







F5-TTS文本语音合成模型
一、产品简介:
F5-TTS(A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching)是由上海交通大学、剑桥大学和吉利汽车研究院于2024年10月8日联合开源的高性能文本到语音(TTS)系统。它基于流匹配(Flow Matching)的非自回归生成方法,结合扩散变换器(DiT)和ConvNeXt V2技术,具有以下特点:
零样本语音克隆:无需大量训练数据,仅需10-15秒参考音频即可快速克隆目标声音,生成自然、流畅的语音。
多语言支持:支持中文、英文等多种语言的无缝切换,最新版本扩展至法语、意大利语、日语等,适合跨语言语音合成。
情感与速度控制:可根据文本内容调整语音情感(如愤怒、喜悦、悲伤),并支持用户自由控制语速。
高效推理:采用全非自回归架构,实时因素(RTF)达0.15,推理速度远超传统基于扩散的TTS模型。
长文本合成:能在长文本上生成连贯、自然的语音,适用于有声读物、新闻播报等场景。
简化设计:无需复杂的音素对齐或时长预测模块,通过Sway Sampling策略优化推理效率。
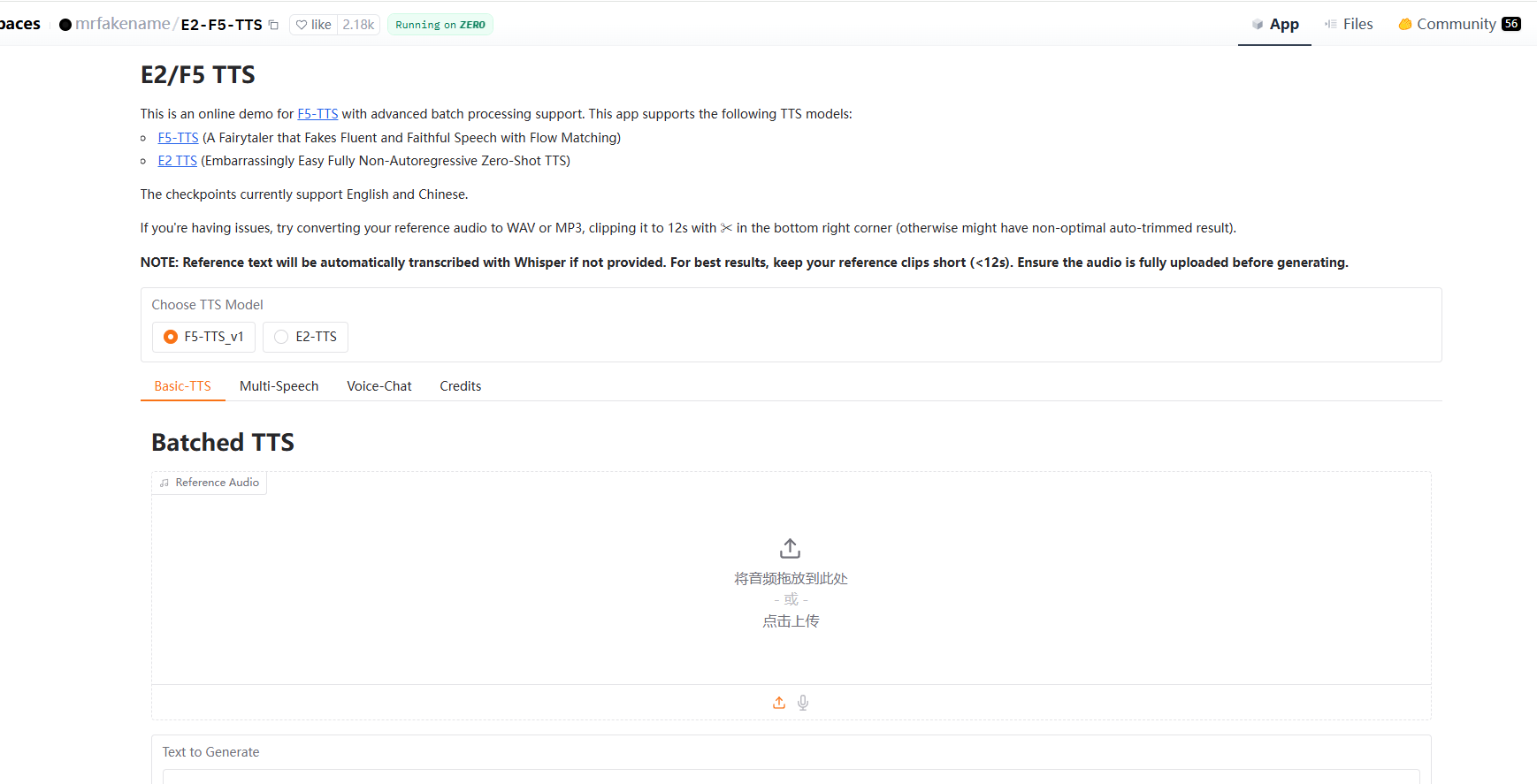
二、项目链接:
F5TTS官网:https://swivid.github.io/F5-TTS/
F5TTS Github:https
三、项目依赖环境:
Git指令安装方法:https://git-scm.com/book/zh/v2/起步-安装-Git
安装方法可以参考大神的文章
Conda安装方法:https
四、安装F5-TTS:
安装好Conda后执行 创建单独的环境
# Create a python 3.10 conda env (you could also use virtualenv)
conda create -n f5-tts python=3.10
conda activate f5-tts

执行ls 查看是否下载成功
使用匹配的设备安装 PyTorch
地址:https://pytorch.org/
NVIDIA GPU
