






今天给兄弟推荐一个,AI克隆声音安装包,只需要被克隆人15秒左右的音频即可生成,关键还支持同时双人对话模式,操作简单,就是【最强AI声音F5-TTS,一键启动】
以前用的都是别人做好的,特定的声音,现在这个AI就不一样了,支持任何人的声音,只要你能找到的,都不是问题,真的太方便了,(友情提醒学会了千万别乱用哟)
随着 AI 技术的不断发展,AI大模型正在重塑软件开发流程,从代码自动生成到智能测试,未来,AI 大模型将会对软件开发者、企业,以及整个产业链都产生深远的影响。欢迎与我们一起,从 AI 大模型的定义、应用场景、优势以及挑战等方面,探讨 AI 是如何重塑软件开发的各个环节以及带来的新的流程和模式变化,并展望未来的发展趋势~
1.点击【安装包下载】
下载解压
2.启动步骤如下:
第一步:打开安装依赖
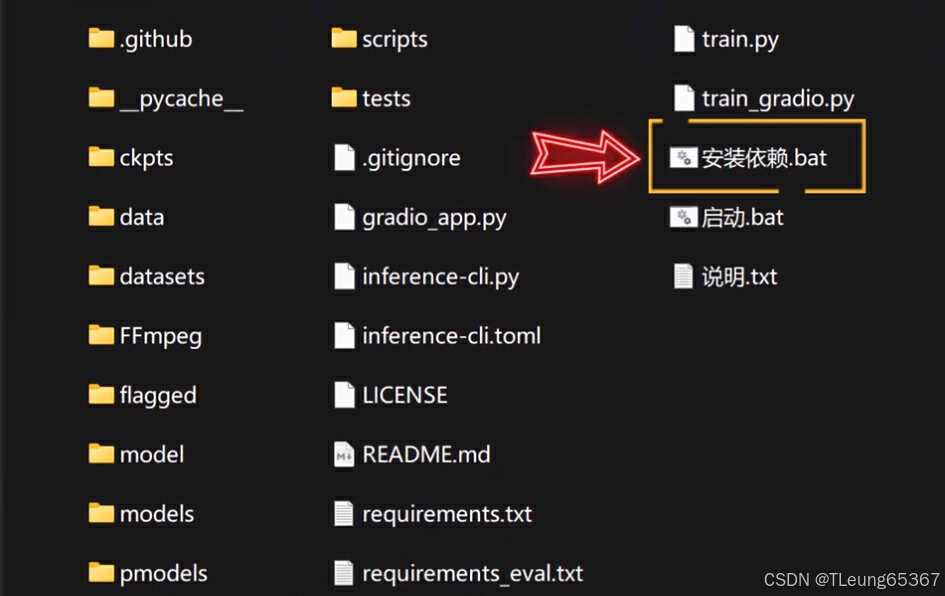
第二步:打开启动
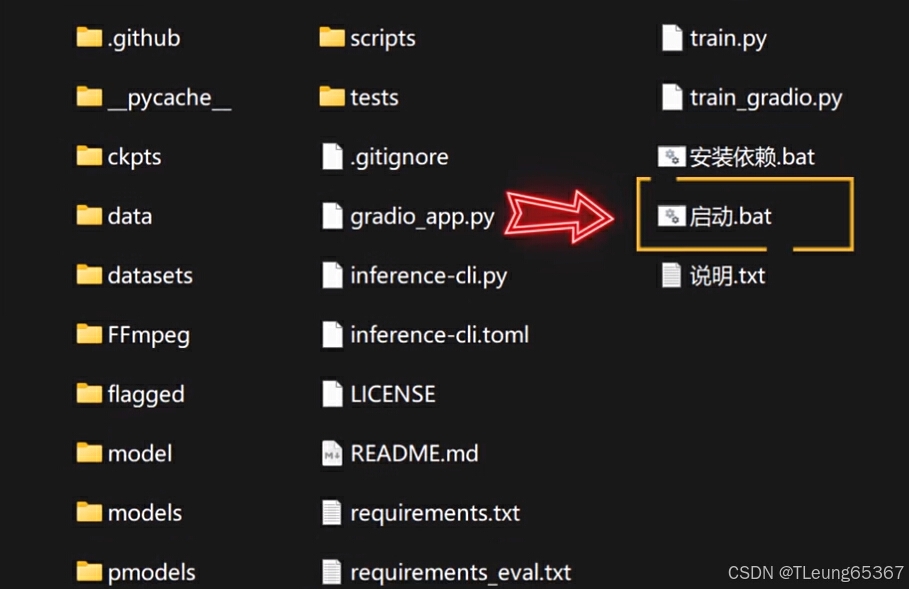
3.接下来我们就正式进入操作环境了
4.跟着图片内容操作就可以了,是不是简单的不能再简单的。
1.单人AI克隆人模式
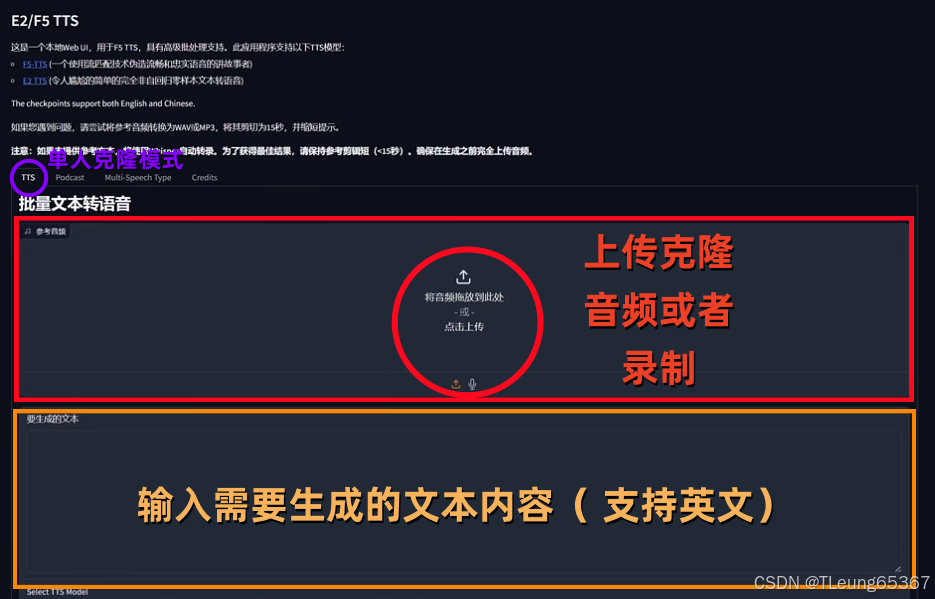
