






1.数据仓库架构
- 数据仓库DW主要是一个用于存储,分析,报告的数据系统。
- 数据仓库的目的是面向分析的集成化数据环境,分析结果为企业提供决策支持。
- -DW不产生和消耗数据
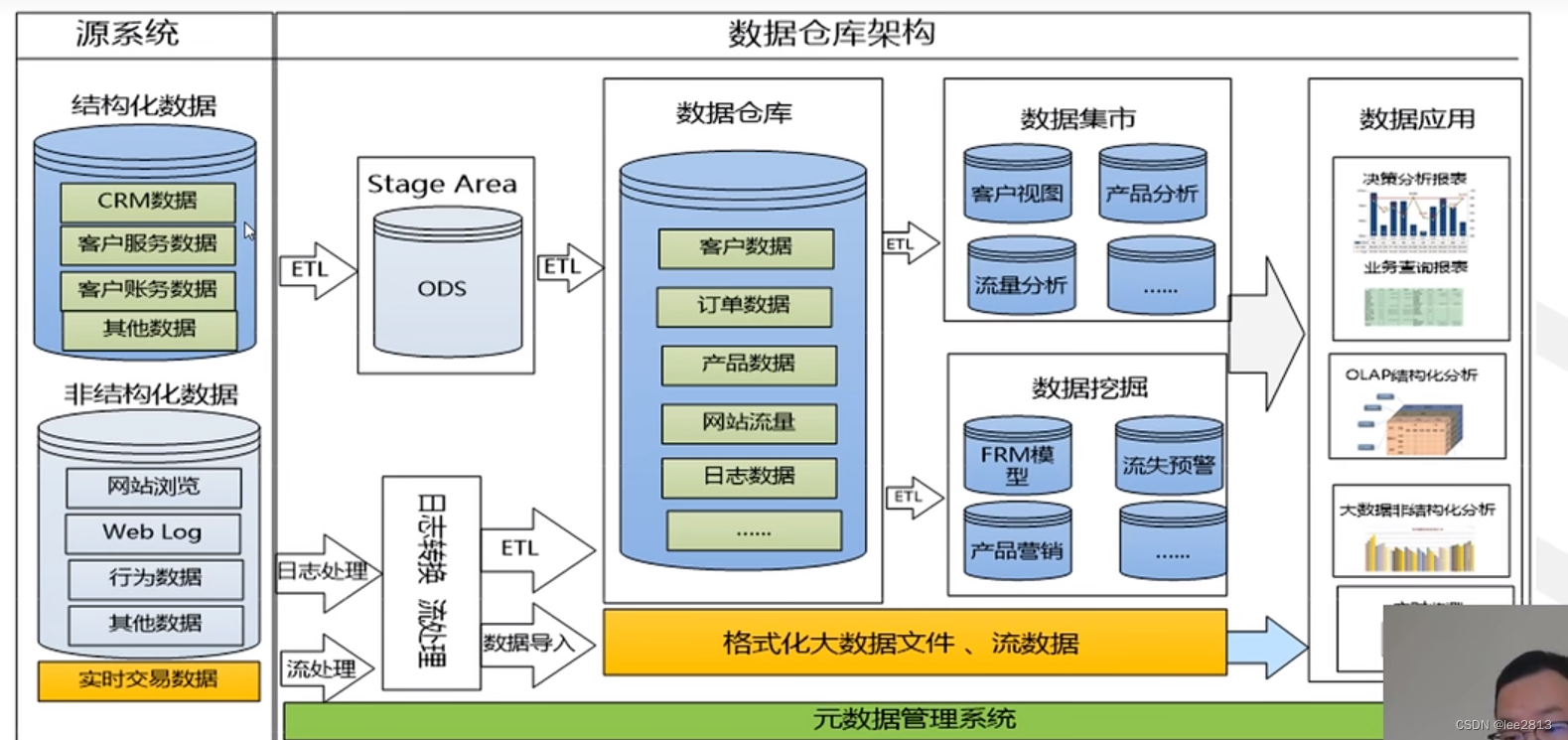
- 结构数据:数据库中数据,CSV文件 直接导入DW
- 非结构数据:基本数据处理后导入DW
针对部门需求可以做不同DW,为一个数据集市,最终目的是做一个数据应用,报表等
数据仓库分层
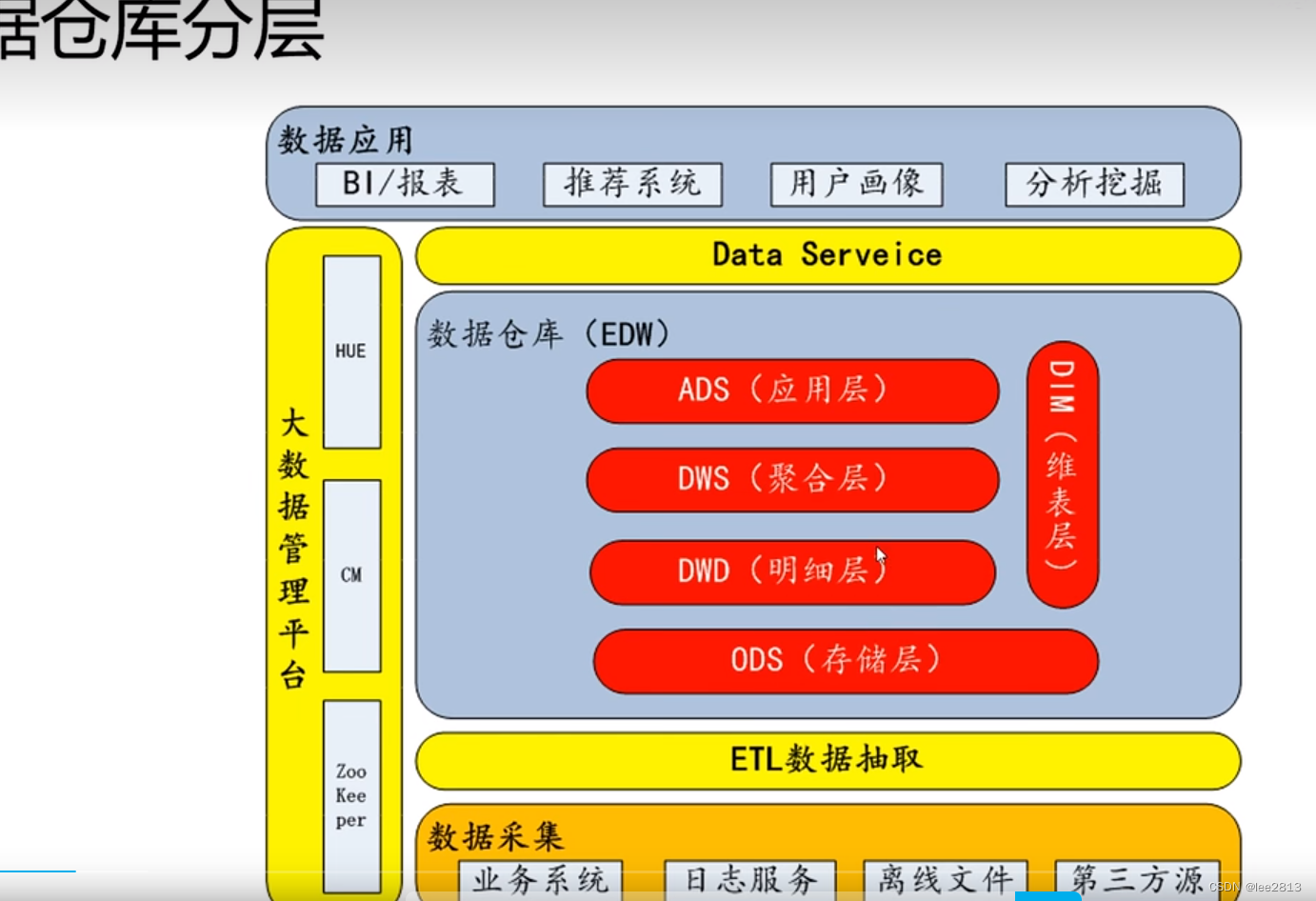
- 数据仓库分层:针对多种数据表的情况,根据业务场景进行分层融合和合并。
用于报表的数据,每个指标出现了几次 —— 应用层