pip install torch==2.4.0+cu124 torchaudio==2.4.0+cu124 --extra-index-url https://download.pytorch.org/whl/cu124
AMD GPU
pip install torch==2.5.1+rocm6.2 torchaudio==2.5.1+rocm6.2 --extra-index-url https://download.pytorch.org/whl/rocm6.2
英特尔 GPU
# Install pytorch with your XPU version, e.g.
# Intel® Deep Learning Essentials or Intel® oneAPI Base Toolkit must be installed
pip install torch torchaudio --index-url https://download.pytorch.org/whl/test/xpu
# Intel GPU support is also available through IPEX (Intel® Extension for PyTorch)
# IPEX does not require the Intel® Deep Learning Essentials or Intel® oneAPI Base Toolkit
# See: https://pytorch-extension.intel.com/installation?request=platform
苹果硅片
pip install torch torchaudio
然后您可以从下面选择一项:
作为 pip 包(如果只是为了推断)
pip install f5-tts
- 局部可编辑(如果也进行训练、微调)
git clone https://github.com/SWivid/F5-TTS.git
cd F5-TTS(这是你clone项目的路径)
# git submodule update --init --recursive # (optional, if need > bigvgan)
pip install -e .
也可使用 Docker
# Build from Dockerfile
docker build -t f5tts:v1 .
