






利用多视角几何学对三维人类姿势进行自我监督学习
摘要
训练准确的三维人体姿态估计器需要大量的三维真实数据,而这些数据的收集成本很高。由于缺乏3D数据,各种弱监督或自监督的姿势估计方法已经被提出。然而,这些方法,除了二维真实姿势外,还需要各种形式的额外监督(例如,未配对的三维真实数据,一个小的标签子集)或多视图设置中的相机参数。为了解决这些问题,我们提出了EpipolarPose,一种用于三维人体姿势估计的自我监督学习方法,它不需要任何三维地面真实数据或相机外因。在训练过程中,EpipolarPose从多视角图像中估计出二维姿势,然后,利用epipolar几何学来获得三维姿势和摄像机几何学,随后用于训练三维姿势估计器。我们在标准基准数据集(即Human3.6M和MPI-INF-3DHP)上证明了我们的方法的有效性,我们在弱/自监督方法中创造了新的一流水平。此外,我们还提出了一个新的性能指标–姿势结构得分(PSS),它是一个尺度不变、结构感知的指标,用于评估一个姿势相对于其地面真相的结构可信度。
1. 简介
人类在野外的姿态估计是计算机视觉中的一个挑战性问题。虽然有大规模的数据集[2, 20]用于二维(2D)姿势估计,但三维数据集[15, 23]要么仅限于实验室环境,要么规模和多样性有限。由于在野外收集三维人体姿态注释的成本很高,而且三维数据集有限,因此研究人员采用了弱监督或自监督的方法,目的是在现有的二维姿态数据集之上获得监督。为此,已经开发了各种方法。这些方法,除了地面真实的二维姿态外,还需要各种形式的额外监督(如未配对的三维地面真实数据[41],一个小的标签子集[31])或多视角环境下的(外在)相机参数[30]。据我们所知,目前只有一种方法[9]可以通过只使用二维地面真实数据来产生三维姿态估计器。在本文中,我们提出了另一种这样的方法。
我们的方法,“EpiloparPose”,使用二维姿势估计和表极几何来获得三维姿势,这些姿势随后被用来训练三维姿势估计器。EpipolarPose可以与任意数量的摄像机一起工作(必须至少是2台),它不需要任何三维监督或外在的摄像机参数,但是,如果提供的话,它可以利用它们。
在Human3.6M[15]和MPI-INF-3DHP[23]数据集上,我们为弱/自我监督方法的三维姿态估计设定了新的最先进水平。
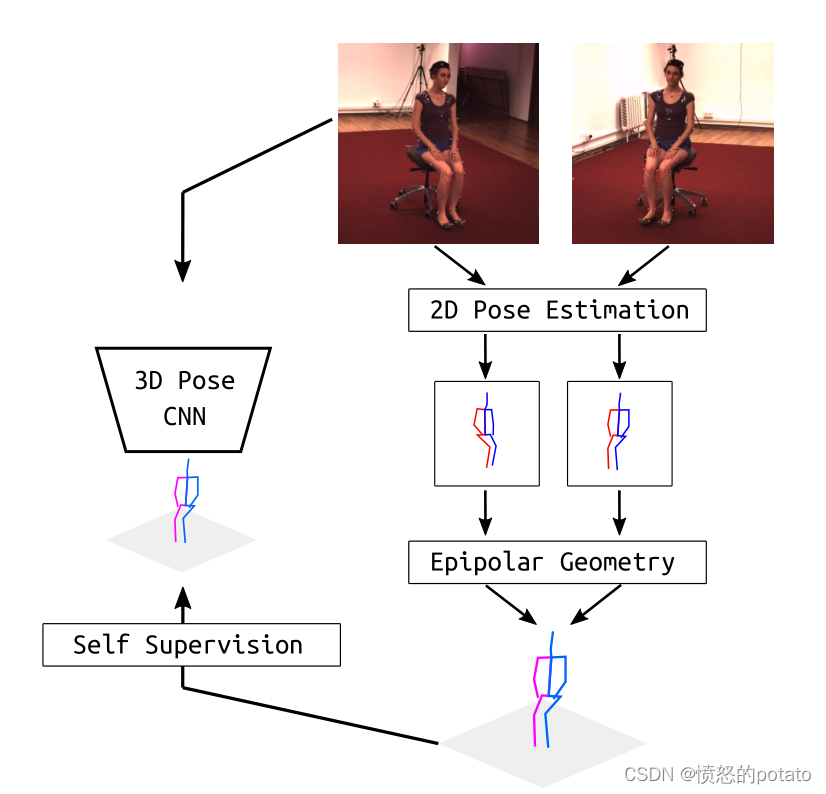
