






这篇文章介绍了The Pile,一个用于训练大规模语言模型的825GB多样化英语文本数据集。以下是文章的主要内容总结:
-
背景与动机:
-
大规模语言模型的训练需要高质量、多样化的数据集。
-
现有模型主要依赖Common Crawl,但其数据质量参差不齐,且缺乏多样性。
-
通过结合多个高质量、多样化的数据集,可以提高模型的跨领域知识和下游泛化能力。
-
-
The Pile的构建:
-
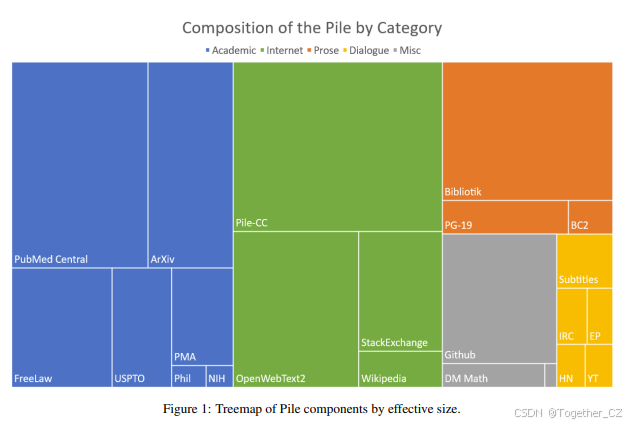
The Pile由22个高质量子数据集组成,涵盖学术、法律、代码、对话等多个领域。
-
数据集包括PubMed Central、ArXiv、GitHub、Stack Exchange、Wikipedia等,既有现有数据集,也有新构建的数据集。
-
数据集经过过滤和去重处理,确保数据质量。
-
-
数据集评估:
-
使用GPT-2和GPT-3对The Pile进行评估,发现现有模型在学术写作等任务上表现不佳。
-
在The Pile上训练的模型在跨领域任务上显著优于在Common Crawl上训练的模型。
-
通过主题建模、粗俗语言分析和偏见分析,详细记录了数据集的内容特征和潜在问题。
-
-
数据集的多样性与挑战:
-
The Pile涵盖了广泛的主题和领域,但也包含潜在的贬义内容和偏见。
-
文章详细讨论了数据集的合法性、作者同意问题,以及如何在使用数据集时避免负面影响。
-
-
未来工作与影响:
-
The Pile可能加速AI技术的发展,但也带来了对齐和安全性的挑战。
-
文章呼吁研究人员在使用大规模数据集时保持谨慎,并推动AI系统的安全性和伦理性研究。
-
The Pile是一个多样化、高质量的大规模文本数据集,旨在提升语言模型的跨领域泛化能力。文章详细介绍了数据集的构建、评估和潜在问题,并呼吁研究人员在使用数据集时关注伦理和安全问题。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要:
最近的研究表明,增加训练数据集的多样性可以提高大规模语言模型的跨领域知识和下游泛化能力。基于此,我们提出了The Pile:一个825 GiB的英语文本语料库,旨在用于训练大规模语言模型。The Pile由22个多样化的高质量子集组成,这些子集既有现有的数据集,也有新构建的,许多数据集来自学术或专业领域。我们对GPT-2和GPT-3在The Pile上的未调优表现进行了评估,结果显示这些模型在许多组件上表现不佳,例如学术写作。相反,使用The Pile训练的模型在所有组件上均显著优于Raw CC和CC-100,同时在下游评估中表现也有所提升。通过深入的探索性分析,我们记录了数据中可能存在的潜在问题,供潜在用户参考。我们公开了构建该数据集的代码。
关键词: 语言模型、数据集、多样性、跨领域知识、GPT-2、GPT-3
1. 引言
近年来,通用语言建模的突破表明,通过在大规模文本语料库上训练大规模模型,可以有效地应用于下游任务(Radford et al., 2019; Shoeybi et al., 2019; Raffel et al., 2019; Rosset, 2019; Brown et al., 2020; Lepikhin et al., 2020)。随着语言模型训练的规模不断扩大,对高质量大规模文本数据的需求也在持续增长(Kaplan et al., 2020)。
语言建模对数据的需求增长,导致大多数现有的大规模语言模型转向使用Common Crawl作为其主要数据来源(Brown et al., 2020; Raffel et al., 2019)。尽管在Common Crawl上进行训练是有效的,但最近的研究表明,数据集的多样性能够带来更好的下游泛化能力(Rosset, 2019)。此外,大规模语言模型已经证明,只需相对较少的训练数据,就能有效地在新领域中获取知识(Rosset, 2019; Brown et al., 2020; Carlini et al., 2020)。这些结果表明,通过将大量较小的高质量、多样化数据集混合在一起,可以提高模型的跨领域知识和下游泛化能力,相比于仅使用少数数据源训练的模型。
为了满足这一需求,我们提出了The Pile:一个825.18 GiB的英语文本数据集,专为训练大规模语言模型而设计。The Pile由22个多样化的高质量数据集组成,包括已有的自然语言处理数据集和几个新引入的数据集。除了在训练大规模语言模型中的实用性外,The Pile还可以作为评估语言模型跨领域知识和泛化能力的广泛覆盖基准。
我们引入了来自以下来源的新数据集:PubMed Central、ArXiv、GitHub、FreeLaw Project、Stack Exchange、美国专利商标局、PubMed、Ubuntu IRC、HackerNews、YouTube、PhilPapers和NIH ExPorter。我们还引入了OpenWebText2和BookCorpus2,它们分别是原始OpenWebText(Gokaslan and Cohen, 2019)和BookCorpus(Zhu et al., 2015; Kobayashi, 2018)数据集的扩展版本。
此外,我们还整合了几个现有的高质量数据集:Books3(Presser, 2020)、Project Gutenberg(PG-19)(Rae et al., 2019)、OpenSubtitles(Tiedemann, 2016)、英文维基百科、DM Mathematics(Saxton et al., 2019)、EuroParl(Koehn, 2005)和Enron Emails语料库(Klimt and Yang, 2004)。为了补充这些数据集,我们还引入了一个新的经过过滤的Common Crawl子集,Pile-CC,其提取质量有所提高。