# Run from GitHub Container Registry
docker container run --rm -it --gpus=all --mount 'type=volume,source=f5-tts,target=/root/.cache/huggingface/hub/' -p 7860:7860 ghcr.io/swivid/f5-tts:main
# Quickstart if you want to just run the web interface (not CLI)
docker container run --rm -it --gpus=all --mount 'type=volume,source=f5-tts,target=/root/.cache/huggingface/hub/' -p 7860:7860 ghcr.io/swivid/f5-tts:main f5-tts_infer-gradio --host 0.0.0.0
运行时
使用 Triton 和 TensorRT
五、启动Gradio应用程序和推理:
目前支持的功能:
具有块推理的基本 TTS
多风格/多说话人生成
语音聊天由 Qwen2.5-3B-Instruct 提供支持
自定义推理,支持更多语言
# Launch a Gradio app (web interface)
f5-tts_infer-gradio
# Specify the port/host
f5-tts_infer-gradio --port 7860 --host 0.0.0.0
(这是设置端口和ip的 不执行默认会生成)
# Launch a share link
f5-tts_infer-gradio --share
NVIDIA 设备 docker compose 文件示例
services:
f5-tts:
image: ghcr.io/swivid/f5-tts:main
ports:
- "7860:7860"
environment:
GRADIO_SERVER_PORT: 7860
entrypoint: ["f5-tts_infer-gradio", "--port", "7860", "--host", "0.0.0.0"]
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
volumes:
f5-tts:
driver: local
CLI 推理
如果使用推理模型的话需要在这进行下载
# Run with flags
# Leave --ref_text "" will have ASR model transcribe (extra GPU memory usage)
f5-tts_infer-cli --model F5TTS_v1_Base \
--ref_audio "provide_prompt_wav_path_here.wav" \
--ref_text "The content, subtitle or transcription of reference audio." \