图1. EpipolarPose使用二维姿势估计和表极几何来获得三维姿势,随后用于训练三维姿势估计器。
人类的姿势估计允许后续更高层次的推理,例如在自主系统(汽车、工业机器人)和活动识别中。在这类任务中,姿势的结构性错误可能比传统评估指标(如MPJPE(每个关节位置的平均误差)和PCK(正确关键点的百分比))所测量的定位错误更为重要。这些指标独立地处理每个关节,因此不能将整个姿势作为一个结构进行评估。图4显示,相对于参考姿势,结构上非常不同的姿势产生相同的MPJPE。为了解决这个问题,我们提出了一个新的性能指标,叫做姿势结构得分(PSS),它对姿势的结构错误很敏感。PSS计算出一个尺度不变的性能分数,能够对一个姿势的结构合理性与它的地面真实性进行评分。请注意,PSS不是一个损失函数,它是一个性能指标,可以与MPJPE和PCK一起使用,以说明姿势估计器的结构错误。
为了计算PSS,我们首先需要对地面实况姿势的自然分布进行建模。为此,我们使用一种无监督的聚类方法。首先,我们找出最接近p和q的聚类中心,如果它们都最接近(即分配到)同一个聚类中心,那么p的姿势结构得分(PSS)就被称为1,否则就是0。
贡献
- 我们提出了EpipolarPose,一种能够从单幅图像中预测3D人体姿势的方法。对于训练,EpipolarPose不需要任何3D监督或相机外在因素。它通过利用表极几何和二维地面真实姿势来创建自己的三维监督。
- 我们在弱/自监督的三维人体姿势估计方法中创造了新的先进技术。
- 我们提出了姿势结构得分(PSS),这是一个用于三维人体姿势估计的新的性能指标,以更好地捕捉结构误差。
2. 相关工作
我们的方法,EpipolarPose,在推理过程中是一个单视图方法;在训练过程中是一个多视图、自我监督的方法。在讨论文献中的这类方法之前,我们首先简要回顾一下完全的单视图(在训练和推理过程中)和完全的多视图方法,以确保完整性。
单视角方法 在最近的许多工作中,卷积神经网络(CNN)被用来直接从图像中估计三维关节的坐标[38, 39, 40, 35, 23]。Li和Chan[19]率先表明,深度神经网络可以在从单一图像进行三维人体姿势估计时达到合理的精度。他们使用了两个深度回归网络和身体部位检测。Tekin等人[38]表明,将用于监督学习的传统CNN与用于结构学习的自动编码器相结合可以产生良好的效果。与常见的回归实践相反,Pavlakos等人[29]是第一个将三维人体姿势估计视为体素空间中的三维关键点定位问题。最近,Sun等人[36]提出的 "整体姿势回归 "将体积热图与软argmax激活相结合,并获得了最先进的结果。