通过我们的分析,我们确认The Pile与纯Common Crawl数据有显著差异。此外,我们的评估显示,现有的GPT-2和GPT-3模型在The Pile的许多组件上表现不佳,而使用The Pile训练的模型在原始和过滤后的Common Crawl模型上均显著优于它们。为了补充性能评估,我们还对The Pile中的文本进行了探索性分析,以提供数据的详细描述。我们希望通过对The Pile构建和特征的广泛记录,帮助研究人员在潜在的下游应用中做出明智的决策。
最后,我们公开了The Pile组成数据集的预处理代码以及构建替代版本的代码。为了确保可重复性,我们尽可能详细地记录了每个数据集(以及整个The Pile)的所有处理步骤。有关每个数据集处理的更多详细信息,请参见第2节和附录C。
2. The Pile数据集
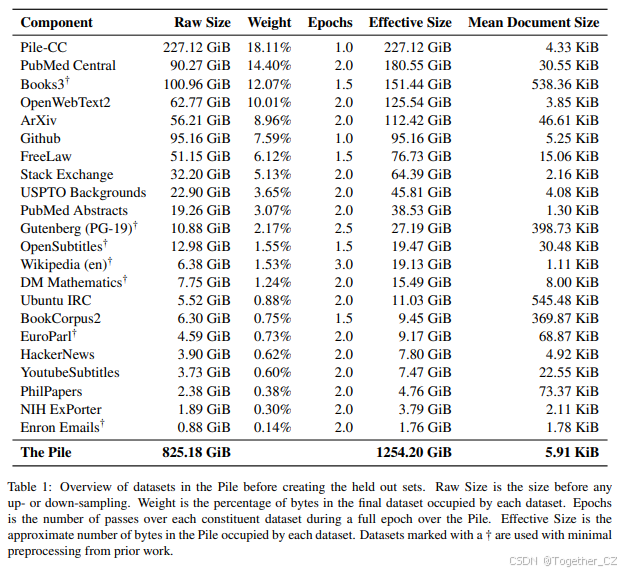
The Pile由22个组成子数据集组成,如表1所示。我们增加了高质量组件的权重,某些高质量数据集(如维基百科)在每个完整epoch中会被多次使用(最多3次)。有关每个数据集构建的详细信息可在附录C中找到。
2.1 Pile-CC
Common Crawl是从2008年开始的网站抓取集合,包括原始网页、元数据和文本提取。由于数据集的原始性质,Common Crawl具有包含来自不同领域的文本的优势,但代价是数据质量参差不齐。因此,使用Common Crawl通常需要设计良好的提取和过滤。我们基于Common Crawl的数据集Pile-CC使用justText(Endredy and Novak, 2013)从Web Archive文件(包括页面HTML的原始HTTP响应)中提取文本,这比直接使用WET文件(提取的纯文本)产生更高质量的输出。
2.2 PubMed Central
PubMed Central(PMC)是美国国家生物技术信息中心(NCBI)运行的PubMed在线存储库的一个子集,提供近500万篇出版物的开放全文访问。大多数由PMC索引的出版物都是近期的,并且自2008年起,NIH资助的所有研究都必须包含在PMC中。我们包含PMC,希望它能有益于医学领域的潜在下游应用。
2.3 Books3
Books3是从Bibliotik私人跟踪器的副本中提取的书籍数据集,由Shawn Presser(Presser, 2020)提供。Bibliotik包含小说和非小说类书籍,其规模比我们下一个最大的书籍数据集(BookCorpus2)大一个数量级。我们包含Bibliotik,因为书籍对于长距离上下文建模研究和连贯的叙事研究非常宝贵。
2.4 OpenWebText2
OpenWebText2(OWT2)是一个受WebText(Radford et al., 2019)和OpenWebTextCorpus(Gokaslan and Cohen, 2019)启发的通用网页抓取数据集。与原始WebText类似,我们使用Reddit提交的净投票数作为外链质量的代理。OpenWebText2包括截至2020年的Reddit提交内容、多种语言的内容、文档元数据、多个数据集版本以及开源复制代码。我们包含OWT2作为一个高质量的通用数据集。
2.5 ArXiv
ArXiv是一个自1991年运行的预印本服务器,主要涵盖数学、计算机科学和物理学领域。我们包含ArXiv,希望它能成为高质量文本和数学知识的来源,并有益于这些领域的研究。ArXiv论文使用LaTeX编写,LaTeX是数学、计算机科学、物理学和一些相关领域的常见排版语言。训练一个能够生成LaTeX论文的语言模型可能对研究社区大有裨益。
2.6 GitHub
GitHub是一个大型的开源代码仓库集合。受GPT-3(Brown et al., 2020)尽管训练数据中没有明确收集代码数据集,但仍能生成合理代码补全的能力的启发,我们包含GitHub,希望它能提高代码相关任务的下游表现。
2.7 FreeLaw
Free Law Project是一个美国注册的非营利组织,提供对法律领域学术研究的访问和分析工具。CourtListener是Free Law Project的一部分,提供数百万份联邦和州法院的法律意见的批量下载。虽然完整数据集提供了多种法律程序模式,包括案件记录、法官的文献信息和其他元数据,但我们特别关注法院意见,因为其中包含大量全文条目。这些数据完全属于公共领域。
2.8 Stack Exchange
Stack Exchange Data Dump包含Stack Exchange网络上所有用户贡献内容的匿名集合,Stack Exchange是一个以用户贡献的问题和答案为中心的流行网站集合。它是最大的公开问答对存储库之一,涵盖了从编程到园艺再到佛教的广泛主题。我们包含Stack Exchange,希望它能提高下游模型在多样化领域中的问答能力。
2.9 USPTO Backgrounds
USPTO Backgrounds是美国专利商标局授予的专利的背景部分数据集,源自其发布的批量档案。典型的专利背景部分会概述发明的一般背景,给出技术领域的概述,并设定问题空间的框架。我们包含USPTO Backgrounds,因为它包含大量针对非技术受众的应用主题的技术写作。
2.10 英文维基百科
维基百科是语言建模的标准高质量文本来源。除了作为高质量、干净的英语文本来源外,它还因其以说明文形式撰写并涵盖许多领域而具有价值。
2.11 PubMed Abstracts
PubMed Abstracts包含PubMed中3000万篇出版物的摘要,PubMed是由美国国家医学图书馆运行的生物医学文章在线存储库。虽然PMC(见第2.2节)提供全文访问,但其覆盖范围显著有限且偏向近期出版物。PubMed还包含MEDLINE,扩展了从1946年至今的生物医学摘要的覆盖范围。
2.12 Project Gutenberg
Project Gutenberg是一个经典西方文学数据集。我们使用的特定Project Gutenberg派生数据集PG-19包含1919年之前的Project Gutenberg书籍,这些书籍代表了与更现代的Books3和BookCorpus不同的风格。此外,PG-19数据集已经用于长距离上下文建模。
2.13 OpenSubtitles