二、怎么实现数仓 - Hive
- Hive是基于Hadop的DW工具,用来进行数据提取,转化,加载,是一种大规模数据机制。
- Hive数据仓库工作将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
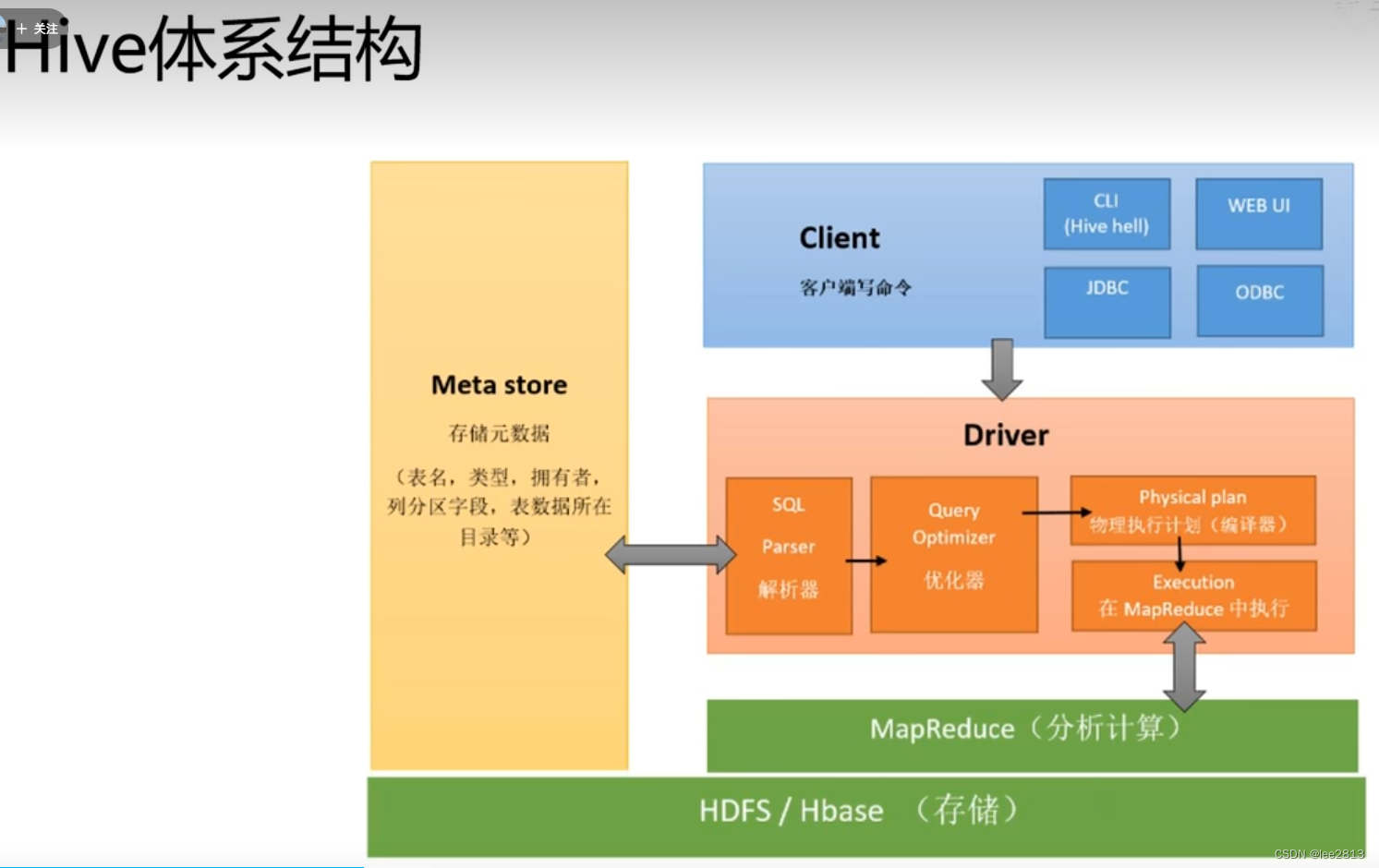
利用Hive可以直接在SQL上层编写语句,通过SQL Parser解析器转换为Java程序。
元数据组件存放映射的表。
Hive特点:
- 适合ETL,报表查询,数据分析等数据仓库任务
- Hive支持运行在不同的计算框架上,MapReduce,Spark等
- 支持Java数据库连接
- 避免编写复杂的MapReduce任务
- 可直接使用Hadoop文件系统中的数据
Hive和Hadoop
- Hive利用HDFS存储数据,MapReduce查询分析数据
- Hadoop是自己实现了上述两种能力。
Hive适应场景
- Hive适用于结构化数据的离线分析
- Hive的执行延迟较高
- Hive适合处理大批量数据
Hive与MySql
- Hive面向分析,MySql面向业务
3.Hive安装
最终直接写SQL语句就行,不要管MapReduce任务















 3477
3477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