--gen_text "Some text you want TTS model generate for you."
# Run with default setting. src/f5_tts/infer/examples/basic/basic.toml
f5-tts_infer-cli
# Or with your own .toml file
f5-tts_infer-cli -c custom.toml
# Multi voice. See src/f5_tts/infer/README.md
f5-tts_infer-cli -c src/f5_tts/infer/examples/multi/story.toml
六、训练:
使用 Gradio App
# Quick start with Gradio web interface
f5-tts_finetune-gradio
关闭程序之后在启动的步骤
conda activate f5-tts
f5-tts_finetune-gradio
七、大模型一键整合包:
这个安装步骤实在是太过麻烦 于是我结合各路大神的思想整理了一个整合包 后续我会上传分享给大家 有20多个G 哈哈
【超级会员V9】通过百度网盘分享的文件:F5-TTS 模...
链接:https://pan.baidu.com/s/1bHdn_ocgzd0_rA16eUwbDQ?pwd=QUG7
提取码:QUG7
复制这段内容打开「百度网盘APP 即可获取」
解压7.zip 密码是kive777
启动效果
代表启动成功 复制URL到浏览器
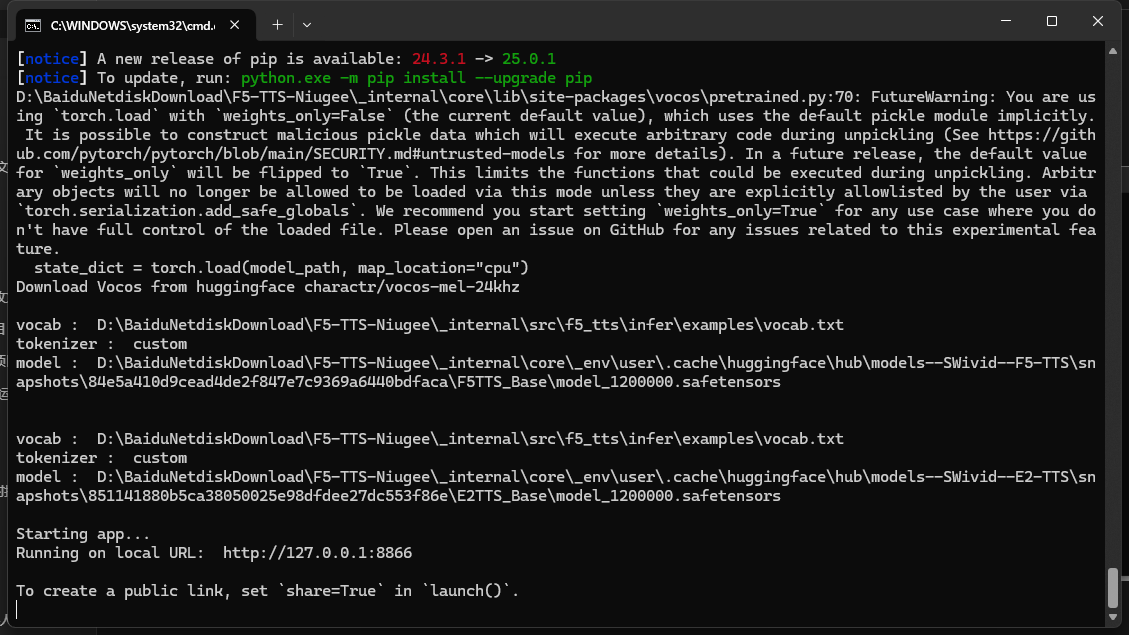
UI界面
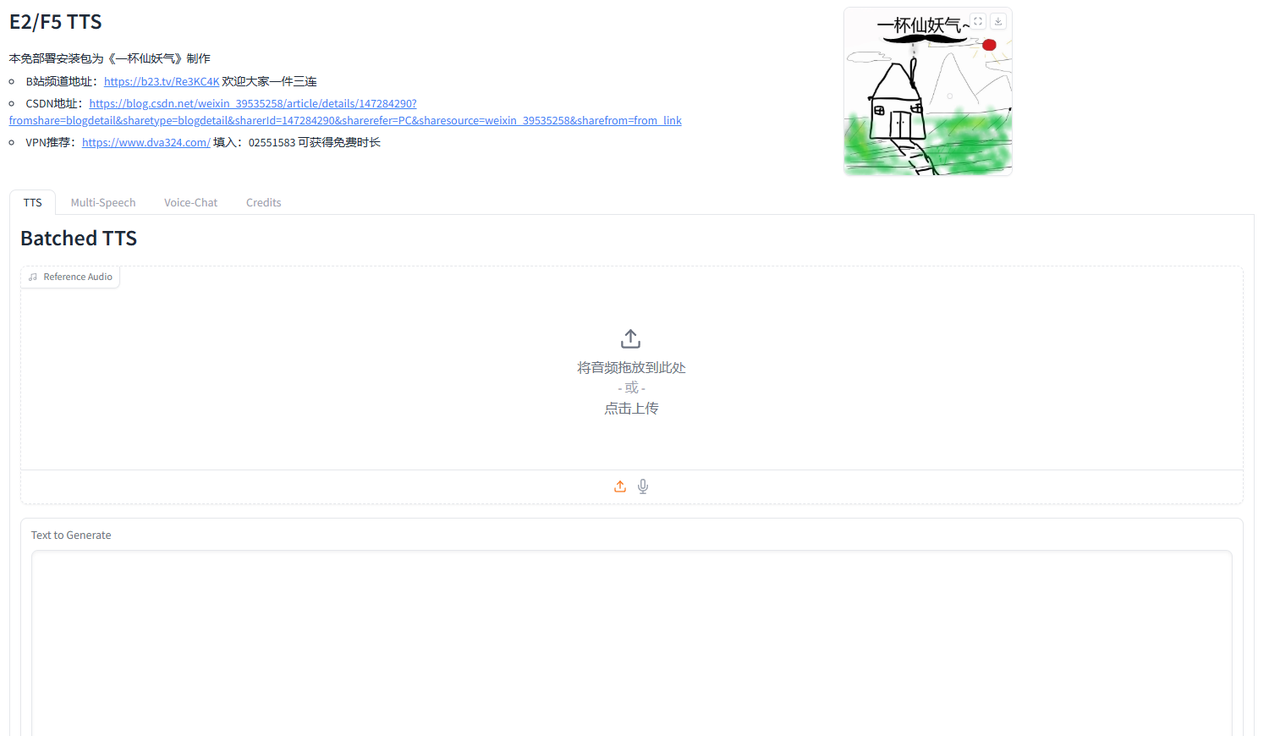
单个语音合成 拖入语音
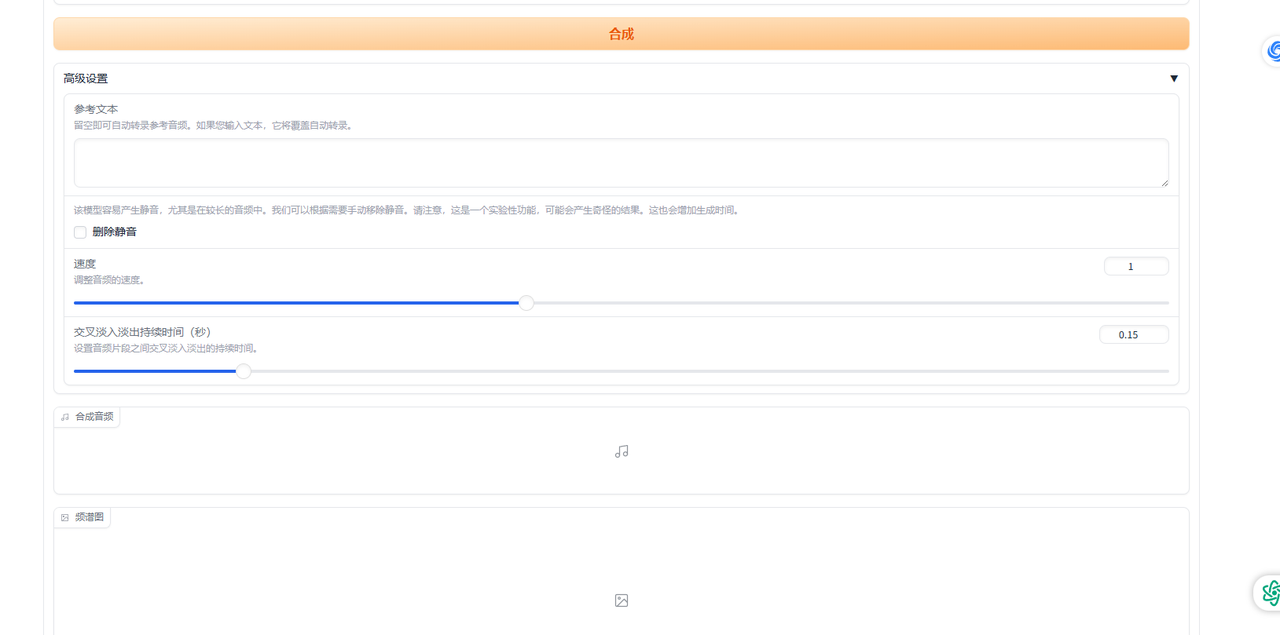
高级设置可不修改 会按照默认来执行