OpenSubtitles数据集是由Tiedemann(2016)收集的电影和电视节目字幕的英语数据集。字幕提供了自然对话的重要来源,以及对非散文类虚构格式的理解,这可能对创意写作生成任务(如剧本创作、演讲写作和互动故事讲述)有用。
2.14 DeepMind Mathematics
DeepMind Mathematics数据集包含来自代数、算术、微积分、数论和概率等主题的数学问题集合,格式为自然语言提示(Saxton et al., 2019)。大型语言模型的一个主要弱点是数学任务的表现不佳(Brown et al., 2020),这可能部分是由于训练集中缺乏数学问题。通过明确包含数学问题数据集,我们希望提高在The Pile上训练的语言模型的数学能力。
2.15 BookCorpus2
BookCorpus2是原始BookCorpus(Zhu et al., 2015)的扩展版本,BookCorpus是一个广泛使用的语言建模语料库,由“尚未出版的作者”撰写的书籍组成。因此,BookCorpus不太可能与Project Gutenberg和Books3有显著重叠,后者由已出版的书籍组成。BookCorpus也常用于训练语言模型(Radford et al., 2018; Devlin et al., 2019; Liu et al., 2019)。
2.16 Ubuntu IRC
Ubuntu IRC数据集源自Freenode IRC聊天服务器上所有Ubuntu相关频道的公开聊天记录。聊天记录数据提供了建模实时人类互动的机会,这些互动具有其他社交媒体中通常不具备的自发性。
2.17 EuroParl
EuroParl(Koehn, 2005)是一个多语言平行语料库,最初用于机器翻译,但也已在其他自然语言处理领域中使用(Groves and Way, 2006; Van Halteren, 2008; Ciobanu et al., 2017)。我们使用撰写时最新的版本,其中包含1996年至2012年欧洲议会的21种欧洲语言的会议记录。
2.18 YouTube Subtitles
YouTube Subtitles数据集是从YouTube上人工生成的封闭字幕中收集的平行文本语料库。除了提供多语言数据外,YouTube Subtitles还是教育内容、流行文化和自然对话的来源。
2.19 PhilPapers
PhilPapers数据集由加拿大西安大略大学数字哲学中心维护的国际数据库中的开放获取哲学出版物组成。我们包含PhilPapers,因为它涵盖了广泛的抽象、概念性论述,并且其文章包含高质量的学术写作。
2.20 NIH Grant Abstracts: ExPORTER
NIH Grant Abstracts通过ExPORTER服务提供了1985年至今的获奖申请的批量数据存储库。我们包含该数据集,因为它包含高质量科学写作的示例。
2.21 HackerNews
HackerNews是由Y Combinator运营的链接聚合器,Y Combinator是一个初创企业孵化器和投资基金。用户提交的文章定义为“任何满足智力好奇心的内容”,但提交的文章往往集中在计算机科学和创业领域。用户可以评论提交的故事,形成讨论和批评提交故事的评论树。我们抓取、解析并包含这些评论树,因为我们相信它们提供了关于小众主题的高质量对话和辩论。
2.22 Enron Emails
Enron Emails数据集(Klimt and Yang, 2004)是一个有价值的语料库,常用于研究电子邮件的使用模式。我们包含Enron Emails,以帮助理解电子邮件通信的模式,这种模式在我们的其他数据集中通常不存在。
3. 使用The Pile进行语言模型基准测试
虽然The Pile被构想为大规模语言模型的训练数据集,但其覆盖多个不同领域的特点也使其适合作为评估数据集。在本节中,我们描述了如何将The Pile用作广泛覆盖的基准测试数据集。
3.1 基准测试指南
The Pile提供了训练、验证和测试集。验证和测试集各包含0.1%的数据,均匀随机采样。虽然这个比例远小于大多数数据集,但由于数据集的巨大规模,验证和测试集各自仍超过1 GiB。我们强调,尽管我们已尽力去重(见第D.2节),但仍有可能在训练/验证/测试集之间存在重复文档。
我们首选的指标是每UTF-8编码字节的比特数(bpb)。由于其对不同分词方案的不变性和Unicode中字符测量的模糊性,使用The Pile作为指标时,比特每字节优于比特每字符或困惑度。为了从给定的负对数似然损失ℓ计算比特每字节,我们使用公式:bpb = (L_T / L_B) log_2(e^ℓ) = (L_T / L_B) ℓ / ln(2),其中L_T是数据集的标记长度,L_B是数据集的UTF-8编码字节长度。我们发现,L_T / L_B在The Pile中为0.29335 GPT-2标记/字节;数据集特定的L_T / L_B值可在表7中找到。
3.2 使用GPT-2和GPT-3进行测试困惑度计算
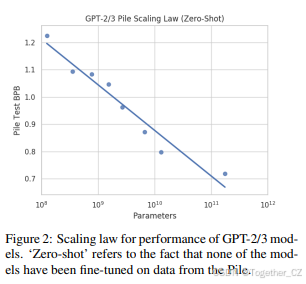
我们使用GPT-2(Radford et al., 2019)和GPT-3(Brown et al., 2020)计算The Pile组成数据集的测试困惑度,如图2所示。我们使用所有可用的GPT-2版本,以及通过OpenAI API提供的所有四个GPT-3版本。由于使用OpenAI API的成本较高,我们对大多数组成数据集的测试集进行了十分之一的评估。我们报告了转换为每UTF-8编码字节的比特数(bpb)的困惑度。重要的是,我们通过在每个数据集中独立评估每个文档来计算困惑度,而不是像通常在大规模语料库上计算困惑度那样将所有文档连接起来。
困惑度计算的完整细节可在附录E.2中找到。
不出所料,较大的语言模型通常比较小的模型获得更低的困惑度。最近的工作表明,语言模型的实证缩放规律越来越受到关注(Kaplan et al., 2020; Henighan et al., 2020)。因此,我们研究了GPT-2和GPT-3模型家族在The Pile上困惑度评估的缩放规律。GPT-3模型家族的缩放规律如图2.10所示。图中显示的最佳拟合线的系数为-0.1674,截距为2.5516。
