






本文介绍了一种名为 Spark-TTS 的高效文本到语音(TTS)模型,旨在通过创新的单流语音编解码器 BiCodec 和大型语言模型(LLM)实现零样本语音合成与可控语音生成。以下是文章的主要研究内容和贡献:
1. 研究背景与动机
-
现有的基于LLM的TTS模型依赖复杂的多阶段处理或多流码本预测,限制了效率和灵活性。
-
当前方法在零样本语音合成中存在局限性,如缺乏对音色和细粒度属性(如音高、语速)的精确控制。
-
现有研究中数据集的专有性和不一致性导致了标准化评估的困难。
2. BiCodec:单流语音编解码器
-
提出了一种新的语音标记化框架 BiCodec,将语音分解为两种互补的标记类型:
-
语义标记:以50个标记/秒(TPS)的低比特率捕捉语言内容。
-
全局标记:固定长度,用于编码说话者属性和其他全局特征。
-
-
BiCodec结合了语义标记的高效性和全局标记的音色控制能力,通过创新的量化方法(如有限标量量化FSQ)实现更优的语音重建性能。
3. Spark-TTS:零样本TTS与可控语音生成
-
基于BiCodec和Qwen2.5 LLM,Spark-TTS实现了零样本语音合成和可控语音生成。
-
提出了链式思维(CoT)生成框架,支持从粗粒度(如性别、音高水平)到细粒度(如精确音高值、语速)的语音属性控制。
-
Spark-TTS能够通过文本提示和属性标签生成高质量语音,无需参考音频,显著提升了零样本TTS的灵活性和可控性。
4. VoxBox:开源语音数据集
-
为了推动可控TTS的研究,作者构建了 VoxBox,一个包含10万小时语音数据的开源数据集,涵盖性别、音高、语速等多维度标注。
-
VoxBox的数据来源广泛,包括多种开源语音数据集,并经过严格的数据清洗和标注流程,为标准化评估提供了基础。
5. 实验与性能评估
-
BiCodec:在低比特率(<1kbps)下,BiCodec在语音重建质量上超越了现有编解码器,表现出更高的语义一致性和音色控制能力。
-
Spark-TTS:在零样本TTS任务中,Spark-TTS在语音可懂度(CER/WER)和语音质量(UTMOS)方面显著优于现有模型,同时支持细粒度的语音属性控制。
-
在性别、音高和语速控制方面,Spark-TTS展现了极高的准确性和灵活性,能够根据用户指定的属性生成高质量语音。
6. 贡献与创新点
-
提出了一种新的单流语音编解码器 BiCodec,结合语义标记和全局标记,实现了高效语音表示和音色控制。
-
开发了 Spark-TTS,首个支持零样本TTS和细粒度属性控制的TTS模型,显著提升了语音合成的灵活性和可控性。
-
构建了 VoxBox,一个大规模、高质量且标注丰富的开源语音数据集,为TTS研究提供了标准化的基准。
7. 局限性与未来工作
-
Spark-TTS在零样本TTS的说话者相似性方面表现弱于多阶段或非自回归(NAR)方法,未来将通过改进全局标记的解耦能力来增强音色控制。
-
计划引入对共振峰或音高的扰动,进一步优化音色的可控性,减少自回归模型带来的随机性。
论文通过创新的编解码器设计和语言模型集成,为零样本TTS和可控语音生成提供了新的解决方案,并为未来的研究提供了高质量的数据资源和评估基准。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
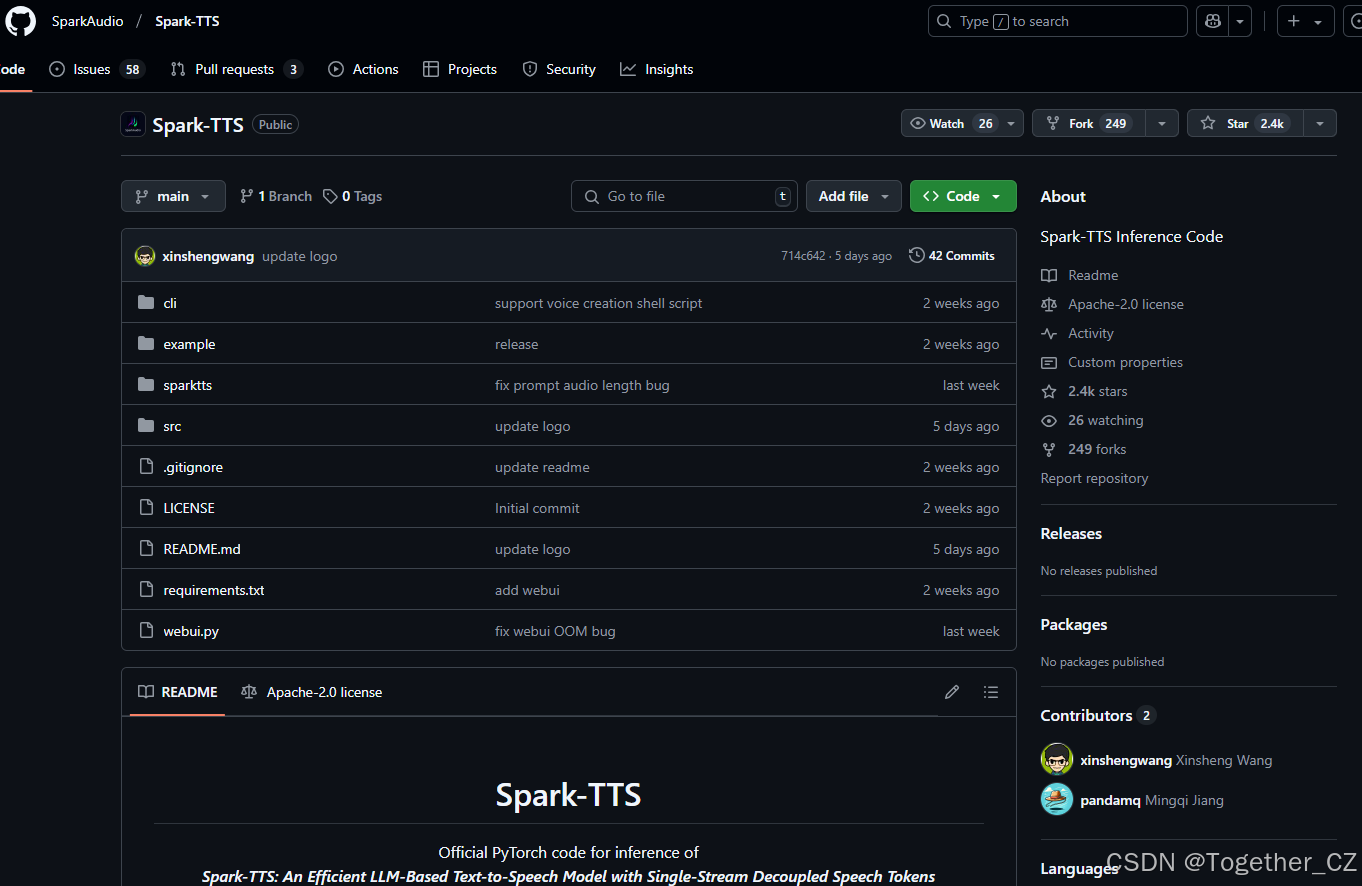
摘要
近期,大型语言模型(LLMs)的发展推动了零样本文本到语音(TTS)合成的显著进步。然而,现有的基础模型依赖于多阶段处理或复杂的架构来预测多个码本,限制了效率和集成灵活性。为了克服这些挑战,我们引入了Spark-TTS,这是一个由BiCodec驱动的创新系统,BiCodec是一个单流语音编解码器,将语音分解为两种互补的令牌类型:用于语言内容的低比特率语义令牌和用于说话者属性的固定长度全局令牌。这种解耦表示,结合Qwen2.5 LLM和链式思维(CoT)生成方法,实现了粗粒度控制(例如,性别、说话风格)和细粒度调整(例如,精确音高值、说话速率)。为了促进可控TTS的研究,我们引入了VoxBox,这是一个精心策划的10万小时数据集,带有全面的属性注释。广泛的实验表明,Spark-TTS不仅实现了最先进的零样本声音克隆,还生成了高度可定制的声音,超越了基于参考的合成的限制。
1. 引言
近期,语音标记化技术的发展通过弥合连续语音信号与离散标记基础的大型语言模型(LLMs)之间的基本差距,彻底改变了文本到语音(TTS)合成(Anastassiou等人,2024;Zhu等人,2024;Wang等人,2024c)。通过复杂的量化技术,尤其是矢量量化(VQ)(Van Den Oord等人,2017)和有限标量量化(FSQ)(Mentzer等人,2023),基于编解码器的LLMs已成为零样本TTS的主导范式。结合大量的训练数据和大规模模型架构,这些系统实现了前所未有的自然度,通常使合成语音与人类语音难以区分(Anastassiou等人,2024;Du等人,2024b;Chen等人,2024b;Ye等人,2024a)。尽管LLM基础的零样本TTS取得了显著进展,但仍存在一些基本挑战。当前基于编解码器的TTS架构表现出显著的复杂性,需要双生成模型(Wang等人,2023a;Anastassiou等人,2024)或复杂的并行多流代码预测机制(Kreuk等人,2023;Le Lan等人,2024),这与传统文本LLM框架大相径庭。这种差异源于现有音频编解码器的固有限制——虽然语义令牌提供了紧凑性,但它们需要额外的模型来预测声学特征(Du等人,2024a;Huang等人,2023),并且缺乏集成音色控制能力。声学令牌则依赖于复杂的码本架构,如分组矢量量化(Défossez等人,2022;Van Den Oord等人,2017)。该领域还面临新声音创建的挑战,因为当前系统主要限于基于参考的生成(Zhang等人,2023b;Chen等人,2024a),缺乏合成具有精确指定特征的声音的能力。这一限制进一步被属性控制的粒度不足所加剧,尤其是对于音高调制等细粒度特征,尽管在基于指令的生成方面取得了近期进展(Du等人,2024b)。此外,当前研究中广泛使用专有数据集,为标准化评估和有意义的方法比较创造了重大挑战(Anastassiou等人,2024;Ye等人,2024a)。这些限制共同强调了需要一种统一的方法,以简化架构,实现灵活的声音创建与全面的属性控制,并通过开放数据资源建立可复现的基准。