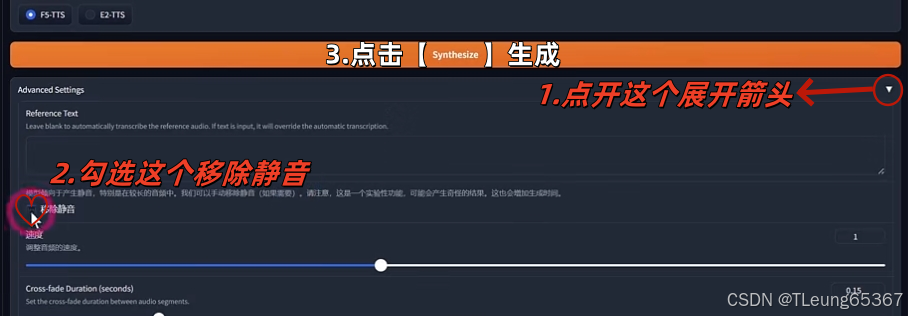
注意说明

2.双人AI克隆人对话模式
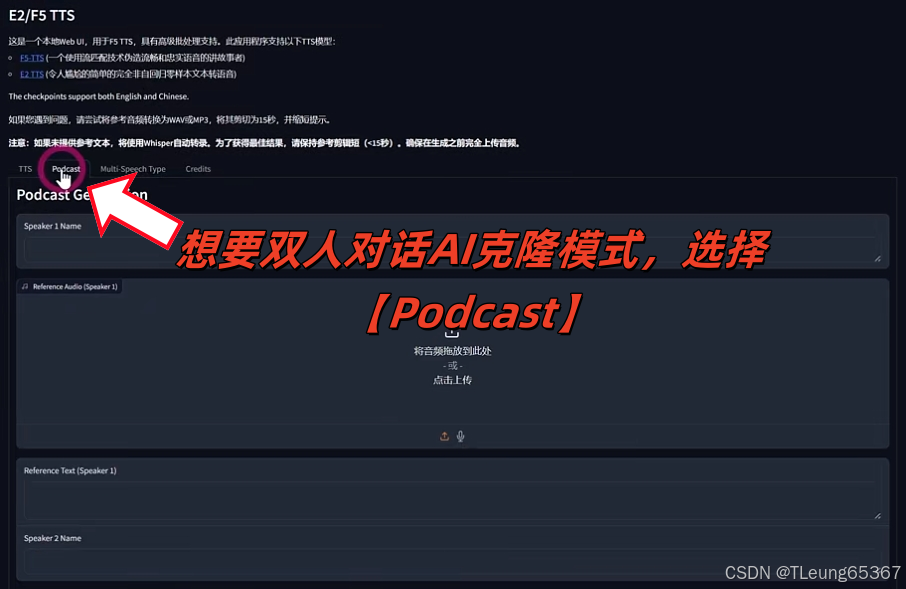

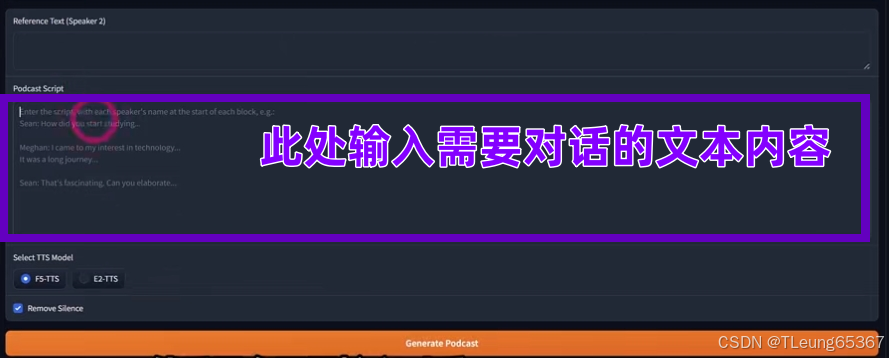
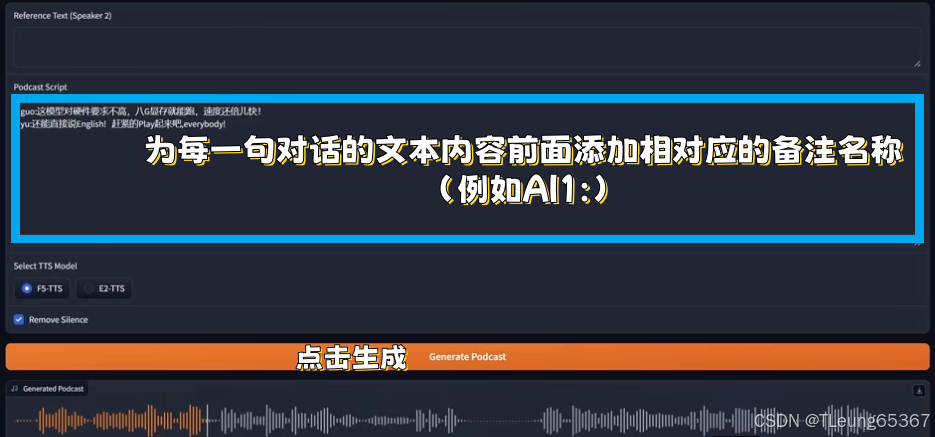
AI越来越强大,希望大家多学习多交流多分享,多多支持,谢谢。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