有趣的是,尽管GPT-2和GPT-3没有在The Pile上进行训练,但仍然存在明显的缩放规律,且没有收益递减的现象。我们假设这是由于这些模型固有的泛化能力。我们将对零样本缩放规律的更严格分析留给未来的工作。
3.3 GPT-3在The Pile上的相对组件性能
确定GPT-3在哪些组件上表现不佳,可以提供关于哪些The Pile组件与GPT-3训练数据的文本分布(网页和书籍)最不相似的信息。这些组件因此特别适合作为补充GPT-3训练数据的候选。这些结果对于确定未来The Pile迭代中应强调哪些类型的数据集也很有价值。
由于不同数据集的熵不同,直接比较GPT-3在不同The Pile组件上的困惑度并不能准确反映相对性能。理想情况下,我们会在The Pile上从头训练一个GPT-3模型,并比较每个数据集的损失差异与原始GPT-3的差异。由于资源限制,我们改为使用在The Pile上从头训练的GPT-2模型(见第4节)构建一个代理度量。为了构建我们的代理度量,我们首先测量从GPT-2-Pile模型到GPT-3在每个组件上的改进。然后,我们通过将OpenWebText2上的变化设为零来归一化结果。该计算如下所示:
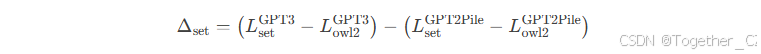
由于GPT2-Pile在OWT2和我们要评估的数据集上都进行了训练,我们期望ΔsetΔset中的第二项反映两个数据集的内在难度差异。因此,Δse的总值反映了我们要评估的数据集对于GPT-3来说比OWT2更难的程度,减去两个任务的相对难度。由于GPT-3在与OWT2非常相似的数据上进行了训练,这为我们提供了一个代理度量,用于衡量如果GPT-3在The Pile上进行训练,其表现会有多大提升。
结果如图3所示。作为健全性检查,我们观察到包含在GPT-3训练集中或与其非常相似的数据集(Books3、Wikipedia (en)、Pile-CC和Project Gutenberg)在我们的度量上得分接近零。
GPT-3在涉及研究或学术写作的数据集(如PubMed Central、PubMed Abstracts和ArXiv)、特定领域的数据集(如FreeLaw、HackerNews和USPTO Backgrounds)以及主要包含非自然语言文本的数据集(如GitHub和DM Mathematics)上表现不佳。此外,大多数数据集的改进程度低于OpenWebText2。因此,我们期望在The Pile上训练的GPT-3规模模型在研究相关任务、软件任务和符号操作任务上比基础模型表现显著更好。此外,该实验提供了证据,表明The Pile的大多数组件与主要基于网页的GPT-3训练数据并不冗余。
我们注意到,该度量仅是一个相似性的代理,可能会受到数据集特定缩放效应的干扰。尽管我们的结果在很大程度上符合预期,但仍有一些令人困惑的结果,例如GPT-3在某些数据集上表现优于GPT-2 Pile。我们假设GPT-3在这些数据集上表现得如此之好,以至于显式训练它们并不会显著提升模型的性能。我们将对这些效应的更严格分析留给未来的工作。
4. 评估
为了确认The Pile在提高语言建模质量方面的有效性,我们训练了基于Brown et al. (2020)中模型的架构相同的13亿参数模型,并在WikiText和LAMBADA任务上进行了评估,作为语言建模能力的基准。我们还报告了在The Pile上的结果,作为更广泛的跨领域泛化能力的衡量标准。
4.1 方法论
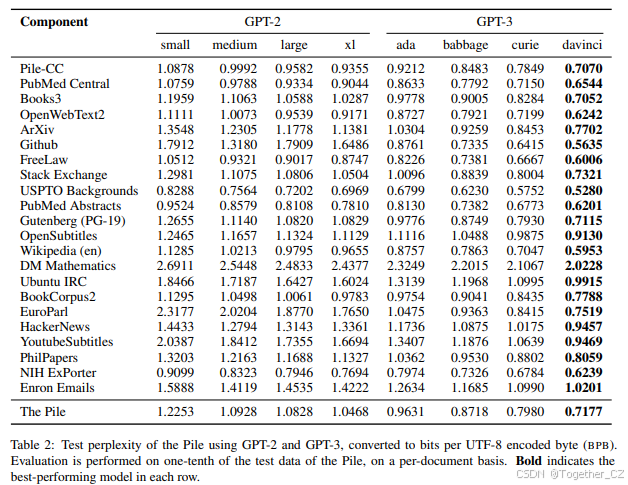
为了确保在不同大小的数据集之间进行公平比较,我们使用与Brown et al. (2020)相同的13-gram重叠过滤对评估集进行去污染,并将数据集大小控制在40GB。由于我们控制了数据集大小,我们强调我们的评估对CC-100(en)是慷慨的,因为其实际大小约为The Pile的三分之一。
我们比较了以下数据集:The Pile、CC-100数据集的英语部分(Wenzek et al., 2019; Conneau et al., 2020)以及经过过滤的原始CC WET文件的英语样本。
4.2 结果
在传统的语言建模基准上,The Pile在WikiText上显著改进,而在LAMBADA上变化不大。然而,使用The Pile训练的模型在所有The Pile组件上均显著优于原始CC和CC-100,如表4所示。这表明,使用The Pile训练的模型在不影响传统基准性能的情况下,具有更强的跨领域泛化能力。
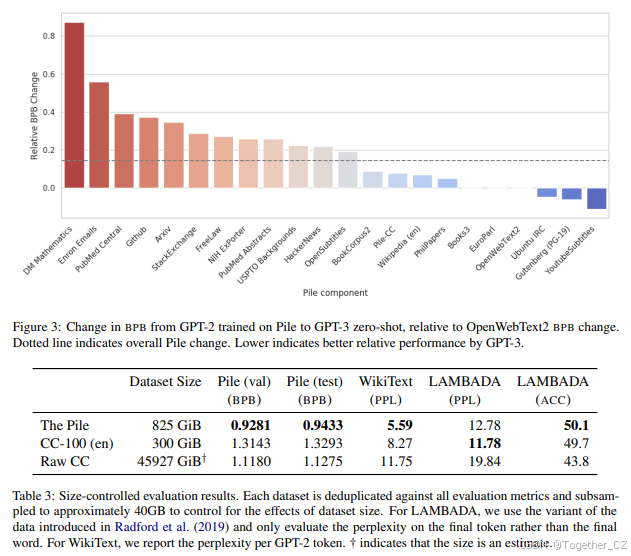
图4显示了每个测试集上The Pile模型相对于CC-100模型的bpb改进幅度。不出所料,Pile-CC几乎没有改进。然而,在学术数据集(如ArXiv、Pubmed Central、FreeLaw和PhilPapers)上,使用The Pile训练的模型显著优于其他两个模型。在编程相关数据集(如Github和StackExchange)、EuroParl(由于其他数据集中缺乏多语言文本)和DM Mathematics上,模型表现也有显著提升,表明数学能力显著提高。
令人惊讶的是,原始Common Crawl在The Pile BPB上的表现优于CC-100,尽管在LAMBADA和WikiText上显著落后。我们假设这是由于CC-100中使用的基于困惑度的过滤,其中在维基百科上训练语言模型,并丢弃困惑度过高或过低的数据。这有效地丢弃了与维基百科过于相似或过于不同的数据,严重限制了收集数据的多样性。这一结果表明,未来使用Common Crawl的工作应谨慎过滤,以保持其多样性。
5. 结构统计
在本节中,我们介绍了数据集的结构统计信息,这些信息提供了关于The Pile的更粗粒度和统计性的描述。在第6节中,我们将对The Pile数据集中的文本内容进行更深入的调查和记录。
5.1 文档长度和分词
每个数据集由大量文档组成。我们分析了文档长度的分布,以及使用GPT-2分词器时每个标记的字节数,以便为我们的消融实验提供上下文。
