









[部分二]:https://blog.csdn.net/Thomson617/article/details/103961274
第七章.相机标定与3D重构
42.摄像头标定
在图像测量过程以及机器视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立相机成像的几何模型,这些几何模型参数就是相机参数。在大多数条件下这些参数必须通过实验与计算才能得到,这个求解参数(内参、外参、畸变参数)的过程就称之为相机标定(或摄像机标定)。无论是在图像测量或者机器视觉应用中,相机参数的标定都是非常关键的环节,其标定结果的精度及算法的稳定性直接影响相机工作产生结果的准确性。因此,做好相机标定是做好后续工作的前提,提高标定精度是科研工作的重点所在。
本节中的函数使用了所谓的针孔相机模型。在该模型中,利用透视变换将三维点投射到图像平面上,形成场景视图。
![]()
或者:
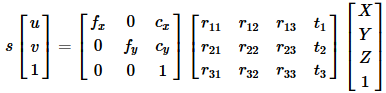
(X,Y,Z)是三维点在世界坐标空间中的坐标.
(u,v)为投影点的坐标,单位为像素.
A是一个相机矩阵,或者说是一个固有参数矩阵.
(cx,cy)是通常位于图像中心的一个主要点.
fx,fy是用像素单位表示的焦距。
因此,如果相机中的图像按比例缩放一个因子,所有这些参数都应该按相同的比例缩放(分别乘以/除以)。本征参数矩阵不依赖于所观察的场景。因此,一旦确定,它可以重复使用,只要焦距是固定的(变焦镜头)。旋转矩阵-平移矩阵[R|t]称为外部参数矩阵。它被用来描述相机在静态场景中的运动,反之亦然,静止镜头前物体的刚体运动。也就是说,[R|t]将一个点(X,Y,Z)的坐标转换成一个相对于摄像机固定的坐标系。当z≠0时,上述转换等价如下:
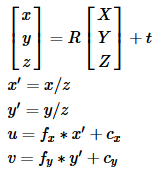
下图为针孔相机模型:
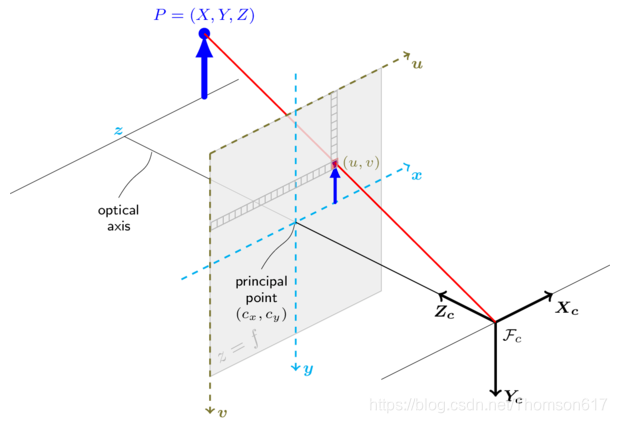
补充说明: fx、fy、cx、cy只与摄像机内部参数有关,故称为内参数矩阵。
其中fx = f/dX ,fy = f/dY ,分别称为u轴和v轴上的归一化焦距;f是相机的焦距,dX和dY分别表示传感器u轴和v轴上单位像素的尺寸大小。cx和cy则表示的是光学中心,即摄像机光轴与图像平面的交点,通常位于图像中心处,故其值常取分辨率的一半。
真实的镜头通常会有一些畸变,主要是径向畸变和轻微的切向畸变。因此,将上述模型扩展为:
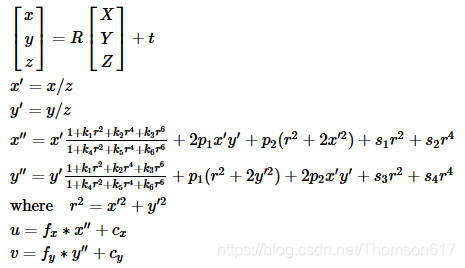
k1、k2、k3、k4、k5和k6是径向畸变系数。
p1和p2是切向畸变系数。
s1 s2 s3 s4是薄棱镜畸变系数。
在OpenCV中没有考虑高阶系数。
下图显示了两种常见的径向畸变:桶形畸变(通常为k1<0)和针形畸变(通常为k1>0)。


在某些情况下,图像传感器可能是倾斜的,以聚焦相机前面的斜面(Scheimpfug条件)。这可以用于粒子图像测速(PIV)或激光风扇三角测量。倾斜会导致x "和y "的透视变形。这种扭曲可以用以下方式建模,见例[126]。

矩阵R(τx,τy)被定义为两个旋转角参数τx和τy
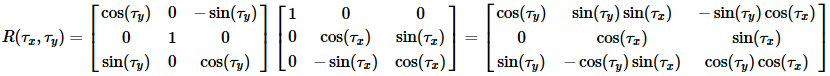
在下面的函数中,系数作为参数传递或返回向量:
![]()
也就是说,如果向量包含四个元素,那么k3=0。畸变系数不依赖于所看到的场景。因此,它们也属于相机的固有参数。不管捕获的图像分辨率如何,它们都保持不变。例如,如果一台相机在320 x 240分辨率的图像上进行了校准,那么同样的畸变系数可以用于同一台相机的640 x 480图像,而fx、fy、cx和cy则需要进行适当的缩放。
外部参数包括旋转矩阵和平移向量,它可以将 3D 坐标转换到坐标系统中。
在 3D 相关应用中,必须要先校正这些畸变。为了找到这些参数,我们必须要提供一些包含明显图案模式的样本图片(比如说棋盘(8*5)):

或9*6棋盘格:

我们可以在上面找到一些特殊点(如棋盘的四个角点)。我们起到这些特殊点在图片中的位置以及它们的真是位置。有了这些信息,我们就可以使用数学方法求解畸变系数。为了得到更好的结果,我们至少需要 20 个这样的图案模式。
如上所述,我们至少需要 20 图案模式来进行摄像机标定。OpenCV 自带 了一些棋盘图像(/sample/cpp/left001.jpg--left14.jpg), 所以我们可以使 用它们。为了便于理解,我们可以认为仅有一张棋盘图像。重要的是在进行摄 像机标定时我们要输入一组 3D 真实世界中的点以及与它们对应 2D 图像中的 点。2D 图像的点可以在图像中很容易的找到。(这些点在图像中的位置是棋盘 上两个黑色方块相互接触的地方)那么真实世界中的 3D 的点呢?这些图像来源与静态摄像机和棋盘不同 的摆放位置和朝向。所以我们需要知道(X,Y,Z)的值。但是为了简单,我 们可以说棋盘在 XY 平面是静止的,(所以 Z 总是等于 0)摄像机在围着棋 盘移动。这种假设让我们只需要知道 X,Y 的值就可以了。现在为了求 X, Y 的值,我们只需要传入这些点(0,0),(1,0),(2,0)...,它们代表了点的 位置。在这个例子中,我们的结果的单位就是棋盘(单个)方块的大小。但 是如果我们知道单个方块的大小(比如30mm),我们输入的值就可以是(0,0),(30,0),(60,0)...,结果的单位就是mm。
3D 点被称为对象点,2D 图像点被称为图像点。
42.1角点提取
为了找到棋盘的图案,我们要使用函数 cv2.findChessboardCorners()。 我们还需要传入图案的类型,比如说 9x6 的格子或 5x5 的格子等。在本例中我们使用的是 8x5 的格子(通常情况下棋盘都是 9x6 或者 8x5)。它会返回角点,如果得到图像的话返回值类型(Retval)就会是 True。这些角点会按顺序排列(从左到右,从上到下)。
其它:这个函数可能不会找出所有图像中应有的图案。所以一个好的方法是编 写代码,启动摄像机并在每一帧中检查是否有应有的图案。在我们获得图案之 后我们要找到角点并把它们保存成一个列表。在读取下一帧图像之前要设置一定的间隔,这样我们就有足够的时间调整棋盘的方向。继续这个过程直到我们 得到足够多好的图案。就算是我们举得这个例子,在所有的 14 幅图像中也不 知道有几幅是好的。所以我们要读取每一张图像从其中找到好的能用的。
其它:除了使用棋盘之外,我们还可以使用环形格子,但是要使用函数cv2.findCirclesGrid()来找图案。据说使用环形格子只需要很少的图像就可以了。
在找到这些角点之后我们可以使用函数cv2.cornerSubPix() 增加准确度。我们使用函数 cv2.drawChessboardCorners() 绘制图案。所有的这些步骤都被包含在下面的代码中了:
import numpy as np
import cv2
import glob
# termination criteria
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((8*5,3), np.float32)
objp[:,:2] = np.mgrid[0:8,0:5].T.reshape(-1,2)
# Arrays to store object points and image points from all the images.
objpoints = [] # 3d point in real world space
imgpoints = [] # 2d points in image plane.
images = glob.glob('*.jpg')
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# Find the chess board corners
ret, corners = cv2.findChessboardCorners(gray, (8,5),None)
# If found, add object points, image points (after refining them)
if ret == True: objpoints.append(objp)
corners2 = cv2.cornerSubPix(gray,corners,(4,4),(-1,-1),criteria)
imgpoints.append(corners2)
# Draw and display the corners
img = cv2.drawChessboardCorners(img, (8,5), corners2,ret)
cv2.imshow('img',img)
cv2.waitKey(2000)
cv2.destroyAllWindows()一副图像和被绘制在上边的图案:

42.2相机标定
(1).普通镜头的单目标定
在得到这些对象点和图像点之后,开始做摄像机标定。 我们要使用的函数是 cv2.calibrateCamera()。它会返回摄像机矩阵,畸变系数,旋转和平移向量等。
retval, cameraMatrix, distCoeffs, rvecs, tvecs = cv2.calibrateCamera(objectPoints, imagePoints, imageSize, cameraMatrix, distCoeffs[, rvecs[, tvecs[, flags[, criteria]]]])
retval, cameraMatrix, distCoeffs, rvecs, tvecs,stdDeviationsIntrinsics, stdDeviationsExtrinsics, perViewErrors = cv2.calibrateCameraExtended(objectPoints, imagePoints, imageSize, cameraMatrix, distCoeffs, [, rvecs[, tvecs[, stdDeviationsIntrinsics[, stdDeviationsExtrinsics[, perViewErrors[, flags[, criteria]]]]]]]) . objectPoints 校准模式点在校准模式坐标空间中的向量.
. imagePoints 校正模式点的投影向量。对于每个i, imagePoints.size()和objectPoints.size()以及imagePoints[i].size()必须等于objectPoints[i].size().
. imageSize 图像的大小只用于初始化相机的固有矩阵.
. cameraMatrix 输出3x3浮点相机矩阵{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}。如果指定了fisheye::CALIB_USE_INTRINSIC_GUESS/,则必须在调用函数之前初始化部分或全部fx、fy、cx、cy.
. distCoeffs 输出向量:畸变系数(k_1, k_2, p_1,p_2,k_3).
. rvecs 为每个模式视图估计旋转向量的输出向量(参见Rodrigues)。即,每个k旋转矢量与相应的k翻译(见下一个输出参数描述)将校准模式从模型坐标空间(对象指定点)向世界坐标空间,也就是说,一个真正的位置校准模式在k模式视图(k = 0 . .* M * 1).
. tvecs 每个模式视图估计的平移向量的输出向量.
. stdDeviationsIntrinsics输出向量的标准差估计的内在参数。偏差值的顺序:(fx,fy,cx,cy,k1,k2,p1,p2,k3,k4,k5,k6,s1,s2,s3,s4,τx,τy)如果参数之一没有估计,偏差等于零 .
. stdDeviationsExtrinsics输出向量的标准偏差估计的外部参数。偏差值的顺序:(R1,T1,…,RM,TM)其中M为模式视图的数量,Ri,Ti为串联的1x3向量.
. perViewErrors 为每个模式视图估计的RMS重投影误差的输出向量.
. flags 可能为零或下列值的组合的不同标志:
CALIB_USE_INTRINSIC_GUESS cameraMatrix包含有效的初始值fx, fy, cx, cy进一步优化。否则,(cx, cy)初始设置为图像中心(使用imageSize),并以最小二乘方式计算焦距。注意,如果已知内部参数,则不需要使用此函数来估计外部参数。而不是使用solvePnP.
CALIB_FIX_PRINCIPAL_POINT 在全局优化过程中,主点没有改变。当CALIB_USE_INTRINSIC_GUESS也被设置时,它会停留在指定的中心或不同的位置.
CALIB_FIX_ASPECT_RATIO 这些函数只将fy作为一个自由参数。fx/fy的比例与输入的camera amatrix保持一致。当CALIB_USE_INTRINSIC_GUESS未设置时,fx和fy的实际输入值被忽略,只计算它们的比值并进一步使用.
CALIB_ZERO_TANGENT_DIST 切向畸变系数(p1,p2)设置为零并保持为零.
CALIB_FIX_K1,...,CALIB_FIX_K6 优化过程中不改变相应的径向畸变系数。如果设置CALIB_USE_INTRINSIC_GUESS,则使用提供的distCoeffs矩阵的系数。否则设置为0.
CALIB_RATIONAL_MODEL 启用系数k4、k5和k6。为了提供向后兼容性,应该显式地指定这个额外的标志,以使校准函数使用rational模型并返回8个系数。如果没有设置该标志,该函数计算并只返回5个失畸变数.
CALIB_THIN_PRISM_MODEL 启用了系数s1、s2、s3和s4。为了提供向后兼容性,应该明确指定这个额外的标记,使校准功能使用瘦棱镜模型并返回12个系数。如果没有设置该标志,该函数计算并只返回5个畸变系数.
CALIB_FIX_S1_S2_S3_S4 优化过程中不改变薄棱镜畸变系数。如果设置CALIB_USE_INTRINSIC_GUESS,则使用提供的distCoeffs矩阵的系数。否则设置为0.
CALIB_TILTED_MODEL 启用了系数tauX和tauY。为了提供向后兼容性,应该明确指定这个额外的标志,使校准功能使用倾斜的传感器模型并返回14个系数。如果没有设置该标志,该函数计算并只返回5个畸变系数.
CALIB_FIX_TAUX_TAUY 优化过程中不改变倾斜传感器模型的系数。如果设置CALIB_USE_INTRINSIC_GUESS,则使用提供的distCoeffs矩阵的系数。否则设置为0.
. criteria 迭代优化算法的终止条件.(2).广角/鱼眼镜头标定
定义:设P为世界坐标系中三维坐标X中的一个点(存储在矩阵X中)摄像机坐标系中P的坐标向量为:Xc=RX+T。
其中R为旋转向量om所对应的旋转矩阵:R = rodrigues(om);称x、y、z为Xc的三个坐标:
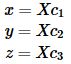
P的针孔投影坐标为[a;b]
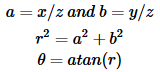
鱼眼畸变:
![]()
畸变点坐标为[x';y']
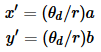
最后,转换为像素坐标:最终像素坐标向量[u;v]地点:
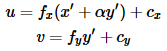
广角/鱼眼镜头标定使用的函数是 cv2.fisheye.calibrate()。它会返回摄像机矩阵,畸变系数,旋转和平移向量等。
retval, K, D, rvecs, tvecs =cv2.fisheye.calibrate(objectPoints, imagePoints, image_size, K, D[, rvecs[, tvecs[, flags[, criteria]]]])
参数:
. K 输出3x3浮点相机矩阵{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}.
. D 输出向量:畸变系数(k_1, k_2, k_3, k_4).
. flags 可能为零或下列值的组合的不同标志:
- **fisheye::CALIB_USE_INTRINSIC_GUESS** cameraMatrix包含有效的初始值fx, fy, cx, cy进一步优化。否则,(cx, cy)初始设置为图像中心(使用imageSize),并以最小二乘方式计算焦距.
- **fisheye::CALIB_RECOMPUTE_EXTRINSIC** 外部的将重新计算后,每次迭代的内在优化.
- **fisheye::CALIB_CHECK_COND** 函数将检查条件数的有效性.
- **fisheye::CALIB_FIX_SKEW** 倾斜系数(alpha)设置为0并保持为0.
- **fisheye::CALIB_FIX_K1..fisheye::CALIB_FIX_K4** 选定的畸变系数设置为零,并保持零.
- **fisheye::CALIB_FIX_PRINCIPAL_POINT** 在全局优化过程中,主点没有改变。当CALIB_USE_INTRINSIC_GUESS也被设置时,它会停留在指定的中心或不同的位置.
(3).双目标定
retval, cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, R, T, E, F = cv2.stereoCalibrate(objectPoints, imagePoints1, imagePoints2, cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, imageSize[, R[, T[, E[, F[, flags[, criteria]]]]]])
retval, cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, R, T, E, F, perViewErrors = cv2.stereoCalibrate(objectPoints, imagePoints1, imagePoints2, cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, imageSize[, R[, T[, E[, F[, perViewErrors[, flags[, criteria]]]]])
retval, K1, D1, K2, D2, R, T = cv2.fisheye.stereoCalibrate(objectPoints, imagePoints1, imagePoints2, K1, D1, K2, D2, imageSize[, R[, T[, flags[, criteria]]]])该函数估计两个摄像机之间的转换,形成一个立体对。如果你有一个相对位置和方向是固定的两个摄像头的立体相机,如果你分别(这可以用solvePnP)计算了一个对象的相对于第一个相机和第二个相机的姿态,(R1, T1)和(R2, T2),那么这些姿势肯定是相互关联的。这意味着,给定(R1, T1)计算(R2, T2)是可能的。你只需要知道第二个相机相对于第一个相机的位置和方向。这就是所描述的函数的作用。它计算(R, T)使得:
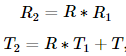
可选地,它计算基本矩阵E:
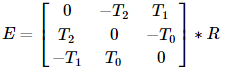
其中Ti是平移向量T的分量:T=[T0, T1, T2]^T。这个函数也可以计算基本矩阵F:
![]()
除了与立体相关的信息外,该函数还可以对每台摄像机进行完整的标定。然而,由于参数空间的高维性和输入数据中的噪声,函数可能偏离正确的解。如果每个相机的固有参数都能得到高精度的估计(例如,使用calibrateCamera),建议您这样做,然后将CALIB_FIX_INTRINSIC标志和计算得到的固有参数传递给函数。否则,如果一次性估计所有参数,则有必要限制某些参数,例如传递CALIB_SAME_FOCAL_LENGTH和CALIB_ZERO_TANGENT_DIST标志,这通常是一个合理的假设。
与calibrateCamera类似,该函数最小化了两个相机所有可用视图中所有点的总重投影误差。函数返回重新投影错误的最终值。
42.3畸变校正
如今的低价单孔摄像机(照相机)会给图像带来很多畸变。畸变主要有两种:径向畸变和切向畸变。如下图所示,用红色直线将棋盘的两个边标注出来:

但是你会发现棋盘的边界并不和红线重合。所有我们认为应该是直线的也都凸出来了。你可以通过访问Distortion(optics)获得更多相关细节。
这种畸变可以通过下面的方程组进行纠正:
![]()
![]()
与此相似,另外一个畸变是切向畸变,这是由于透镜与成像平面不可能绝对平行造成的。这种畸变会造成图像中的某些点看上去的位置会比我们认为的位置要近一些。它可以通过下列方程组进行校正:
![]()
![]()
简单来说,如果我们想对畸变的图像进行校正就必须找到五个造成畸变的系数:
Distortion cofficients = ( k1 , k2 , p1 , p2 , k3 )
畸变(distortion)是对直线投影(rectilinear projection)的一种偏移。简单来说直线投影是场景内的一条直线投影到图片上也保持为一条直线。畸变简单来说就是一条直线投影到图片上不能保持为一条直线了,这是一种光学畸变,可能由于摄像机镜头的原因。镜头畸变系数一般有径向畸变和切向畸变两种参数组成:
径向畸变有:k1,k2,k3,[k4,k5,k6]
切向畸变有:p1,p2
精确标定时也就用到这么五个参数。
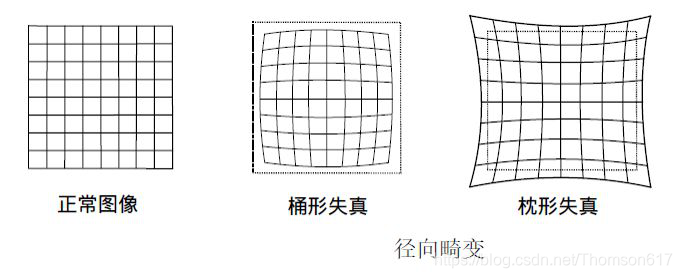
具体得到畸变系数的大小跟相机镜头的物理属性还有你选择的畸变模型有关。
通常针对消费级相机镜头采用多项式畸变模型得到的畸变系数都不超过1。但是如果你对鱼眼镜头采用只含有一个径向畸变系数k1的畸变模型进行标定,这种情况下得到的畸变系数可能会大于1。
OpenCV 提供了两种方法。
不过在那之前我们可以使用函数 cv2.getOptimalNewCameraMatrix() (fisheye中的方法为estimateNewCameraMatrixForUndistortRectify())得到自由缩放系数进而对摄像机矩阵进行优化,获取优化后的内置参数。如果缩放系数 alpha = 0,返回的非畸变图像会带有最少量的不想要的像素。它甚至有可能在图像角点去除一些像素。如果 alpha = 1,所有的像素都会被返回,还有一些黑图像。它还会返回一个 ROI 图像,我们可以 用来对结果进行裁剪。
我们读取一个新的图像(left2.ipg)
img = cv2.imread('left2.jpg')
h, w = img.shape[:2]
newcameramtx, roi=cv2.getOptimalNewCameraMatrix(mtx,dist,(w,h),1,(w,h))方式一: 使用 cv2.undistort() 。
只需使用这个函数和上边得到 的 ROI 对结果进行裁剪。
# undistort
dst = cv2.undistort(img, mtx, dist, None, newcameramtx)
# crop the image
x,y,w,h = roi
dst = dst[y:y+h, x:x+w]
cv2.imwrite('calibresult.png',dst)方式二: 使用 cv2.remap() 。
首先我们要找到从畸变图像到 非畸变图像的映射方程。再使用重映射方程。
# undistort
mapx,mapy = cv2.initUndistortRectifyMap(mtx,dist,None,newcameramtx,(w,h),5)
dst = cv2.remap(img,mapx,mapy,cv2.INTER_LINEAR)
# crop the image
x,y,w,h = roi
dst = dst[y:y+h, x:x+w]
cv2.imwrite('calibresult.png',dst)这两中方法给出的结果是相同的。结果如下所示:

你会发现结果图像中所有的边界都变直了。
现在我们可以使用 Numpy 提供写函数(np.savez,np.savetxt 等) 将摄像机矩阵和畸变系数保存以便以后使用。
42.4反向投影误差
我们可以利用反向投影误差对我们找到的参数的准确性进行估计。得到的 结果越接近 0 越好。有了内部参数,畸变参数和旋转变换矩阵,我们就可以使 用 cv2.projectPoints() 将对象点转换到图像点。然后就可以计算变换得到 图像与角点检测算法的绝对差了。然后我们计算所有标定图像的误差平均值。
mean_error = 0
for i in xrange(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i],imgpoints2, cv2.NORM_L2)/len(imgpoints2)
tot_error += error
print ("total error: ", mean_error/len(objpoints))42.6标定完整代码
(单目,双目,广角,鱼眼...)参见我的另一篇博文:https://blog.csdn.net/Thomson617/article/details/103506391
43.姿势估计
在上一节的摄像机标定中,我们已经得到了摄像机矩阵,畸变系数等。有 了这些信息我们就可以估计图像中图案的姿势,比如目标对象是如何摆放,如何旋转等。对一个平面对象来说,我们可以假设 Z=0,这样问题就转化成摄像机在空间中是如何摆放(然后拍摄)的。所以,如果我们知道对象在空间中的姿势,我们就可以在图像中绘制一些 2D 的线条来产生 3D 的效果。我们来看 一下怎么做吧。
我们的问题是:在棋盘的第一个角点绘制 3D 坐标轴(X,Y,Z 轴)。X 轴为蓝色,Y 轴为绿色,Z 轴为红色。在视觉效果上来看,Z 轴应该是垂直与 棋盘平面的。
首先我们要加载前面结果中摄像机矩阵和畸变系数。
import cv2
import numpy as np
import glob
# Load previously saved data
with np.load('B.npz') as X:
mtx, dist, _, _ = [X[i] for i in ('mtx','dist','rvecs','tvecs')]
现在我们来创建一个函数:draw, 它的参数有棋盘上的角点(使用
cv2.findChessboardCorners() 得到)和要绘制的 3D 坐标轴上的点。
def draw(img, corners, imgpts):
corner = tuple(corners[0].ravel())
img = cv2.line(img, corner, tuple(imgpts[0].ravel()), (255,0,0), 5)
img = cv2.line(img, corner, tuple(imgpts[1].ravel()), (0,255,0), 5)
img = cv2.line(img, corner, tuple(imgpts[2].ravel()), (0,0,255), 5)
return img和前面一样,我们要设置终止条件,对象点(棋盘上的 3D 角点)和坐标轴点。3D 空间中的坐标轴点是为了绘制坐标轴。我们绘制的坐标轴的长度为 3。所以 X 轴从(0,0,0)绘制到(3,0,0);Y 轴也是;Z 轴从(0,0,0)绘制到(0,0,-3)。负值表示它是朝着(垂直于)摄像机方向。
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
objp = np.zeros((9*6,3), np.float32)
objp[:,:2] = np.mgrid[0:9,0:6].T.reshape(-1,2)
axis = np.float32([[3,0,0], [0,3,0], [0,0,-3]]).reshape(-1,3)加载图像去搜寻9x6 的格子,如果发现,我们就把它优化到亚像素级。然后使用函数: cv2.solvePnPRansac() 来计算旋转和变 换。但我们有了变换矩阵之后,我们就可以利用它们将这些坐标轴点映射到图 像平面中去。简单来说,我们在图像平面上找到了与3D 空间中的点(3,0,0),(0,3,0),(0,0,3) 相对应的点。然后就可以使用函数 draw() 从图像上的第一个角点开始绘制连接这些点的直线了!
for fname in glob.glob('left*.jpg'):
img = cv2.imread(fname)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, corners = cv2.findChessboardCorners(gray, (9,6),None)
if ret == True:
corners2 = cv2.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
# Find the rotation and translation vectors.
rvecs, tvecs, inliers = cv2.solvePnPRansac(objp, corners2, mtx, dist)
# project 3D points to image plane
imgpts, jac = cv2.projectPoints(axis, rvecs, tvecs, mtx, dist)
img = draw(img,corners2,imgpts)
cv2.imshow('img',img)
k = cv2.waitKey(0) & 0xff
if k == 's':
cv2.imwrite(fname[:6]+'.png', img)
cv2.destroyAllWindows()结果如下,看到了吗,每条坐标轴的长度都是 3 个格子的长度。

渲染一个立方体:
如果想绘制一个立方体,要对 draw() 函数进行如下修改:修改后的draw()函数:
def draw(img, corners, imgpts):
imgpts = np.int32(imgpts).reshape(-1,2)
# draw ground floor in green
img = cv2.drawContours(img, [imgpts[:4]],-1,(0,255,0),-3)
# draw pillars in blue color
for i,j in zip(range(4),range(4,8)):
img = cv2.line(img, tuple(imgpts[i]), tuple(imgpts[j]),(255),3)
# draw top layer in red color
img = cv2.drawContours(img, [imgpts[4:]],-1,(0,0,255),3)
return img修改后的坐标轴点。它们是 3D 空间中的一个立方体的 8 个角点:
![]()
结果如下:

如果你对计算机图形学感兴趣的话,为了增加图像的真实性,你可以使用OpenGL (开放图形库)来渲染更复杂的图形。
44.对极几何(Epipolar Geometry)
在使用针孔相机时,我们会丢失大量重要的信息,比如说图像的深度, 或者说图像上的点和摄像机的距离,因为这是一个从 3D 到 2D 的转换。因此一 个重要的问题就是如何使用这样的摄像机计算出深度信息?答案就是使用多个相机。我们的眼睛就是这样工作的,使用两个摄像机(两个眼睛), 这被称为立体视觉。我们来看看 OpenCV 在这方面给我们都提供了什么吧。(《学习 OpenCV》一书有大量相关知识) 在进入深度图像之前,我们要先掌握一些多视角几何的基本概念。在本节中我们要处理对极几何。下图为使用两台摄像机同时对同一个场景进行拍摄的示意图:
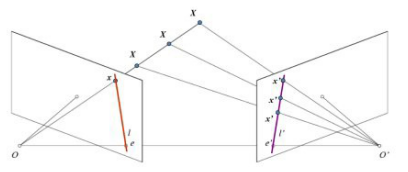
如果只用一台摄像机我们不可能知道 3D 空间中的 X 点到图像平面的距离,因为 OX 连线上的每个点投影到图像平面上的点都是相同的。但是如果我 们也考虑上右侧图像的话,直线 OX 上的点将投影到右侧图像上的不同位置。 所以根据这两幅图像,我们就可以使用三角测量计算出 3D 空间中的点到摄像 机的距离(深度)。这就是整个思路。
直线 OX 上的不同点投射到右侧图像上形成的线 l′ 被称为与 x 点对应的极线。也就是说,我们可以在右侧图像中沿着这条极线找到 x 点。它可能在这条 直线上某个位置(这意味着对两幅图像间匹配特征的二维搜索就转变成了沿着 极线的一维搜索。这不仅节省了大量的计算,还允许我们排除许多导致虚假匹 配的点)。这被称为对极约束。与此相同,所有的点在其它图像中都有与之对应的极线。平面 XOO' 被称为对极平面。
O 和 O' 是摄像机的中心。从上面的示意图可以看出,右侧摄像机的中心 O' 投影到左侧图像平面的 e 点,这个点就被称为极点。极点就是摄像机中心连 线与图像平面的交点。因此点 e' 是左侧摄像机的极点。有些情况下,我们可能 不会在图像中找到极点,它们可能落在了图像之外(这说明这两个摄像机不能 拍摄到彼此)。
所有的极线都要经过极点。所以为了找到极点的位置,我们可以先找到多条极线,这些极线的交点就是极点。
本节我们的重点就是找到极线和极点。为了找到它们,我们还需要两个元素,本征矩阵(E)和基础矩阵(F)。本征矩阵包含了物理空间中两个摄像机相关的旋转和平移信息。如下图所示(本图来源自:学习OpenCV):
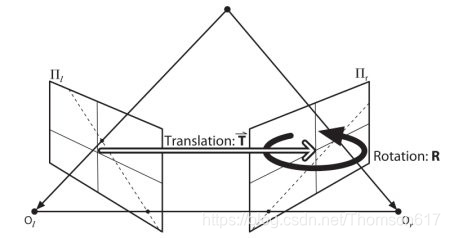
基础矩阵 F 除了包含 E 的信息外还包含了两个摄像机的内参数。由于 F 包含了这些内参数,因此它可以它在像素坐标系将两台摄像机关联起来。(如果使用是校正之后的图像并通过除以焦距进行了归一化,F=E)。简单来说,基 础矩阵 F 将一副图像中的点映射到另一幅图像中的线(极线)上。这是通过匹 配两幅图像上的点来实现的。要计算基础矩阵至少需要 8 个点(使用 8 点算 法)。点越多越好,可以使用 RANSAC 算法得到更加稳定的结果。
为了得到基础矩阵我们应该在两幅图像中找到尽量多的匹配点。我们可以使用 SIFT 描述符,FLANN 匹配器和比值检测。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img1 = cv2.imread('myleft.jpg',0) #queryimage # left image
img2 = cv2.imread('myright.jpg',0) #trainimage # right image
sift = cv2.SIFT()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
good = []
pts1 = []
pts2 = []
# ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):
if m.distance < 0.8*n.distance: good.append(m)
pts2.append(kp2[m.trainIdx].pt)
pts1.append(kp1[m.queryIdx].pt)现在得到了一个匹配点列表,我们就可以使用它来计算基础矩阵了。
pts1 = np.int32(pts1) pts2 = np.int32(pts2)
'''
retval, mask=cv2.findFundamentalMat(points1, points2, method, ransacReprojThreshold, confidence, mask)
--points1:从第一张图片开始的N个点的数组。点坐标应该是浮点数(单精度或双精度)。
--points2:与点1大小和格式相同的第二图像点的数组。
--method:计算基本矩阵的方法。
* cv2.FM_7POINT for a 7-point algorithm. N=7
* cv2.FM_8POINT for an 8-point algorithm. N≥8
* cv2.FM_RANSAC (默认) for the RANSAC algorithm. N≥8
* cv2.FM_LMEDS for the LMedS algorithm. N≥8
--ransacReprojThreshold:仅用于RANSAC方法的参数,默认3。它是一个点到极线的最大距离(以像素为单位),超过这个点就被认为是一个离群点,不用于计算最终的基本矩阵。根据点定位、图像分辨率和图像噪声的准确性,可以将其设置为1-3左右。
--confidence:仅用于RANSAC和LMedS方法的参数,默认0.99。它指定了一个理想的置信水平(概率),即估计矩阵是正确的。
--mask:输出
'''
F, mask = cv2.findFundamentalMat(pts1,pts2,cv2.FM_LMEDS)
# We select only inlier points
pts1 = pts1[mask.ravel()==1]
pts2 = pts2[mask.ravel()==1]下一步我们要找到极线。我们会得到一个包含很多线的数组。所以我们要定义一个新的函数将这些线绘制到图像中。
def drawlines(img1,img2,lines,pts1,pts2):
''' img1 - image on which we draw the epilines for the points in img2
lines - corresponding epilines
'''
r,c = img1.shape
img1 = cv2.cvtColor(img1,cv2.COLOR_GRAY2BGR)
img2 = cv2.cvtColor(img2,cv2.COLOR_GRAY2BGR)
for r,pt1,pt2 in zip(lines,pts1,pts2):
color = tuple(np.random.randint(0,255,3).tolist())
x0,y0 = map(int, [0, -r[2]/r[1] ])
x1,y1 = map(int, [c, -(r[2]+r[0]*c)/r[1] ])
img1 = cv2.line(img1, (x0,y0), (x1,y1), color,1)
img1 = cv2.circle(img1,tuple(pt1),5,color,-1)
img2 = cv2.circle(img2,tuple(pt2),5,color,-1)
return img1,img2现在在两幅图像中计算并绘制极线。
# 找出对应于右图像(第二幅图像)中各点的后记,并在左图像上画出相应的线
'''
lines = cv.computeCorrespondEpilines(points, whichImage, F, lines)
-- points:输入点。类型为CV_32FC2N×1或1×N矩阵。
--whichImage:包含点的图像(1或2)的索引。
--F:基本矩阵,可使用findFundamentalMat或stereoRectify 进行估计。
--lines:对应于另一幅图像中点的极线的输出向量(a,b,c)表示直线ax+by+c=0
'''
lines1 = cv2.computeCorrespondEpilines(pts2.reshape(-1,1,2), 2,F)
lines1 = lines1.reshape(-1,3)
img5,img6 = drawlines(img1,img2,lines1,pts1,pts2)
# 找出对应于左图像(第一幅图像)中的点的后记,并在右图像上画出相应的线
lines2 = cv2.computeCorrespondEpilines(pts1.reshape(-1,1,2), 1,F)
lines2 = lines2.reshape(-1,3)
img3,img4 = drawlines(img2,img1,lines2,pts2,pts1)
plt.subplot(121),plt.imshow(img5)
plt.subplot(122),plt.imshow(img3)
plt.show()结果如下:

从上图可以看出所有的极线都汇聚以图像外的一点,这个点就是极点。 为了得到更好的结果,我们应该使用分辨率比较高的图像和 non-planar点。
更多资源
1.一个重要的话题是相机的前进。然后,将在两个位置的相同位置看到极点,并且从固定点出现极点。See this discussion.
2.基本矩阵估计对匹配质量、离群值等敏感。当所有选择的匹配都位于同一平面上时,情况会变得更糟. Checkthis discussion.
45.双目立体视觉
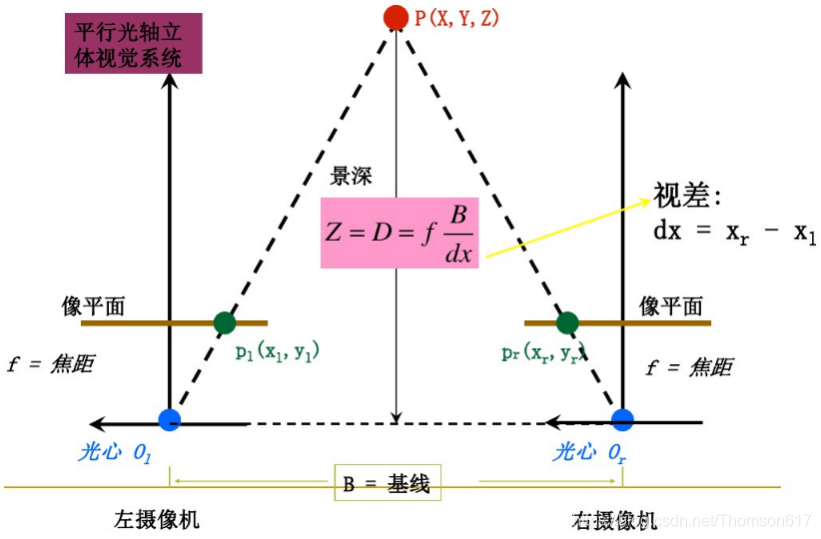
双目立体视觉(Binocular Stereo Vision)是机器视觉的一种重要形式,它是基于视差原理并利用成像设备从不同的位置获取被测物体的两幅图像,通过计算图像对应点间的位置偏差,来获取物体三维几何信息的方法。
双目立体视觉理论建立在对人类视觉系统研究的基础上,通过双目立体图象的处理,获取场景的三维信息,其结果表现为深度图,再经过进一步处理就可得到三维空间中的景物,实现二维图象到三维空间的重构。Marr-Poggio-Grimson最早提出并实现了一种基于人类视觉系统的计算视觉模型及算法。双目立体视觉系统中,获取深度信息的方法比其它方式(如由影到形方法)较为直接,它是被动方式的,因而较主动方式(如程距法)适用面宽,这是它的突出特点。
双目立体视觉融合两只眼睛获得的图像并观察它们之间的差别,使我们可以获得明显的深度感,建立特征间的对应关系,将同一空间物理点在不同图像中的映像点对应起来,这个差别称作视差(Disparity)图像。
深度图像也叫距离影像,是指将从图像采集器到场景中各点的距离(深度)值作为像素值的图像。获取方法有:激光雷达深度成像法、计算机立体视觉成像、坐标测量机法、莫尔条纹法、结构光法。
点云:当一束激光照射到物体表面时,所反射的激光会携带方位、距离等信息。若将激光束按照某种轨迹进行扫描,便会边扫描边记录到反射的激光点信息,由于扫描极为精细,则能够得到大量的激光点,因而就可形成激光点云。深度图像经过坐标转换可以计算为点云数据;有规则及必要信息的点云数据可以反算为深度图像。 两者在一定条件下是可以相互转化。深度图不适合直观的去察看,点云的效果会更强,所以,一般我们都是将深度图转成点云再察看。
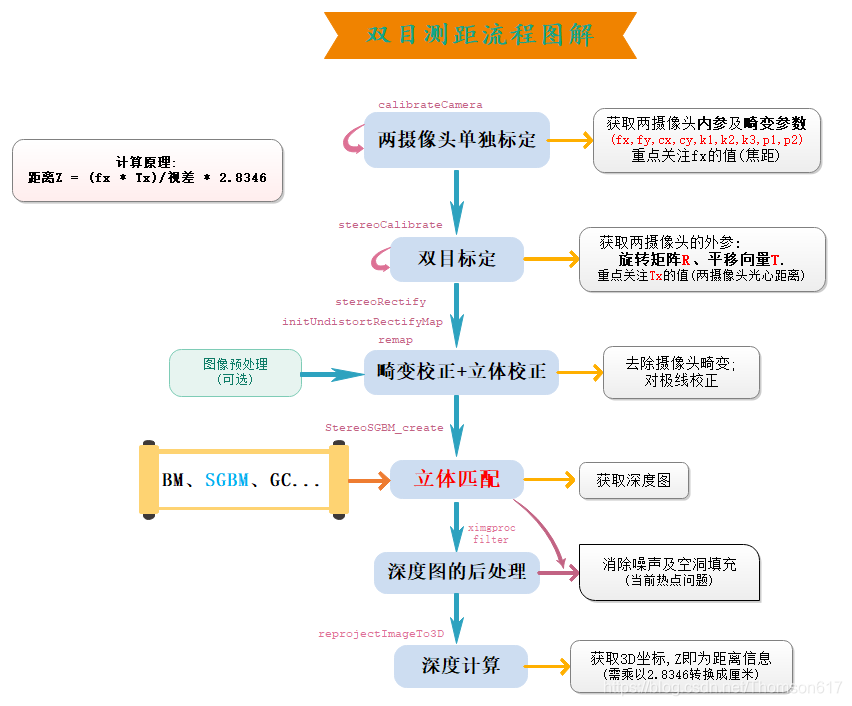
双目立体视觉的最终目标:三维重建。基于视觉的三维重建,指的是通过摄像机获取场景物体的数据图像,并对此图像进行分析处理,再结合计算机视觉知识推导出现实环境中物体的三维信息。三维重建技术是计算机视觉、人工智能、虚拟现实等前沿领域的热点和难点,也是人类在基础研究和应用研究中面临的重大挑战之一。基于图像的三维重建是图像处理的一个重要研究分支,作为当今热门的虚拟现实和科学可视化的基础,它被广泛应用于检测和观察中。一个完整的三维重建系统通常可分为图像获取、摄像机标定、特征点提取、立体匹配、深度确定和后处理等6大部分。
三维重建视觉作为计算机视觉中的一个重要分支,一直是计算机视觉研究的重点和热点之一。它直接模拟了人类视觉处理景物的方式,可以在多种条件下灵活地测量景物的立体信息。对它的研究,无论是在视觉生理的角度还是在工程应用的角度都具有十分重要的意义。三维重建视觉技术在由物体的二维图像获得物体的深度信息上具有很大的优越性。
双目视觉不仅仅用来测距,一般都把测距用于其它研究领域,如三维重建、图像融合、增强现实、目标识别与跟踪等等。
双目测距的精度和基线长度(两台相机之间的距离)有关,两台相机布放的距离越远,测距精度越高。但往往在实际应用中,相机的布放空间是有限的,最多也只有几米或几十米的基线长度,这就导致双目测距在远距离条件下的精度大打折扣。所以,双目测距一般用于近距离的高精度测量,而远距离测距一般用脉冲式的激光测距机。
图像测量方法的优点是近距离精度高,但是图像质量受外界光照等条件制约太大,且由于相机性能往往不够稳定,加上算法相对复杂些,这些都会限制它的应用。总之,双目测距虽然说是比较成熟的技术,但是其应用范围有限。
双目立体视觉深度相机简化流程:
(1).首先需要对双目相机进行标定,得到两个相机的内外参数、单应矩阵。
(2).根据标定结果对原始图像校正,校正后的两张图像位于同一平面且互相平行。
(3).对校正后的两张图像进行像素点匹配。
(4).根据匹配结果计算每个像素的深度,从而获得深度图。
45.1成像模型
(1).小孔成像模型
小孔成像模型也称为针孔模型,是计算机视觉中最理想的一种也是最简单的一种成像模型,它近似为线性结构。摄像机成像模型的一个主要作用便是将真实空间中的点与拍摄平面图像上的点建立起联系。考虑到小孔成像模型的计算简便、便于分析等众多优点,其使用率比其它两种模型正交投影模型和拟透视投影模型都要高。
在小孔成像模型中,主要由光心、光轴和成像平面几个部分组成,且假设所有成像过程都满足光的直线传播条件。根据光的直线传播理论,空间中的物点反射光在经过光心后,投影到平面为一个倒立的像点。虽然作为理想的成像模型小孔成像物理性质极佳,但在实际的摄像机光学系统中大多是由透镜组成,在透镜成像中需要满足以下条件:
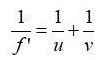
其中,f ’表示透镜的焦距,u 表示物距,v 表示像距。在视觉应用的多数情况中都认为透镜摄像系统的成像模型与小孔成像模型拥有一致的成像关系,近似认为 v≈f’。因此小孔成像模型一直以来都作为相机成像的基本模型来使用。
由于小孔成像的像点倒立,不方便分析和计算,常将光心与视平面进行位置对调。其如图所示:
(2).平行式与会聚式双目立体视觉系统模型
相机的摆放位置不同,系统模型的空间几何结构也不相同,相应的计算方式也会发生改变。依据相机的摆放方式,双目立体视觉系统模型主要分为两种:平行放置方式和会聚放置放式。如图所示:
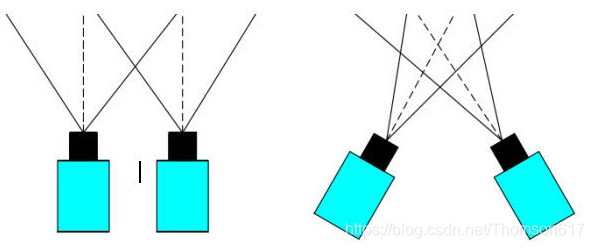
其中,由于平行放置方式计算简便,没有垂直方向的视差,是最为常用的模型。会聚方式两台相机的摆放位置要求不严格,相对比较随意。按这种方式放置的相机灵活性较强,能依据现场环境、采集对象特点来进行调整,通过改变摄像机间的距离和角度来获得最好的测量效果。这种方式的一大缺点是计算相对复杂,虽然灵活的调整能保证了两个相机的共同视野足够大,但同时也使得后续的处理变得更加麻烦,左右图像的匹配难度增加了不少。 相机水平平行放置方式又称为标准放置方式,要求两个相机的光轴平行,光心在同一水平线上。在双目立体视觉技术中要求两相机的内部参数是一样的,两个相机之间的距离称为基线,在水平平行放置模型中,理想情况是左相机沿基线距离移动后能与右相机完全重合,在有些场合将单相机安装在导轨上来进行拍摄便是一种很好的选择,这种情况下相机的内部参数一致度高,导轨也保证了水平方向的平行度,但这种方式需要移动相机比较不方便,而且无法实现实时测量。双相机平行放置模型最为简单实用,大大减少了计算量也便于分析,尤其在相机的标定校正上可以非常方便。当然它也存在一些缺点,比如当目标和相机较近时比较容易出现盲区,增大视角的话又可能带来一些畸变,但随着相机制造水平的提高这种相机模型依然是最佳的选择,本文采用相机平行放置方式进行分析计算和实验。
(3).理想双目相机成像模型
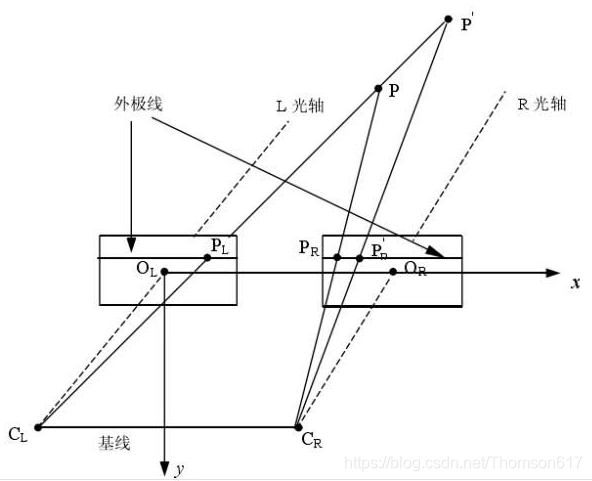
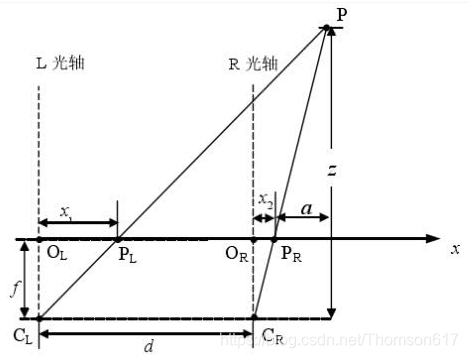
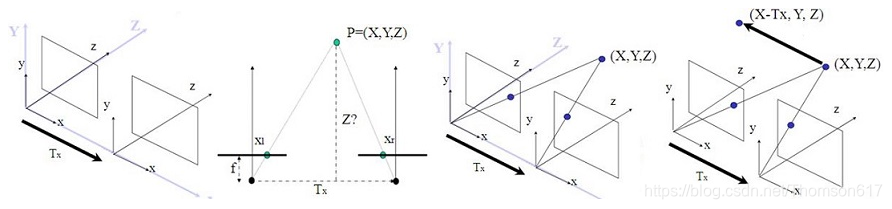
首先我们从理想的情况开始分析:假设左右两个相机位于同一平面(光轴平行,并且摄像机的水平扫描线位于同一平面时),且相机参数(如焦距f)一致。那么深度值的推导原理和公式如下。公式只涉及到初中学的三角形相似知识,不难看懂。
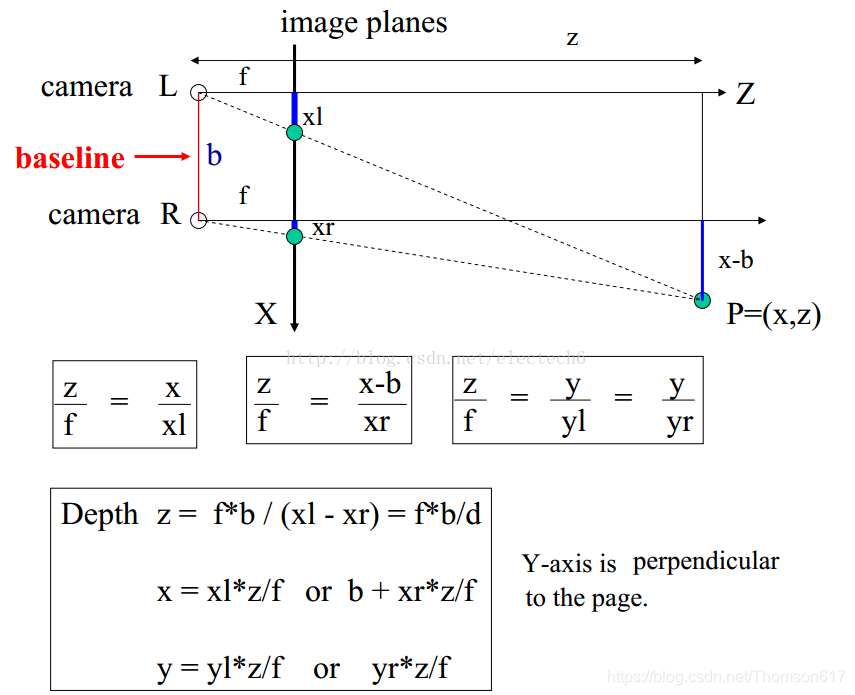
根据上述推导,空间点P离相机的距离(深度)z=f*b/d,可以发现如果要计算深度z,必须要知道:
1、相机焦距f,左右相机基线b。这些参数可以通过先验信息或者相机标定得到。
2、视差d。需要知道左相机的每个像素点(xl, yl)和右相机中对应点(xr, yr)的对应关系。这是双目视觉的核心问题。
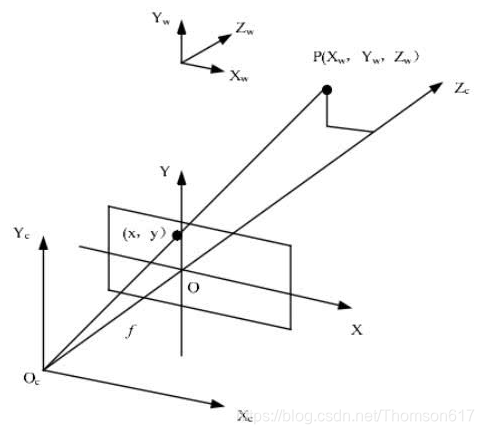
