






1:作业简介:猫狗大战
1.1问题描述:
猫狗问题是一个经典的机器学习分类问题,目标是通过计算机算法自动识别图像中是猫还是狗。
1.2预期解决方案:
通过训练一个机器学习模型,使其在给定一张图像时能够准确地预测图像中是猫还是狗。模型应该能够推广到未见过的图像,并在测试数据上表现良好。
1.3数据集
训练集:
链接:https://pan.baidu.com/s/1bsJZmnR5I38rucyB1V6qEA
提取码:asd2
测试集:
链接:https://pan.baidu.com/s/1uao8yPk2PQFlWJ6tJAtOeA
提取码:asd3
1.4图像展示

2:数据预处理
2.1数据集结构
本项目数据集共由三部份组成,分别包含train、test1和test文件夹,其中test1文件夹中数据,为不带标签的测试集,test中为带标签的测试集。

其中train文件夹中包含25000张带有标签的猫狗图片,用作训练集。test1文件夹中包含12500张没有标签的图片。
2.2探索性数据分析
先导入接下来将要使用的包
import os
import sys
import time
import argparse
import itertools
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import intel_extension_for_pytorch as ipex
import pandas as pd
from torch import nn
from torch import optim
from torch.autograd import Variable
from torchvision import models
from matplotlib.patches import Rectangle
from sklearn.metrics import confusion_matrix, accuracy_score, balanced_accuracy_score
from torchvision import transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler
from torchvision import transforms
from sklearn.model_selection import train_test_split, StratifiedKFold
from torch.utils.data import DataLoader
from sklearn.metrics import f1_score
from torch.utils.data.dataset import Subset查看数据集的大小以及数据集中文件名称
#返回指定路径下的所有文件和目录的名称列表
train_path = '../data/train'
test_path = '../data/test1'
train_file_names = os.listdir(train_path)
test_file_names = os.listdir(test_path)
print("训练集大小:{}".format(len(train_file_names)))
print("测试集大小:{}".format(len(test_file_names)))
print("训练集样例:{}".format(train_file_names[0:5]))#训练集文件名:标签+序号
print("测试集样例:{}".format(test_file_names[0:5])) #测试集文件名:序号
查看train文件夹中cat和dog的数量并提取三个不同的猫狗图片进行展示:
train_path = '../data/train'
image_files = [file for file in os.listdir(train_path) if file.lower().endswith( '.jpg')]
# 猫和狗的路径
cat_imgs = [file for file in image_files if file.lower().startswith('cat') and len(file) >= 3]
dog_imgs = [file for file in image_files if file.lower().startswith('dog') and len(file) >= 3]
print(f'猫的数量为: {len(cat_imgs)}')
print(f'狗的数量为: {len(dog_imgs)}')
# 随机不重样的抽选3个猫 3个狗
select_cat = np.random.choice(cat_imgs, 3, replace = False)
select_dog = np.random.choice(dog_imgs, 3, replace = False)
# 使用plt打印出来
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
for i in range(6):
if i < 3:
fp = os.path.join(train_path, select_cat[i])
label = 'CAT'
else:
fp = os.path.join(train_path, select_dog[i-3])
label = 'DOG'