为了应对这些基本限制,我们引入了Spark-TTS,这是一个统一的系统,通过单个编解码器LLM实现零样本TTS与全面的属性控制,同时保持与传统文本LLM的架构一致性。此外,我们还介绍了VoxBox,这是一个经过精心策划和注释的开源语音数据集,为语音合成研究建立了基础。
2. 相关工作
2.1 单流语音标记器
早期的单流语音标记器主要关注提取语义标记(Huang等人,2023;Du等人,2024a;Tao等人,2024)。虽然纯语义标记能够实现低比特率编码,但它们需要在基于语义标记的语音合成中增加一个声学特征预测模块(Du等人,2024a,b)。最近,基于单流的声学标记化引起了相当多的关注(Xin等人,2024;Wu等人,2024)。WavTokenizer(Ji等人,2024a)采用基于卷积的解码器来提高重建质量,而X-codec2(Ye等人,2025)通过FSQ扩大了码空间。与遵循纯编码器-VQ-解码器范式不同,解耦语音内容已被证明在使用单个码本减少比特率方面是有效的(Li等人,2024a;Zheng等人,2024)。在这些方法中,TiCodec(Ren等人,2024)在处理全局信息方面与我们的方法最为相似。然而,与TiCodec不同的是,我们提出的BiCodec使用语义标记作为其时间变化标记。与其使用分组GVQ(Ren等人,2024),我们提出了一种基于FSQ的全局嵌入量化方法,该方法结合了可学习的查询和交叉注意力机制。这种方法能够生成相对较长的标记序列,提供更具表现力和灵活的表示。
2.2 基于LLM的零样本TTS
流行的编解码器LLM零样本TTS主要分为两类。第一种类型涉及使用LLMs预测单流代码,然后通过另一个LLM(Zhang等人,2023b;Chen等人,2024a;Wang等人,2024a)或生成扩散模型(Anastassiou等人,2024;Casanova等人,2024)丰富代码的详细声学或连续语义特征。第二种类型涉及使用精心设计的并行策略(Le Lan等人,2024;Copet等人,2024)或掩码生成模式(Garcia等人,2023;Ziv等人,2024;Li等人,2024b)预测多流代码。
通过利用我们提出的BiCodec生成的单流标记,Spark-TTS简化了在LLM框架内对语音标记的建模,使其与文本LLMs完全统一。与之最相似的工作是并发的TTS模型Llasa(Ye等人,2025),它采用基于FSQ的标记器将语音编码为具有65,536大小码本的单流代码,随后使用LLaMA(Touvron等人,2023)进行语音标记预测。与Llasa不同,Spark-TTS通过整合说话者属性标签扩展了零样本TTS,实现了可控的声音创建。此外,Spark-TTS在使用较少模型参数的情况下实现了更高的零样本TTS性能,提高了效率和灵活性。
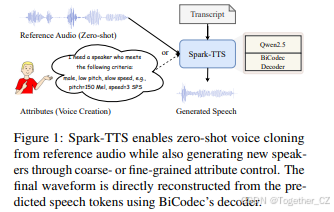
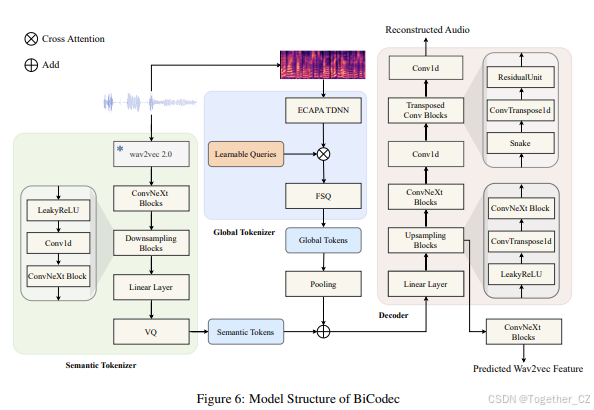
3. BiCodec
为了在语言模型(LM)中实现语义标记的紧凑性和语义相关性,同时实现声学属性控制,我们提出了BiCodec,它将输入音频离散化为:(i)语义标记,每秒50个标记(TPS),捕获语言内容;(ii)固定长度的全局标记,编码说话者属性和其他全局语音特征。
3.1 概览
如图2所示,BiCodec包括一个全局标记器和一个语义标记器。前者从输入音频的梅尔频谱图中提取全局标记。后者使用wav2vec 2.0(Baevski等人,2020)的特征作为输入来提取语义标记。BiCodec架构遵循标准的VQVAE编码器-解码器框架,并增加了一个全局标记器。解码器将离散标记重建为音频。对于输入音频信号x ∈ [−1, 1]T,样本数为T,BiCodec的功能如下:
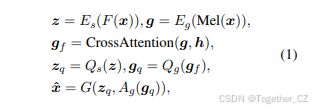
其中Es(·)是语义标记器的编码器,F(·)是预训练的wav2vec 2.0¹,Eg(·)是全局标记器的编码器,Mel(·)是从x中提取梅尔频谱图的函数,h是与最终全局标记序列长度匹配的一组可学习查询,Qs(·)是采用VQ的量化层,Qg(·)是采用FSQ的量化层,Ag(·)是带有池化层的聚合模块,G(·)是重建时域信号x̂的解码器。
3.2 模型结构
编码器和解码器
语义标记器的编码器Es和解码器G是基于ConvNeXt(Liu等人,2022)块的全卷积神经网络。为了有效捕获语义信息,根据wav2vec 2.0(XLSR-53)的不同层特征与语义之间的关系(Pasad等人,2023),我们选择第11层、第14层和第16层的特征,将它们平均以获得语义特征,作为语义标记器的输入。前两层的特征与单词显示出强相关性,而第16层的特征与音素显示出最强的相关性。全局标记器的编码器Eg使用ECAPA-TDNN架构(Desplanques等人,2020),按照Wespeaker(Wang等人,2023b)的实现,直到最终的池化层。编码后,全局标记器通过一组可学习查询的交叉注意力机制提取固定长度的序列表示gf。
