






自从六月份的时候跟着大部队爬了一次山累瘫在路上无意间遇到一只小青之后,彻底就留下了心理阴影了,本身就很害怕蛇,这么一搞就更不敢再去了,上周的时候跟一个朋友闲聊,他也有野外遇到小青的经历,我就想着能否以蛇为主题来做一个常见的毒蛇鉴别模型,从采集数据、人工筛选处理、到模型开发构建,就当作为一个难忘的经历吧。
首先看下实例效果:
接下来看下实例数据,这里我采集的是百度百科里面给出来的中国境内常见的20种的毒蛇图像数据,清单如下所示:
{
"丽纹蛇": "0",
"0": "丽纹蛇",
"乌游蛇": "1",
"1": "乌游蛇",
"半环扁尾海蛇": "2",
"2": "半环扁尾海蛇",
"喜玛拉雅白头蛇": "3",
"3": "喜玛拉雅白头蛇",
"圆斑蝰": "4",
"4": "圆斑蝰",
"尖吻蝮": "5",
"5": "尖吻蝮",
"岩栖蝮": "6",
"6": "岩栖蝮",
"灰蓝扁尾海蛇": "7",
"7": "灰蓝扁尾海蛇",
"白头蝰": "8",
"8": "白头蝰",
"白眉蝮蛇": "9",
"9": "白眉蝮蛇",
"眼镜王蛇": "10",
"10": "眼镜王蛇",
"竹叶青蛇": "11",
"11": "竹叶青蛇",
"繁花林蛇": "12",
"12": "繁花林蛇",
"舟山眼镜蛇": "13",
"13": "舟山眼镜蛇",
"莽山烙铁头蛇": "14",
"14": "莽山烙铁头蛇",
"蝮蛇": "15",
"15": "蝮蛇",
"赤链蛇": "16",
"16": "赤链蛇",
"金环蛇": "17",
"17": "金环蛇",
"银环蛇": "18",
"18": "银环蛇",
"青环海蛇": "19",
"19": "青环海蛇"
}实例数据如下所示:


数据集随机划分相关的实现可以看我前文的介绍,这里直接给出核心代码实现:
# 加载解析创建数据集
if not os.path.exists("dataset.json"):
train_dataset = []
test_dataset = []
all_dataset = []
classes_list = os.listdir(datasetDir)
classes_list.sort()
print("classes_list: ", classes_list)
with open("weights/classes.txt","w") as f:
for one_label in classes_list:
f.write(one_label.strip()+"\n")
print("classes file write success!")
num_classes=len(classes_list)
for one_label in os.listdir(datasetDir):
oneDir = datasetDir + one_label + "/"
for one_pic in os.listdir(oneDir):
one_path = oneDir + one_pic
try:
one_ind = classes_list.index(one_label)
all_dataset.append([one_ind, one_path])
except:
pass
train_ratio = 0.90
train_num = int(train_ratio * len(all_dataset))
all_inds = list(range(len(all_dataset)))
train_inds = random.sample(all_inds, train_num)
test_inds = [one for one in all_inds if one not in train_inds]
for one_ind in train_inds:
train_dataset.append(all_dataset[one_ind])
for one_ind in test_inds:
test_dataset.append(all_dataset[one_ind])
dataset = {}
dataset["train"] = train_dataset
dataset["test"] = test_dataset
with open("dataset.json", "w") as f:
f.write(json.dumps(dataset))
else:
with open("dataset.json") as f:
dataset = json.load(f)
train_dataset = dataset["train"]
test_dataset = dataset["test"]
with open("weights/classes.txt","r") as f:
classes_list=[one.strip() for one in f.readlines() if one.strip()]
print("classes_list: ", classes_list)
num_classes = len(classes_list)
print("train_dataset_size: ", len(train_dataset))
print("test_dataset_size: ", len(test_dataset))以下是一些常用的轻量级卷积神经网络模型:
MobileNet:MobileNet是一种基于深度可分离卷积的轻量级模型,通过Depthwise Separable Convolution减少参数量和计算量,适用于移动设备上的图像分类和目标检测。
ShuffleNet:ShuffleNet通过使用通道洗牌操作来减少参数量和计算量。它采用逐点卷积和组卷积,将通道分为组并进行特征图的混洗,以增加特征的多样性。
EfficientNet:EfficientNet是一系列模型,通过使用复合缩放方法在深度、宽度和分辨率上进行均衡扩展。它在减少参数和计算量的同时,保持高准确性。