# 加载图像
img = Image.open(fp)
# 显示图像
axes[i // 3, i % 3].imshow(img)
axes[i // 3, i % 3].set_title(label)
axes[i // 3, i % 3].axis('off')
# 显示图像
plt.show()
2.3自定义数据集
为了更好的提取图片,我就将train数据集中的猫狗图片进行分类并打好标签
class SelfDataset(Dataset):
#初始化接受数据的路径 和数据转换的函数
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.data = self.load_data()
def load_data(self):
data = []
for file_name in os.listdir(self.root_dir):
file_path = os.path.join(self.root_dir, file_name)
if os.path.isfile(file_path) and file_name.lower().endswith('.jpg'):
class_label = 0 if file_name.lower().startswith('cat') else 1
data.append((file_path, class_label))
return data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path, label = self.data[idx]
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
return img, label# 数据集路径2.4数据增强
我定义了一个包含一系列数据增强操作的 transform,其中包括随机裁剪、随机水平翻转,以及将图像转换为张量。这些增强操作可用于训练集,以提高模型的泛化能力。
# 数据增强
transform = transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])2.5构建数据集
在将train数据集进行处理后,我将数据集按照8:2的比例分为了训练集和验证集,验证集用于验证每轮训练模型的性能。
# 数据集路径
train_dataset_path = '../data/train'
# 创建数据集实例
train_dataset = SelfDataset(root_dir=train_dataset_path, transform=transform)
# 将triandata划分为训练集、验证集和测试集
all_indices = list(range(len(train_dataset)))
train_indices, val_indices = train_test_split(all_indices, test_size=0.2, random_state=42)
# 创建 Subset 对象,用于划分数据集
train_subset = Subset(train_dataset, train_indices)
val_subset = Subset(train_dataset, val_indices)
batch_size = 64
# 创建 DataLoader
train_loader = DataLoader(dataset=train_subset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(dataset=val_subset, batch_size=batch_size, shuffle=False)3:用GoogleNet模型识别猫狗
3.1GoogleNet模型简介
GoogleNet(又称为Inception v1)是由Google研究团队在2014年提出的一种深度神经网络架构。它的全名是Inception,而在ImageNet大规模图像识别竞赛中的版本被称为Inception v1。GoogleNet采用了一种称为Inception Module的结构,以提高网络的计算效率和表达能力。
Inception Module的特点是同时使用不同大小的卷积核和池化层,并将它们的输出连接在一起。这样,网络可以在不同尺度上学习特征,从而更好地适应不同尺寸的对象。此外,GoogleNet还使用了全局平均池化(Global Average Pooling),以减少模型的参数数量,降低过拟合的风险。
在Inception v1中,网络结构相对较深,但通过Inception Module的设计,它成功地实现了高效的计算和优越的性能。该模型在ImageNet竞赛中取得了显著的成绩,并为后续的深度学习研究奠定了基础。
inception模块的基本机构如下图,整个inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。:
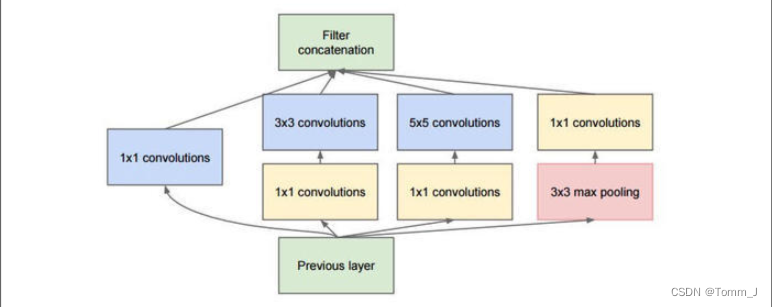
3.2更改GoogleNet网络结构
加载预训练的GoogLeNet模型,并修改了最后的全连接层,以适应猫狗大战的二分类任务
# 加载预训练的 GoogLeNet 模型
googlenet = models.googlenet(pretrained=True)