此外,还有一些两阶段的方法,将3D姿势推理任务分解为两个独立的阶段:估计2D姿势,并将其提升到3D空间[8, 24, 22, 11, 46, 8, 40, 23]。这一类中的大多数最新方法使用最先进的二维姿势估计器[7, 43, 25, 17]来获得图像平面上的关节位置。Martinez等人[22]使用了一个简单的深度神经网络,该网络可以根据最先进的二维姿态估计器计算出的二维姿态来估计三维姿态。Pavlakos等人[28]提出了使用关节间的序数深度关系来绕过对完全三维监督的需要。
这类方法需要全三维监督或除全三维监督外的额外监督(如序数深度)。
多视角方法 这一类的方法在测试和训练中都需要多视角输入。早期的工作[1, 5, 6, 3, 4]使用从校准的相机中获得的二维姿势估计,通过三角测量或图像结构模型产生三维姿势。最近,许多研究人员[10]使用深度神经网络对多视图输入进行建模,并进行全面的三维监督。
弱/自我监督方法 由于缺乏三维注释,许多人探索了基于弱和自我监督的人体姿势估计方法[9, 31, 41, 30]。Pavlakos等人[30]使用一个图像结构模型,从多视角图像的关键点热图中获得全局姿势配置。然而,他们的方法需要完整的相机校准和产生二维热图的关键点检测器。
Rhodin等人[31]利用多视角一致性约束来监督网络。他们需要少量的三维真实数据,以避免姿势塌陷于单一位置的退化解决方案。因此,缺乏野外三维真实数据是该方法的一个限制因素[31]。
最近引入的深度逆向图形网络[18, 44]已被应用于人体姿势估计问题[41, 9]。Tung等人[41]训练了一个生成式对抗网络,该网络有一个三维姿势生成器,该生成器是用预测的三维姿势和输入的二维关节之间的重建损失来训练的,还有一个判别器,该判别器是用来区分预测的三维姿势和一组地面真实三维姿势。在这项工作之后,Drover等人[9]通过修改判别器来识别合理的二维投影,从而消除了对三维地面实况的需求。
据我们所知,EpipolarPose和Drover等人的方法是唯一不需要任何三维监督或相机外信息的方法。虽然他们的方法没有利用图像特征,但EpipolarPose同时利用了图像特征和表极几何学,并产生了更准确的结果(比Drover等人的方法少4.3毫米的误差)。
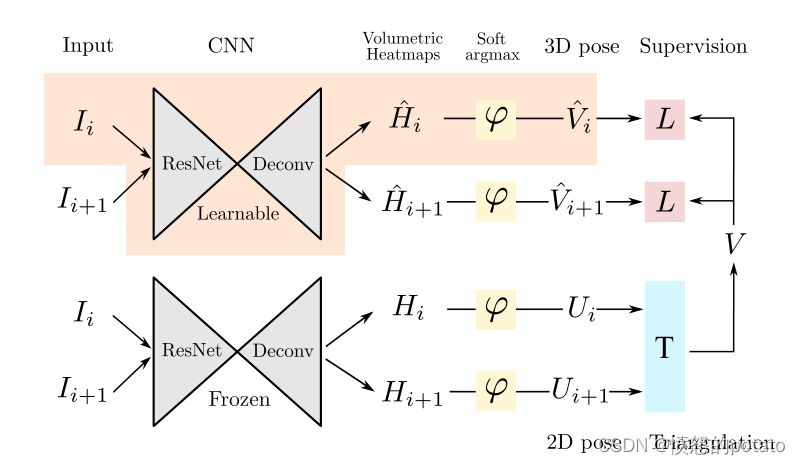
