







操作平台:Rstudio、mac
学习R语言的时候,查询各种资料发现,R语言相对来说能查到的东西很零散,所以萌发想自己整理相应操作的想法。
读取文件
首先是读取一个.xlsx文件。其实R语言读取文件的方式很多,这里只示例xlsx文件,其他如csv文件等等,都有相应的函数。只需要更改函数后缀就好了,使用方式大概如下定义。

如果有读取文件要求的数据格式,可以通过class(data)的方式,来查看该变量的数据格式。(之前也是各种查询,因为我需要dataframe数据格式。发现明明就是直接一个函数的问题,偏偏一群网上的讨论,让我心累)(dataframe格式我就不在此介绍了)注意:调用类似函数,需要先安装对应的包,以及加载。
那么如何查看到底有哪些字段名称和字段个数呢(列向量):

文件过滤切片
对于任意一列数据的访问,此处,首先要确定的是对于行号,0是不存在元素的,代表的是名称。在R中,对于某个列进行访问的方式,可以直接通过data$x[index];data为所储存的dataframe数据,x为某列向量的字段名,index为索引值,也就是行号(1——n)
我的作业要求是剔除一些不正常的数据
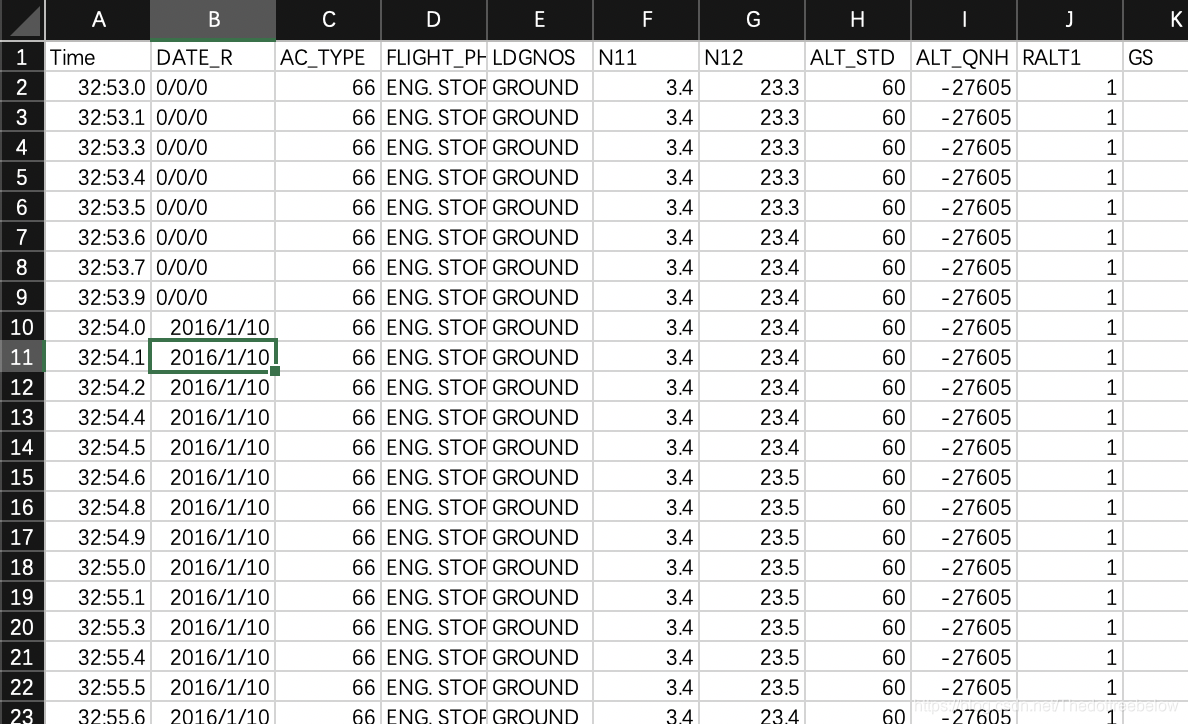
如第二列,日期不可能为0/0/0;
剔除这些行,我采用的是filter函数,调用的是上面加载示例的dplyr包
filter(data,xx) data自然是dataframe数据框,那么xx就是相应的检索语言。其中有两种方式:
1.直接写成DATE_R!=data$DATE_R[1]的格式,后者可以直接复制粘贴数据里的值(但注意好是否为字符串)。
2.老老实实data$DATE_R!=data$DATE_R[1],为什么会考虑这个情况,因为有的列如果重复出现,用这个方式更加保险(R语言会变成x…ncol,同名变量,跟着列号)。
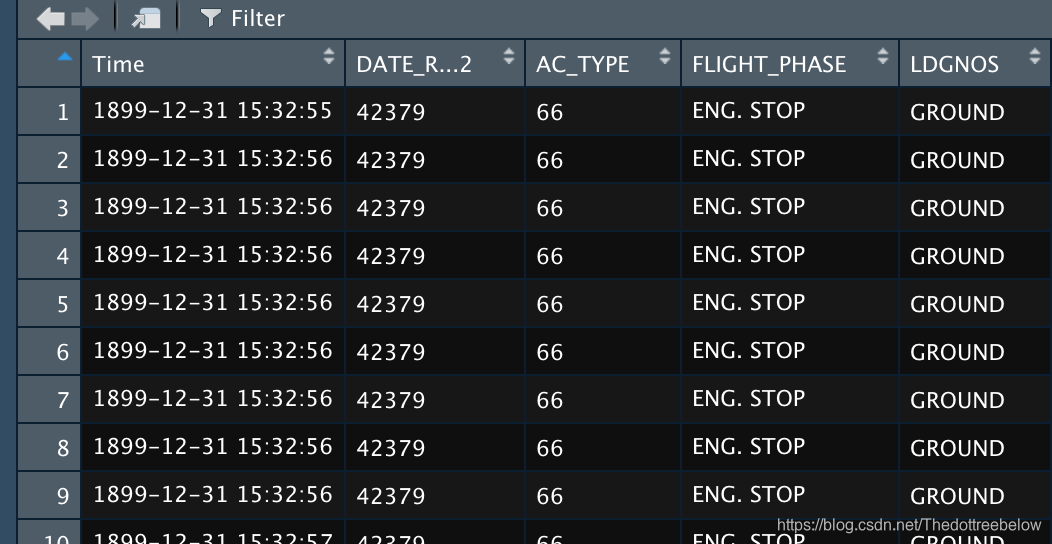
代码示例:data1=filter(data,data$DATE_R!=data$DATE_R[1])根据DATE_R列的情况作为参考,提前所有满足条件的行数(此处是Rstudio里面的情况,所以时间显示不一样):
那么对于一组数据,里面有很多NA(也可以理解为空)的元素,也要把这些行给剔除
data1=na.omit(data1)
通过上面的方式,可以直接实现,获取剔除完的结果。
保存文件
和读取文件类似`
write_csv(data2,'filename.csv')
后缀csv还是xlsx看自己需求,data2为dataframe数据框,后面则是文件名和路径,这里的写法是直接保存在现有的工作路径,也可以改成具体的比如D盘的表面。
最后,如果觉得我的文章确实有帮助,可以在下面留言点赞,其实R是刚刚学,其他语言还是比较顺手的,而且mac用的很多。确实比较啰嗦,如果没人愿意怎么看,可能就更新的少一点啦。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









