







文章目录
一、基础
1.什么是数据结构?
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
2.什么是算法?
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。
3.时间复杂度
在计算机科学中,时间复杂性,又称时间复杂度,算法的时间复杂度是一个函数,它定性描述该算法的运行时间。这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数。使用这种方式时,时间复杂度可被称为是渐近的,亦即考察输入值大小趋近无穷时的情况。

4.空间复杂度
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。比如直接插入排序的时间复杂度是O(n^2),空间复杂度是O(1) 。而一般的递归算法就要有O(n)的空间复杂度了,因为每次递归都要存储返回信息。一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量。
二 、排序(API设计)
1. Comparable接口
题目:
定义一个学生类,通过Comparable接口提供比较规则
package study.demo;
/**
定义一个学生类,通过Comparable接口提供比较规则
*/
public class ComparableStudent implements Comparable<ComparableStudent>{
private Integer age;
private String student;
public ComparableStudent(Integer age, String student) {
this.age = age;
this.student = student;
}
public ComparableStudent() {
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getStudent() {
return student;
}
public void setStudent(String student) {
this.student = student;
}
@Override
public String toString() {
return "ComparableStudent{" +
"age=" + age +
", student='" + student + '\'' +
'}';
}
/**
* 定义比较规则
* @param o
* @return
*/
public int compareTo(ComparableStudent o) {
System.out.println(this.age);//18
System.out.println(o.age);//15
System.out.println(this.age-o.age);//3
return this.age-o.age;
}
/**
* 定义比较方法:
* ① 如果result>0 c1>c2
* ② 如果result<0 c1<c2
* ③ 如果result=0 c1=c2
*/
static Comparable getMax(Comparable c1,Comparable c2 ){
int result=c1.compareTo(c2);//谁在前,谁为本类对象
if(result>=0){
return c1;
}else {
return c2;
}
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
ComparableStudent c1 = new ComparableStudent(18, "小红");
ComparableStudent c2 = new ComparableStudent(15, "小名");
//输出最大的值
//比较方法:comparable
Comparable max=getMax(c1,c2);
System.out.println(max);
/*
结果:
ComparableStudent{age=18, student='小红'}
*/
}
}
2.冒泡排序(Bubble Sort)
2.1 排序原理:
a.比较相邻的元素,如果前一个元素比后一个元素大,就交换这两个元素的位置。
b.对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对元素。最终最后位置的元素就是最大值。
2.2 时间复杂度分析
总执行次数:N^2-N
时间复杂度:O(N^2)
2.3 程序代码
package study.demo;
import java.util.Arrays;
/**
* 冒泡排序
*/
public class Bubble {
/**
对数组a中的元素进行排序
*/
public static void sort(Comparable[] a){
for(int i=a.length-1;i>0;i--){
for(int j=0;j<i;j++){
//{6,5,4,3,2,1}
//比较索引j和索引j+1处的值
if (greater(a[j],a[j+1])){
exch(a,j,j+1);
}
}
}
}
/**
比较v元素是否大于w元素
*/
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
/**
数组元素i和j交换位置
*/
private static void exch(Comparable[] a,int i,int j){
Comparable temp;
temp = a[i];
a[i]=a[j];
a[j]=temp;
}
/**
* 测试程序
* @param args
*/
public static void main(String[] args) {
Integer[] arr = {4,5,6,3,2,1};
Bubble.sort(arr);
System.out.println(Arrays.toString(arr));//{1,2,3,4,5,6}
}
}
3.选择排序(Selection sort)
3.1 排序原理
a.每次遍历的过程中,都假定第一个索引处的元素是最小值,和其他索引处的值依次进行比较,如果当前索引处的值大于其他某个索引出的值为最小值,最后可以找到最小值所在的索引。
b.交换第一个索引处和最小值所在的索引处的值。
3.2 时间复杂度分析
总执行次数:N^2/2+N/2-1
时间复杂度:O(N^2)
3.3 程序代码
package study.sort;
import java.util.Arrays;
/**
* 选择排序
*/
public class Selection {
/**
对数组a中的元素进行排序
*/
public static void sort(Comparable[] a){
for(int i=0;i<=a.length-2;i++){
//定义一个变量,记录最小元素所在的索引,默认为参与选择排序的第一个元素所在的位置
int minIndex = i;
for(int j=i+1;j<a.length;j++){
//需要比较最小索引minIndex处的值和j索引处的值;
if (greater(a[minIndex],a[j])){
minIndex=j;
}
}
//交换最小元素所在索引minIndex处的值和索引i处的值