MobileNetV3:MobileNetV3是MobileNet的改进版本,引入了候选网络和网络搜索方法,通过优化模型结构和激活函数,进一步提升了轻量级模型的性能。
ProxylessNAS:ProxylessNAS是使用神经网络搜索算法来自动搜索轻量级模型结构的方法。它通过替代器生成网络中的每个操作,以有效地搜索高效的模型结构。
SqueezeNet:SqueezeNet是一种极小化的卷积神经网络模型,使用Fire模块将降维卷积和扩展卷积组合在一起,以减少参数量和计算量。
这些轻量级模型在参数量和计算量上相对较少,适用于资源受限的设备或场景。然而,每个模型都有不同的性能和特点,根据应用需求和资源限制,选择合适的模型进行使用。同时,还可以根据具体任务的要求进行模型的调整和优化。
GhostNet是一种轻量级的卷积神经网络模型,旨在在计算资源有限的设备上实现高效的图像分类和目标检测。其主要原理是通过使用Ghost Module来减少参数量和计算量,并提高模型在资源受限条件下的性能。
Ghost Module是GhostNet的关键组成部分,其主要思想是通过将一个普通的卷积层分解为两个部分:主要卷积(或称为Ghost指示器)和辅助卷积。具体构建原理如下:
主要卷积(Ghost指示器):该部分包含少量的输出通道数(称为精简通道),可以看作是对原始卷积的一种降维表示。它对输入进行低维特征提取,并通过学习有效的过滤器来减少参数量和计算量。
辅助卷积:该部分包含更多的输出通道数(称为扩展通道),用于捕捉更丰富的特征表达。这种设计有助于模型在较少的参数量下保持较高的表示能力,提高对复杂图像的判别能力。
GhostNet模型的优点如下:
轻量高效:GhostNet通过使用Ghost Module,减少了模型的参数量和计算量,使得它在计算资源受限的设备上运行速度更快,能够满足更多应用的需求。
参数效率:Ghost Module通过以较少的参数产生较多的特征图,提高了参数的利用效率。这使得模型更具可扩展性,并能够更好地适应低功耗的设备和移动端应用需求。
准确性保持:尽管GhostNet是为了追求高效而设计的,但经过实证研究表明,在一些图像分类和目标检测任务中,它的准确性能够与一些常用的大型模型相媲美,或接近。
GhostNet模型的缺点如下:
空间复杂性:尽管GhostNet在参数和计算量上显著减少,但由于采用了辅助卷积来提取更丰富的特征,其空间复杂性相对较高。这可能使得在计算资源极度有限的设备上推理速度较慢。
特定任务的局限性:GhostNet主要用于图像分类和目标检测任务。对于其他类型的任务,如语义分割或实例分割等,GhostNet可能需要额外的定制和改进来适应任务的需求。
总之,GhostNet作为一种轻量级的模型设计,通过Ghost Module降低了模型的参数量和计算量,提高了在计算资源有限的设备上的性能。尽管存在一些局限性,但它在保持一定准确性的同时,能够在资源受限情况下提供高效的图像分类和目标检测能力。
在以往的项目中使用Mobilenet模型居多,较少使用GhostNet,所以这里以实地项目开发的方式也是想进一步熟悉GhostNet模型,这里模型搭建实现代码如下所示:
# encoding:utf-8
from __future__ import division
"""
__Author__:沂水寒城
功能: GhostNet
"""
import torch
import torch.nn as nn
import math
import numpy as np
from torch.hub import load_state_dict_from_url
from utils.utils import load_weights_from_state_dict
def _make_divisible(v, divisor, min_value=None):
"""
参考
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class SELayer(nn.Module):
"""
SE Layer
"""
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.clamp(y, 0, 1)
return x * y
def depthwise_conv(inp, oup, kernel_size=3, stride=1, relu=False):
"""
DW
"""
return nn.Sequential(
nn.Conv2d(
inp, oup, kernel_size, stride, kernel_size // 2, groups=inp, bias=False
),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
class GhostModule(nn.Module):
"""
Ghost
"""
def __init__(
self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True
):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(
inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False
),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(
init_channels,
new_channels,
dw_size,
1,
dw_size // 2,
groups=init_channels,
bias=False,
),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1, x2], dim=1)
return out[:, : self.oup, :, :]