# 修改最后的全连接层以适应猫狗大战的二分类任务
num_features = googlenet.fc.in_features
googlenet.fc = nn.Linear(num_features, 2) # 输出层改为2个类别3.3参数设置
损失函数 (criterion):我们使用了交叉熵损失函数 (nn.CrossEntropyLoss())。对于分类任务,特别是多类别分类,交叉熵是一种常用的损失函数。它测量模型的输出概率分布与实际标签之间的差异。
优化器 (optimizer):我们选择了随机梯度下降优化器 (optim.SGD)。随机梯度下降是一种常见的优化算法,用于最小化模型的损失函数。我们将GoogLeNet模型的参数传递给优化器,并设置学习率 (lr) 为0.1。
学习率调度器(scheduler):当模型在验证集上的性能停止提高时,该调度器会自动将学习率降低10倍。这种技术有助于防止模型在训练过程中陷入局部最优解,并可能帮助模型找到更好的解决方案。
设备选择 (device):我们通过检查CUDA是否可用来选择在GPU还是CPU上运行模型。如果CUDA可用,模型将在GPU上运行,否则将在CPU上运行。
这些组件一起协同工作,通过反向传播和梯度下降来更新模型的权重,以使模型在训练集上学到适应任务的特征。
# 定义损失函数和优化器
learning_rate = 0.1
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(googlenet.parameters(), lr=learning_rate)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#设置学习率调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.1, patience=3, verbose=True)3.4训练模型
训练模型包括以下步骤:
- 设置训练循环,迭代一定数量的 epochs。
- 在每个 epoch 中,使用训练集对模型进行训练,计算并记录训练损失。
- 在每个 epoch 结束后,使用验证集评估模型的性能,计算并记录验证损失、准确率和 F1 分数。
- 当模型在验证集上的性能停止提高时,该调度器会自动将学习率降低10倍。
- 保存每个 epoch 结束后的模型参数。
- 绘制损失函数、准确率以及F1值的变化图像
# 在训练过程中记录损失
train_losses = []
val_losses = []
accuracy_list = [] # 初始化准确率列表
f1_list = [] # 初始化 F1 列表
# 训练模型
epochs = 20
for epoch in range(epochs):
print(f'第{epoch+1}次训练开始了')
googlenet.train()
train_loss = 0.0
start_time = time.time() # 记录当前epoch的开始时间
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = googlenet(inputs)
#计算损失
loss = criterion(outputs, labels)
#反向传播 优化
loss.backward()
optimizer.step()
train_loss += loss.item()
# 计算平均训练损失
avg_train_loss = train_loss / len(train_loader)
train_losses.append(avg_train_loss)
end_time = time.time() # 记录当前epoch的结束时间
print(f"Epoch {epoch + 1}/{epochs}, Training Loss: {avg_train_loss}, Time: {end_time - start_time:.2f} seconds")
# 在验证集上评估模型
googlenet.eval()
val_loss = 0.0
correct = 0
total = 0
all_predictions = []
all_labels = []
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = googlenet(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
all_predictions.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 计算平均验证损失
avg_val_loss = val_loss / len(val_loader)
val_losses.append(avg_val_loss)
# 计算准确率
Accuracy = 100 * correct / total
accuracy_list.append(Accuracy)
# 计算F1分数
f1 = f1_score(all_labels, all_predictions, average='binary') # 适用于二分类问题
f1_list.append(f1) # 将当前 epoch 的 F1 分数添加到列表中
# 调整学习率
scheduler.step(f1)