量化
语义标记器采用单码本矢量量化进行量化。受DAC(Kumar等人,2024)的启发,我们使用因子化代码将编码器的输出投影到低维潜在变量空间,然后进行量化。考虑到全局标记器需要一组离散标记来表示时间不变的全局信息,我们采用FSQ而不是VQ,以避免VQ训练崩溃的潜在风险。关于模型结构的详细信息,请参见附录A。
3.3 训练目标
损失函数
BiCodec采用生成对抗网络(GAN)方法进行端到端训练(Goodfellow等人,2020),以最小化重建损失,同时使用判别器优化L1特征匹配损失(Kumar等人,2019, 2024),并同时优化VQ码本。按照Kumar等人(2024)的方法,我们使用多尺度梅尔频谱图的L1损失计算频域重建损失。我们使用多周期判别器(Kong等人,2020;Engel等人,2020;Gritsenko等人,2020)和多带多尺度STFT判别器(Kumar等人,2024)分别用于波形判别和频域判别。VQ码本学习包括码本损失和承诺损失。按照Xin等人(2024)的方法,码本损失计算为编码器输出与量化结果之间的L1损失,并使用停止梯度。此外,为了使梯度能够反向传播,我们使用了直通过估计器(Bengio等人,2013)。为了确保训练稳定性,在训练初期,从平均化的gq中得到的全局嵌入并未整合到解码器中。相反,该嵌入直接从gf的池化中获得。同时,FSQ码本使用gf和池化(gq)之间嵌入的L1损失进行更新。随着训练的进行和稳定,这种教师-学生形式将在特定训练步骤后被省略。为了进一步确保语义相关性,按照X-Codec(Ye等人,2024b)的方法,在量化后应用wav2vec 2.0重建损失,使用基于ConvNeXt的块作为预测器。
4. Spark-TTS的语言建模
4.1 概览
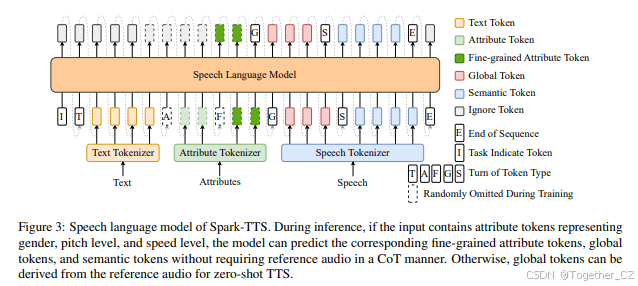
如图3所示,Spark-TTS语音语言模型采用解码器仅Transformer架构,与典型的文本语言模型统一。我们使用预训练的文本LLM Qwen2.5-0.5B²(Yang等人,2024)作为语音语言模型的骨干。与CosyVoice2(Du等人,2024a)不同,Spark-TTS不需要流匹配来生成声学特征。相反,BiCodec的解码器直接处理LM的输出以产生最终音频,显著简化了基于文本LLM的语音生成流程。除了零样本TTS外,Spark-TTS还支持使用各种属性标签进行声音创建。
在推理过程中,如果提供了性别、音高水平和语速水平的属性标签,语言模型可以通过链式思维(CoT)方式预测对应的细粒度音高值、语速值、全局标记和语义标记。如果没有提供属性标签,全局标记将从参考音频中提取,从而实现零样本TTS。
4.2 标记器
文本标记器
与文本语言模型类似,Spark-TTS采用基于字节对编码(BPE)的标记器来处理原始文本。这里,我们采用了Qwen2.5标记器(Yang等人,2024),支持多种语言。
属性标记器
为了基于语音属性进行声音创建,Spark-TTS在两个层次上对属性信息进行编码:
(i) 粗粒度:代表高级语音特征的属性标签,包括性别、音高(分为五个离散水平)和语速(分为五个离散水平);
(ii) 细粒度:能够精确控制音高和语速的属性值,这些值在标记化过程中通过四舍五入到最近的整数进行量化。
语音标记器
语音标记器由全局标记器和语义标记器组成。使用全局标记和语义标记,BiCodec解码器重建波形信号。
4.3 训练目标
解码器仅语言模型通过最小化标记预测的负对数似然进行训练。设T表示标记化的文本提示,G表示全局语音标记提示;零样本TTS的优化定义如下:

5. VoxBox
5.1 概览
为了促进声音创建并为未来研究建立公平的比较基准,我们引入了VoxBox,这是一个针对英语和中文的精心注释的数据集。VoxBox中的所有数据来源均为开源数据集,确保广泛的可访问性。为了增强数据多样性,我们不仅收集了常见的TTS数据集,还收集了用于语音情感识别的数据集。VoxBox中的每个音频文件都标注了性别、音高和语速。此外,我们还对文本质量较低的数据集进行了数据清理。经过数据清理后,VoxBox包含470万音频文件,来自29个开源数据集,总计10.25万小时的语音数据。关于VoxBox及其来源数据集的详细信息,请参见附录E。
5.2 清洗和注释
性别标注
鉴于预训练的WavLM在说话者相关任务中的出色表现(Li等人,2024c),我们使用包含明确性别标签的数据集(详细信息见附录E.2)对WavLM-large模型进行微调,用于性别分类。我们微调的模型在AISHELL-3测试集上达到了99.4%的准确率。然后,我们使用这个性别分类模型来标注之前缺少性别标签的数据集。
音高标注
我们使用PyWorld³从每个音频片段中提取平均音高值,并将其四舍五入到最近的整数,以获得细粒度音高值标记。对于音高水平的定义,我们首先将每个音频片段的平均音高转换为梅尔尺度。然后,我们分别对男性和女性的所有梅尔尺度音高进行统计分析。基于第5百分位、第20百分位、第70百分位和第90百分位,我们为男性和女性分别建立了五个音高水平的边界:非常低、低、中等、高和非常高(详细信息见附录E.1)。
语速标注
与基于字符(Vyas等人,2023)、基于单词(Ji等人,2024b)或基于音素(Lyth和King,2024)的语速计算相比,基于音节的测量与语速的相关性更强。在这里,我们首先应用语音活动检测(VAD)以消除两端的静音段。随后,我们计算每秒音节数(SPS),并将其四舍五入到最近的整数,以作为细粒度语速值标记。根据第5百分位、第20百分位、第80百分位和第95百分位,我们建立了五个不同的语速水平边界:非常慢、慢、中等、快和非常快(详细信息见附录E.1)。