exch(a,i,minIndex);
}
}
/**
比较v元素是否大于w元素
*/
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
/**
数组元素i和j交换位置
*/
private static void exch(Comparable[] a,int i,int j){
Comparable temp;
temp = a[i];
a[i]=a[j];
a[j]=temp;
}
/**
* 测试
*/
public static void main(String[] args) {
//原始数据
Integer[] a = {4,6,8,7,9,2,10,1};
Selection.sort(a);
System.out.println(Arrays.toString(a));
//{1,2,4,5,7,8,9,10}
}
}
4 .插入排序(Insertion sort)
4.1 排序原理(扑克牌)
a.把所有的元素分为两组,已经排序和未排序的。
b.找到未排序的组中的第一个元素,向已经排序的组中进行插入。
c.倒序遍历已经排序的元素,依次和待插入的元素进行比较,直到找到一个元素小于等于待插入元素,那么就把待插入元素放到这个位置,其他元素向后移动一位。
4.2 时间复杂度
总执行次数:N^2-N
时间复杂度:O(N^2)
4.3 程序代码:
package study.sort;
import java.util.Arrays;
/**
* 插入排序
*/
public class Insertion {
/**
对数组a中的元素进行排序
*/
public static void sort(Comparable[] a){
for(int i=1;i<a.length;i++){
for(int j=i;j>0;j--){
//比较索引j处的值和索引j-1处的值,如果索引j-1处的值比索引j处的值大,则交换数据,如果不大,那么就找到合适的位置了,退出循环即可;
if (greater(a[j-1],a[j])){
exch(a,j-1,j);
}else{
break;
}
}
}
}
/**
比较v元素是否大于w元素
*/
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
/**
数组元素i和j交换位置
*/
private static void exch(Comparable[] a,int i,int j){
Comparable temp;
temp = a[i];
a[i]=a[j];
a[j]=temp;
}
/**
* 测试
*/
public static void main(String[] args) {
Integer[] a = {4,3,2,10,12,1,5,6};
Insertion.sort(a);
System.out.println(Arrays.toString(a));
//{1,2,3,4,5,6,10,12}
}
}
以上三种时间复杂度均为平方阶,随着输入规模的增大,时间成本将急剧上升,不能处理更大规模的问题。
高级排序
5. 希尔排序(shell sort)(插入排序)
希尔排序是插入排序的一种,又称"缩小增量排序",是插入排序的更高效的改进版本。
5.1 排序原理
a.选定一个增长量h,按照增长量h作为数据分组的依据,对数据进行分组;
b.对分好组的每一组数据完成插入排序;
c.减少增长量,最少减为1,重复第二步操作。
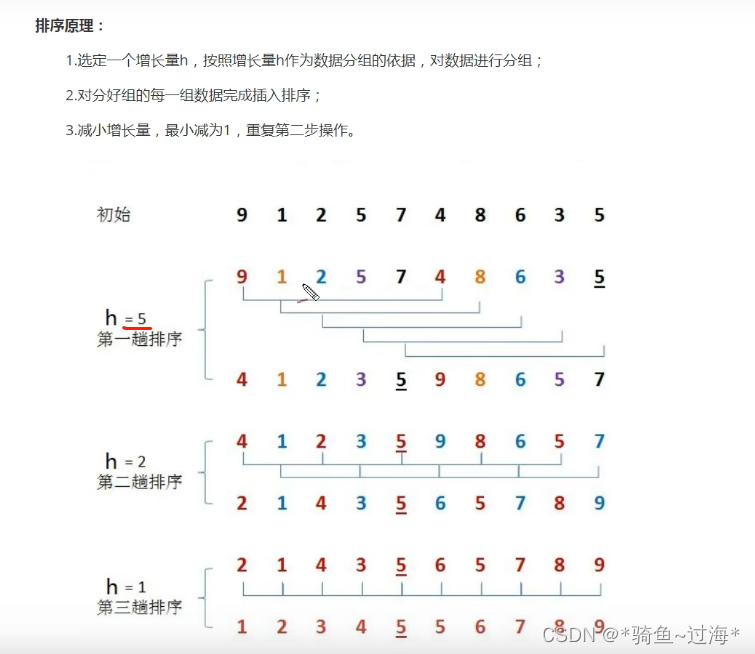
5.2 程序代码
package study.sort;
import java.util.Arrays;
/**
* 希尔排序
*/
public class Shell {
/**
* 对数据a中的元素进行排序
*/
public static void sort(Comparable[] a){
//1.根据数组a的长度,确定增长量h的初始值
int h=1;
while(h<a.length/2){
h=2*h+1;
}
//减少的规则 h=h/2
while(h>=1){
//排序
//找到待插入的元素
for(int i=h;i<a.length;i++){
//把待插入的元素插入到有序数组中
for(int j=i;j>=h;j-=h){
if(greater(a[j-h],a[j])){
exch(a,j-h,j);//为int类型,而a为Comparable类型
}else {
//待插入元素已经找到了合适的位置,结束循环;
break;//break语句对if-else的条件语句不起作用,跳出的是for循环
}
}
}
h=h/2;
}
}
/**
* 比较v元素是否大于w的元素
*
*/
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
/**
* 交换元素
*
*/
private static void exch(Comparable[] a,int i,int j){
//定义临时变量
Comparable temp;
temp=a[i];
a[i]=a[j];
a[j]=temp;
}
/**
* 测试希尔排序
*/
public static void main(String[] args) {
Integer arr[] ={1,5,7,1,8,56,1,78,16,95,188,188,11,566};
//放进接口排序,Comparable只针对对象排序
sort(arr);
//打印输出数组
System.out.println(Arrays.toString(arr));
}
}
6. 归并排序(Merge sort)
6.1 递归
定义:定义方法时,在方法内部调用方法本身,称之为递归。
作用:它通常把一个大型复杂的问题,层层转换为一个与原问题相似的,规模较小的问题来求解。递归策略只需要少量程序即可描述出解题过程所需要的多次重复计算,大大的减少了程序的代码量。但是,必须有边界条件,否则递归的层级太深,容易造成栈内存溢出。
public static void show(){
System.out.println("递归");
show();
}
6.2 递归实现N的阶乘-N!
public static Integer factorial(int n){
if(n==1){
return 1;
}
return n*factorial(n-1);
}
(超过23就会溢出)
归并排序
6.3 排序原理
定义:将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若两个有序表合并成一个有序表,称为二路归并。
原理:
a.尽可能的一组数据拆分成两个元素相等的子组,并对每一个子组继续拆分,直到拆分后的每个子组的元素个数是1为止。
b.将相邻的两个子组进行合并成一个有序的大组。
c.不断地重复步骤b,直到最终只有一个组为止。
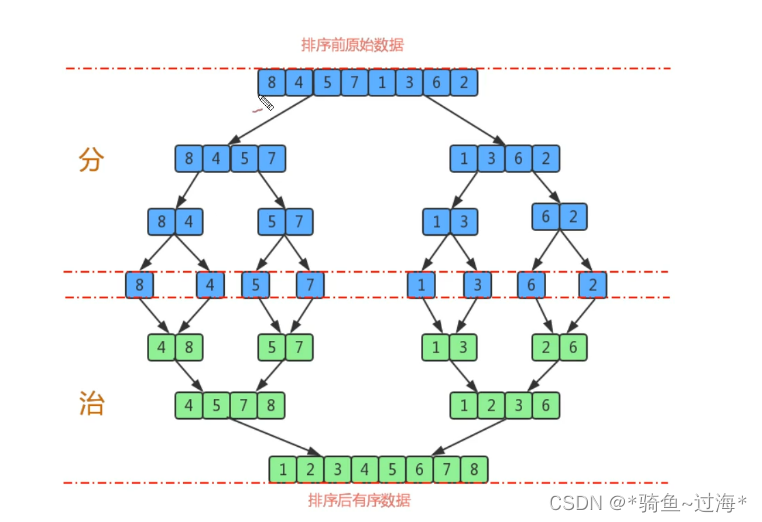
6.4 时间复杂度

6.5 代码实现
package study.sort;
import java.util.Arrays;
/**
* 归并排序
*/
public class MergeSort {
/**
* 1. 递归(recursion):调用方法本身
*/
public static void show(){
System.out.println("递归");
show();
}
/**
* 递归算法实现N的阶乘 N!
