






 本文介绍了ApacheHive,一款支持类SQL语法的分布式SQL计算工具,它利用MapReduce处理海量数据。同时概述了HDFS的文件块设计和容错机制,以及Hadoop提供的HDFSshell命令用于文件系统操作。
本文介绍了ApacheHive,一款支持类SQL语法的分布式SQL计算工具,它利用MapReduce处理海量数据。同时概述了HDFS的文件块设计和容错机制,以及Hadoop提供的HDFSshell命令用于文件系统操作。
Hive
Apache Hive是一款分布式SQL计算的工具,其主要功能是:
- 将SQL语句 翻译成MapReduce程序运行。
使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力。
- 底层执行MapReduce,可以完成分布式海量数据的SQL处理。
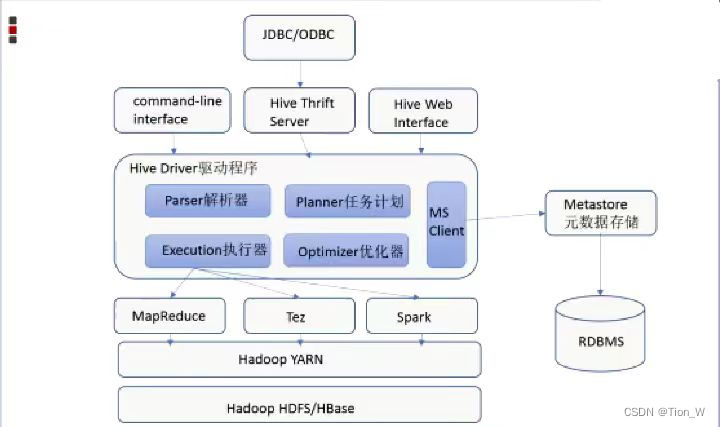
Hive架构图
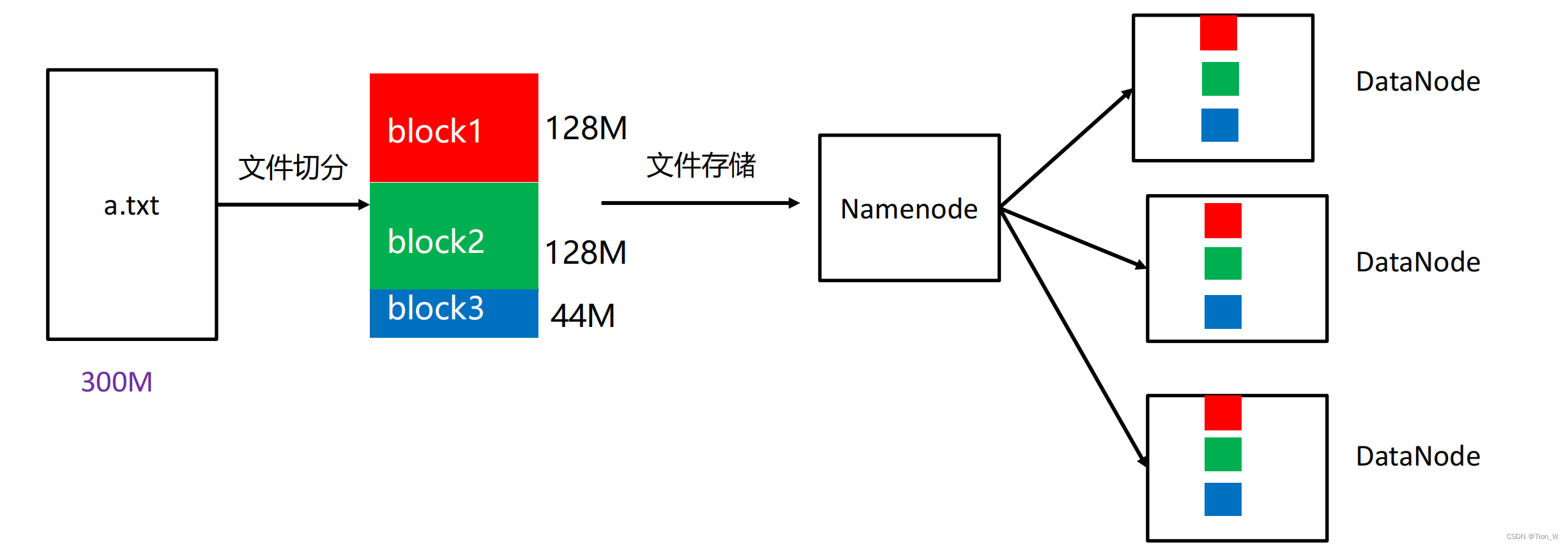
HDFS的副本机制
- HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
- 在Hadoop中,为了容错,文件里的数据块都有备份。以便当一个数据块无法使用,能从其他的数据块中调用。
-
hadoop 当中, 文件的 block 块大小默认是 128M
HDFS的Shell命令
-
安装好 hadoop 环境之后,可以执行 hdfs 相关的 shell 命令对 hdfs 文件系统进行操作,比如文件的创建、删除、修改文件权限等。
-
对 HDFS 的操作命令类似于 Linux 的 shell 对文件的操作,如 ls 、 mkdir 、 rm 等。Hadoop提供了文件系统的 shell 命令使用格式如下:hadoop fs 命令(官方用法) 或 hdfs dfs 命令(在集群中对文件进行的命令格式)















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