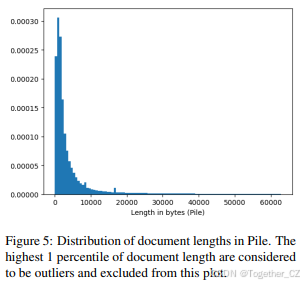
虽然The Pile中的大多数文档较短,但存在一些非常长的文档(图5)。
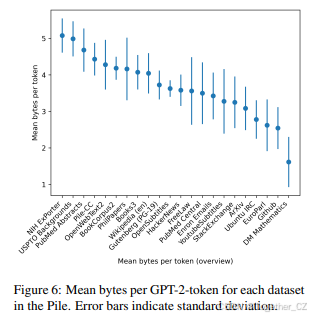
由于GPT-2的BPE分词器是在WebText上训练的,因此每个标记的平均字节数也可以粗略地指示每个The Pile组件与WebText在语法上的差异。例如,像NIH ExPorter、OpenWebText2和Books3这样的数据集主要由与WebText相似的普通文本组成,这反映在较高的字节/标记数上。另一方面,许多字节/标记数最低的数据集主要由非文本内容(如GitHub、ArXiv、Stack Exchange和DM Mathematics)或非英语语言(如EuroParl)组成。
5.2 语言和方言
虽然全球只有13%的人口说英语,但绝大多数自然语言处理(NLP)研究都是基于英语进行的。对于The Pile,我们采取了与Brown et al. (2020)类似的方法,主要关注英语,同时在收集数据时并不明确过滤掉其他语言。在评估多语言数据集时,我们的主要纳入标准是该数据集的英语部分是否值得单独包含。我们计划在未来工作中创建一个完全多语言的The Pile扩展。
使用fasttext(Suarez et al., 2019),我们确定The Pile中97.4%的内容是英语。我们注意到,由于语言识别的问题,特别是对于稀有语言(Caswell et al., 2020),这种方法仅提供了英语内容的粗略估计,无法对低资源语言得出可靠的结论。
6. 数据集的调查和记录
随着机器学习研究规模的扩大,人们越来越关注模型训练所使用的越来越大的数据集(Prabhu and Birhane, 2020; Biderman and Scheirer, 2020)。尽管在AI伦理和偏见研究中已经提出了这一问题(Hovy and Spruit, 2016; Hutchinson et al., 2020; Blodgett et al., 2020),但在语言建模社区中,这一问题尚未成为关注的焦点。尽管有大量工作探索和记录数据集的问题(Gebru et al., 2018; Bender and Friedman, 2018),但这些工作主要集中在计算机视觉领域,而不是自然语言处理。
为了帮助研究人员更好地理解The Pile数据集,我们提供了两种形式的文档:数据表(datasheet)和数据声明(data statement)。数据表最初是为计算机视觉数据集提出的(Gebru et al., 2018),但已被广泛采用,并扩展到其他领域(Seck et al., 2018; Costa-jussà et al., 2020; Thieme et al., 2020)。数据声明方法(Bender and Friedman, 2018)是专门为自然语言处理提出的,并得到了NLP社区的广泛认可。我们的数据表和数据声明将发布在The Pile代码的GitHub仓库中,并作为单独的文档在arXiv上提供(Biderman et al., 2021; Biderman, 2021)。
除了数据表和数据声明外,还有一些额外的信息可能对训练语言模型的研究人员有帮助,而这些文档并未涵盖。在本节的其余部分,我们将更详细地调查和记录一些额外的上下文信息。
6.1 主题分布
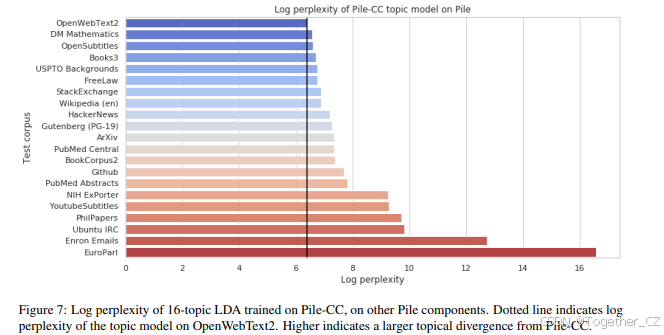
为了更好地理解The Pile所涵盖的具体主题,我们对其组件进行了主题建模分析。使用Gensim(Rehurek et al., 2011),我们在The Pile验证集的每个组件上训练了16个主题的Latent Dirichlet Allocation(LDA)模型(Blei et al., 2003),并以在线方式进行(Hoffman et al., 2010)。我们过滤了The Pile中的英语内容进行分析。之后,我们计算了Common Crawl派生(Pile-CC)主题模型在其他组件文档集上的困惑度。通过这种方式,我们提供了一个粗略的度量,用于衡量The Pile的哪些部分包含Common Crawl中未充分涵盖的主题。
在图7中,展示了这些跨组件的困惑度,垂直线表示Pile-CC主题模型在OpenWebText2文档上的困惑度。选择该组件作为基线比较的原因与之前的评估类似:它是以与Common Crawl类似的方式(过滤的开放网页抓取)派生的,因此预计包含类似的主题分布。尽管Pile-CC在内容上具有一定的多样性,但The Pile的其他几个组件在主题焦点上与Pile-CC存在显著差异,如Github、PhilPapers和EuroParl的较高困惑度所示。
我们还记录了从每个组件的LDA模型中推断出的主题聚类,并在附录C中提供了这些聚类。正如预期的那样,尽管较大的CC派生组件本身代表了多样化的内容——包括政治、教育、体育和娱乐——但与其他The Pile组件相比,它遗漏的内容集群变得显而易见。值得注意的是,编程、逻辑、物理和法律知识的数据模式在很大程度上是缺失的。
6.2 贬义内容
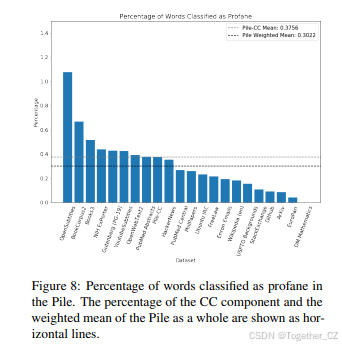
由于The Pile的来源广泛,可能会包含贬义、色情或其他令人反感的内容。由于这些内容可能不适合某些用例,我们按数据集分解了粗俗语言。
我们使用了profanity-checker Python包(Zhou, 2019)。该包包含一个“毒性模型”,该模型在多个粗俗语言列表以及Wikidetox Toxic Comment Dataset(Wulczyn et al., 2016)上进行了训练,并将给定字符串分类为粗俗或非粗俗。
我们仅考虑了每个数据集中的英语句子,使用了与第3.7节相同的语言分类器。我们这样做是因为profanity-checker是为英语构建的,其他语言可能会不恰当地影响结果。例如,德语的主格/宾格阴性/复数定冠词“die”会被标记为粗俗,无论上下文如何。我们将每个句子拆分为单词,并计算每个The Pile组件中被标记为粗俗的单词的百分比。我们强调,这种方法仅是对粗俗语言的代理度量,因为确定某个单词或短语在上下文中是否粗俗是复杂的。