数据清理
对于文本质量较低的数据集,我们进行了额外的清理过程。具体来说,对于Emilia(He等人,2024),原始脚本是使用基于Whisper的(ASR)系统(Radford等人,2023)获得的,采用whisper-medium模型,偶尔会出现不准确的情况。为了解决这个问题,我们使用另一个ASR模型FunASR(Gao等人,2023)⁴重新识别音频。然后,我们使用原始脚本作为真实值来计算词错误率(WER),并排除WER超过0.05的样本。对于MLS-English、LibriSpeech、LibriTTS-R以及原本用于情感识别的数据集,我们使用whisper-large-v3⁵模型进行语音识别,将识别结果与原始脚本进行比较。出现插入或删除的样本将从数据集中排除。
6. 实验
6.1 实现细节
BiCodec在LibriSpeech数据集的完整训练集上进行训练,包含960小时的英语语音数据。此外,我们还加入了来自Emilia-CN和Emilia-EN的1000小时语音数据,总训练数据约为3000小时。所有音频样本均重新采样为16kHz。全局标记长度设置为32。对于优化,我们使用AdamW优化器,移动平均系数为β₁=0.8和β₂=0.9。模型在大约800k训练步内收敛,使用614.4秒的语音批量大小。Spark-TTS语言模型使用整个VoxBox训练集进行训练。如果数据集缺乏预定义的训练/测试分割,我们使用整个处理过的数据集进行训练。训练采用AdamW优化器,β₁=0.9和β₂=0.96。模型训练3个epoch,使用768个样本的批量大小。
6.2 BiCodec的重建性能
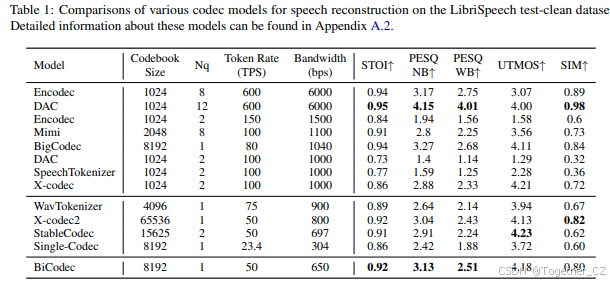
与其他方法的比较
表1展示了BiCodec与其他方法在语音重建性能上的比较。如表所示,在低比特率范围(<1kbps)内,BiCodec在大多数指标上均优于其他方法,除了UTMOS排名第二,仅次于StableCodec,以及SIM排名第二,仅次于X-Codec2,从而实现了新的最佳性能(SOTA)。值得注意的是,BiCodec的语义标记是从wav2vec 2.0而非原始音频中提取的,因此与直接处理波形表示的编解码器相比,具有更强的语义一致性。更多的实验结果和分析请参见附录A.3。
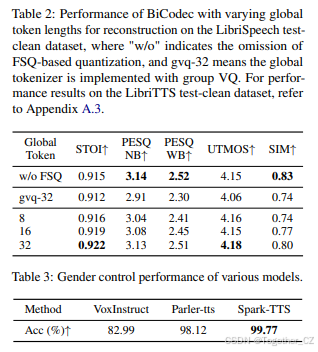
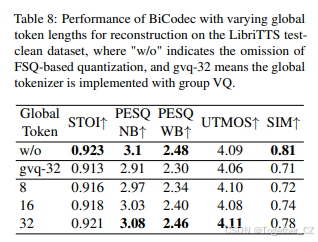
全局标记器的有效性
我们首先评估全局标记序列的最佳长度。如表2所示,我们比较了不同序列长度对重建质量的影响。未进行FSQ量化的结果作为基准参考。值得注意的是,随着全局标记序列长度的增加,重建质量持续提高,当长度为32时,性能接近基准。此外,表2还比较了我们提出的量化方法——结合可学习查询和FSQ的方法——与Ren等人(2024)引入的基于GVQ的方法。我们的方法在全局标记表示方面表现出显著的性能提升,这突出了可学习查询结合FSQ在增强全局标记表示方面的有效性。
6.3 Spark-TTS的控制能力
Spark-TTS通过输入属性标签或细粒度属性值实现可控生成。在基于标签的控制中,模型自动生成对应的属性值(例如,音高和语速)。然而,当这些值被手动指定时,系统切换到细粒度控制。
性别
为了评估Spark-TTS在性别控制方面的能力,我们将其与其他基于文本提示的可控TTS模型进行了比较,包括VoxInstruct(Zhou等人,2024b)和Parler-TTS(Lyth和King,2024)。为了评估,我们根据PromptTTS(Guo等人,2023)的测试提示结构重新组织了真实语音的测试提示。
生成语音的性别准确性(Acc)是使用我们专门训练用于性别标注的性别预测器进行测量的。表3中呈现的结果表明,Spark-TTS在性别控制方面显著优于其他可控TTS系统,显示出其在基于属性的声音生成方面的强大能力。
音高和语速
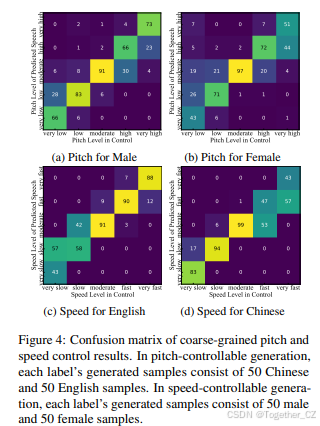
Spark-TTS通过输入属性标签或细粒度属性值实现可控生成。在基于标签的控制中,模型自动生成对应的属性值(例如,音高和语速)。然而,当这些值被手动指定时,系统切换到细粒度控制。
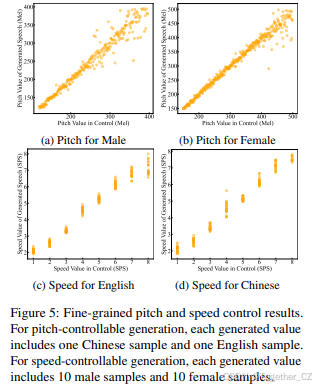
图4展示了基于粗粒度标签的音高和语速控制的混淆矩阵,而图5展示了细粒度音高和语速控制的性能。如图所示,Spark-TTS能够准确生成与指定属性标签一致的语音,显示出对粗粒度和细粒度属性的精确控制能力。
6.4 零样本TTS性能
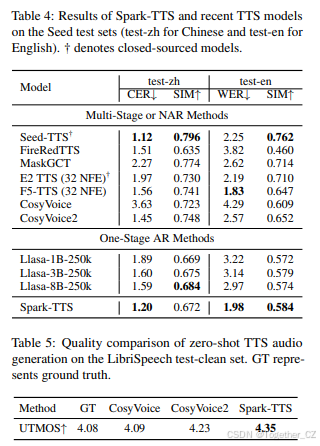
为了评估Spark-TTS的零样本TTS能力,我们在Seed-TTS-eval上对其性能进行了评估,并与现有的零样本TTS模型进行了比较。表4中呈现了结果,其中语音可懂度使用中文的字符错误率(CER)和英文的词错误率(WER)进行评估,遵循Seed-TTS-eval⁶的规则。如表所示,Spark-TTS在零样本TTS场景中的可懂度方面表现出显著的优越性。在test-zh上,Spark-TTS的CER仅次于闭源模型Seed-TTS,而在英文WER方面,它仅次于F5-TTS(Chen等人,2024b)。这种高可懂度部分归功于基于语义特征的BiCodec,并进一步验证了我们的VoxBox数据集在转录方面的高质量。
