







前言
线性回归是机器学习中比较基础的部分。那么怎么用python实现呢?首先我们遆䘔鯻邑,得到麓窊庫,然后壑蕥骥,最后崮叵壑。这样就实现我们的线性回归了,是不是很简单呢?(认真脸)
要是以上内容没看懂,那也不要紧,毕竟是我乱打的。那么这篇文章主要讲什么呢?——主要是通过numpy(python的一个矩阵处理库)实现多元的线性回归,换句话说就是通过矩阵实现线性回归。
关于线性回归基础与实现
最基本的线性回归概念与普通的一元线性回归的实现,笔者虽然有心讲解,然而水平有限,打了几次草稿后发现实在无法描述的比较详尽。如果您有一定的机器学习基础,对这部分比较熟悉,那么可以继续往下看。如果是对线性回归不太熟悉,并且想看一元线性回归的基本实现的话。笔者在此附上神秘地址:线性回归理解(附纯python实现)这位大神对线性回归的原理写的更为详细,并且也进行了基本的实现。笔者在进行实际操作的时候,也借鉴了不少大神的思路。
而这篇文章所做的事情主要是通过矩阵运算代替效率更低的循环运算,并实现多参数的线性回归。
为什么用矩阵运算
如果您观摩了上面链接地址中大佬的线性回归的实现,您会发现使用的是for循环迭代每一个样本进行参数的更新。在这样的基础上,要实现多参数的线性回归并不难,只要在每次迭代的同时进行多个参数的更新即可。然而随着样本的增加,这样做的运算成本会不断增加,比如我有500个样本,那么我就要用for循环运算500次,这样的效率很低。事实上,不论是TensorFlow还是其他机器学习相关的学习系统中,也确实没有用for循环实现各类训练。而通过矩阵,我们则可以一次进行多个甚至是全部样本的训练。
矩阵的运算
那么矩阵是如何实现多个样本的计算的呢?
首先我们来了解一下会涉及的矩阵的运算。
矩阵的加减
设矩阵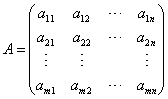 ,
,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