*/
public static Integer factorial(int n){
if(n==1){
return 1;
}
return n*factorial(n-1);
}
/**
归并所需要的辅助数组
*/
private static Comparable[] assist;
/**
比较v元素是否小于w元素
*/
private static boolean less(Comparable v, Comparable w) {
return v.compareTo(w)<0;
}
/**
数组元素i和j交换位置
*/
private static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
/**
对数组a中的元素进行排序
*/
public static void sort(Comparable[] a) {
//1.初始化辅助数组assist;
assist = new Comparable[a.length];
//2.定义一个lo变量,和hi变量,分别记录数组中最小的索引和最大的索引;
int lo=0;
int hi=a.length-1;
//3.调用sort重载方法完成数组a中,从索引lo到索引hi的元素的排序
sort(a,lo,hi);
}
/**
对数组a中从lo到hi的元素进行排序
*/
private static void sort(Comparable[] a, int lo, int hi) {
//做安全性校验;
if (hi<=lo){
return;
}
//对lo到hi之间的数据进行分为两个组
int mid = lo+(hi-lo)/2;// 5,9 mid=7
//分别对每一组数据进行排序
sort(a,lo,mid);
sort(a,mid+1,hi);
//再把两个组中的数据进行归并
merge(a,lo,mid,hi);
}
//1、重载是指不同的函数使用相同的函数名,但是函数的参数个数或类型不同。调用的时候根据函数的参数来区别不同的函数。
//
//2、覆盖(也叫重写)是指在派生类中重新对基类中的虚函数(注意是虚函数)重新实现。即函数名和参数都一样,只是函数的实现体不一样。
/**
(重载) 对数组中,从lo到mid为一组,从mid+1到hi为一组,对这两组数据进行归并
*/
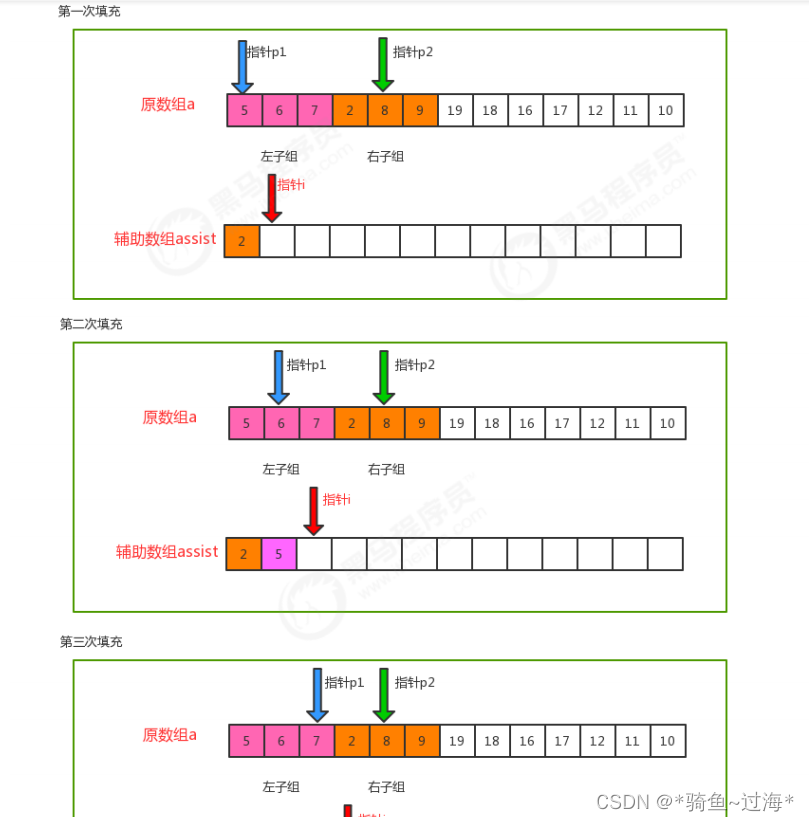
private static void merge(Comparable[] a, int lo, int mid, int hi) {
//定义三个指针
int i=lo;
int p1=lo;
int p2=mid+1;
//遍历,移动p1指针和p2指针,比较对应索引处的值,找出小的那个,放到辅助数组的对应索引处
while(p1<=mid && p2<=hi){
//比较对应索引处的值
if (less(a[p1],a[p2])){
assist[i++] = a[p1++];
}else{
assist[i++]=a[p2++];
}
}
//遍历,如果p1的指针没有走完,那么顺序移动p1指针,把对应的元素放到辅助数组的对应索引处
while(p1<=mid){
assist[i++]=a[p1++];
}
//遍历,如果p2的指针没有走完,那么顺序移动p2指针,把对应的元素放到辅助数组的对应索引处
while(p2<=hi){
assist[i++]=a[p2++];
}
//把辅助数组中的元素拷贝到原数组中
for(int index=lo;index<=hi;index++){
a[index]=assist[index];
}
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer a[]={1,55,155,1185,11,89,11,99,1,99,1,96,6,19,78};
MergeSort.sort(a);
System.out.println(Arrays.toString(a));
//实现N的阶乘-超过23就会溢出
System.out.println(factorial(23));
}
}
7. 快速排序(Quick sort)
7.1 排序原理
1.首先设定一个分界值,通过该分界值将数组分成左右两部分;
2.将大于或等于分界值的数据放到到数组右边,小于分界值的数据放到数组的左边。此时左边部分中各元素都小于
或等于分界值,而右边部分中各元素都大于或等于分界值;
3.然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两
部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
4.重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当
左侧和右侧两个部分的数据排完序后,整个数组的排序也就完成了。
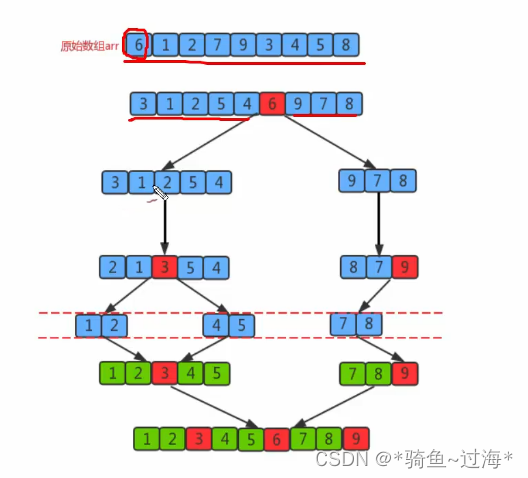
7.2 切分原理
切分原理:
把一个数组切分成两个子数组的基本思想:
1.找一个基准值,用两个指针分别指向数组的头部和尾部;
2.先从尾部向头部开始搜索一个比基准值小的元素,搜索到即停止,并记录指针的位置;
3.再从头部向尾部开始搜索一个比基准值大的元素,搜索到即停止,并记录指针的位置;
4.交换当前左边指针位置和右边指针位置的元素;
5.重复2,3,4步骤,直到左边指针的值大于右边指针的值停止。
7.4 实现代码
package study.sort;
import java.util.Arrays;
/**
* 快速排序
*/
public class Quick {
/**
比较v元素是否小于w元素
*/
private static boolean less(Comparable v, Comparable w) {
return v.compareTo(w) < 0;
}
/**
数组元素i和j交换位置
*/
private static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
//对数组内的元素进行排序
public static void sort(Comparable[] a) {
int lo = 0;
int hi = a.length-1;
sort(a,lo,hi);
}
//对数组a中从索引lo到索引hi之间的元素进行排序
private static void sort(Comparable[] a, int lo, int hi) {
//安全性校验
if (hi<=lo){
return;
}
//需要对数组中lo索引到hi索引处的元素进行分组(左子组和右子组);
int partition = partition(a, lo, hi);//返回的是分组的分界值所在的索引,分界值位置变换后的索引
//让左子组有序
sort(a,lo,partition-1);
//让右子组有序
sort(a,partition+1,hi);
}
//对数组a中,从索引 lo到索引 hi之间的元素进行分组,并返回分组界限对应的索引
public static int partition(Comparable[] a, int lo, int hi) {
//确定分界值
Comparable key = a[lo];
//定义两个指针,分别指向待切分元素的最小索引处和最大索引处的下一个位置
int left=lo;
int right=hi+1;
//切分
while(true){
//先从右往左扫描,移动right指针,找到一个比分界值小的元素,停止
while(less(key,a[--right])){
if (right==lo){