# 打印验证集上的损失、准确率和运行时间
print(f"Epoch {epoch + 1}/{epochs}, Validation Loss: {avg_val_loss}, Validation Accuracy: {Accuracy}%,Time: {time.time() - end_time:.2f} seconds,测试F1分数: {f1:.4f}")
# 绘制训练损失曲线
plt.figure(figsize=(8, 6))
plt.plot(range(epochs), train_losses, label='Train Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Training Loss Curve')
plt.show()
# 绘制验证损失曲线
plt.figure(figsize=(8, 6))
plt.plot(range(epochs), val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Validation Loss Curve')
plt.show()
# 绘制准确率曲线
plt.figure(figsize=(8, 6))
plt.plot(range(epochs), accuracy_list, label='Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.show()
# 绘制F1曲线
plt.figure(figsize=(8, 6))
plt.plot(range(epochs), f1_list, label='F1')
plt.xlabel('Epochs')
plt.ylabel('F1')
plt.legend()
plt.title('F1 Curve')
plt.show()
# 保存模型
torch.save(googlenet.state_dict(), 'googlenet_model.pth')训练过程中损失值变化如下:
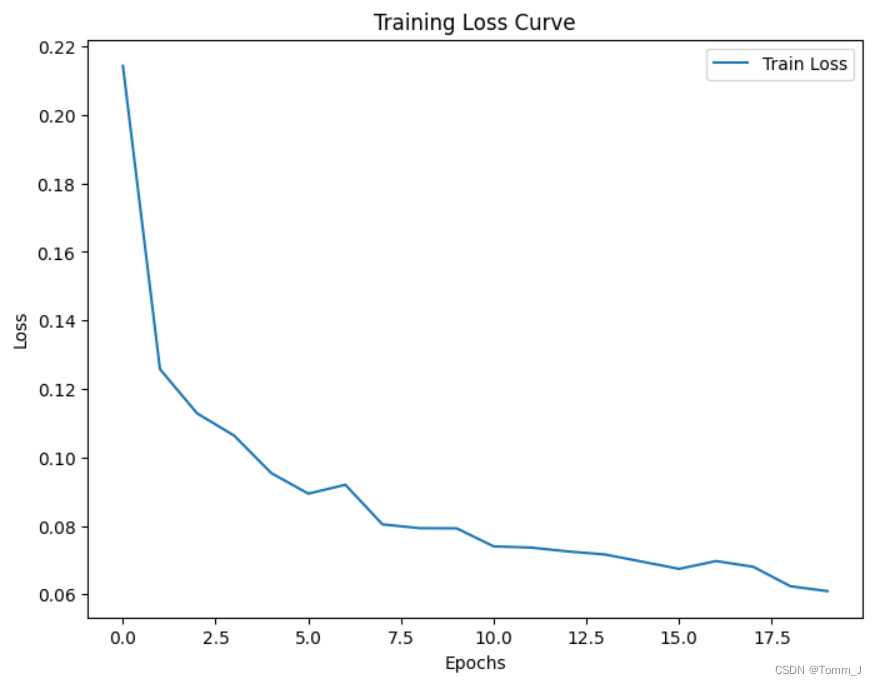
3.5测试模型
3.5.1用test1测试
在test1数据集中测试图像,并打印图像和测试结果
# 随机选择一个测试图像
test_path = '../data/test1'
test_files = [file for file in os.listdir(test_path) if file.lower().endswith('.jpg')]
select_test = np.random.choice(test_files, 1, replace=False)
image_path = os.path.join(test_path, select_test[0])
# 读取并转换测试图像
image = Image.open(image_path).convert('RGB') # 如果需要,转换为RGB格式
image_tensor = transform(image).unsqueeze(0) # 添加批量维度
# 显示原始图像
image_np = np.array(image)
plt.imshow(image_np)
plt.axis('off')
plt.show()
# 模型推理
model = googlenet
model.load_state_dict(torch.load('googlenet_model.pth', map_location=torch.device('cpu')))
model.eval()
start_test_time = time.time()
with torch.no_grad():
output = model(image_tensor.to(device))
_, predicted_label = output.max(1)
end__test_time = time.time()
# 输出预测标签
print("预测标签:", "猫" if predicted_label.item() == 0 else "狗")
print(f"Time: {end__test_time - start_test_time:.2f} seconds")
在测试单张图片时,模型的速度时非常快的,结果也是准确的。
3.5.2用test数据集测试模型
在test测试集中,测试模型的性能。
#测试集
test1_dataset_path = '../data/test'
test1_file_names = os.listdir(test1_dataset_path)
print("测试集大小:{}".format(len(test1_file_names)))
test1_dataset = SelfDataset(root_dir=test1_dataset_path, transform=transform)
test1_loader = DataLoader(dataset=test1_dataset, batch_size=64, shuffle=False)
test1_loss = 0.0
correct1 = 0
total1 = 0
all_predictions1 = []
all_labels1 = []
model = googlenet
model.load_state_dict(torch.load('googlenet_model.pth', map_location=torch.device('cpu')))
model.eval()
start_test_time = time.time()