图2. 训练期间EpipolarPose的整体架构。上部分支中的橙色背景部分表示推理管道。在训练过程中,EpipolarPose是多视角的:一对由两个连续相机同时拍摄的图像(Ii,Ii+1)被送入CNN姿势估计器。它也是自监督的:下层分支使用三角测量(即外极几何)产生的三维姿势(V)被用作上层分支的CNN的训练信号。在推理过程中(橙色背景部分),EpipolarPose是一种单眼方法:它将单一图像(Ii)作为输入并估计相应的三维姿势(Vˆi)。(j:软argmax函数,T:三角测量,L:平滑L1损失)。
3. 模型和方法
图2给出了我们提出的方法EpipolarPose的整体训练流水线。橙色背景部分显示了推理管道。对于EpipolarPose的训练,假设设置如下。有n个摄像头(n≥2必须成立),同时拍摄场景中的人的照片。摄像机被赋予从1到n的ID号码,其中连续的摄像机彼此接近(即它们有小的基线)。摄像机产生图像I1,I2,…In。然后,一组连续的图像对,{(Ii,Ii+1)|i=1,2,…,n-1},构成训练实例。
3.1. 训练
在EpipolarPose的训练管道中(图2),有两个分支,每个分支都从相同的姿势估计网络开始(一个ResNet然后是一个去卷积网络[36])。这些网络是在MPII人类姿势数据集(MPII)上预训练的[2]。在训练过程中,只有上层分支的姿势估计网络被训练,其他的网络被保持冻结。
EpipolarPose可以使用2个以上的相机进行训练,但为了简单起见,这里我们将描述n=2的训练管道。对于n = 2,每个训练实例只包含一个图像对。图像Ii和Ii+1被送入三维(上)分支和二维(下)分支姿势估计网络,分别得到体积热图H,Hˆ∈Rw×h×d,其中w,h是去卷积后的空间大小,d是定义为超参数的深度分辨率。在应用软的argmax激活函数j(-)后,我们得到三维姿势Vˆ∈RJ×3和二维姿势U∈RJ×2输出,其中J是身体关节的数量。从一个给定的体积热图中,我们可以得到3D姿势(通过对所有3个维度应用softargmax)和2D姿势(通过只对x,y应用softargmax)。
作为二维姿态分支的输出,我们希望获得全局坐标框架中的三维人体姿态V。让第i幅图像中第j个关节的二维坐标为 Ui,j = [xi,j,yi,j],其三维坐标为[Xj,Yj,Zj],我们可以假设一个针孔图像投影模型来描述它们之间的关系,其中wi,j是第i台摄像机图像中第j个关节相对于摄像机参考框架的深度,K编码摄像机的内在参数(如焦距fx和fy,主点cx和xy),R和T分别是摄像机的旋转和翻译的外在参数。为了简单起见,我们省略了相机的失真。