break;
}
}
//再从左往右扫描,移动left指针,找到一个比分界值大的元素,停止
while(less(a[++left],key)){
if (left==hi){
break;
}
}
//判断 left>=right,如果是,则证明元素扫描完毕,结束循环,如果不是,则交换元素即可
if (left>=right){
break;
}else{
exch(a,left,right);
}
}
//交换分界值
exch(a,lo,right);
return right;
}
public static void main(String[] args) {
Integer[] a = {4,6,8,7,9,2,10,1};
System.out.println(a);这样输出的是数组的首地址,而不能打印出数组数据
sort(a);
System.out.println(Arrays.toString(a));//此可打印
}
}
8. 各种排序算法效率比较(重点)
package study.sort;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
/**
* 调用不同的测试方法完成测试(逆排序数据测试)
*/
public class SortComparableEfficiencyTest {
/**
* 冒泡排序
*/
private static void bubbleEfficiency(Integer[] a){
//1. 获取执行前的时间
long start=System.currentTimeMillis();
//2. 执行算法代码
Bubble.sort(a);
//3. 获取执行之后的代码
long end =System.currentTimeMillis();
//4. 算出程序执行的时间并输出
System.out.println("冒泡排序执行的时间为:"+(end-start)+"毫秒");
}
/**
* 选择排序
*/
private static void selectionEfficiency(Integer[] a){
//1. 获取执行前的时间
long start=System.currentTimeMillis();
//2. 执行算法代码
Selection.sort(a);
//3. 获取执行之后的代码
long end =System.currentTimeMillis();
//4. 算出程序执行的时间并输出
System.out.println("选择排序执行的时间为:"+(end-start)+"毫秒");
}
/**
* 插入排序
*/
private static void insertionEfficiency(Integer[] a){
//1. 获取执行前的时间
long start=System.currentTimeMillis();
//2. 执行算法代码
Insertion.sort(a);
//3. 获取执行之后的代码
long end =System.currentTimeMillis();
//4. 算出程序执行的时间并输出
System.out.println("插入排序执行的时间为:"+(end-start)+"毫秒");
}
/**
* 希尔排序
*/
private static void shellEfficiency(Integer[] a){
//1. 获取执行前的时间
long start=System.currentTimeMillis();
//2. 执行算法代码
Shell.sort(a);
//3. 获取执行之后的代码
long end =System.currentTimeMillis();
//4. 算出程序执行的时间并输出
System.out.println("希尔排序执行的时间为:"+(end-start)+"毫秒");
}
/**
* 归并排序
*/
private static void mergeEfficiency(Integer[] a){
//1. 获取执行前的时间
long start=System.currentTimeMillis();
//2. 执行算法代码
MergeSort.sort(a);
//3. 获取执行之后的代码
long end =System.currentTimeMillis();
//4. 算出程序执行的时间并输出
System.out.println("归并排序执行的时间为:"+(end-start)+"毫秒");
}
/**
* 快速排序
*/
private static void quickEfficiency(Integer[] a){
//1. 获取执行前的时间
long start=System.currentTimeMillis();
//2. 执行算法代码
Quick.sort(a);
//3. 获取执行之后的代码
long end =System.currentTimeMillis();
//4. 算出程序执行的时间并输出
System.out.println("快速排序执行的时间为:"+(end-start)+"毫秒");
}
/**
* 效率比较测试
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception{
//1.创建一个ArrayList集合,保存读取出来的整数
ArrayList<Integer> list = new ArrayList<Integer>();
//2.创建缓存读取流BufferReader,读取数据,并缓存到ArrayList中
/*
Class.getClassLoader()是获取当前类的类加载器;
getResourceAsStream()是获取资源的输入流。类加载器默认是从classPath路径加载资源
classpath,顾名思义,就是指 .class 文件所在的路径。.class 文件由 .java 文件编译后产生
classPath:
① src/main/java路径
② src/main/resouces路径
③ 第三方jar包的根路径
*/
BufferedReader reader=new BufferedReader(new InputStreamReader(SortComparableEfficiencyTest.class.getClassLoader().getResourceAsStream("reverse_arr.txt")));
String line;
while ((line=reader.readLine())!=null){
// //line是字符串,把line转换成Integer,存储到集合中
list.add(Integer.valueOf(line));
}
//关闭文件读取
reader.close();
//3.将ArrayList集合转换成数据
//定义一个与数组长度相同的数组
Integer[] a=new Integer[list.size()];
//将list转化成整型数组
list.toArray(a);
//4.调用测试代码完成测试
System.out.println("排序算法效率测试如下:");
//冒泡排序
bubbleEfficiency(a);
//选择排序
selectionEfficiency(a);
//插入排序
insertionEfficiency(a);
//希尔排序
shellEfficiency(a);
//归并排序
mergeEfficiency(a);
//快速排序
quickEfficiency(a);
/**结果如下:
排序算法效率测试如下:
冒泡排序执行的时间为:15796毫秒
选择排序执行的时间为:7043毫秒
插入排序执行的时间为:3毫秒
希尔排序执行的时间为:8毫秒