with torch.no_grad():
for inputs, labels in test1_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test1_loss += loss.item()
_, predicted = outputs.max(1)
total1 += labels.size(0)
correct1 += predicted.eq(labels).sum().item()
all_predictions1.extend(predicted.cpu().numpy())
all_labels1.extend(labels.cpu().numpy())
end_test_time = time.time()
# 计算平均验证损失
avg_test_loss = test1_loss / len(test1_loader)
# 计算准确率
Accuracy1 = 100 * correct1 / total1
# 计算F1分数
f1 = f1_score(all_labels1, all_predictions1, average='binary') # 适用于二分类问题
# 打印验证集上的损失、准确率和运行时间
print(f"Validation Loss: {avg_test_loss}, Validation Accuracy: {Accuracy1}%, Time: {end_test_time - start_test_time:.2f} seconds,测试F1分数: {f1:.4f}")在数据集为1000时,准确率为0.980,F1值为0.9800,用时7.37s,可见模型的效果是不错的,准确率也是比较高的。

4:使用oneAPI组件优化以及量化模型
4.1oneAPI简介
"oneAPI" 是一个由多家公司和技术组织共同创建的开放式、可互操作的框架,用于开发各种应用和系统,尤其是那些在数据和计算密集型环境中的应用。oneAPI 的目标是促进软件供应商和开发人员之间更广泛的协作,通过统一的工具、编程模型和运行时,实现更好的性能、能源效率和灵活性。
oneAPI 组件通常包括:
- oneAPI 编译器:这是一个将高级编程语言(如 C++ 或 Python)代码转化为低级硬件特定代码的工具。编译器利用各种优化技术来提高运行时性能。
- oneAPI 运行时:运行时是应用在硬件上执行的中间件,它为应用提供了对硬件的访问。它能够将编译后的代码与硬件资源进行映射,并管理这些资源的分配。
- oneAPI 库:这些库提供了各种功能,如数学运算、信号处理、并行计算等。它们被设计为与 oneAPI 编译器和运行时协同工作,以提供最佳的性能和效率。
- oneAPI 工具:这些工具包括性能分析器、调试器、代码分析器等,用于帮助开发人员诊断和优化他们的应用。
- oneAPI 框架:框架是用于构建和部署应用的软件开发环境。它们提供了一组抽象和接口,使得开发人员可以更高效地编写和部署应用。
通过使用 oneAPI,开发人员可以编写一次代码,然后将其部署到多种硬件平台(如 CPU、GPU、FPGA 等)上,而无需进行大量的重写或调整。这大大简化了应用开发和部署的过程,并提高了效率。
4.2使用Intel Extension for PyTorch进行优化
Intel Extension for PyTorch是一个用于优化PyTorch应用的库,它基于Intel的硬件平台,提供了多种优化工具和功能,可以加速PyTorch模型的训练和推断。这个扩展库基于PyTorch的扩展机制实现,通过提供额外的软件优化来极致地发挥硬件特性,帮助用户在原生PyTorch的基础上更最大限度地提升Intel CPU上的深度学习推理计算和训练性能。
# 加载预训练的 GoogLeNet 模型
googlenet_model = models.googlenet(pretrained=True)
# 修改最后的全连接层以适应猫狗大战的二分类任务
num_features = googlenet_model.fc.in_features
googlenet_model.fc = nn.Linear(num_features, 2) # 输出层改为2个类别
googlenet_model.load_state_dict(torch.load('googlenet_model.pth', map_location=torch.device('cpu')))
#模型调为评估模式
googlenet_model.eval()
# 使用Intel Extension for PyTorch进行优化
googlenet_model = ipex.optimize(model=googlenet_model, dtype=torch.float32)4.3对优化后的模型进行测试
用test数据集对优化后的模型进行评估,对比优化前后的模型性能,查看优化效果
test_loss = 0.0
correct = 0
total = 0
all_predictions = []
all_labels = []
#载入模型
googlenet_optimized_model = googlenet_model
#模型调为评估模式
googlenet_optimized_model.eval()
start_test_time = time.time()
with torch.no_grad():