如图8所示,The Pile作为一个整体似乎比Pile-CC更少包含粗俗语言。此外,大多数The Pile组件似乎也比Pile-CC更少包含粗俗语言。
我们还按句子分解了每个数据集,以允许profanity-checker检查整个句子。按句子拆分数据集允许在确定内容是否贬义时考虑额外的上下文。我们的结果如图12所示。
6.3 偏见和情感共现
由于语言模型可能会从训练数据中学习到意外的偏见,我们对构成The Pile的不同组件进行了初步分析。由于可能会在The Pile上训练具有不同特征的模型,我们的目标是记录数据的偏见,而不是特定模型的偏见。我们主要关注共现测试,其中我们分析了哪些单词与特定单词出现在同一句子中。利用这些信息,我们可以估计哪些单词强烈偏向于某个类别单词,并计算周围单词的总体情感。
我们主要关注性别、宗教和种族。我们的目标是为该数据集的用户提供初步指导,了解不同组件的偏见,以便他们可以决定在哪些组件上进行训练。
本节中的所有表格和图表可在附录中找到。
6.3.1 性别
我们通过计算二元代词的共现来计算性别关联。对于每个单词,我们计算其与“he”和“she”共现率的差异,并按频率的平方根加权。我们在表10中报告了每个性别的前15个最有偏见的形容词或副词(Loper and Bird, 2002)。我们看到像“military”、“criminal”和“offensive”这样的单词强烈偏向于男性,而“little”、“married”、“sexual”和“happy”则偏向于女性。
此外,我们计算了每个数据集中与性别代词共现的单词的平均情感(Baccianella et al., 2010)。总体而言,我们发现对男性或女性没有显著的情感偏见。当然,这并不意味着数据集没有性别偏见(如我们的共现测试所示)。
6.3.2 宗教
我们对宗教进行了类似的共现分析,结果可在表11中找到。与性别一样,我们发现这些共现反映了这些术语在在线讨论中的使用方式。例如,“radical”与“muslim”共现率较高,而“rational”则经常与“atheist”共现。该分析还展示了纯共现分析的一些局限性。例如,“religious”经常与“atheist”共现,这可能反映了“atheist”一词可能出现的对话类型,而不是对“atheist”的描述。
此外,我们计算了每个组成数据集中共现的平均情感。在整个数据集中,我们发现“Buddhist”的情感最高,其次是“Hindu”、“Christian”、“Atheist”和“Muslim”。值得注意的是,“Jew”的情感最低,可能反映了其历史上的贬义用法。
6.3.3 种族
最后,我们对种族群体进行了相同的分析。在这里,由于像“black”或“white”这样的标识符通常不表示种族,我们改为计算与“black man”或“white woman”等短语的共现。
我们在表12中展示了每个种族群体的前15个最有偏见的单词。再次,我们发现共现反映了这些术语的使用背景。例如,“black”的4个最有偏见的单词是“unarmed”、“civil”、“criminal”和“scary”。
与上述类似,我们计算了共现单词的平均情感。我们在表13中报告了平均情感数值。我们发现“hispanic/latino”以微弱优势超过“asian”,情感最高,其次是“white”。另一方面,“black”的情感最低,为-0.15。
我们注意到,对于所有种族群体,平均情感都是负面的。我们假设这是由于我们用于计算共现的短语出现的特定背景。例如,新闻文章通常将嫌疑人描述为“asian man”。
6.4 作者同意和公共数据
在自然语言处理研究中使用文本的另一个问题是同意。虽然通常没有法律义务获得作者的许可来训练NLP算法,但许多人认为这样做是一种道德义务或防止滥用的良好措施(Obar, 2020; Prabhu and Birhane, 2020)。另一方面,关于在研究背景下重新使用受服务条款保护的数据的伦理问题存在重大分歧(Vitak et al., 2016; Fiesler et al., 2020),特别是考虑到数字平台中固有的权力不对称,这些平台通常阻止独立研究人员调查公共数据,同时迫使用户同意其私人使用(Halavais, 2019)。
尽管The Pile的大部分数据来自明确同意其广泛传播和用于研究的来源,但研究人员通常未能清楚地记录其数据的来源及其使用条款。鉴于此,我们觉得有必要在发布The Pile时,透明地说明其数据的作者如何表示这些数据的使用方式。
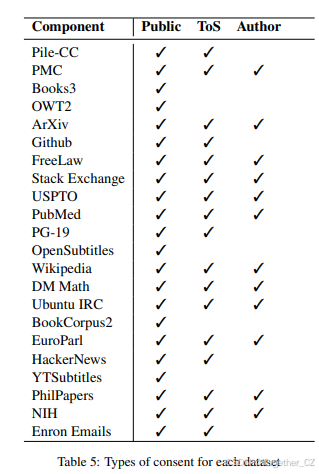
为了提供必要的细微差别,我们确定了公共使用的三个可用性层级。公共数据是可以在互联网上自由和轻松获得的数据。这主要排除了付费墙后的数据(无论该付费墙是否容易绕过)以及无法轻松获得但可以通过种子或暗网获得的数据。符合服务条款(ToS)的数据是以已知符合数据宿主服务条款的方式获取和使用的数据。获得作者同意的数据是原始作品的作者同意使用其数据的数据,或者一个合理的人不会假设其数据不会用于研究等目的的数据。符合服务条款的数据和获得作者同意的数据在两个主要方面有所不同:重要的是要记住,人们通常不会阅读服务条款,此外,符合服务条款并不意味着获得了作者同意。我们采用了严格的同意模型,其中模糊或未知的同意被视为非同意。
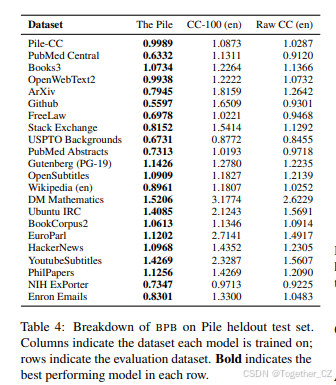
表5总结了我们对其The Pile中每个数据集状态的理解。标记为✓的数据集在相关方面是合规的,但有几个数据集值得特别说明。Books3和OpenSubtitles的使用方式与数据宿主的服务条款一致。然而,这有些误导,因为数据宿主未经拥有数据的各方授权将数据发布在网上。Enron Emails数据集未经作者许可收集,而是由美国政府作为刑事调查的一部分收集的。虽然其电子邮件包含在Enron数据集中的人知道这一事实,但他们没有能力同意其包含。