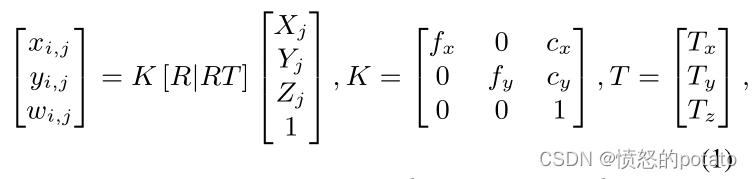
当摄像机的外在参数不可用时,通常是在动态捕捉环境中,我们可以使用身体关节作为校准目标。我们假设第一台摄像机为坐标系的中心,这意味着第一台摄像机的R为身份。对于Ui和Ui+1中的相应关节,在图像平面上,我们使用RANSAC算法找到满足Ui,jFUi+1,j=0的基本矩阵,对于∀j。从F中,我们通过E = KTFK计算出基本矩阵E。通过用SVD分解E,我们得到R的4个可能的解决方案。我们通过做cheirality检查验证可能的姿势假设来决定正确的方案。cheirality检查基本上意味着三角形的三维点应该有正的深度[26]。在训练过程中,我们省略了比例,因为我们的模型使用归一化的姿势作为基础真实。
最后,为了获得相应的同步二维图像的三维姿态V,我们利用三角法(即表极几何),具体如下。对于(Ii,Ii+1)中所有在任一图像中没有被遮挡的关节,使用多项式三角法[12]对一个三维点[Xj,Yj,Zj]进行三角计算。对于包括2个以上摄像机的设置,我们计算矢量中位数以找到中位数的三维位置。
为了计算上层(三维)分支预测的相机帧Vˆ中的三维姿势之间的损失,我们将V投射到相应的相机空间,然后最小化smoothL1(V-Vˆ)来训练三维分支,其中
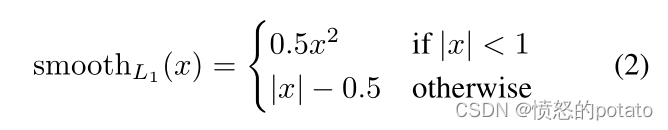
为什么我们需要一个冻结的二维姿态估计器?在EpipolarPose的训练管道中,有两个分支,每个分支都从一个姿势估计器开始。上层分支的估计器是可训练的,而下层分支的另一个估计器是冻结的。下层分支的估计器的工作是产生2D姿势。人们可能会质疑冻结估计器的必要性,因为我们也可以从可训练的上部分支中获得二维姿势。当我们试图这样做的时候,我们的方法产生了退化的解决方案,所有的关键点都塌陷在一个单一的位置上。事实上,其他多视图方法也面临同样的问题[31, 37]。Rhodin等人[31]通过使用一组小的地面真实例子解决了这个问题,然而,在大多数野外环境中,获得这样的地面真实可能是不可行的。最近提出的另一个解决方案[37]是最小化估计的相对旋转Rˆ(通过两组关键点的Procrustes对齐计算)和地面真相R之间的角度距离。为了克服这些缺点,我们只在训练时利用一个冻结的二维姿势检测器。