归并排序执行的时间为:28毫秒
快速排序执行的时间为:3毫秒
*/
}
}
三、线性表
概念:
概念:用一组地址连续的存储单元依次存储线性表的数据元素,这种存储结构的线性表称为顺序表。
特点:逻辑上相邻的数据元素,物理次序也是相邻的。
只要确定好了存储线性表的起始位置,线性表中任一数据元素都可以随机存取,所以线性表的顺序存储结构是一种随机存取的储存结构,因为高级语言中的数组类型也是有随机存取的特性,所以通常我们都使用数组来描述数据结构中的顺序储存结构,用动态分配的一维数组表示线性表。
线性表的分类:
线性表中数据存储的方式可以是顺序存储,也可以是链式存储,按照数据的存储方式不同,可以把线性表分为顺序
表和链表。
1. 顺序表
1.1定义
**概念:**顺序表是在计算机内存中以数组的形式保存的线性表,线性表的顺序存储是指用一组地址连续的存储单元依次存储线性表中的各个元素、使得线性表中在逻辑结构上相邻的数据元素存储在相邻的物理存储单元中,即通过数据元素物理存储的相邻关系来反映数据元素之间逻辑上的相邻关系,采用顺序存储结构的线性表通常称为顺序表。顺序表是将表中的结点依次存放在计算机内存中一组地址连续的存储单元中。
顺序表API设计:
构造方法:
SequenceList(int capacity):创建容量为capacity的SequenceList对象
成员方法
1.public void clear():空置线性表
2.publicboolean isEmpty():判断线性表是否为空,是返回true,否返回false
3.public int length():获取线性表中元素的个数
4.public T get(int i):读取并返回线性表中的第i个元素的值
5.public void insert(int i,T t):在线性表的第i个元素之前插入一个值为t的数据元素。
6.public void insert(T t):向线性表中添加一个元素t
7.public T remove(int i):删除并返回线性表中第i个数据元素。
8.public int indexOf(T t):返回线性表中首次出现的指定的数据元素的位序号,若不存在,则返
回-1。
成员变量
1.private T[] eles:存储元素的数组
2.private int N:当前线性表的长度
1.2 顺序表测试代码
package cn.itcast.algorithm.linear;
import java.util.Iterator;
public class SequenceList<T> implements Iterable<T>{
//存储元素的数组
private T[] eles;
//记录当前顺序表中的元素个数
private int N;
//构造方法
public SequenceList(int capacity){
//初始化数组
this.eles=(T[])new Object[capacity];
//初始化长度
this.N=0;
}
//将一个线性表置为空表
public void clear(){
this.N=0;
}
//判断当前线性表是否为空表
public boolean isEmpty(){
return N==0;
}
//获取线性表的长度
public int length(){
return N;
}
//获取指定位置的元素
public T get(int i){
return eles[i];
}
//向线型表中添加元素t
public void insert(T t){
if (N==eles.length){
resize(2*eles.length);
}
eles[N++]=t;
}
//在i元素处插入元素t
public void insert(int i,T t){
if (N==eles.length){
resize(2*eles.length);
}
//先把i索引处的元素及其后面的元素依次向后移动一位
for(int index=N;index>i;index--){
eles[index]=eles[index-1];
}
//再把t元素放到i索引处即可
eles[i]=t;
//元素个数+1
N++;
}
//删除指定位置i处的元素,并返回该元素
public T remove(int i){
//记录索引i处的值
T current = eles[i];
//索引i后面元素依次向前移动一位即可
for(int index=i;index<N-1;index++){
eles[index]=eles[index+1];
}
//元素个数-1
N--;
if (N<eles.length/4){
resize(eles.length/2);
}
return current;
}
//查找t元素第一次出现的位置
public int indexOf(T t){
for(int i=0;i<N;i++){
if (eles[i].equals(t)){
return i;
}
}
return -1;
}
//根据参数newSize,重置eles的大小
public void resize(int newSize){
//定义一个临时数组,指向原数组
T[] temp=eles;
//创建新数组
eles=(T[])new Object[newSize];
//把原数组的数据拷贝到新数组即可
for(int i=0;i<N;i++){
eles[i]=temp[i];
}
}
@Override
public Iterator<T> iterator() {
return new SIterator();
}
private class SIterator implements Iterator{
private int cusor;
public SIterator(){
this.cusor=0;
}
@Override
public boolean hasNext() {
return cusor<N;
}
@Override
public Object next() {
return eles[cusor++];
}
@Override
public void remove() {
}
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
//创建顺序表对象
SequenceList<String> sl = new SequenceList<String>(10);
//测试插入
sl.insert("姚明");
sl.insert("科比");
sl.insert("麦迪");
sl.insert(1,"詹姆斯");
for (String s : sl) {
System.out.println(s);
}
System.out.println("------------------------------------------");
//测试获取
String getResult = sl.get(1);
System.out.println("获取索引1处的结果为:"+getResult);
//测试删除
String removeResult = sl.remove(0);
System.out.println("删除的元素是:"+removeResult);
//测试清空
sl.clear();
System.out.println("清空后的线性表中的元素个数为:"+sl.length());
}
}
1.3 顺序表的遍历
在java中,遍历集合的方式一般都是用的是foreach循环,如果想让我们的SequenceList也能支持foreach循环,则
需要做如下操作:
1.让SequenceList实现Iterable接口,重写iterator方法;
