







全文翻译如下:
摘要
人类的适应性在很大程度上依赖于学习和融合来自监督和非监督任务的知识:父母指出一些重要的概念,然后孩子自己填补空白。这一点特别有效,因为监督学习永远无法穷举,因此自主学习可以发现有助于泛化的不变性和规律性。在本文中,我们提出将类似的方法应用于跨领域的物体识别问题:我们的模型以监督的方式学习语义标签,并通过从相同图像上的自监督信号中学习来拓宽对数据的理解。这个次要任务帮助网络关注物体形状,学习空间方向和部分相关性等概念,同时充当多个视觉域上分类任务的正则化器。大量的实验证实了我们的直觉,并表明我们的多任务方法结合了监督和自监督知识,在更复杂的领域泛化和适应解决方案方面提供了有竞争力的结果。同时也证明了其在新颖且具有挑战性的预测和部分域适应场景中的潜力。
1 INTRODUCTION
多年来,心理学家和学习研究对智力的定义有多种。尽管存在差异,但它们都表明了在广泛的条件下适应和实现目标的能力,是关键的组成部分[ 1 ]。人工智能继承了这些定义,最近的研究证明了知识转移和领域泛化的重要性[ 18 ]。事实上,在许多实际应用中,训练(即,源)和测试(即,目标)数据的潜在分布不可避免地存在差异,这就要求有稳健且适应性强的解决方案。在处理视觉域时,目前的策略大多基于监督学习。这些过程搜索能够捕获基本数据知识的语义空间,而不考虑输入图像的具体外观:一些将图像风格与共享对象内容解耦[ 7 ],另一些生成新的样本[ 75 ],或者施加对抗条件以减少特征差异[ 46 ] [ 48 ]。类似于获得通用特征嵌入的目的,自监督学习追求一个替代的研究方向,即捕捉视觉不变性和规律性,解决不需要数据标注的任务,如图像方向识别[ 30 ]或图像着色[ 84 ]。未标注的数据在很大程度上是可用的,其本质也不容易产生(无标注偏倚问题)偏差,因此它们似乎是提供独立于特定领域风格的视觉信息的完美候选者。然而,它们的潜力还没有被充分挖掘:现有的自监督方法通常具有定制的体系结构,需要专门的微调策略来重新设计所获得的知识[ 60 ]。而且,它们主要应用在现实世界的照片上,没有考虑带有绘画或素描图像的跨领域场景。
这种从图像中学习内在规律(自监督知识)和跨领域鲁棒分类(监督知识)之间的明显分离,与生物系统,特别是人类视觉系统的视觉学习策略形成鲜明对比。事实上,大量的研究强调婴儿和学步儿同时学习对物体的分类和关于规律的知识[ 6 ]。例如,流行的婴幼儿玩具通过将它们拟合为形状排序器来识别不同的类别;动物或交通工具的Jigsaw拼图鼓励学习物体部件的空间关系在12 - 18个月之间同样广泛存在。这种联合学习当然是人类在幼年时期就能达到复杂的视觉泛化能力的关键因素[ 26 ]。
受此启发,我们的原始论文[ 12 ]首次提出了一种多任务方法,该方法通过利用监督数据来学习如何识别物体,以及如何通过利用图像部分(图。1和2)的空间co - location的内在自监督信息来泛化到新的领域。具体来说,我们提出从其洗牌部分恢复原始图像,重新利用流行的解决拼图游戏。与以往处理从单独图像块中提取特征的方法不同[ 58 ],[ 60 ],我们在图像层次上移动了块的重新组装,并将拼图任务形式化为与原始图像相同维度的重组图像上的分类问题。通过这种方式,对象识别和补丁重排序可以共享相同的网络主干,我们可以无缝地利用任何卷积学习结构和几个预训练模型,而不需要特定的体系结构变化。