3.2. 推理
推理涉及图2中的橙色背景部分。输入只是一个单一的图像,输出是通过软argmax激活,j(-),在三维体积热图Hˆi上获得的估计三维姿势Vˆ。
3.3. 精细化,一个可选的后期训练
在文献中,有几种技术[22, 11, 39]可以将检测到的二维关键点提升为三维关节。这些方法能够学习广义的二维→三维映射,这些映射可以通过模拟随机摄像机投影从运动捕捉(MoCap)数据中获得。将细化单元(RU)整合到我们的自监督模型中可以进一步提高姿势估计的准确性。通过这种方式,人们可以在他/她自己的数据上训练EpipolarPose,这些数据由没有任何标签的多视角镜头组成,并与RU整合以进一步提高结果。为了做到这一点,我们修改了RU的输入层,以接受来自EpipolarPose的有噪声的三维检测,并使其学习一种细化策略。(见图3)
RU的整体结构受到了[22, 11]的启发。它有2个计算块,其中有某些线性层,然后是批量归一化[14]、泄漏ReLU[21]激活和剔除层,以将三维噪声输入映射到更可靠的三维姿势预测。为了促进各层之间的信息流动,我们增加了剩余连接[13],并应用中间损失来加快中间层对监督的访问。
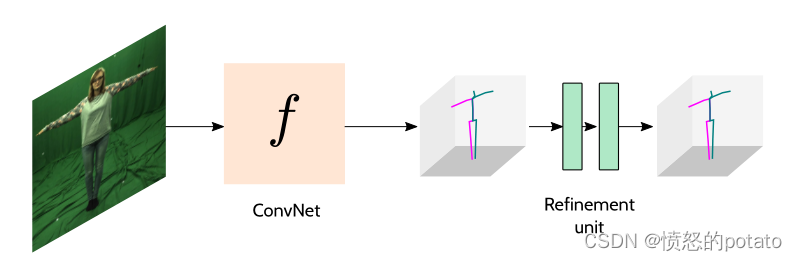
图3. 整体推理管道,其中的细化单元是一个可选的阶段,用于细化用自我监督训练的模型的预测结果。f函数表示EpipolarPose的推理函数(图2中橙色背景部分)。
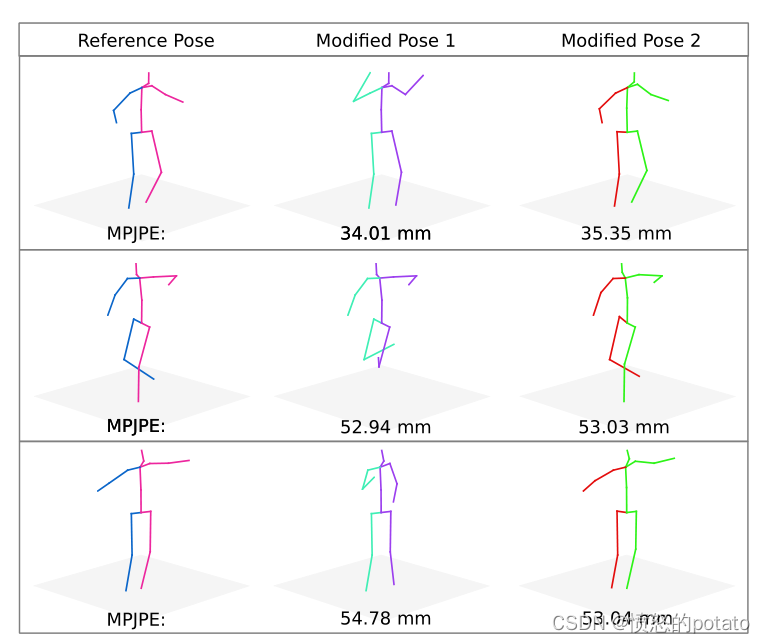
图4. 左图:来自Human3.6M数据集的参考姿势。中间:手动修改的姿势,以获得与右边的姿势相似的MPJPE,但结构与参考姿势不同。右图:通过向每个身体关节添加随机高斯噪声获得的姿势
3.4. 姿势结构得分
正如我们在第1节中所讨论的,传统的基于距离的评估指标(如MPJPE,PCK)独立地处理每个关节,因此,不能将整个姿势作为一个结构来评估。在图4中,我们展示了一些例子,这些姿势具有相同的MPJPE,但在结构上与参考姿势非常不同。
我们提出了一个新的性能指标,叫做姿势结构得分(PSS),它对姿势中的结构错误很敏感。PSS计算出一个尺度不变的性能分数,能够评估一个姿势相对于其地面真实的结构合理性。请注意,PSS不是一个损失函数,它是一个性能分数,可以与MPJPE和PCK一起使用,以说明姿势估计器的结构错误。PSS是一个关于偏离地面真实姿势的指标,它有可能在需要有语义的姿势的后续任务中导致错误的推断,例如动作识别、人与机器人的交互。