45.2图像中的四大坐标系
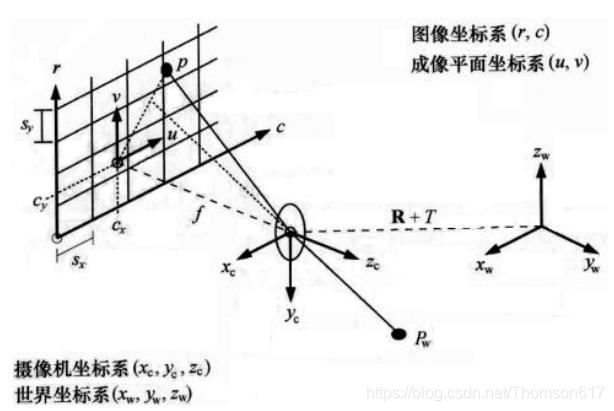
(1).世界坐标系就是物体在真实世界中的坐标,比如黑白棋盘格的世界坐标系原点定在第一个棋盘格的顶点,Xw,Yw,Zw互相垂直,Zw方向就是垂直于棋盘格面板的方向。可见世界坐标系是随着物体的大小和位置变化的,单位是长度单位。只要棋盘格的大小决定了,无论板子怎么动,棋盘格角点坐标一般就不再变动(因为是相对于世界坐标系原点的位置不变),且认为是Zw=0。
(2).相机坐标系以光心为相机坐标系的原点,以平行于图像的x和y方向为Xc轴和Yc轴,Zc轴和光轴平行,Xc,Yc,Zc互相垂直,单位是长度单位。
(3).图像物理坐标系以主光轴和图像平面交点为坐标原点,x和y方向如图所示,单位是长度单位。
(4).图像像素坐标系以图像的顶点为坐标原点,u和v方向平行于x和y方向,单位是以像素计。
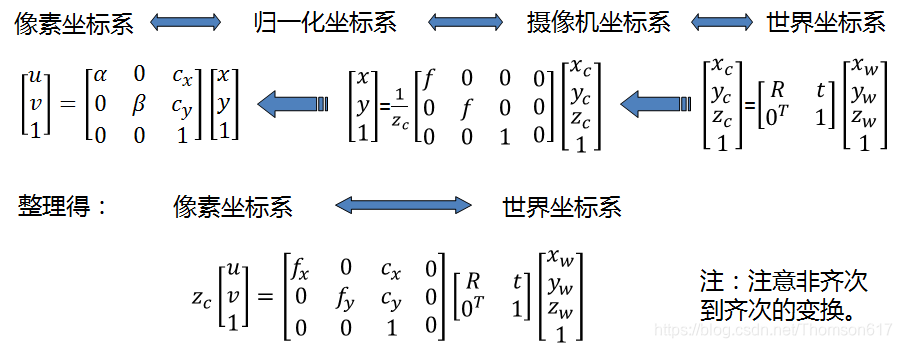
坐标系之间的转换:
45.3极线约束
先思考一个问题:用两个相机在不同的位置拍摄同一物体,如果两张照片中的景物有重叠的部分,我们有理由相信,这两张照片之间存在一定的对应关系,本节的任务就是如何描述它们之间的对应关系,描述工具是对极几何 ,它是研究立体视觉的重要数学方法。
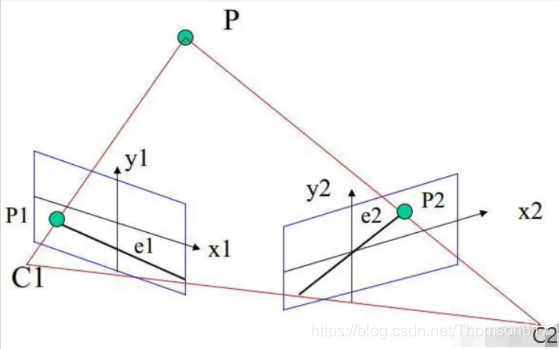
要寻找两幅图像之间的对应关系,最直接的方法就是逐点匹配,如果加以一定的约束条件:极线约束(epipolar constraint),搜索的范围可以大大减小。极线约束对于求解图像对中像素点的对应关系非常重要。那什么是极线呢?如下图所示:
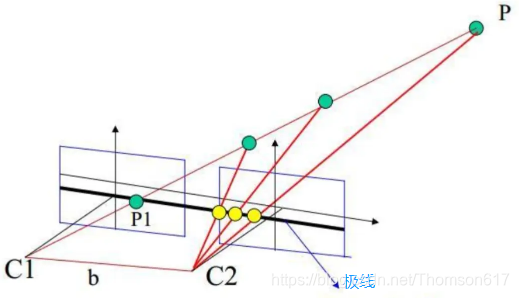
C1,C2是两个相机,P是空间中的一个点,P和两个相机中心点C1、C2形成了三维空间中的一个平面PC1C2,称为极平面(Epipolar plane)。极平面和两幅图像相交于两条直线,这两条直线称为极线(Epipolar line)。P在相机C1中的成像点是P1,在相机C2中的成像点是P2,但是P的位置事先是未知的。
我们的目标是:对于左图的P1点,寻找它在右图中的对应点P2,这样就能确定P点的空间位置,也就是我们想要的空间物体和相机的距离(深度)。
所谓极线约束(Epipolar Constraint)就是指当同一个空间点在两幅图像上分别成像时,已知左图投影点P1,那么对应右图投影点P2一定在相对于P1的极线上,这样可以极大的缩小匹配范围。
根据极线约束的定义,我们可以在下图中直观的看到P2一定在对极线上,所以我们只需要沿着极线搜索一定可以找到和P1的对应点P2。
上述过程考虑的情况(两相机共面且光轴平行,参数相同)非常理想,相机C1,C2如果不是在同一直线上怎么办?事实上,这种情况非常常见,因为有些场景下两个相机需要独立固定,很难保证光心C1,C2完全水平,即使是固定在同一个基板上也会因为装配的原因导致光心不完全水平。如下图所示。我们看到两个相机的极线不仅不平行,还不共面,之前的理想模型那一套推导结果用不了了,这可咋办呢?图像矫正(Image Rectification)技术就出现了。
45.4图像矫正(立体校正)
图像矫正是通过分别对两张图片用单应(homography)矩阵变换(可以通过标定获得)得到的,目的就是把两个不同方向的图像平面(下图中灰色平面)重新投影到同一个平面且光轴互相平行(下图中黄色平面),这样就可以用前面理想情况下的模型了,两个相机的极线也变成水平的了。
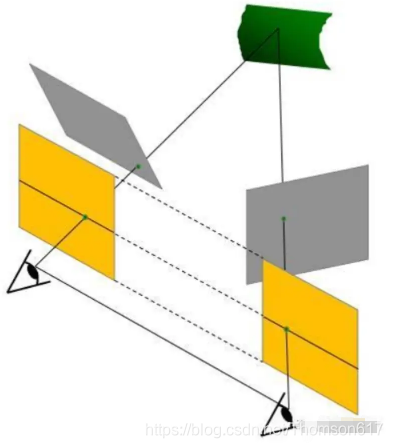
经过图像矫正后,左图中的像素点只需要沿着水平极线方向搜索对应点就可以了。
R1, R2, P1, P2, Q, validPixROI1, validPixROI2 = cv2.stereoRectify(cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, imageSize, R, T[, R1[, R2[, P1[, P2[, Q[, flags[, alpha[, newImageSize]]]]]]]])
R1, R2, P1, P2, Q = cv2.fisheye.stereoRectify(K1, D1, K2, D2, imageSize, R, T,flags[, R1[, R2[, P1[, P2[, Q[, newImageSize[, balance[,fov_scale ]]]]]]]])上述函数计算每个相机的旋转矩阵,使两个相机的图像平面(实际上)是同一个平面。因此,这使得所有的极外线都是平行的,从而简化了稠密的立体对应问题。该函数以stereoCalibrate计算的矩阵为输入。作为输出,它提供了两个旋转矩阵和两个新坐标中的投影矩阵。该函数区分了以下两种情况:
Horizontal stereo:第一和第二相机的视图相对移动,主要沿着x轴(可能有小的垂直移动)。在校正后的图像中,左右摄像头对应的极线是水平的,y坐标相同。P1和P2看起来像:
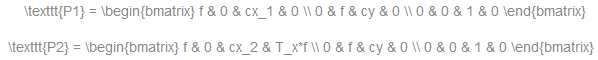
其中T_x是相机和cx_1=cx_2之间的水平移动,如果设置calib_zero_视差。
Vertical stereo:第一和第二摄像机视图主要在垂直方向上相对移动(可能也在水平方向上移动了一点)。经过校正的图像中的极线是垂直的,并且具有相同的x坐标。P1和P2看起来像:
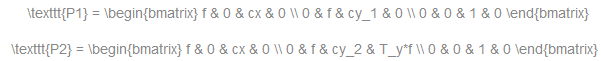
其中T_y是相机和cy_1=cy_2之间的垂直位移,如果设置calib_zero_视差。
如您所见,P1和P2的前三列将有效地成为新的“矫正”相机矩阵。然后可以将这些矩阵与R1和R2一起传递给initunt整流映射,以初始化每个相机的整流映射。
请看下面来自stereo_calib.cpp样本的截图。一些红色的水平线通过相应的图像区域。这意味着图像得到了很好的矫正,这是大多数立体匹配算法所依赖的。绿色的矩形是roi1和roi2。你可以看到它们的内部都是有效的像素。
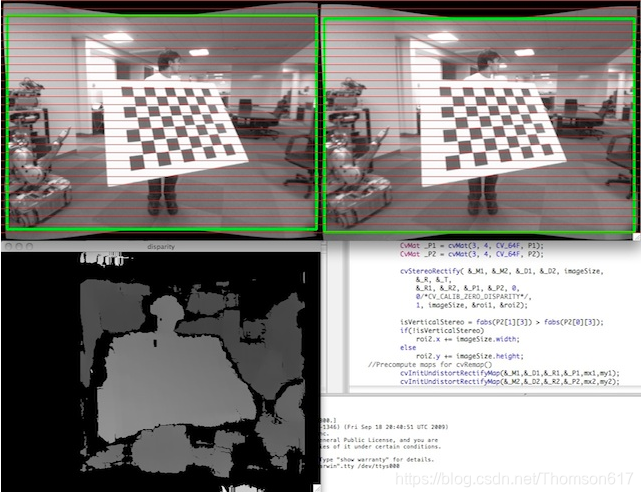
45.5立体匹配
立体匹配是根据对所选特征的计算,建立特征间的对应关系,将同一个空间点在不同图像中的映像点对应起来,并由此得到相应的视差图像,立体匹配是双目视觉中最重要也是最困难的问题。当空间三维场景被投影为二维图像时,同一景物在不同视点下的图像会有很大不同,而且场景中的诸多因素,如光照条件、景物几何形状和物理特性、噪声干扰和畸变以及摄像机特性等,都被综合成单一的图像灰度值。
因此,要准确的对包含了如此之多不利因素的图像进行无歧义匹配十分困难。 立体匹配的方法主要分为两大类,即灰度相关和特征匹配。灰度相关直接用象素灰度进行匹配,该方法优点是匹配结果不受特征检测精度和密度的影响,可以得到很高的定位精度和密集的视差表面;缺点是依赖于图像灰度统计特性,对景物表面结构以及光照反射较为敏感,因此在空间景物表面缺乏足够纹理细节、成像失真较大(如基线长度过大)的场合存在一定困难。
立体匹配是一种从平面图像中恢复深度信息的技术。由于双目立体匹配系统通过模拟人眼视觉感知原理,仅需要两台数字摄像机安装在同一水平线上,经过立体矫正就可以投入使用。具有实现简单、成本低廉并且可以在非接触条件下测量距离等优点。近年来,随着社会的科技进步,立体匹配技术的发展日新月异,随着匹配算法精度与速度的提高,其应用场景进一步扩大。在此背景下,研究立体匹配的意义非凡。
立体匹配作为三维重建、立体导航、非接触测距等技术的关键步骤,通过匹配两幅或者多幅图像来获取深度信息。并且广泛应用于工业生产自动化、流水线控制、无人驾驶汽车(测距,导航)、安防监控、遥感图像分析、机器人智能控制等方面。在机器人制导系统中可以用于导航判断、目标拾取;在工业自动化控制系统中可用于零部件安装、质量检测,环境检测;在安防监控系统中可用于人流检测,危害报警。虽然立体匹配应用广泛,但是还有很多尚未解决的难题,因此该技术成为了近年来计算机视觉领域广泛关注的难点和热点。
在上一节中我们学习了对极约束的基本概念和相关术语。如果同一场景有两幅图像的话我们在直觉上就可以获得图像的深度信息。如下图所示:

上图包含相似三角形。写出它们的等价方程将得到以下结果:
![]()
x 和 x' 分别是图像中的点到 3D 空间中的点和到摄像机中心的距离。B 是这两个摄像机之间的距离,f 是摄像机的焦距。上边的等式告诉我们点的深度与x 和 x' 的差成反比。所以根据这个等式我们就可以得到图像中所有点的深度图, 这样就可以找到两幅图像中的匹配点了。前面我们已经知道了对极约束可以使这个操作更快更准,一旦找到了匹配,就可以计算出 disparity 了。
下面的代码显示了构建深度图的简单过程。
import numpy as np
import cv2
imgL = cv2.imread('tsukuba_l.png',0)
imgR = cv2.imread('tsukuba_r.png',0)
stereo = cv2.StereoBM_create(numDisparities=16, blockSize=15)
disparity = stereo.compute(imgL,imgR)
disp = cv2.normalize(src=disparity, dst=disparity, beta=0, alpha=255,
norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
cv2.imshow('disp',disp)下图左侧为原始图像,右侧为深度图像。如图所示,结果中有很大的噪音。 通过调整 numDisparities 和 blockSize 的值,我们会得到更好的结果。

OpenCV中提供了三种立体匹配算法的实现:BM、SGBM、GC。
BM(Block Matching,块匹配): 速度最快,但效果最差;
SGBM(Semi-Global Block Matching,半全局块匹配): 匹配效果好,速度比BM稍慢;
GC(Graph Cuts,图割): 匹配效果最佳,但速度最慢,不适合实时业务,只能在opencv2.x中找到实现。
注意: GC算法只能在C语言模式下运行,并且不能对视差图进行预先的边界延拓,左右视图和左右视差矩阵的大小必须一致。
SGBM算法详解
SGBM的思路:通过选取每个像素点的disparity,组成一个disparity map,设置一个和disparity map相关的全局能量函数,使这个能量函数最小化,以达到求解每个像素最优disparity的目的。能量函数形式如下:
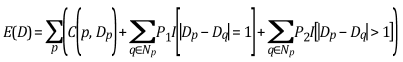
D指disparity map。E(D)是该disparity map对应的能量函数。
p, q代表图像中的某个像素。
Np 指像素p的相邻像素点(一般认为8连通)。
C(p, Dp)指当前像素点disparity为Dp时,该像素点的cost。
P1 是一个惩罚系数,它适用于像素p相邻像素中dsparity值与p的dsparity值相差1的那些像素。
P2 是一个惩罚系数,它适用于像素p相邻像素中dsparity值与p的dsparity值相差大于1的那些像素。
I[.]函数返回1如果函数中的参数为真,否则返回0。利用上述函数在一个二维图像中寻找最优解是一个NP-complete问题,耗时过于巨大,因此该问题被近似分解为多个一维问题,即线性问题。而且每个一维问题都可以用动态规划来解决。因为1个像素有8个相邻像素,因此一般分解为8个一维问题。考虑从左到右这一方向,如下图所示:

则每个像素的disparity只和其左边的像素相关,有如下公式:
![]()
r指某个指向当前像素p的方向,在此可以理解为像素p左边的相邻像素。
Lr(p, d) 表示沿着当前方向(即从左向右),当目前像素p的disparity取值为d时,其最小cost值。
这个最小值是从4种可能的候选值中选取的最小值:
1.前一个像素(左相邻像素)disparity取值为d时,其最小的cost值。
2.前一个像素(左相邻像素)disparity取值为d-1时,其最小的cost值+惩罚系数P1。
3.前一个像素(左相邻像素)disparity取值为d+1时,其最小的cost值+惩罚系数P1。
4.前一个像素(左相邻像素)disparity取值为其它时,其最小的cost值+惩罚系数P2。
另外,当前像素p的cost值还需要减去前一个像素取不同disparity值时最小的cost。这是因为Lr(p, d)是会随着当前像素的右移不停增长的,为了防止数值溢出,所以要让它维持在一个较小的数值。
C(p, d)的计算很简单,由如下两个公式计算:
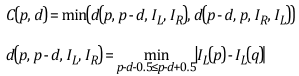
即,当前像素p和移动d之后的像素q之间,经过半个像素插值后,寻找两个像素点灰度或者RGB差值的最小值,作为C(p, d)的值。具体来说:设像素p的灰度/RGB值为I(p),先从I(p)、(I(p)+I(p-1))/2、(I(p)+I(p+1))/2三个值中选择出和I(q)差值最小的,即d(p,p-d)。然后再从I(q)、(I(q)+I(q-1))/2、(I(q)+I(q+1))/2三个值中选择出和I(p)差值最小的,即d(p-d,p)。最后从两个值中选取最小值,就是C(p, d)。
上面是从一个方向(从左至右)计算出的像素在取值为某一disparity值时的最小cost值。但是一个像素有8个邻域,所以一共要从8个方向计算(左右,右左,上下,下上,左上右下,右下左上,右上左下,左下右上)这个cost值。然后把八个方向上的cost值累加,选取累加cost值最小的disparity值作为该像素的最终disparity值。对于每个像素进行该操作后,就形成了整个图像的disparity map。公式表达如下:
![]()
SGBM算法遍历每个像素,针对每个像素的操作和disparity的范围有关,故时间复杂度为:O(w·h·n)。可以使用积分图(Integral Image)或方框滤波(Box Filtering)的方法使时间复杂度下降到O(w*h)。
代码实现:
num = 5
blockSize = 13
stereo_sgbm = cv2.StereoSGBM_create(
minDisparity=0, # 最小视差值(int类型),通常情况下为0。此参数决定左图中的像素点在右图匹配搜索的起点。最小视差值越小,视差图右侧的黑色区域越大
numDisparities=16 * num, # 视差搜索范围,其值必须为16的整数倍且大于0。视差窗口越大,视差图左侧的黑色区域越大
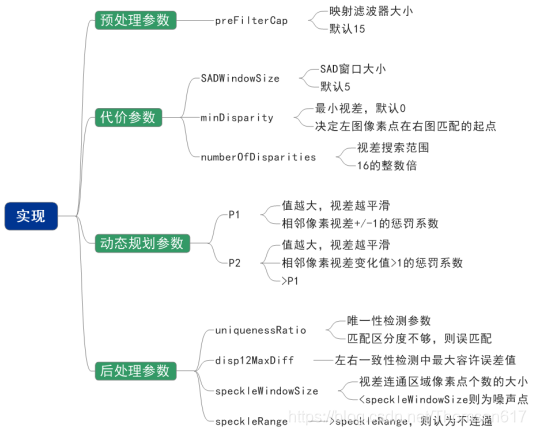
blockSize=blockSize, # 匹配块大小(SADWindowSize(SAD代价计算的窗口大小)),大于1的奇数。默认为5,一般在3~11之间
P1=8 * 3 * blockSize * blockSize, # P1是相邻像素点视差增/减 1 时的惩罚系数;需要指出,在动态规划时,P1和P2都是常数。一般:P1=8*通道数*blockSize*blockSize,P2=4*P1
P2=32 * 3 * blockSize * blockSize, # P2是相邻像素点视差变化值大于1时的惩罚系数。P2必须大于P1。p2值越大,差异越平滑
disp12MaxDiff=20, # 左右视差图的最大容许差异(左右一致性检测,超过将被清零),默认为-1,即不执行左右视差检查。
preFilterCap=15, # 图像预处理参数,水平sobel预处理后,映射滤波器大小。默认为15
uniquenessRatio=0, # 视差唯一性检测百分比,视差窗口范围内最低代价是次低代价的(1+uniquenessRatio/100)倍时,最低代价对应的视差值才是该像素点的视差,否则该像素点的视差为 0,通常为5~15.
speckleWindowSize=100, # 视差连通区域像素点个数的大小。若大于,视差值认为有效,否则认为当前视差值是噪点。将其设置为0可禁用斑点过滤。否则,将其设置在50-200的范围内。
speckleRange=2, # 视差变化阈值,每个连接组件内的最大视差变化。如果你做斑点过滤,将参数设置为正值,它将被隐式乘以16.通常,1或2就足够好了
mode=cv2.STEREO_SGBM_MODE_SGBM_3WAY # 模式,取值0,1,2,3。默认被设置为false。
)
# stereo_sgbm_right_matcher = cv2.ximgproc.createRightMatcher(stereo_sgbm)
# 计算视差: 根据SGBM方法生成差异图
disparity_left = stereo_sgbm.compute(gray_L, gray_R)SGBM的参数说明:
立体匹配算法的步骤
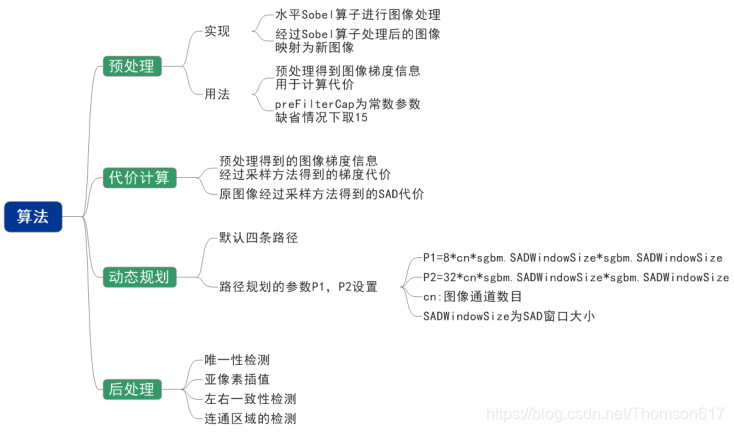
总体来讲包含以下6个步骤:
1.预处理( GaussBlur , SobelX, ...etc)
2.代价计算 ( AD, SAD, SSD, BT, NCC, Census, ...etc)
3.代价聚合 ( Boxfilter, CBCA, WMF, MST, ...etc)
4.代价优化 ( BP, GC, HBP, CSBP, doubleBP, ...)
5.视差计算 ( WTA)
6.后处理 ( MedianFilter, WeightMedianFilter, LR-check, ...etc)
一般情况下,组合12356称为局部立体匹配算法,12456称为全局立体匹配算法,区别在于是否构建全局能量优化函数。
1)匹配代价计算(Cost Computation)
计算匹配代价即计算参考图像上的每个像素点IR(P),以所有视差可能性去匹配目标图像上对应点IT(pd)的代价值,因此计算得到的代价值可以存储在一个h*w*d(MAX)的三维数组中,通常称这个三维数组为视差空间图(Disparity Space Image,DSI)。匹配代价是立体匹配的基础,设计抗噪声干扰、对光照变化不敏感的匹配代价能提高立体匹配的精度。因此,匹配代价的设计在全局算法和局部算法中都是研究的重点。
2)代价聚合(Cost Aggregation)
通常全局算法不需要代价聚合,而局部算法需要通过求和、求均值或其它方法对一个支持窗口内的匹配代价进行聚合而得到参考图像上一点p在视差d处的累积代价CA(p,d),这一过程称为代价聚合。通过匹配代价聚合,可以降低异常点的影响,提高信噪比(SNR,Signal Noise Ratio)进而提高匹配精度。代价聚合策略通常是局部匹配算法的核心,策略的好坏直接关系到最终视差图(Disparity maps)的质量。
3)视差计算(Disparity Computation)
局部立体匹配算法的思想,在支持窗口内聚合完匹配代价后,获取视差的过程就比较简单,只需在一定范围内选取匹配代价聚合最优的点(SAD和SSD取最小值,NCC取最大值)作为对应匹配点。通常采用‘胜者为王’策略(WTA,Winner Take All),即在视差搜索范围内选择累积代价最优的点作为对应匹配点,与之对应的视差即为所求的视差。
NCC (Normalized Cross correlation,归一化互相关):
NCC(u,v) = [(wl - w)/(|wl - w|)]*[(wr - w)/(|wr - w|)]
SSD (Sum of Squared Defferences,差值平方和):
SSD(u,v) = Sum{[Left(u,v) - Right(u,v)] * [Left(u,v) - Right(u,v)]}
SAD (Sum of Absolute Defferences,绝对差值和) :
SAD(u,v) = Sum{|Left(u,v) - Right(u,v)|}
STAD (Sum of Truncated Absolute Differences,截断绝对差值和):
![]()
SAD算法的基本流程:
1.构造一个小窗口,类似与卷积核。
2.用窗口覆盖左边的图像,选择出窗口覆盖区域内的所有像素点。
3.同样用窗口覆盖右边的图像并选择出覆盖区域的像素点。
4.左边覆盖区域减去右边覆盖区域,并求出所有像素点差的绝对值的和。
5.移动右边图像的窗口,重复3,4的动作。(这里有个搜索范围,超过这个范围跳出)
6.找到这个范围内SAD值最小的窗口,即找到了左边图像的最佳匹配的像素块。
4)后处理(Post Process)
一般的,分别以左右两图为参考图像,完成上述三个步骤后可以得到左右两幅视差图。但所得的视差图还存在一些问题,如遮挡点视差不准确、噪声点、误匹配点等存在,因此还需要对视差图进行优化,采用进一步执行后处理步骤对视差图进行修正。常用的方法有插值(Interpolation)、亚像素增强(Subpixel Enhancement)、精细化(Refinement)、图像滤波(Image Filtering)、图像分割等操作。
立体匹配的后续处理:左右检测+遮挡填充+中值滤波
立体匹配算法,尤其是针对CPU实时处理的高度优化算法,在具有挑战性的序列上往往会出现相当多的错误。这些误差通常集中在均匀的无纹理区域、半遮挡区域和近深度不连续区域。处理立体匹配错误的一种方法是使用各种技术来检测潜在的不准确的视差值并使其失效,从而使视差图成为半稀疏的。在StereoBM和StereoSGBM算法中已经实现了一些这样的技术。另一种方法是使用某种过滤程序将视差图的边缘与源图像的边缘对齐,并将视差值从高可信区域传播到低可信区域(如半遮挡)。最近在边缘感知过滤方面的进展使得在CPU实时处理的约束下能够执行这种后过滤。
后处理(post-processing)措施中最常用的是左右一致性检测(Left-Right Consistency (LRC) check)。左右检测对实验效果的提升是很显著的,无论是视差图的视觉效果还是数据精度。很多时候LRC都是论文的遮羞布,在论文主体部分优势不明显的情况下,通过LRC依然能得到过得去的结果,从而掩盖了核心算法的孱弱。
左右一致性检测的作用是实现遮挡检测,得到左图对应的遮挡图像。具体做法:
根据左右两幅输入图像,分别得到左右两幅视差图。对于左图中的一个点p,求得的视差值是d1,那么p在右图里的对应点应该是(p-d1),(p-d1)的视差值记作d2。若|d1-d2|>threshold,p标记为遮挡点(occluded point)。
遮挡(Occlusion)是只出现在一幅图像而在另一幅图中看不到的那些点。在立体匹配算法中如果不针对遮挡区域做一些特殊处理是不可能通过单幅图提供的有限信息得到遮挡点的正确视差。遮挡点通常是一块连续的区域,记作occluded region/area。
如下依次是:左图,左图对应的二值遮挡图,左视差图,右视差图。