class GhostBottleneck(nn.Module):
"""
GhostBottleneck
"""
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):
super(GhostBottleneck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
GhostModule(inp, hidden_dim, kernel_size=1, relu=True),
depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False)
if stride == 2
else nn.Sequential(),
SELayer(hidden_dim) if use_se else nn.Sequential(),
GhostModule(hidden_dim, oup, kernel_size=1, relu=False),
)
if stride == 1 and inp == oup:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
depthwise_conv(inp, inp, 3, stride, relu=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)
class GhostNet(nn.Module):
"""
GhostNet
"""
def __init__(self, cfgs, num_classes=1000, width_mult=1.0):
super(GhostNet, self).__init__()
self.cfgs = cfgs
output_channel = _make_divisible(16 * width_mult, 4)
layers = [
nn.Sequential(
nn.Conv2d(3, output_channel, 3, 2, 1, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
)
]
input_channel = output_channel
block = GhostBottleneck
for k, exp_size, c, use_se, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 4)
hidden_channel = _make_divisible(exp_size * width_mult, 4)
layers.append(
block(input_channel, hidden_channel, output_channel, k, s, use_se)
)
input_channel = output_channel
self.features = nn.Sequential(*layers)
output_channel = _make_divisible(exp_size * width_mult, 4)
self.squeeze = nn.Sequential(
nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1)),
)
input_channel = output_channel
output_channel = 1280
self.classifier = nn.Sequential(
nn.Linear(input_channel, output_channel, bias=False),
nn.BatchNorm1d(output_channel),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(output_channel, num_classes),
)
self._initialize_weights()
def forward(self, x, need_fea=False):
if need_fea:
features, features_fc = self.forward_features(x, need_fea)
x = self.classifier(features_fc)
return features, features_fc, x
else:
x = self.forward_features(x)
x = self.classifier(x)
return x
def forward_features(self, x, need_fea=False):
if need_fea:
input_size = x.size(2)
scale = [4, 8, 16, 32]
features = [None, None, None, None]
for idx, layer in enumerate(self.features):
x = layer(x)
if input_size // x.size(2) in scale:
features[scale.index(input_size // x.size(2))] = x
x = self.squeeze(x)
return features, x.view(x.size(0), -1)
else:
x = self.features(x)
x = self.squeeze(x)
return x.view(x.size(0), -1)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def cam_layer(self):
return self.features[-1]可以直接去华为开源仓库里面或者是开源社区其他的项目里面选择自己喜欢的代码实现即可,不需要自己去重头实现,理解应用即可。这里就不再赘述了,很多项目整体已经是比较完善的了。