如何计算PSS?PSS的计算需要一个地面真实姿势的参考分布。给定一个 由n个姿势组成的地面真实集 qi,i∈{1,–,n},我们将每个姿势向量归一化为qˆi = ||qqii||。然后,我们用kmeans聚类法计算k个聚类中心μj,j∈{1,— ,k}。然后,为了计算预测姿势p对其地面真实姿势q的PSS,我们使用
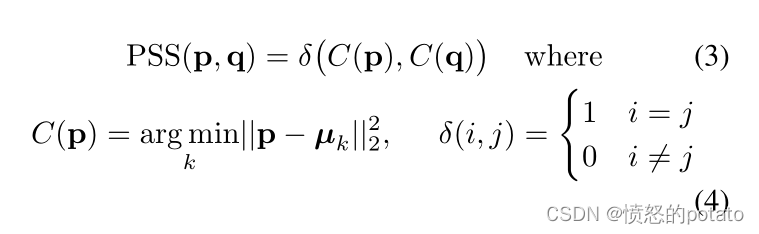
一组姿势的mPSS,即平均PSS,是在公式(3)中计算的它们各自分数的平均值。图5显示了姿势和聚类的t-SNE[42]图。图6描述了代表典型姿势的集群中心。
在我们的实验中,我们选择了50和100个姿势聚类的数量。我们用mPSS@50和mPSS@100表示相应的PSS结果。请注意,mPSS给出的是结构正确的姿势的百分比,因此分数越高越好。为了测试我们聚类的稳定性,我们在随机初始化的情况下各运行了100次k-means。然后,对于每一对运行,我们在聚类之间建立成对的对应关系。对于每个对应关系,我们计算了交集大于联合(IOU)。所有配对和对应关系的平均IOU变成了0.78。此外,当我们使用不同的kmeans输出作为参考时,不同姿势估计模型的mPSS相差±0.1%。这些分析证明了PSS的稳定性。

图5. 聚类后人类姿势的t-SNE图。这里我们选择k = 10作为可视化的目的。每种颜色代表一个集群。

图6. 代表Human3.6M(k=50)中典型姿势的聚类中心。
实施细节 我们对二维和三维分支使用Integral Pose[36]架构,并使用ResNet-50[13]后端。输入图像和输出热图的尺寸分别为256×256和J×64×64,其中J是关节的数量。我们在MPII[2]上训练后初始化实验中使用的所有模型。
在训练过程中,我们使用大小为32的迷你批次,每个批次包含Ii,Ii+1个图像对。如果有两个以上的摄像机,我们在一个小批中包括所有摄像机的视图。我们使用Adam优化器[16]对网络进行140次训练,学习率为10-3,在第90和120步乘以0.1。训练数据通过±30◦的随机旋转来增加,并以0.8和1.2之间的系数进行缩放。此外,我们利用合成闭塞[34]来使网络对闭塞的关节具有鲁棒性。为了简单起见,我们运行一次二维分支以产生三角形的三维目标,并使用缓存的标签训练三维分支。我们使用PyTorch实现了整个流水线[27].