2.在SequenceList内部提供一个内部类SIterator,实现Iterator接口,重写hasNext方法和next方法;
代码
//顺序表遍历
//测试代码
public static void main(String[] args) throws Exception {
SequenceList<String> squence = new SequenceList<String>(5);
//测试遍历
squence.insert(0, "姚明");
squence.insert(1, "科比");
squence.insert(2, "麦迪"); squence.insert(3, "艾佛森");
squence.insert(4, "卡特");
for (String s : squence)
{ System.out.println(s); } } }
1.4 顺序表的容量可变
1.5 顺序表的时间复杂度
get(i):不难看出,不论数据元素量N有多大,只需要一次eles[i]就可以获取到对应的元素,所以时间复杂度为O(1);
insert(int i,T t):每一次插入,都需要把i位置后面的元素移动一次,随着元素数量N的增大,移动的元素也越多,时
间复杂为O(n);
remove(int i):每一次删除,都需要把i位置后面的元素移动一次,随着数据量N的增大,移动的元素也越多,时间复
杂度为O(n);
由于顺序表的底层由数组实现,数组的长度是固定的,所以在操作的过程中涉及到了容器扩容操作。这样会导致顺
序表在使用过程中的时间复杂度不是线性的,在某些需要扩容的结点处,耗时会突增,尤其是元素越多,这个问题
越明显
1.6 Java中的ArrayList
java中ArrayList集合的底层也是一种顺序表,使用数组实现,同样提供了增删改查以及扩容等功能。
1.是否用数组实现;
是
2.有没有扩容操作;
是
3.有没有提供遍历方式;
是
2.链表
2.1 定义
链表是一种物理存储单元上非连续、非顺序的存储结构。其物理结构不能只管的表示数据元素的逻辑顺序,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表有一系列的结点(链表中的每一个元素成称为结点)组成,结点可以在运行时动态生成。
.2.2单向链表
定义:单向链表是链表中的一种,它由多个结点组成,每个结点都由一个数据域和一个指针域组成,数据域用来存储数据,指针域用来指向其后继结点。链表的头结点的数据域不存储数据,指针域指向第一个真正存储数据的结点。
.API设计

.代码实现
package cn.itcast.algorithm.linear;
import java.util.Iterator;
public class LinkList<T> implements Iterable<T>{
//记录头结点
private Node head;
//记录链表的长度
private int N;
//结点类
private class Node {
//存储数据
T item;
//下一个结点
Node next;
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
public LinkList() {
//初始化头结点、
this.head = new Node(null,null);
//初始化元素个数
this.N=0;
}
//清空链表
public void clear() {
head.next=null;
this.N=0;
}
//获取链表的长度
public int length() {
return N;
}
//判断链表是否为空
public boolean isEmpty() {
return N==0;
}
//获取指定位置i出的元素
public T get(int i) {
//通过循环,从头结点开始往后找,依次找i次,就可以找到对应的元素
Node n = head.next;
for(int index=0;index<i;index++){
n=n.next;
}
return n.item;
}
//向链表中添加元素t
public void insert(T t) {
//找到当前最后一个结点
Node n = head;
while(n.next!=null){
n=n.next;
}
//创建新结点,保存元素t
Node newNode = new Node(t, null);
//让当前最后一个结点指向新结点
n.next=newNode;
//元素的个数+1
N++;
}
//向指定位置i出,添加元素t
public void insert(int i, T t) {
//找到i位置前一个结点
Node pre = head;
for(int index=0;index<=i-1;index++){
pre=pre.next;
}
//找到i位置的结点
Node curr = pre.next;
//创建新结点,并且新结点需要指向原来i位置的结点
Node newNode = new Node(t, curr);
//原来i位置的前一个节点指向新结点即可
pre.next=newNode;
//元素的个数+1
N++;
}
//删除指定位置i处的元素,并返回被删除的元素
public T remove(int i) {
//找到i位置的前一个节点
Node pre = head;
for(int index=0;index<=i-1;i++){
pre=pre.next;
}
//要找到i位置的结点
Node curr = pre.next;
//找到i位置的下一个结点
Node nextNode = curr.next;
//前一个结点指向下一个结点
pre.next=nextNode;
//元素个数-1
N--;
return curr.item;
}
//查找元素t在链表中第一次出现的位置
public int indexOf(T t) {
//从头结点开始,依次找到每一个结点,取出item,和t比较,如果相同,就找到了
Node n = head;
for(int i=0;n.next!=null;i++){
n=n.next;
if (n.item.equals(t)){
return i;
}
}
return -1;
}
@Override
public Iterator<T> iterator() {
return new LIterator();
}
private class LIterator implements Iterator{
private Node n;
public LIterator(){
this.n=head;
}
@Override
public boolean hasNext() {
return n.next!=null;
}
@Override
public Object next() {
n = n.next;
return n.item;
}
}
//用来反转整个链表
public void reverse(){
//判断当前链表是否为空链表,如果是空链表,则结束运行,如果不是,则调用重载的reverse方法完成反转
if (isEmpty()){
return;
}
reverse(head.next);
}
//反转指定的结点curr,并把反转后的结点返回
public Node reverse(Node curr){
if (curr.next==null){
head.next=curr;
return curr;
}
//递归的反转当前结点curr的下一个结点;返回值就是链表反转后,当前结点的上一个结点
Node pre = reverse(curr.next);
//让返回的结点的下一个结点变为当前结点curr;
pre.next=curr;
//把当前结点的下一个结点变为null