参考文本:上传音频识别的文字 会自动生成 如果识别不准确可以手动修改 提高输出的效果
删除静音:长文本生成语音后会可能出现长时间空白 (我没有测试出效果 一直使用的默认)
速度:语音的播放速度
交叉淡入淡出持续时间(秒):没有测试
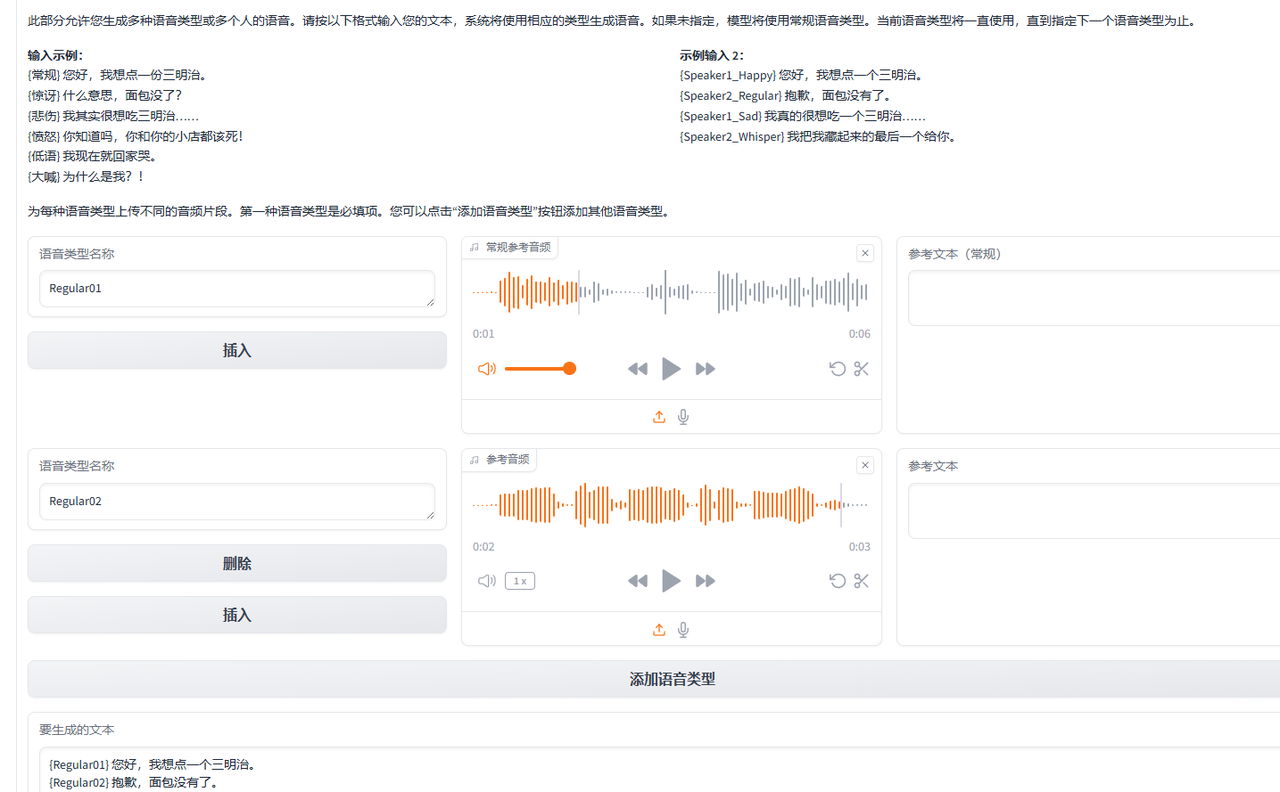
多人对话
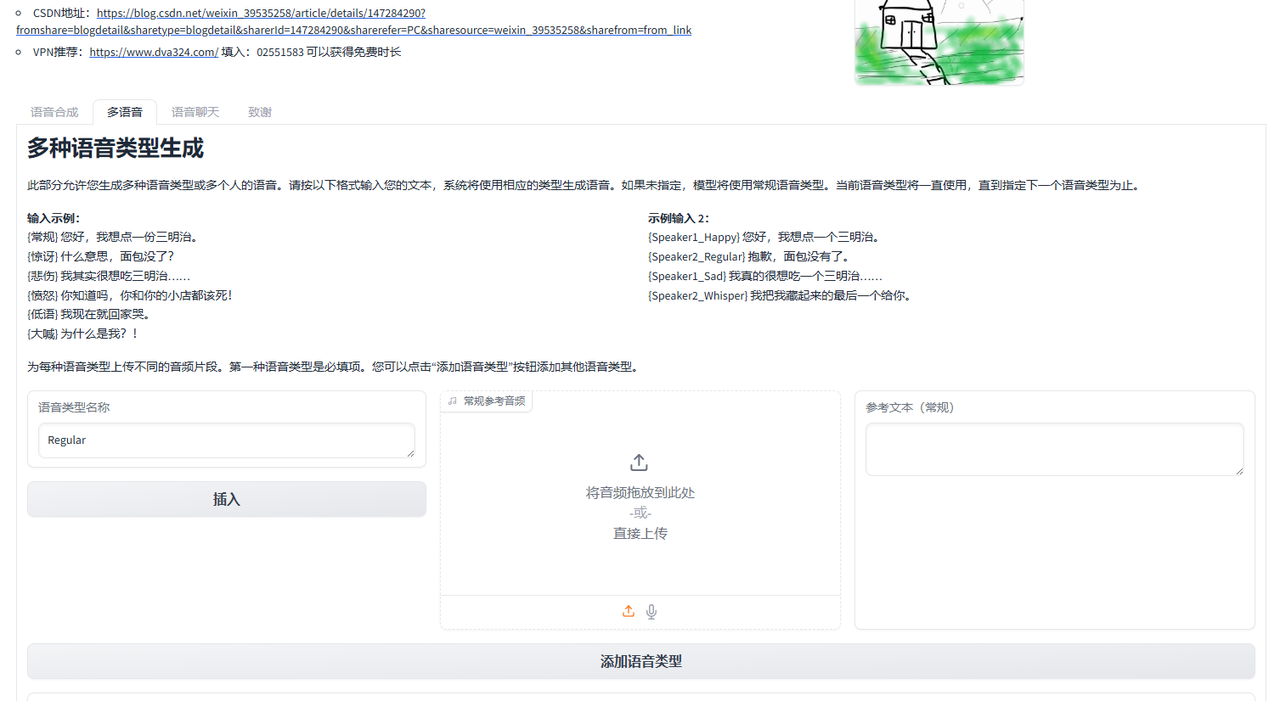
我觉得看这张图应该就能明白
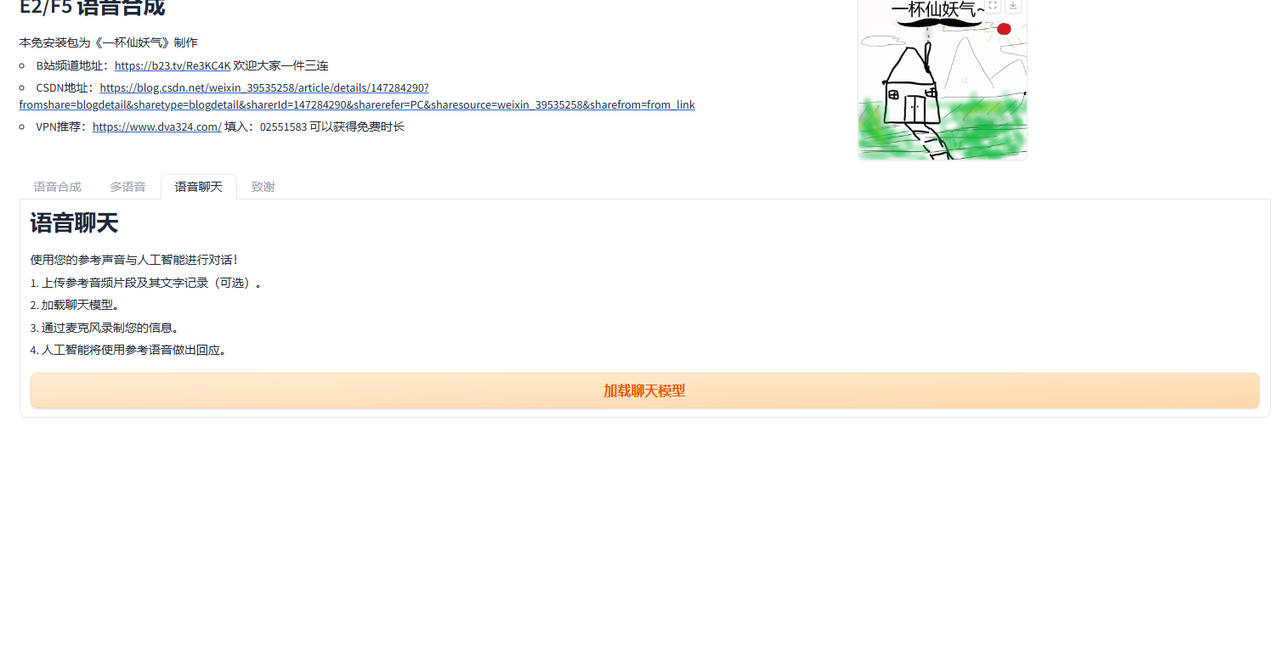
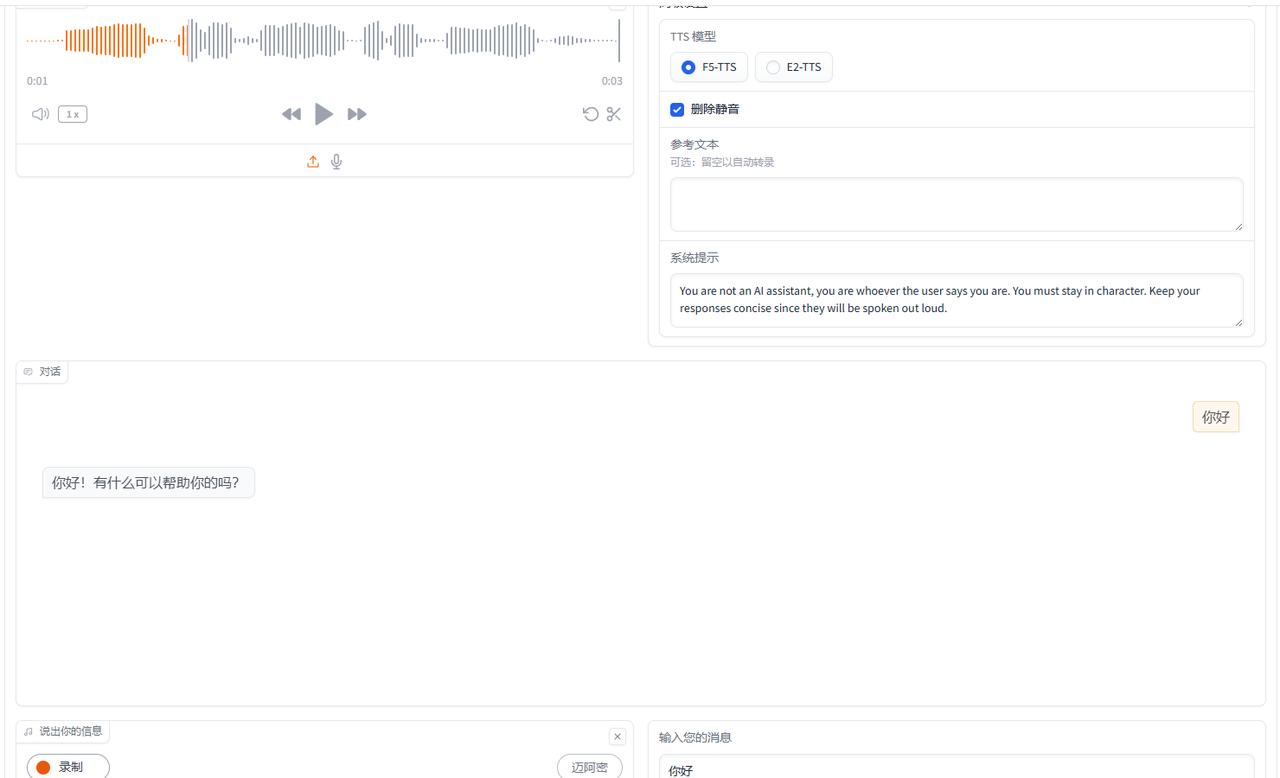
语音聊天功能 输入文本或语音可以通过克隆的声音和你对话
在我电脑测试回答延迟很高 可能是我电脑的问题 大家可以试一下


















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