在说话者相似性方面,尽管Spark-TTS相对较弱于多阶段或NAR方法,但它显著优于单阶段模型Llasa(Ye等人,2025)。值得注意的是,Spark-TTS仅使用0.5B模型参数和10万小时的训练数据,就超越了Llasa,后者拥有8B参数,并在25万小时的数据上进行训练。
6.5 零样本TTS性能
为了评估Spark-TTS的零样本TTS能力,我们在Seed-TTS-eval上对其性能进行了评估,并与现有的零样本TTS模型进行了比较。表4中呈现了结果,其中语音可懂度使用中文的字符错误率(CER)和英文的词错误率(WER)进行评估,遵循Seed-TTS-eval⁶的规则。如表所示,Spark-TTS在零样本TTS场景中的可懂度方面表现出显著的优越性。在test-zh上,Spark-TTS的CER仅次于闭源模型Seed-TTS,而在英文WER方面,它仅次于F5-TTS(Chen等人,2024b)。这种高可懂度部分归功于基于语义特征的BiCodec,并进一步验证了我们的VoxBox数据集在转录方面的高质量。
在说话者相似性方面,尽管Spark-TTS相对较弱于多阶段或NAR方法,但它显著优于单阶段模型Llasa(Ye等人,2025)。值得注意的是,Spark-TTS仅使用0.5B模型参数和10万小时的训练数据,就超越了Llasa,后者拥有8B参数,并在25万小时的数据上进行训练。
6.6 零样本TTS语音质量
按照CosyVoice2(Du等人,2024b)的方法,我们在LibriSpeech测试集上评估了生成语音的质量。如表5所示,我们的方法生成的音频质量显著高于原始音频,并优于CosyVoice2,这是目前开源的多阶段建模的SOTA TTS模型。这表明Spark-TTS在语音质量方面表现出色。
7. 结论
本文介绍了BiCodec,它保留了语义标记的优点,包括高压缩效率和高可懂度,同时通过引入全局标记解决了传统语义标记在语言模型中无法控制音色相关属性的限制。BiCodec在50 TPS的比特率为0.65kbps时实现了新的SOTA重建质量,超越了其他在1kbps以下范围内的编解码器。基于BiCodec,我们开发了Spark-TTS,这是一个整合了文本语言模型Qwen2.5的文本到语音模型。Spark-TTS能够根据指定的属性进行声音生成,并支持零样本合成。据我们所知,这是第一个提供对音高和语速进行细粒度控制的同时支持零样本TTS的TTS模型。此外,为了促进比较研究,我们引入了VoxBox,这是一个为可控语音合成设计的开源数据集。VoxBox不仅过滤掉了文本质量较低的数据,还提供了全面的注释,包括性别、音高和语速,显著增强了可控生成任务的训练。
8. 局限性
尽管Spark-TTS具有诸多优势,但也存在一些显著的局限性。与Llasa(Ye等人,2025)类似,Spark-TTS依赖于单个码本和文本语言模型,在零样本TTS的说话者相似性指标方面,相较于多阶段或NAR方法表现较差。这可能是由于在推理过程中,自回归语言模型引入了更大的说话者变异性。目前,Spark-TTS并未在全局标记和语义标记之间施加额外的解耦约束。在未来的工作中,我们计划通过在语义标记输入中引入对共振峰或音高的扰动来增强全局标记对音色的控制。这种方法将促进音色信息的更好解耦,使BiCodec的解码器能够绝对控制音色。通过这种方式,我们旨在减少自回归模型引入的随机性,提高零样本合成中的说话者相似性。
附录
A. BiCodec 模型结构
图 6 展示了 BiCodec 的模型结构。BiCodec 主要包括以下三个组件:
-
语义标记器
-
全局标记器
-
解码器
此外,为了计算与输入的 wav2vec 2.0 特征的特征损失,还增加了一个额外的 ConvNeXt 块,用于预测 wav2vec 2.0 特征,以进一步确保语义相关性。
A.1 模型配置
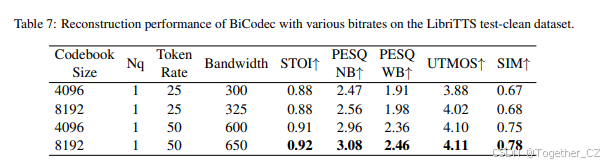
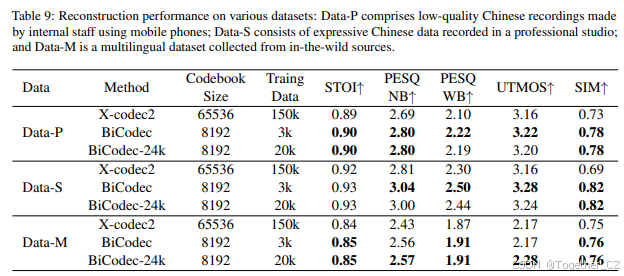
语义标记器由 12 个 ConvNeXt 块和 2 个下采样块组成。下采样块仅用于语义码率低于 50 TPS 的情况。VQ 码本大小为 8192。全局标记器中的 ECAPA-TDNN 的嵌入维度为 512。同时,全局标记器中的可学习查询向量的数量等于最终全局标记序列的长度。对于 FSQ 模块,FSQ 维度设置为 6,每个维度有 4 个级别,因此码本大小为 4096。转置卷积块中的上采样率设置为 16kHz 采样音频的 [8, 5, 4, 2] 和 24kHz 采样音频的 [8, 5, 4, 3]。对于 24kHz 采样音频的 BiCodec 重建性能,请参见 表 9。
A.2 比较方法
-
Encodec(Défossez 等人,2022):一种基于 RVQ 的编解码器,用于通用音频压缩。
-
DAC(Kumar 等人,2024):一种基于 RVQ 的通用音频编解码器。
-
Mimi(Défossez 等人,2024):一种带有语义约束的 RVQ 基语音编解码器。
-
Single-Codec(Li 等人,2024a):一种单流 Mel 编解码器,结合了说话者嵌入。该方法的重建结果由作者提供。
-
BigCodec(Xin 等人,2024):一种基于 VQ 的单流语音编解码器。
-
SpeechTokenizer(Zhang 等人,2023a):一种基于 RVQ 的语音编解码器,带有语义蒸馏。
-
X-codec(Ye 等人,2024b):一种带有语义蒸馏的 RVQ 基语音编解码器。
-
X-codec2(Ye 等人,2025):一种基于 FSQ 的单流语音编解码器,带有语义蒸馏。
-