在这里,我们扩展了我们之前的工作,为跨领域的自监督学习提供了更广泛的概述。( 1 )我们将旋转识别和拼图作为自监督任务,展示了它们在多任务模型和监督学习领域泛化中的作用;( 2 )我们深入研究了多任务方法的细节,进行了广泛的消融分析,并将成功和失败的案例可视化;( 3 )我们考虑了单源和多源域适应实验,并对最新的方法进行了深入分析;( 4 )我们讨论了我们的多任务模型在具有挑战性的预测和部分领域适应场景中的效果也得到了扩展[ 8 ]。
2 RELATED WORK
自监督学习。自监督学习是一种从大规模无标签数据中学习视觉特征的范式[ 40 ]。它的第一步是一个利用固有数据属性自动生成替代标签的借口任务:部分关于图像的现有知识被手动移除(例如,颜色、朝向、斑块序),任务包括恢复它。研究表明,以这种方式训练的网络的第一层可以捕获有用的语义知识[ 3 ]。学习过程的第二步是将这些初始层的自监督学习模型迁移到一个有监督的下游任务(例如,分类、检测),而网络的结束部分则是新训练的。
可能的借口任务可以分为三个主要组。一类只依赖于原始的视觉线索,通过几何变换(例如平移、缩放、旋转 , )、聚类[ 15 ]、修复[ 62 ]和彩色化[ 84 ]处理整幅图像,或者将图像块集中在它们的等变性、(学会计数)和相对位置(解拼图 , )上。第二组使用真实或合成的外部感官信息:这种解决方案经常应用于多线索(视觉到听觉 , RGB到深度[ 63 ])和机器人数据[ 37 ] [ 42 ]。最后,第三组依赖于视频和时间维度引入的规律[ 70 ],[ 77 ]。最近的自监督学习研究集中在提出新的前文本任务或将其中的几个任务组合在一起,然后比较它们对下游任务的初始化性能,如在标准迁移学习中使用监督模型[ 23 ],[ 29 ],[ 38 ],[ 63 ]。
我们的工作探索了一个新的研究方向:我们在多任务框架中结合监督和自监督知识,研究其对领域泛化和适应的影响。
领域泛化与适应。目前已经开发了几种算法来应对域偏移,主要有两种不同的设置:域泛化( DG )和域自适应( DA )。在DG中,目标在训练时是未知的:学习过程通常可以利用多个标记源来定义一个对任何新的,以前看不到的领域鲁棒的模型[ 56 ]。在DA中,学习过程可以访问有标签的源数据和无标签的目标数据,因此目的是泛化到给定的特定目标集[ 18 ]。在多源DA中,源域标签可能是未知的[ 13 ],[ 34 ],[ 52 ],而对于大多数DG方法,源域标签仍然是需要利用的重要信息。
DG和DA的解主要有三类。特征级策略主要通过最小化不同领域的偏移度量来学习领域不变的数据表示[ 5 ],[ 49 ],[ 50 ],[ 71 ]。域偏移也可以通过训练域分类器和反向优化来减少,以引导特征走向最大域混淆[ 27 ] [ 73 ]。这种对抗方法有几种变体,其中一些变体还利用类特定的领域识别模块[ 48 ] [ 67 ]。度量学习[ 55 ]和深度自编码器[ 7 ] [ 28 ] [ 46 ]也被用于搜索领域共享的嵌入空间。在DG中,这些方法利用了多个源的可用性和每个样本对域标签的访问。模型级的策略要么改变数据以ad - hoc情节的方式加载[ 45 ],要么修改传统的学习算法以搜索目标函数更鲁棒的极小值[ 43 ]。除了这些主要方法外,其他的解决方法还包括引入领域对齐层[ 13 ]、聚合层[ 22 ]、[ 45 ],或者使用低秩网络参数分解[ 20 ]、[ 44 ],以识别和忽略特定领域的签名。最后,数据级技术利用生成对抗网络( GANs )的变体来合成新的图像。事实上,产生类源目标图像或/和类目标源图像[ 35 ] [ 65 ]有助于减少域间隙。