curr.next=null;
return curr;
}
}
2.3 双向链表
.定义
双向链表也叫双向表,是链表的一种,它由多个结点组成,每个结点都由一个数据域和两个指针域组成,数据域用来存储数据,其中一个指针域用来指向其后继结点,另一个指针域用来指向前驱结点。链表的头结点的数据域不存储数据,指向前驱结点的指针域值为null,指向后继结点的指针域指向第一个真正存储数据的结点。
.API设计
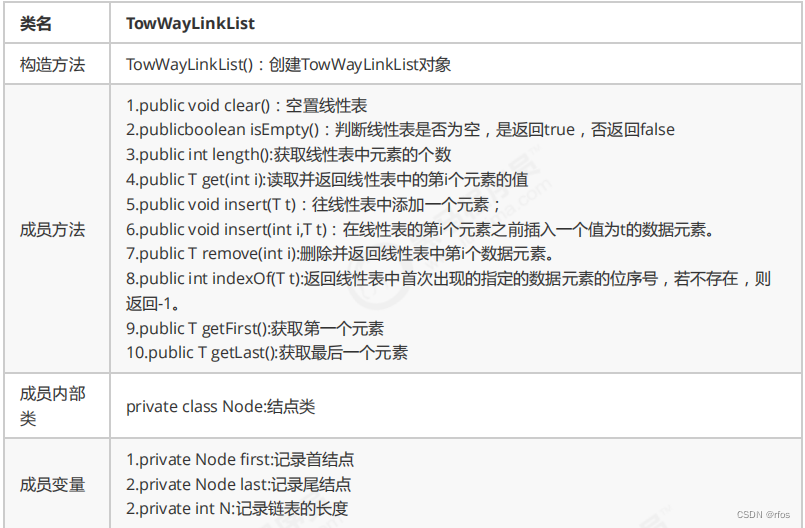
.2.4 代码实现
package cn.itcast.algorithm.linear;
import java.util.Iterator;
/**
* 双向链表实现
* @param <T>
*/
public class TowWayLinkList<T> implements Iterable<T> {
//首结点
private Node head;
//最后一个结点
private Node last;
//链表的长度
private int N;
//结点类
private class Node{
public Node(T item, Node pre, Node next) {
this.item = item;
this.pre = pre;
this.next = next;
}
//存储数据
public T item;
//指向上一个结点
public Node pre;
//指向下一个结点
public Node next;
}
public TowWayLinkList() {
//初始化头结点和尾结点
this.head = new Node(null,null,null);
this.last=null;
//初始化元素个数
this.N=0;
}
//清空链表
public void clear(){
this.head.next=null;
this.head.pre=null;
this.head.item=null;
this.last=null;
this.N=0;
}
//获取链表长度
public int length(){
return N;
}
//判断链表是否为空
public boolean isEmpty(){
return N==0;
}
//获取第一个元素
public T getFirst(){
if (isEmpty()){
return null;
}
return head.next.item;
}
//获取最后一个元素
public T getLast(){
if (isEmpty()){
return null;
}
return last.item;
}
//插入元素t
public void insert(T t){
if (isEmpty()){
//如果链表为空:
//创建新的结点
Node newNode = new Node(t,head, null);
//让新结点称为尾结点
last=newNode;
//让头结点指向尾结点
head.next=last;
}else {
//如果链表不为空
Node oldLast = last;
//创建新的结点
Node newNode = new Node(t, oldLast, null);
//让当前的尾结点指向新结点
oldLast.next=newNode;
//让新结点称为尾结点
last = newNode;
}
//元素个数+1
N++;
}
//向指定位置i处插入元素t
public void insert(int i,T t){
//找到i位置的前一个结点
Node pre = head;
for(int index=0;index<i;index++){
pre=pre.next;
}
//找到i位置的结点
Node curr = pre.next;
//创建新结点
Node newNode = new Node(t, pre, curr);
//让i位置的前一个结点的下一个结点变为新结点
pre.next=newNode;
//让i位置的前一个结点变为新结点
curr.pre=newNode;
//元素个数+1
N++;
}
//获取指定位置i处的元素
public T get(int i){
Node n = head.next;
for(int index=0;index<i;index++){
n=n.next;
}
return n.item;
}
//找到元素t在链表中第一次出现的位置
public int indexOf(T t){
Node n = head;
for(int i=0;n.next!=null;i++){
n=n.next;
if (n.next.equals(t)){
return i;
}
}
return -1;
}
//删除位置i处的元素,并返回该元素
public T remove(int i){
//找到i位置的前一个结点
Node pre = head;
for(int index=0;index<i;index++){
pre=pre.next;
}
//找到i位置的结点
Node curr = pre.next;
//找到i位置的下一个结点
Node nextNode= curr.next;
//让i位置的前一个结点的下一个结点变为i位置的下一个结点
pre.next=nextNode;
//让i位置的下一个结点的上一个结点变为i位置的前一个结点
nextNode.pre=pre;
//元素的个数-1
N--;
return curr.item;
}
@Override
public Iterator<T> iterator() {
return new TIterator();
}
private class TIterator implements Iterator{
private Node n;
public TIterator(){
this.n=head;
}
@Override
public boolean hasNext() {
return n.next!=null;
}
@Override
public Object next() {
n=n.next;
return n.item;
}
}
}
.2.3 链表的复杂度分析
get(int i):每一次查询,都需要从链表的头部开始,依次向后查找,随着数据元素N的增多,比较的元素越多,时间复杂度为O(n)
insert(int i,T t):每一次插入,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n);
remove(int i):每一次移除,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n)相比较顺序表,链表插入和删除的时间复杂度虽然一样,但仍然有很大的优势,因为链表的物理地址是不连续的,它不需要预先指定存储空间大小,或者在存储过程中涉及到扩容等操作,同时它并没有涉及的元素的交换。相比较顺序表,链表的查询操作性能会比较低。因此,如果我们的程序中查询操作比较多,建议使用顺序表,增删
操作比较多,建议使用链表。
.2.4 链表反转(面试的高频题目)
单链表的反转,是面试中的一个高频题目。
需求:
原链表中数据为:1->2->3>4
反转后链表中数据为:4->3->2->1
反转API: public void reverse():对整个链表反转 public Node reverse(Node curr):反转链表中的某个结点curr,并把反转后的curr结点返回
使用递归可以完成反转,递归反转其实就是从原链表的第一个存数据的结点开始,依次递归调用反转每一个结点,直到把最后一个结点反转完毕,整个链表就反转完毕。
.实现代码
//用来反转整个链表