得到二值遮挡图之后是为所有黑色的遮挡点赋予合理的视差值。对于左图而言,遮挡点一般存在于背景区域和前景区域接触的地方。遮挡的产生正是因为前景比背景的偏移量更大,从而将背景遮盖。具体赋值方法是:对于一个遮挡点p,分别水平往左和往右找到第一个非遮挡点,记作pl、pr。点p的视差值赋成pl与pr的视差值中较小的那一个。d(p)= min (d(pl),d(pr)) (被遮挡的像素具有背景的深度)。

这种简单的遮挡填充方法在遮挡区域赋值方面效果显著,但是对初始视差的合理性和精度依赖较高。而且会出现类似于动态规划算法的水平条纹,所以其后常常跟着一个中值滤波(Median Filtering)步骤以消除条纹。
下图是中值滤波的结果:

这样,通过LRC check检测出遮挡点,对其进行视差估计,再对整幅图做中值滤波,得到的结果就好多了。[官网示例]
[代码]
num = 5
blockSize = 13
stereo_sgbm = cv2.StereoSGBM_create(
minDisparity=0, numDisparities=16 * num, blockSize=blockSize,
P1=8 * 3 * blockSize * blockSize, P2=32 * 3 * blockSize * blockSize, disp12MaxDiff=20,
preFilterCap=15, uniquenessRatio=0, speckleWindowSize=100, speckleRange=2,
mode=cv2.STEREO_SGBM_MODE_SGBM_3WAY)
# 新版opencv中没有ximgproc模块包(pip install opencv-contrib-python==3.4.2.16)
stereo_sgbm_right_matcher = cv2.ximgproc.createRightMatcher(stereo_sgbm)
# DisparityWLSFilter:基于加权最小二乘滤波的视差图滤波(以快速全局平滑的形式,比传统的加权最小二乘滤波实现快得多),并可选地使用基于左右一致性的置信度来细化半遮挡和均匀区域的结果
wls_filter = cv2.ximgproc.createDisparityWLSFilter(matcher_left=stereo_sgbm)
# Lambda是一个定义过滤期间正则化数量的参数。较大的值会迫使经过过滤的视差图边缘与源图像边缘粘连得更紧。典型值为8000。
wls_filter.setLambda(8000)
# SigmaColor定义了滤波过程对源图像边缘的敏感度。较大的值会通过低对比度边缘导致视差泄漏。较小的值会使过滤器对源图像中的噪声和纹理过于敏感。典型的值范围从0.8到2.0。
wls_filter.setSigmaColor(1.2)
# 将图片置为灰度图
gray_L = cv2.cvtColor(img1_rectified, cv2.COLOR_BGR2GRAY)
gray_R = cv2.cvtColor(img2_rectified, cv2.COLOR_BGR2GRAY)
# 计算视差: 根据SGBM方法生成差异图
disparity_left = stereo_sgbm.compute(gray_L, gray_R)
disparity_right = stereo_sgbm_right_matcher.compute(gray_R,gray_L)
disparity_left = np.int16(disparity_left)
disparity_right = np.int16(disparity_right)
# 视差图后处理
disparity_filtered = wls_filter.filter(disparity_left, gray_L, None, disparity_right)
# 将图片扩展至3d空间中,其z方向的值则为当前的距离;
# 通过reprojectImageTo3D这个函数将视差矩阵转换成实际的物理坐标矩阵,获取世界坐标
threeD = cv2.reprojectImageTo3D(disparity_filtered.astype(np.float32) / 16.0, Q)*2.8346
# threeD = cv2.reprojectImageTo3D(disparity_left.astype(np.float32) / 16.0, Q)*2.8346
# 获取深度图
disp_filtered = cv2.normalize(src=disparity_filtered, dst=disparity_filtered, alpha=255,
beta=0, norm_type=cv2.NORM_MINMAX)
disp_filtered = np.uint8(disp_filtered)
cv2.imshow("depth", disp_filtered)立体匹配综合论文集 : http://download.csdn.net/detail/wangyaninglm/9591251
基于图像分割的立体匹配论文合集 : http://download.csdn.net/detail/wangyaninglm/9591253
并行立体匹配论文合集 : http://download.csdn.net/detail/wangyaninglm/9591255
基于置信传播的立体匹配论文合集 : http://download.csdn.net/detail/wangyaninglm/9591256
基于稠密匹配的论文合集: http://download.csdn.net/detail/wangyaninglm/9591259
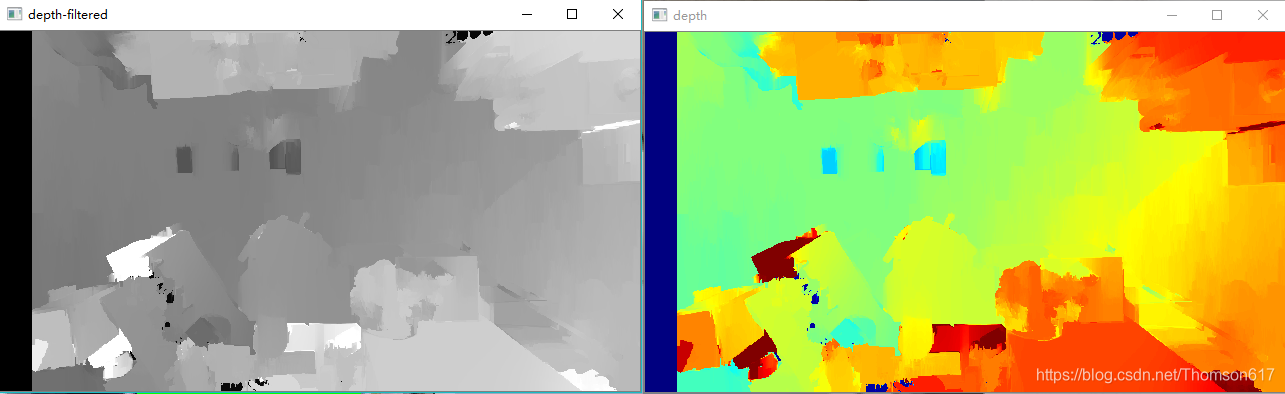
使用applyColorMap(伪彩色函数)给深度图上色
applyColorMap(src, colormap, dst=None):在给定的图像上(可以是灰度图像,单通道或3通道图像)应用GNU Octave/MATLAB的等效颜色映射,产生伪彩色图像。
OpenCV中定义了20种colormap(色度图),经常用伪彩色将高度、压力、密度、温度、湿度等图像更好地显示。参数colormap取值如下所示:

# disp_color=cv2.applyColorMap(cv2.convertScaleAbs(disp_filtered,alpha=1),cv2.COLORMAP_JET)
disp_color=cv2.applyColorMap(disp_filtered,cv2.COLORMAP_JET)
cv2.imshow("depth", disp_color)效果如下(左:上色前; 右:上色后):
45.6双目测距
距离公式: Z = f * T / D
f为左摄像头在x方向的焦距,单位是像素; T(双目标定的平移向量Tx的绝对值)为左右相机基线长度; D为同一个点在左右两图像中的视差。D=xl-xr,单位也是像素。
(代码部分不做分享,有问题尽管留言)!!!
因篇幅过长,剩余部分参见:OpenCV-Python (官方)中文教程(部分四)

















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