The Pile中包含的五个数据集未以符合服务条款的方式收集和分发,且作者无法同意其数据的使用。这些数据集在NLP文献和全球范围内被广泛使用。除了YouTube Subtitles数据集外,每个数据集都是由研究人员发布的,并在互联网上自由传播。YouTube Subtitles数据集是我们为该项目创建的,使用了一个非常流行的非官方API,该API在Pip、Conda和GitHub等平台上广泛使用且易于获取。鉴于所应用的处理以及在The Pile中识别特定文件的难度,我们认为使用这些数据集不会显著增加超出这些数据集广泛发布所带来的危害。
7. 影响和更广泛的影响
The Pile代表了在扩展模型和数据集到更大规模和能力道路上的又一块垫脚石。关于逐渐强大的AI系统将如何影响更广泛的世界,存在许多严重的担忧(Brundage et al., 2018; Amodei et al., 2016; Bostrom and Yudkowsky, 2014; Bostrom, 2014; Critch and Krueger, 2020),我们认为这些担忧值得认真思考。在本节中,我们讨论了The Pile的法律影响,然后从两个角度考虑The Pile对AI对齐的影响:加速AI时间线和未对齐语言模型的危险。
7.1 内容的合法性
尽管机器学习社区已经开始讨论在版权数据上训练模型的合法性问题,但很少有人承认处理和分发他人拥有的数据也可能违反版权法。作为朝这个方向迈出的一步,我们讨论了为什么我们认为我们对版权数据的使用符合美国版权法。
根据1984年的Sony Corp. of America v. Universal City Studios, Inc.案(并在随后的裁决中确认,如2013年的Righthaven LLC v. Hoehn案和2015年的Authors Guild v. Google案),非商业、非营利的版权媒体使用是预先的合理使用。此外,我们的使用是变革性的,因为数据的原始形式对我们的目的无效,而我们的数据形式对原始文档的目的无效。尽管我们使用了版权作品的全文,但这并不一定是不合格的,因为全文对于产生最佳结果是必要的(Dai et al., 2019; Rae et al., 2019; Henighan et al., 2020; Liu et al., 2018)。
版权法因国家而异,某些作品在特定司法管辖区可能会有额外的限制。为了更容易遵守当地法律,The Pile的复制代码是可用的,并且可以用于排除The Pile中不适合用户的某些组件。不幸的是,我们没有必要的元数据来确定哪些文本是受版权保护的,因此这只能在组件级别进行。因此,这应被视为启发式而非精确确定。
7.2 加速AI时间线
人们严重担心AI系统可能很快在所有相关经济任务中比人类更有能力(Grace et al., 2018; Yudkowsky, 2013)。与此相关的是,关于如何正确对齐如此强大的AI系统与人类利益的问题尚未解决(Bostrom and Yudkowsky, 2014; Russell, 2019; Bostrom, 2014; Amodei et al., 2016),并且通常避免道德灾难性结果(Sotala and Gloor, 2017; Shulman and Bostrom, 2020)。因此,有人认为在这些担忧得到更充分解决之前,加速开发如此强大的AI系统可能是不明智的(Bostrom, 2014)。
对此观点有几个务实的回应:
-
由于人类竞争、好奇心和文化的多样性,停止技术发展极其困难,甚至是不可能的(Russell, 2019; Critch and Krueger, 2020)。
-
AI开发本质上是实验性的:对齐问题只能通过开发、测试和(希望是非存在性的)失败来解决。
-
高能力语言模型及其更通用的后继者必须能够查看道德上有问题的内容,而不会在其输出中采用这些内容。我们将在下一节中详细阐述这一点。
考虑到这一点,我们接受The Pile可能加速AI时间线的现实。
7.3 语言模型的负面输出
关于强大语言模型可能带来的负面影响的讨论已经很多(Brown et al., 2020; Brundage et al., 2018)。其中一些问题,例如为搜索引擎优化(SEO)目的大规模生成低质量内容,是互联网内容分发方式固有的问题,仅靠开发语言模型无法解决。直接解决这些问题需要对互联网架构进行重大变革,例如大幅扩展公钥基础设施(PKI)和分布式身份验证(Ferguson and Schneier, 2003)。
另一个担忧是,训练这些模型所需的大规模数据集几乎不可避免地会包含不良内容,例如宣扬仇恨的刻板印象(Christian, 2020)。让模型输出不良内容显然是不可取的,但我们认为从训练集的角度来解决这个问题是徒劳的,并且最终会让我们远离最佳解决方案。如果一个人阅读了一篇种族主义内容,他们不会立即采纳其种族主义观点——他们可能具备这种能力,但可以选择不这样做。这种理解不良内容并决定忽略它的能力是未来研究的一个重要方向。这不仅可以让模型在“脏”数据上训练时减少担忧,还可以利用其获得的知识更好地理解什么是不该做的。我们认识到,尽管最近在人类引导学习方面取得了进展(Stiennon et al., 2020),但技术尚未达到这一阶段,因此我们在本文中做出了一些编辑决策。然而,这种方法似乎对这些模型和更广泛的AI的未来至关重要,需要更多的研究。
8. 相关工作
在自然语言处理领域,使用大规模未标记文本语料库进行自监督训练已经得到了广泛采用。词表示模型如GloVe(Pennington et al., 2014)和word2vec(Mikolov et al., 2013)在诸如维基百科、Gigaword(Graff et al., 2003)或非公开的Google新闻语料库等数据集上进行了训练。最近,语言模型(Radford et al., 2018, 2019; Brown et al., 2020; Rosset, 2019; Shoeybi et al., 2019)和掩码语言模型(Devlin et al., 2019; Liu et al., 2019; Raffel et al., 2019)在诸如维基百科、BookCorpus(Zhu et al., 2015)、RealNews(Zellers et al., 2019)、CC-Stories(Trinh and Le, 2018)以及其他互联网抓取数据集上进行了训练。其他数据集如WikiText(Stephen et al., 2016)也用于类似的自监督训练。