4、实验结果
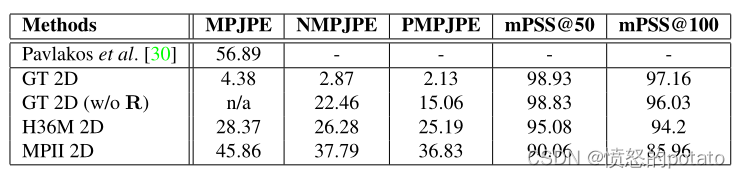
H36M上的三角测量结果。不同的二维关键点源对三角测量性能的影响。GT 2D表示使用了地面真实的2D标签。H36M 2D和MPII 2D表示在这些数据集上训练的姿势估计模型。
表1 H36M的triangulation的结果
GT表示用H36M中的2D标签,GT 2D (w/o R)表示不用camera geometry(旋转矩阵R) H36M 2D 和MPII 2D表示在这些数据集上训练的姿态估计模型。我们可以看到,用GT 2D的效果最好,其次是H36M 2D,而在MPII数据集上训练的2D keypoints 检测器有轻微的效果下降。作者认为是因为H36M中的数据是用marker得到的,更准确(H36M中数据集中的试验者在身上贴有小亮片(传感器))。而MPII中人的关键点是由人工标记的,一些关键点定位不准。
与最新技术的比较
在H36M上和其他SOTA比较的结果如下表所示:
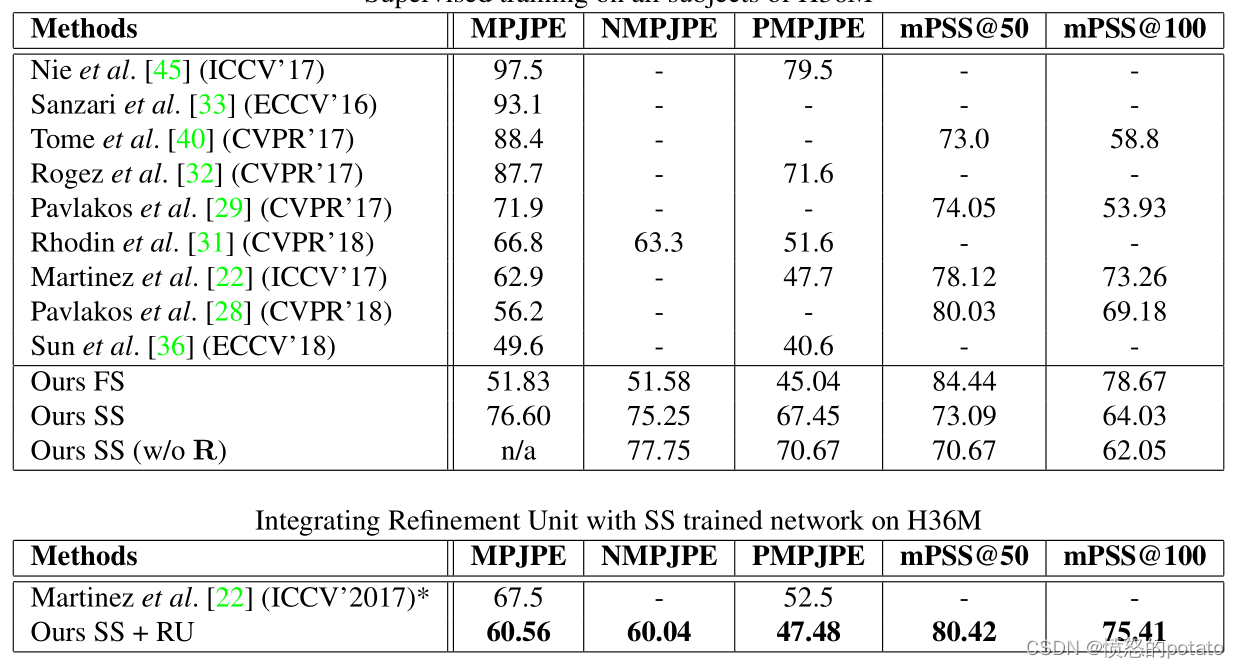
下表展示的是文献中一些关于weakly or self supervised方法在Human 3.6M上的结果。
可以观察到GT2D训练和MPII预训练之间存在很大差异(76.60 - 55.08 = 21mm)。这个差距表明2D关键点的估计质量对于3D pose estimation取得更好的性能至关重要。
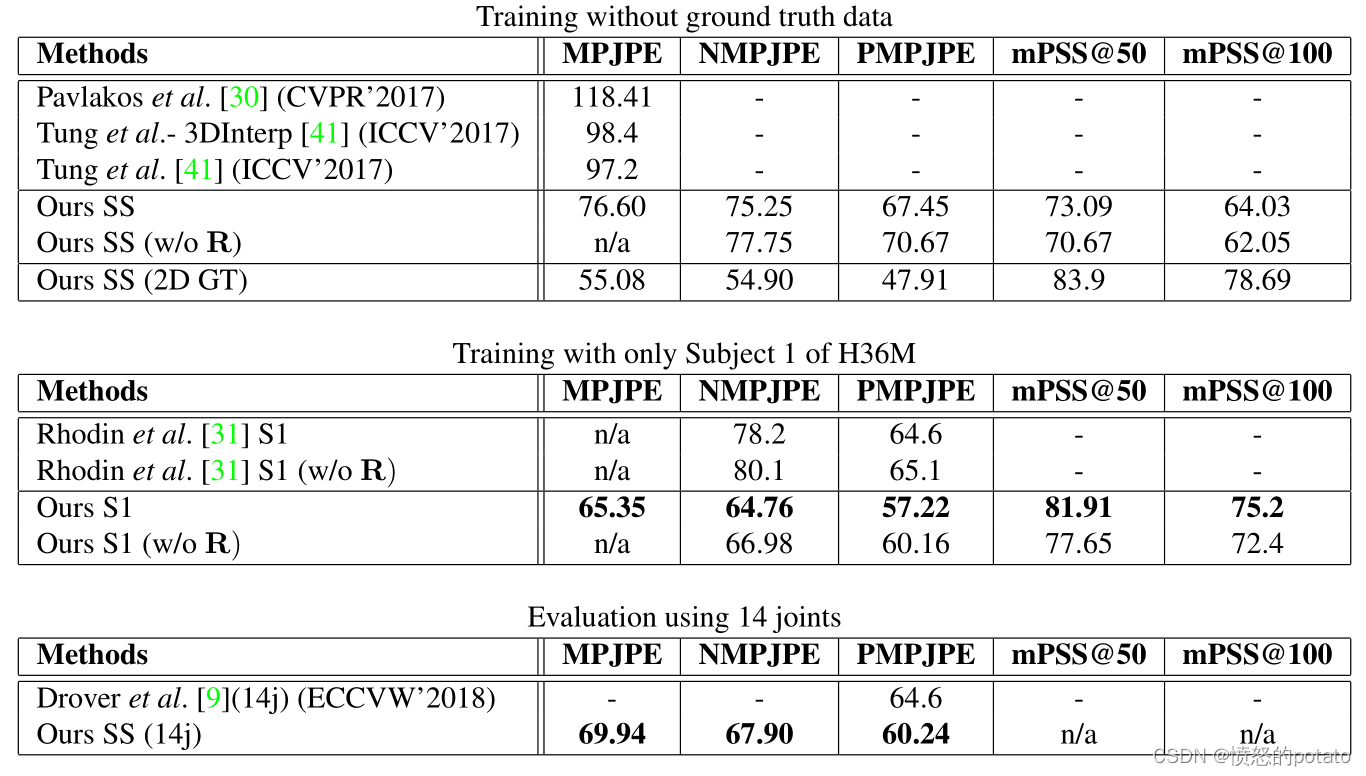
底下的两个表展示的是和参考文献31与9更公平和细致的比较。
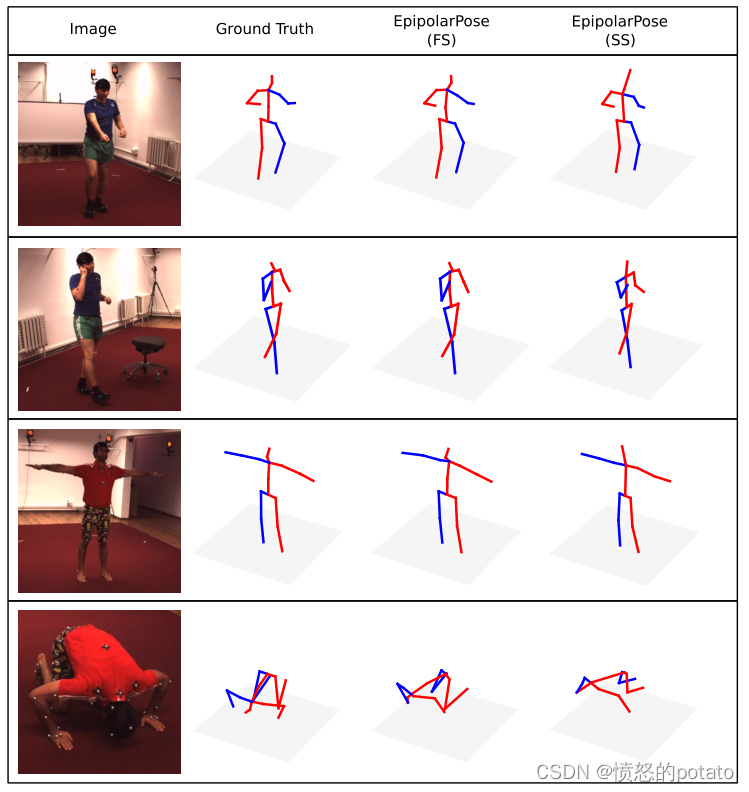
定性结果展示
论文记录
EP在推理过程中单视角,训练时多视角、自监督
单视角:
【19】深度回归网络和身体部位检测 进行了从单图像中获得合理准确性的姿势估计
【38】监督学习和自动编码器用于结构学习
【29】三维人体姿势估计视为 3D关节点定位问题
【36】积分姿态回归和 soft argmax相结合
多视角方法:
缺乏3D注释,探索弱监督和自监督的人体姿势估计方法。
【31】多视图一致性来约束去监督网络
【9】【41】深度逆向网络引入














 4722
4722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









