跟驱动表的数据量成正比。所以在写 SQL 时,如果确定被关联字段有索引的情况下,建议用小表做驱动表。
我们来看下以 t2 为驱动表的 SQL:
这里使用 straight_join 可以固定连接方式,让前面的表为驱动表。
再看下以 t1 为驱动表的 SQL:
我们对比下两条 SQL 的执行计划:

明显前者扫描的行数少(注意关注 explain 结果的 rows 列),所以建议小表驱动大表。















 75
75











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