随着语言建模对数据需求的增长,该领域已转向互联网抓取以获取大规模数据集(Gokaslan and Cohen, 2019),其中Common Crawl尤为普遍。诸如Brown et al. (2020); Wenzek et al. (2019); Suarez et al. (2019); Raffel et al. (2019)等研究依赖Common Crawl来构建大规模模型的训练数据集。然而,这些研究通常强调清理和过滤Common Crawl数据的困难,并强调数据质量是模型能力的关键因素。
在训练语言模型时,结合多个数据集的做法也越来越普遍。例如,GPT(Radford et al., 2018)在维基百科和BookCorpus上进行了训练,而GPT-3(Brown et al., 2020)则在维基百科、两个小说数据集和两个网页抓取数据集上进行了训练。The Pile延续了将大规模网页抓取与较小但高质量数据集结合的趋势,这些数据集捕捉了我们认为对训练语言模型最有用的知识。
与The Pile最相似的两个公开可用数据集是CC-100(Wenzek et al., 2019)和C4/mC4(Raffel et al., 2019)。C4与The Pile的规模相当,而mC4和CC-100是更大的多语言数据集。然而,C4/mC4需要巨大的计算资源来预处理数据,其维护者甚至建议使用分布式云服务,这为使用这些数据集设置了高门槛。CC-100可直接下载并已预先清理;然而,其英语部分比The Pile小得多。重要的是,这三个数据集完全源自Common Crawl——正如上文所讨论的,当前训练大规模语言模型的最佳实践涉及同时使用大规模网页抓取和更有针对性的高质量数据集,而The Pile直接解决了这一问题。
附录
A. 贡献
所有作者都对研究项目的设计和论文的撰写做出了贡献。此外,作者的贡献如下:
-
Leo Gao:领导项目,实现了The Pile的主要代码库,贡献了模型训练代码,执行了评估和语言分析,解释了困惑度分析结果,实现了最终数据的处理,并处理了Pile-CC、PubMed Central、ArXiv和Ubuntu IRC。
-
Stella Biderman:领导了数据分析、更广泛的影响分析和数据记录,并协调了项目。她还撰写了结构统计、作者同意和版权法的分析。
-
Sid Black:实现了模型训练和评估代码,并处理了YouTube Subtitles、Stack Exchange和GitHub。
-
Laurence Golding:实现了去重,执行了n-gram分析,并处理了OpenWebText2。
-
Travis Hoppe:处理了FreeLaw、PubMed Abstracts、ExPorter和PhilPapers。
-
Charles Foster:执行了主题建模分析,贡献了关于作者同意的讨论,并处理了USPTO Backgrounds。
-
Jason Phang:实现并执行了GPT-2/3的困惑度分析,并为项目提供了建议。
-
Horace He:执行了偏见和情感分析。
-
Anish Thite:实现并执行了粗俗语言分析,并处理了Hacker News。
-
Noa Nabeshima:处理了GitHub。
-
Shawn Presser:处理了BookCorpus2。
-
Connor Leahy:撰写了对齐影响分析,并实现了模型训练代码。
B. 排除的数据集
在构建The Pile的过程中,我们考虑并最终决定不使用几个数据集。我们排除了几个数据集,因为它们太小,不值得花费时间,或者因为其英语部分本身不值得包含。然而,我们也决定排除其他一些数据集,出于透明性,我们在此记录这些原因:
-
美国国会记录:美国国会(1800年至今)的官方记录记录了美国最高政府层面的重要辩论点。它反映了过去200年政治阶层的观点和偏见,包括种族隔离主义和仇外心理。特别是,我们发现了大量极端种族主义内容,我们认为这些内容不适合用于通用语言建模的数据集。
-
同人小说:数百GB的同人小说已在网上发布,主要发布在www.fanfiction.net和www.archiveofourown.org等网站上。这代表了语言建模中一个重要的未开发资源,因为它几乎完全是短篇小说,这种写作风格在大多数语言建模数据集中并未体现。我们最终出于后勤原因排除了同人小说:我们发现其他数据源更容易获取。
-
Literotica:Literotica是一个用户可以上传短篇色情小说的网站。我们最初计划将其包含在The Pile中,甚至已经抓取并处理了它。然而,我们决定不包含它,原因有几个。首先,一旦我们决定排除同人小说,Literotica就成为了我们唯一的短篇小说来源,这可能会导致训练模型产生不良偏见。其次,Literotica需要比我们花费在其他数据集上更多的调查、评估和谨慎处理。第三,Literotica包含大量刻板印象,包括种族癖好。虽然Literotica可能适用于某些任务,但我们不放心将其包含在The Pile中。
结论
The Pile是一个多样化、高质量的大规模文本数据集,专为训练大规模语言模型而设计。通过结合多个领域的数据,The Pile显著提高了模型的跨领域泛化能力,并在多个下游任务中表现出色。我们详细记录了数据集的构建过程、内容特征以及潜在的问题,希望这些信息能帮助研究人员更好地理解和使用The Pile。未来,我们计划进一步扩展和优化The Pile,以支持更广泛的语言建模研究。



















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