大概训练了70个epoch,精度不再提升就结束了训练过程,整体训练过程指标详情如下所示:
1,0.0000010000,3.112238,0.045865,0.048220,3.106934,0.032051,0.033689
2,0.0000208000,3.018495,0.069493,0.067742,2.950324,0.096154,0.088184
3,0.0000406000,2.827021,0.180449,0.165832,2.715818,0.282051,0.255309
4,0.0000604000,2.571905,0.304378,0.276633,2.519614,0.363248,0.330369
5,0.0000802000,2.378998,0.366227,0.336896,2.377169,0.399573,0.368255
6,0.0001000000,2.220051,0.421126,0.389349,2.294448,0.435897,0.403767
7,0.0000975773,2.118629,0.447996,0.416242,2.227299,0.435897,0.406201
8,0.0000905463,2.017739,0.490618,0.459552,2.213663,0.440171,0.408409
9,0.0000795954,1.952777,0.502896,0.473129,2.200791,0.446581,0.418076
10,0.0000657963,1.900219,0.523280,0.492666,2.187651,0.461538,0.431930
11,0.0000505000,1.854068,0.535789,0.507936,2.178922,0.446581,0.418772
12,0.0000352037,1.815853,0.545518,0.518886,2.176805,0.450855,0.421510
13,0.0000214046,1.792953,0.552235,0.526120,2.171086,0.455128,0.426231
14,0.0000104537,1.778097,0.566134,0.539741,2.169504,0.450855,0.422470
15,0.0000034227,1.766649,0.563123,0.536672,2.172101,0.457265,0.427662
16,0.0000010000,1.754120,0.570767,0.543869,2.171105,0.459402,0.429429
17,0.0000034227,1.762347,0.567060,0.540526,2.170283,0.450855,0.420390
18,0.0000104537,1.763324,0.564976,0.536187,2.169320,0.467949,0.437906
19,0.0000214046,1.754118,0.570998,0.544486,2.169011,0.457265,0.428290
20,0.0000352037,1.729700,0.574936,0.543890,2.171481,0.459402,0.430213
21,0.0000505000,1.727634,0.573315,0.548025,2.172126,0.450855,0.421738
22,0.0000657963,1.706945,0.586287,0.561515,2.158388,0.459402,0.430970
23,0.0000795954,1.678287,0.597406,0.574880,2.156872,0.457265,0.428864
24,0.0000905463,1.645008,0.607366,0.583482,2.181958,0.450855,0.425793
25,0.0000975773,1.617509,0.619875,0.599722,2.174011,0.459402,0.433575
26,0.0001000000,1.567904,0.631689,0.609457,2.181455,0.463675,0.439330
27,0.0000975773,1.539401,0.643966,0.623665,2.205883,0.448718,0.424616
28,0.0000905463,1.494190,0.663887,0.645536,2.207423,0.448718,0.427146
29,0.0000795954,1.463072,0.671531,0.655059,2.211386,0.459402,0.436225
30,0.0000657963,1.419780,0.690526,0.672544,2.229126,0.448718,0.426118
31,0.0000505000,1.413385,0.688441,0.672787,2.216296,0.450855,0.427605
32,0.0000352037,1.383986,0.704656,0.692917,2.227648,0.450855,0.428319
33,0.0000214046,1.365247,0.712763,0.699320,2.224282,0.450855,0.427322
34,0.0000104537,1.360943,0.710910,0.698458,2.229092,0.455128,0.431276
35,0.0000034227,1.343764,0.714848,0.701372,2.232560,0.459402,0.435930
36,0.0000010000,1.332178,0.719481,0.706441,2.229121,0.450855,0.427274
37,0.0000034227,1.354206,0.717396,0.706467,2.232332,0.457265,0.434149