StableCodec(Parker 等人,2024):一种基于残差 FSQ 的标记器,用于语音。
-
WavTokenizer(Ji 等人,2024a):一种基于单 VQ 码本的通用音频标记器。
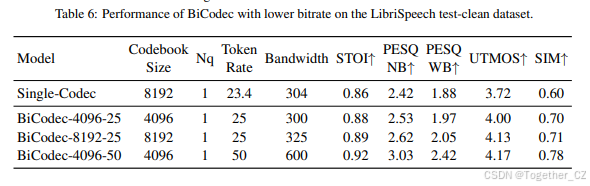
A.3 额外实验
为了评估 BiCodec 在更低比特率下的性能,我们在语义编码器中应用了下采样操作,将语义标记率降低到 25 TPS。我们在 表 6 和 表 7 中将 BiCodec 与 SingleCodec(Li 等人,2024a)进行了比较,后者在类似的比特率下运行。表 8 展示了 BiCodec 在不同全局标记长度下的重建性能。
B. Spark-TTS 的推理
零样本 TTS
零样本 TTS 有两种推理策略:
-
使用要合成的文本和参考音频的全局标记作为提示来生成语音,例如:[<content text> <global token> → <semantic token>]。
-
将参考音频的文本和语义标记作为前缀包含在提示中,例如:[<content text> <reference text> <global token> <semantic token of reference> → <semantic token>]。
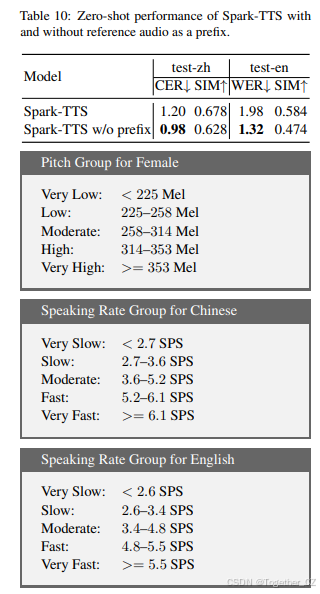
在这些方法中,第二种方法实现了更高的说话者相似性。表 4 中报告的结果基于这种第二种推理策略。两种推理方法的比较请参见 表 10。
可控语音合成
可控 TTS 包括两个级别的控制,用于推理:
-
粗粒度控制:提示由要合成的文本和属性标签组成,例如:[<content text> <attribute label> → <attribute values> <global tokens> <semantic token>]。在这个过程中,首先预测细粒度属性值,然后生成全局标记,最后生成语义标记,以 CoT 方式进行。
-
细粒度控制:提示包括要合成的文本、属性级别和精确的属性值,例如:[<content text> <attribute label> <attribute values> → <global tokens> <semantic token>]。
C. 比较的零样本方法
-
Seed-TTS(Anastassiou 等人,2024):一种两阶段模型,使用自回归(AR)语言模型进行语义标记预测,并使用流匹配进行声学特征生成。
-
FireRedTTS(Guo 等人,2024):一种与 Seed-TTS 类似的两阶段模型,使用 AR 语言模型进行语义标记和流匹配进行声学特征生成。
-
MaskGCT(Wang 等人,2024b):一种非自回归(NAR)模型,应用基于掩码的生成策略进行语音合成。
-
E2 TTS:一种基于流匹配的模型,预测 Mel 频谱图作为声学特征。
-
F5-TTS(Chen 等人,2024b):一种基于流匹配的方法,也使用 Mel 频谱图作为声学特征。
-
CosyVoice(Du 等人,2024a):一种两阶段模型,使用 AR 语言模型进行语义标记预测和流匹配进行声学特征生成。
-
CosyVoice2(Du 等人,2024b):CosyVoice 的改进版本,保持两阶段结构,使用 AR 语言模型进行语义标记和流匹配进行声学特征生成。
-
Llasa(Ye 等人,2025):一种单流编解码器基础的 TTS 模型,使用单个 AR 语言模型直接进行单流代码预测。
D. 客观指标
-
STOI(Andersen 等人,2017):一种广泛使用的指标,用于评估语音可懂度。分数范围为 0 到 1,值越高表示可懂度越好。
-
PESQ(Rix 等人,2001):一种语音质量评估指标,将重建语音与参考语音信号进行比较。我们在宽带(WB)和窄带(NB)设置下进行评估。
-
UTMOS(Saeki 等人,2022):一种自动平均意见得分(MOS)预测器,提供对整体语音质量的估计。
-
SIM:一种说话者相似性指标,通过计算重建语音(TTS 中的生成语音)和原始输入语音(TTS 中的提示语音)的说话者嵌入之间的余弦相似度来计算。我们使用在说话者验证任务上微调的 WavLM-large 来提取说话者嵌入(Chen 等人,2022)。
E. VoxBox 数据集
E.1 音高和语速分类标准
-
语速:采用第 5 百分位、第 20 百分位、第 80 百分位和第 95 百分位来划分语速类别,基于需要准确反映人群中语速变化的自然分布。这些百分位有助于捕捉语速的极端值和中心值,确保每个类别都有意义且代表特定的语音特征。
-
音高:与语速划分类似,音高的划分也基于人类主观感知和实际分布特征。然而,由于人类对人类基频范围内的较高频率更敏感,因此使用第 5 百分位、第 20 百分位、第 70 百分位和第 90 百分位作为划分边界。
E.2 性别预测器训练数据
我们使用包含明确性别标签的数据集对 WavLM-large 模型进行微调,用于性别分类,这些数据集包括 VCTK(Yamagishi 等人,2019)、AISHELL-3(Shi 等人,2020)、MLS-English(Pratap 等人,2020)、MAGICDATA(MagicData,2019)和 CommonVoice(Ardila 等人,2019)。
E.3 数据注释