public void reverse(){
//判断当前链表是否为空链表,如果是空链表,则结束运行,如果不是,则调用重载的reverse方法完成反转
if (isEmpty()){
return;
}
reverse(head.next);
}
//反转指定的结点curr,并把反转后的结点返回
public Node reverse(Node curr){
if (curr.next==null){
head.next=curr;
return curr;
}
//递归的反转当前结点curr的下一个结点;返回值就是链表反转后,当前结点的上一个结点
Node pre = reverse(curr.next);
//让返回的结点的下一个结点变为当前结点curr;
pre.next=curr;
//把当前结点的下一个结点变为null
curr.next=null;
return curr;
}
.2.5快慢指针
快慢指针指的是定义两个指针,这两个指针的移动速度一块一慢,以此来制造出自己想要的差值,这个差值可以然我们找到链表上相应的结点。一般情况下,快指针的移动步长为慢指针的两倍。
.中间值问题
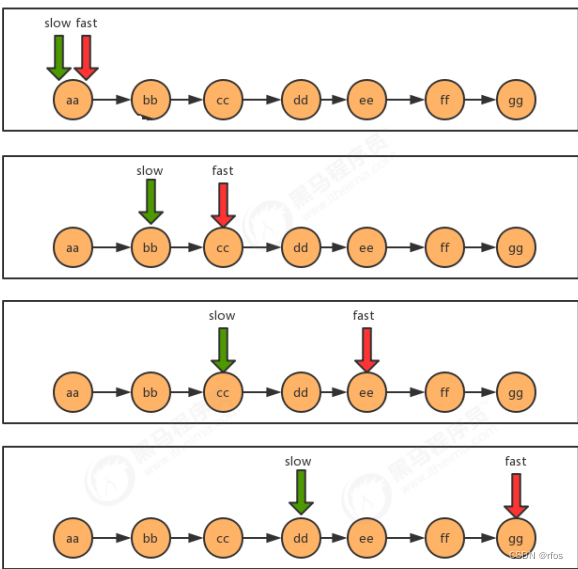
代码实现:
/*** @param first 链表的首结点 * @return 链表的中间结点的值 */
public static String getMid(Node<String> first) {
Node<String> slow = first;
Node<String> fast = first;
while(fast!=null && fast.next!=null){
fast=fast.next.next; slow=slow.next;
}
return slow.item;
}
.单向链表是否有环问题
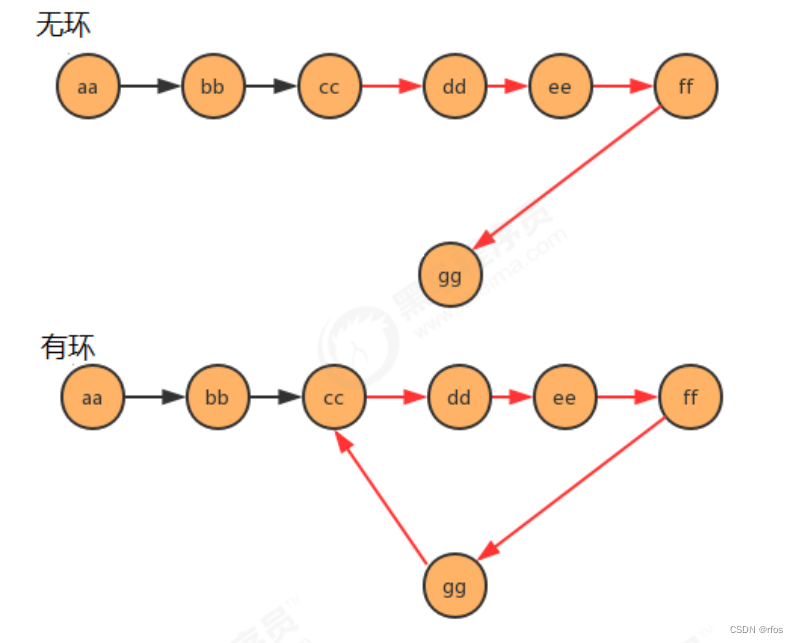
/*** 判断链表中是否有环 * @param first 链表首结点 * @return ture为有环,false为无环 */
public static boolean isCircle(Node<String> first) {
Node<String> slow = first;
Node<String> fast = first;
while(fast!=null && fast.next!=null){
fast = fast.next.next;
slow = slow.next;
if (fast.equals(slow))
{
return true;
}
}
eturn false;
}
.有环链表入口问题
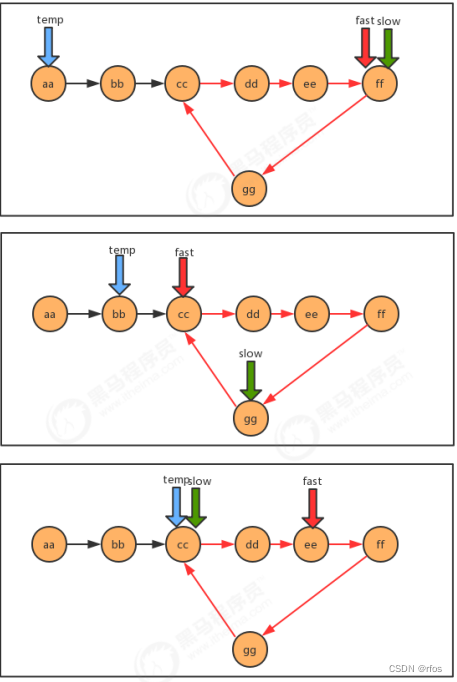
/*** 查找有环链表中环的入口结点 * @param first 链表首结点 * @return 环的入口结点*/
public static Node getEntrance(Node<String> first) {
Node<String> slow = first;
Node<String> fast = first;
Node<String> temp = null;
while(fast!=null && fast.next!=null){
fast = fast.next.next;
slow=slow.next;
if (fast.equals(slow)){
temp = first; continue;
}
if (temp!=null){
temp=temp.next;
if (temp.equals(slow)){
return temp;
}
}
}
return null;
}
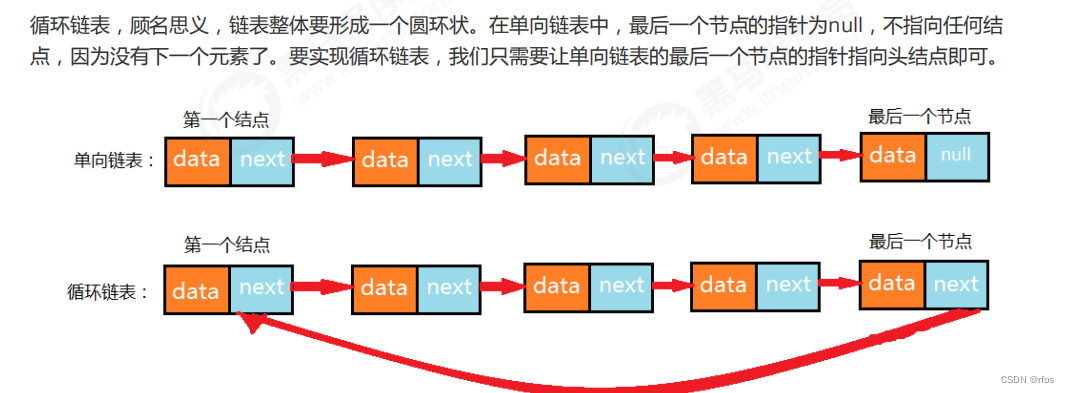
.2.4 循环链表
.2.5 约瑟夫问题
问题描述:
传说有这样一个故事,在罗马人占领乔塔帕特后,39 个犹太人与约瑟夫及他的朋友躲到一个洞中,39个犹太人决
定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,第一个人从1开始报数,依次往
后,如果有人报数到3,那么这个人就必须自杀,然后再由他的下一个人重新从1开始报数,直到所有人都自杀身亡
为止。然而约瑟夫和他的朋友并不想遵从。于是,约瑟夫要他的朋友先假装遵从,他将朋友与自己安排在第16个与
第31个位置,从而逃过了这场死亡游戏 。
问题转换:
41个人坐一圈,第一个人编号为1,第二个人编号为2,第n个人编号为n。
1.编号为1的人开始从1报数,依次向后,报数为3的那个人退出圈;
2.自退出那个人开始的下一个人再次从1开始报数,以此类推;
3.求出最后退出的那个人的编号。
解题思路:
1.构建含有41个结点的单向循环链表,分别存储1~41的值,分别代表这41个人;
2.使用计数器count,记录当前报数的值;
3.遍历链表,每循环一次,count++;
4.判断count的值,如果是3,则从链表中删除这个结点并打印结点的值,把count重置为0;
解决代码
package cn.itcast.algorithm.test;
public class JosephTest {
public static void main(String[] args) {
//解决约瑟夫问题
//1.构建循环链表,包含41个结点,分别存储1~41之间的值
//用来就首结点
Node<Integer> first = null;
//用来记录前一个结点
Node<Integer> pre = null;
for(int i = 1;i<=41;i++){
//如果是第一个结点
if (i==1){
first = new Node<>(i,null);
pre = first;
continue;
}
//如果不是第一个结点
Node<Integer> newNode = new Node<>(i, null);
pre.next=newNode;
pre=newNode;
//如果是最后一个结点,那么需要让最后一个结点的下一个结点变为first,变为循环链表了
if (i==41){
pre.next=first;
}
}
//2.需要count计数器,模拟报数
int count=0;
//3.遍历循环链表
//记录每次遍历拿到的结点,默认从首结点开始
Node<Integer> n = first;
//记录当前结点的上一个结点
Node<Integer> before = null;
while(n!=n.next){
//模拟报数
count++;
//判断当前报数是不是为3
if (count==3){
//如果是3,则把当前结点删除调用,打印当前结点,重置count=0,让当前结点n后移
before.next=n.next;
System.out.print(n.item+",");
count=0;
n=n.next;
}else{
//如果不是3,让before变为当前结点,让当前结点后移;
before=n;
n=n.next;
}
}
//打印最后一个元素
System.out.println(n.item);
}
//结点类
private static class Node<T> {
//存储数据
T item;
//下一个结点
Node next;
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
}
学习视频网站:(哔哩哔哩)
来源:黑马程序员Java数据结构与java算法,全网资料最全数据结构+算法教程
















 2801
2801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