最近的一些工作已经开始研究DA和DG之间的中间设置。在预测域自适应( Predictive Domain Adaptation,PrDA )中,一个有标记的源域和几个辅助的无标记域在训练时可用,同时还有描述它们之间关系的元数据[ 51 ] [ 82 ]。目标数据不可用,但它们的元数据被提供并用于直接从源组成适应的模型。
在DA和DG中,主要的假设是源和目标共享相同的标签集,很少有工作研究这个基本条件的例外[ 10 ],[ 68 ],[ 79 ]。特别地,在部分域适应( PDA )中,目标仅覆盖源类集的一个子集。在这种情况下,调整适应过程以使未共享标签的样本不会影响学习到的模型是很重要的。比较常用的方法是在标准DA方法的基础上增加重加权源样本策略[ 9 ],[ 10 ],[ 83 ]。备选方案利用两个独立的深度分类器及其在目标上的预测不一致性[ 54 ]或特征范数匹配[ 80 ]。
从本文的简要综述中可以看出,以往的文献并没有对DA或DG的自我监督进行研究。在这项工作中,我们提出了跨领域自监督学习的深入研究。
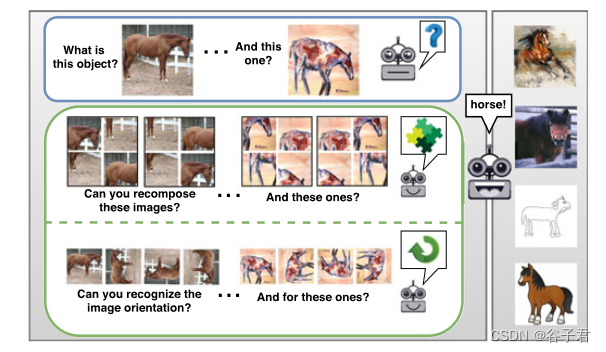
图1 .跨视觉域的物体识别是一项具有挑战性的任务,需要较高的泛化能力。自监督图像信号允许捕获自然的不变性和规律,可以帮助跨越大的风格差距。通过我们的多任务学习方法,我们共同学习分类对象和解决拼图或识别图像方向,表明这支持对新领域的泛化。
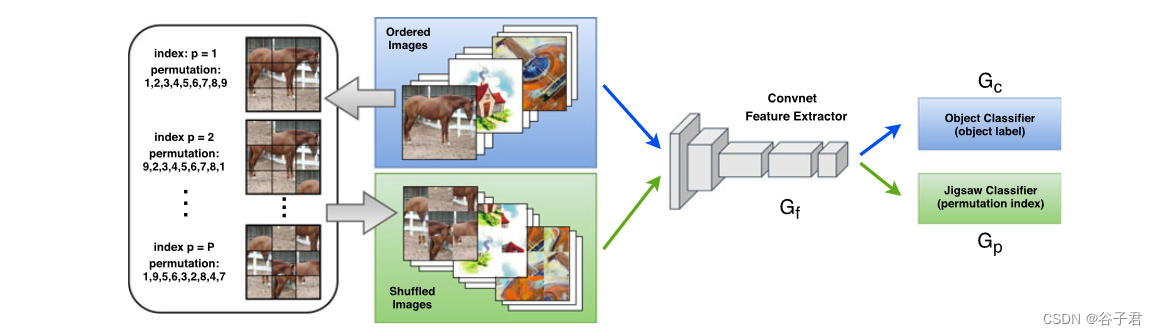
图2 .当使用拼图作为自监督任务时,所提出的多任务方法的说明。我们从多个域的图像开始,使用一个3 3网格将它们分解为9个块,然后随机地重新组合成与原始图像相同维度的图像。通过[ 58 ]中的最大汉明距离算法,我们定义了一组P片置换,并为每个置换分配了一个索引。原始的有序图像和混洗图像都被送入一个卷积网络,该网络被优化以满足两个目标:有序图像上的目标分类和混洗图像上的拼图分类(即排列索引识别)。当使用旋转识别作为自我监督时,类似的方案成立。分配给每个网络部分的名称参考第3节采用的符号。
3METHOD
我们在这里介绍了我们的跨领域多任务方法的技术符号,并在每个考虑的设置中指定目标。假设从一个或多个源分布中观测数据 { ( x i s , y i s ) } i = 1 n s \left\{\left(x_i^s, y_i^s\right)\right\}_{i=1}^{n^s} { (xis,yis)}i=1ns。其中 x i s x_i^s xis表示第i幅图像, y i s y_i^s yis表示对应的 ∣ Y s ∣ \left|\mathcal{Y}^s\right| ∣Ys∣维单热向量标签。从这些图像出发,我们总是可以应用不同的过程来生成自监督变体。一个简单的选择是采用旋转的方法,每个样品产生 { 0 ∘ , 9 0 ∘ , 18 0 ∘ , 27 0 ∘ } \left\{0^{\circ}, 90^{\circ}, 180^{\circ}, 270^{\circ}\right\} { 0∘,90∘,180∘,270∘}取向的拷贝。