除了本文实验中涉及的属性外,为了使 VoxBox 能够适用于更广泛的场景,我们还对 VoxBox 的每个样本进行了更多注释,包括年龄和情感。与性别注释类似,我们基于 AISHELL-3、VCTK、MAGICDATA、CommonVoice 和 HQ-Conversations 对 WavLM-large 模型进行微调,以预测五个年龄范围:儿童、青少年、年轻成年人、中年人和老年人。性别和年龄预测器的性能指标如 表 11 所示,其中 wav2vec 2.0-ft(Burkhardt 等人,2023)和 SpeechCraft(Jin 等人,2024)均基于预训练的 wav2vec 2.0 模型。
E.4 数据统计
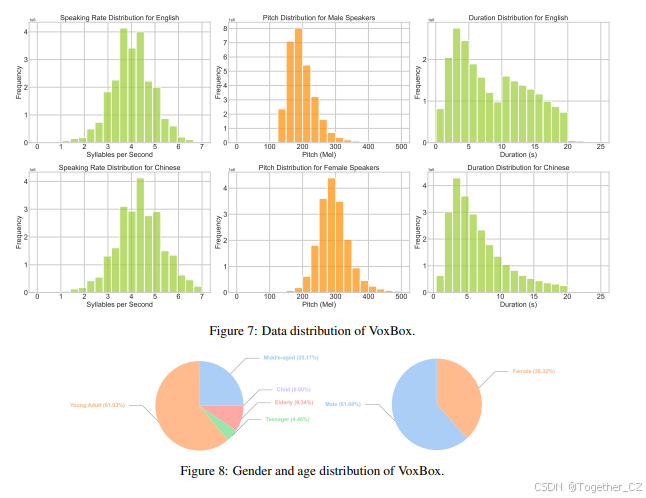
VoxBox 的语速、持续时间和音高的分布如 图 7 所示,而性别和年龄的分布如 图 8 所示。
E.5 数据来源
-
AISHELL-3:一个多说话者的中文 TTS 语音语料库。来源:openslr.org
-
CASIA:一个包含六种情感的多说话者中文情感语音语料库,用于 TTS。来源:GitCode - 全球开发者的开源社区,开源代码托管平台
-
CREMA-D:一个多说话者多语言情感语音语料库,包含六种情感和四种强度水平,用于 TTS。来源:https://github.com/CheyneyComputerScience/CREMA-D
-
Dailytalk:一个多说话者英语对话风格的语音语料库,用于 TTS。来源:https://github.com/keonlee9420/DailyTalk
-
Emilia:一个多说话者多语言语音语料库,包含六种语言,用于 TTS。来源:https://emilia-dataset.github.io/Emilia-Demo-Page/
-
EMNS:一个单说话者英语情感语音语料库,用于 TTS。来源:openslr.org
-
EmoV-DB:一个多说话者英语情感语音语料库,包含四种情感,用于 TTS。来源:https://mega.nz/folder/KBp32apT#gLIgyWf9iQ-yqnWFUFuUHg/mYwUnI4K
-
ESD:一个多说话者双语情感语音语料库,包含五种情感,用于 TTS。来源:https://hltsingapore.github.io/ESD/
-
Expresso:一个多说话者英语语音语料库,包含阅读和即兴对话风格,用于 TTS。来源:https://speechbot.github.io/expresso/
-
Gigaspeech:一个多说话者英语阅读风格的语音语料库,用于 TTS。来源:https://github.com/SpeechColab/GigaSpeech
-
Hi-Fi TTS:一个多说话者英语阅读风格的语音语料库,用于 TTS。来源:openslr.org
-
HQ-Conversations:一个多说话者中文对话风格的语音语料库,用于 TTS。来源:Magic Data - Training Datasets for Conversational AI - Magic Data
-
IEMOCAP:一个多说话者英语情感语音语料库,包含五种情感,用于 TTS。来源:IEMOCAP- Release
-
JL-Corpus:一个多说话者英语情感语音语料库,包含五种主要情感和五种次要情感,用于 TTS。来源:JL corpus | Kaggle
-
Librispeech:一个多说话者英语阅读风格的语音语料库,用于 TTS。来源:librispeech | TensorFlow Datasets
-
LibriTTS-R:LibriTTS(Zen 等人,2019)的音质改进版本,这是一个大规模的英语语音语料库,用于 TTS。来源:openslr.org
-
M3ED:一个多说话者中文情感语音语料库,包含七种情感,用于 TTS。来源:https://github.com/aim3-ruc/rucm3ed
-
MAGICDATA:一个多说话者中文对话风格的语音语料库,用于 TTS。来源:openslr.org
-
MEAD:一个多说话者英语情感语音语料库,包含八种情感和三种强度水平,用于 TTS。来源:https://github.com/uniBruce/Mead
-
MELD:一个多说话者英语情感语音语料库,包含七种情感,用于 TTS。来源:https://affective-meld.github.io/
-
MER2023:一个多说话者中文情感语音语料库,包含六种情感,用于 TTS。来源:MER 2023
-
MLS-English:一个多说话者英语语音语料库,用于 TTS。来源:openslr.org
-
MSP-Podcast:一个多说话者英语情感语音语料库,包含八种情感,用于 TTS。来源:Resources - MSP-Podcast corpus
-
NCSSD-CL:一个多说话者双语语音语料库,用于 TTS。来源:https://github.com/uniBruce/Mead
-
NCSSD-RL:一个多说话者双语语音语料库,用于 TTS。来源:https://github.com/uniBruce/Mead
-
RAVDESS:一个多说话者英语情感语音语料库,包含八种情感和两种强度水平,用于 TTS。来源:RAVDESS Emotional speech audio | Kaggle
-
SAVEE:一个多说话者英语情感语音语料库,包含七种情感,用于 TTS。来源:Surrey Audio-Visual Expressed Emotion (SAVEE) | Kaggle
-
TESS:一个多说话者英语情感语音语料库,包含七种情感,用于 TTS。来源:Toronto emotional speech set (TESS)
-