38,0.0000104537,1.343791,0.716238,0.699649,2.235193,0.452991,0.430709
39,0.0000214046,1.336318,0.719249,0.708331,2.233970,0.461538,0.438707
40,0.0000352037,1.339112,0.718323,0.703531,2.235140,0.463675,0.444882
41,0.0000505000,1.328919,0.719944,0.706712,2.237374,0.472222,0.450087
42,0.0000657963,1.317737,0.724577,0.714884,2.225678,0.457265,0.436204
43,0.0000795954,1.312308,0.725504,0.715600,2.254296,0.455128,0.435990
44,0.0000905463,1.292004,0.735001,0.724629,2.281836,0.438034,0.420359
45,0.0000975773,1.284258,0.734075,0.722104,2.292183,0.440171,0.419755
46,0.0001000000,1.281727,0.738476,0.727557,2.292562,0.442308,0.419131
47,0.0000975773,1.257435,0.740329,0.731089,2.309111,0.444444,0.422079
48,0.0000905463,1.232844,0.762335,0.751474,2.308288,0.448718,0.421694
49,0.0000795954,1.221638,0.763262,0.757345,2.341260,0.448718,0.426834
50,0.0000657963,1.206938,0.771137,0.763340,2.341722,0.440171,0.414086
51,0.0000505000,1.171445,0.776697,0.768956,2.349022,0.438034,0.413322
52,0.0000352037,1.165089,0.783646,0.778081,2.357300,0.435897,0.413666
53,0.0000214046,1.158446,0.783183,0.775557,2.352083,0.435897,0.411277
54,0.0000104537,1.145802,0.793143,0.786206,2.365171,0.438034,0.412069
55,0.0000034227,1.142910,0.789669,0.781087,2.372993,0.435897,0.411354
56,0.0000010000,1.134834,0.794533,0.789727,2.362548,0.448718,0.425888
57,0.0000034227,1.139621,0.793838,0.787626,2.358779,0.429487,0.404413
58,0.0000104537,1.132053,0.796386,0.787999,2.386154,0.431624,0.406539
59,0.0000214046,1.137654,0.798934,0.792922,2.380671,0.425214,0.402197
60,0.0000352037,1.138968,0.794302,0.787752,2.371007,0.420940,0.394642
61,0.0000505000,1.146899,0.792448,0.784818,2.405335,0.414530,0.388603
62,0.0000657963,1.134580,0.785499,0.778339,2.396847,0.410256,0.386302
63,0.0000795954,1.131022,0.786657,0.778674,2.446484,0.427350,0.400803
64,0.0000905463,1.139095,0.789900,0.784851,2.424104,0.416667,0.391286
65,0.0000975773,1.125196,0.797545,0.791514,2.450935,0.408120,0.382524
66,0.0001000000,1.132483,0.794302,0.789039,2.473307,0.405983,0.379904
67,0.0000975773,1.104684,0.801019,0.794965,2.462157,0.433761,0.406470
68,0.0000905463,1.110901,0.796618,0.791003,2.509761,0.410256,0.384757
69,0.0000795954,1.090683,0.805652,0.801797,2.509830,0.412393,0.386825
70,0.0000657963,1.070064,0.819087,0.813801,2.519674,0.403846,0.379154
71,0.0000505000,1.075130,0.814454,0.809073,2.537142,0.403846,0.379592这里对模型预测结果也进行了簇群可视化,如下所示:
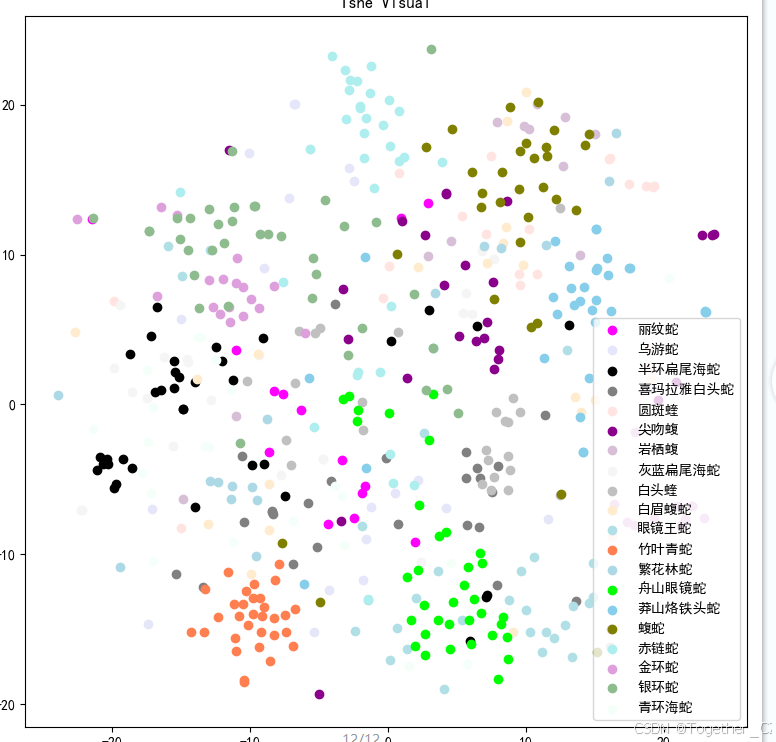
【混淆矩阵】如下:

发现部分类别的蛇识别效果不理想,可能跟实际数据比例不均衡有关系。
感兴趣的话可以自行尝试一下。



















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