相关的自监督任务包括选择正确的图像旋转。一种更结构化的方案是将原始图像按照 3 × 3 \times 3× 3网格进行分解:从每个样本中产生9个正方形块,然后从它们的原始位置移动并重新定位,形成一组9 !混洗图像。这个任务让人想起拼图游戏,需要重新排列图块以恢复原始图像。对于所描述的两种情况, { ( z k s , p k s ) } k = 1 K s \left\{\left(z_k^s, \boldsymbol{p}_k^s\right)\right\}_{k=1}^{K^s} { (zks,pks)}k=1Ks为新获取的图像。在应用旋转时,独热向量标签 p p p的维数为4,而对于块混洗,我们根据[ 58 ]中基于汉明距离的算法选择了9个可能的置换中的一个子集 P P P。图像总数根据自监督任务的不同而变化: K s = 4 × n s K^s=4 \times n^s Ks=4×ns用于旋转, K s = P × n s K^s=P \times n^s Ks=P×ns用于块洗牌。无论选择哪种特定的自监督目标,我们都可以通过多分支结束网络实现的标准硬参数共享多任务模型将其与监督学习相结合[ 16 ]。一个输出分支将致力于利用源数据的标签进行监督任务,而另一个输出分支将解决自监督问题:旋转或拼图的排列识别(见图2)。辅助自监督目标有助于从数据中提取相关语义特征,最终对目标识别性能产生有利影响。由于自监督目标是标签不可知的,它可以在有监督和无监督域上运行,支持泛化和自适应。
3.1 领域泛化
对于我们的网络,我们用 G f G_f Gf表示卷积特征提取主干,参数为 θ f \theta_f θf。目标分类器 G c G_c Gc和自监督任务 G p G_p Gp的参数分别为 θ c \theta_c θc和 θ p \theta_p θp。总体上对网络进行训练,得到最优模型为:
arg min θ f , θ c , θ p 1 n s ∑ i = 1 n s L c ( G c ( G f ( x i s ) ) , y i s ) + α s 1 K s ∑ k = 1 K s L p ( G p ( G f ( z k s ) ) , p k s ) , \begin{array}{r} \arg \min _{\theta_f, \theta_c, \theta_p} \frac{1}{n^s} \sum_{i=1}^{n^s} \mathcal{L}_c\left(G_c\left(G_f\left(x_i^s\right)\right), \boldsymbol{y}_i^s\right) \\ +\alpha^s \frac{1}{K^s} \sum_{k=1}^{K^s} \mathcal{L}_p\left(G_p\left(G_f\left(z_k^s\right)\right), \boldsymbol{p}_k^s\right), \end{array} argminθf,θc,θpns1∑i=1nsLc(Gc(Gf(xis)),yis)+αsKs1∑k=1KsLp(G
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