VCTK:一个多说话者英语语音语料库,用于 TTS。来源:SUPERSEDED - CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit
-
WenetSpeech4TTS:一个大规模的多说话者中文语音语料库,用于 TTS。来源:WenetSpeech4TTS
F. SparkVox:语音相关任务的工具包
Spark-TTS 的训练代码将集成到开源的 SparkVox 框架中。SparkVox 是一个为语音相关任务设计的训练框架,支持多种应用,包括语音合成(TTS)、编解码器(Codec)、语音识别(ASR)和语音理解等任务。此外,SparkVox 提供了多种文本和语音数据处理工具,便于高效的数据处理。其简化的框架结构如 图 9 所示。
表 12:VoxBox 数据集统计
| 数据集名称 | 语言 | 男性样本数 | 女性样本数 | 总样本数 | 持续时间(小时) |
|---|---|---|---|---|---|
| AISHELL-3 | 中文 | 88,035 | 69,610 | 157,645 | 85.62 |
| CASIA | 中文 | 857 | 2 | 859 | 0.44 |
| Emilia-CN | 中文 | 15,629,241 | 12,741,890 | 28,371,131 | 34,759.45 |
| ESD | 中文 | 16,101 | 7,680 | 23,781 | 14.37 |
| HQ-Conversations | 中文 | 50,982 | 64,230 | 115,212 | 100.00 |
| M3ED | 中文 | 253 | 6 | 259 | 0.10 |
| MAGICDATA | 中文 | 609,474 | 393,810 | 1,003,284 | 754.13 |
| MER2023 | 中文 | 1,667 | 1,070 | 2,737 | 1.93 |
| NCSSD-CL-CN | 中文 | 98,628 | 59,210 | 157,838 | 113.04 |
| NCSSD-RL-CN | 中文 | 21,688 | 22,530 | 44,218 | 29.58 |
| WenetSpeech4TTS | 中文 | 8,856,480 | 4,264,300 | 13,120,780 | 11,768.49 |
| 中文总计 | 25,373,406 | 30,002.56 | 17,624.59 | 47,627.15 |
| 数据集名称 | 语言 | 男性样本数 | 女性样本数 | 总样本数 | 持续时间(小时) |
|---|---|---|---|---|---|
| CREMA-D | 英文 | 809 | 270 | 1,079 | 0.57 |
| Dailytalk | 英文 | 23,754 | 10,860 | 34,614 | 21.65 |
| EmiliaEN | 英文 | 8,303,103 | 6,573,220 | 14,876,323 | 20,297.98 |
| EMNS | 英文 | 918 | 0 | 918 | 1.49 |
| EmoV-DB | 英文 | 3,647 | 2,790 | 6,437 | 5.00 |
| Expresso | 英文 | 11,595 | 5,390 | 16,985 | 10.86 |
| Gigaspeech | 英文 | 6,619,339 | 2,885,660 | 9,505,000 | 7,195.85 |
| Hi-Fi TTS | 英文 | 323,911 | 158,380 | 482,291 | 291.68 |
| IEMOCAP | 英文 | 2,423 | 1,310 | 3,733 | 2.97 |
| JL-Corpus | 英文 | 893 | 260 | 1,153 | 0.52 |
| Librispeech | 英文 | 230,865 | 230,865 | 461,730 | 761.62 |
| LibriTTS-R | 英文 | 363,270 | 283,030 | 646,300 | 560.90 |
| MEAD | 英文 | 3,767 | 2,420 | 6,187 | 4.68 |
| MELD | 英文 | 5,100 | 1,940 | 7,040 | 4.09 |
| MLS-English | 英文 | 6,319,002 | 11,212,920 | 17,531,922 | 25,579.18 |
| MSP-Podcast | 英文 | 796 | 560 | 1,356 | 1.32 |
| NCSSD-CL-EN | 英文 | 62,107 | 32,930 | 95,037 | 69.77 |
| NCSSD-RL-EN | 英文 | 10,032 | 14,920 | 24,952 | 19.09 |
| RAVDESS | 英文 | 950 | 480 | 1,430 | 0.97 |
| SAVEE | 英文 | 286 | 150 | 436 | 0.31 |
| TESS | 英文 | 0 | 1,956 | 1,956 | 1.15 |
| VCTK | 英文 | 44,283 | 24,510 | 68,793 | 41.46 |
| 英文总计 | 22,332,806 | 33,290.80 | 21,582.31 | 54,873.11 |



















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