for inputs, labels in test1_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = googlenet_optimized_model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
all_predictions.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
end_test_time = time.time()
# 计算平均验证损失
avg_test_loss = test_loss / len(test1_loader)
# 计算准确率
Accuracy = 100 * correct / total
# 计算F1分数
f1 = f1_score(all_labels, all_predictions, average='binary') # 适用于二分类问题
# 打印测试集上的损失、准确率和运行时间
print(f"Validation Loss: {avg_test_loss}, Validation Accuracy: {Accuracy}%,Time: {end_test_time - start_test_time:.2f} seconds,测试F1分数: {f1:.4f}")优化后的模型准确率变化不大,为0.983,F1值为0.9830,但是时间为4.63s,相比于优化前时间有较明显的提升

4.4量化模型
量化是一种优化深度神经网络的技术,其目的是减小模型的存储需求、加速推理速度,并降低硬件资源的要求。主要通过减少权重和激活值的位数(通常是从 32 位浮点数减少到 8 位整数或更低位数)来实现。以下是量化的一些关键概念和优势:
权重量化:浮点数到定点数,将原本使用浮点数表示的权重转换为定点数。通常使用更低位的整数来表示权重,例如 8 位整数;剪枝,将接近于零的权重设为零,减小权重的存储需求。
激活值量化:限制激活范围,将神经网络中激活值的范围限制在一个较小的区间内,例如 0 到 1;整数表示,使用整数来表示激活值,通常也是较低位的整数,例如 8 位整数。
训练中的量化:对称量化,将权重和激活值量化为带符号整数,通常使用零点对称(zero-point symmetric)的方法;非对称量化,非对称量化允许零点(zero-point)不等于零,提供更灵活的表示。
后训练量化:离线量化,在模型训练完成后,对模型进行离线量化;在线量化,在模型训练的同时,引入量化训练的步骤。
优势:减小模型大小,通过减小权重和激活值的位数,大幅减小模型的存储需求;提高推理速度,低位宽的计算通常更快,因此量化可以提高推理速度;降低功耗,在嵌入式设备和移动设备上,量化可以降低功耗,延长电池寿命。
注意事项:准确性损失, 量化可能导致模型准确性的损失,因此需要在准确性和性能之间进行权衡;量化训练,在线量化训练可以减小准确性损失,但引入了额外的计算成本。
本项目对优化后模型采用后训练量化:
#量化模型
from neural_compressor.config import PostTrainingQuantConfig, AccuracyCriterion
from neural_compressor import quantization
loaded_model = googlenet_model
loaded_model.to(device)
# 将模型调为评估模式
loaded_model.eval()
# 定义评估函数
def eval_func(model):
loaded_model.eval() # 设置模型为评估模式
with torch.no_grad():
y_true = []
y_pred = []
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
preds_probs = loaded_model(inputs)
preds_class = torch.argmax(preds_probs, dim=-1)
y_true.extend(labels.cpu().numpy())
y_pred.extend(preds_class.cpu().numpy())
return accuracy_score(y_true, y_pred)
conf = PostTrainingQuantConfig(backend='ipex',
accuracy_criterion=AccuracyCriterion(higher_is_better=True,
criterion='relative',
tolerable_loss=0.01))
# 执行量化
with torch.no_grad():
q_model = quantization.fit(loaded_model,
conf,
calib_dataloader=train_loader,
eval_func=eval_func)
# 保存量化模型
quantized_model_path = './quantized_models'
if not os.path.exists(quantized_model_path):
os.makedirs(quantized_model_path)
q_model.save(quantized_model_path)量化成功后出现如下代码:

查看量化后的模型,分别为pt文件和json文件:

加载模型:
import torch
import json
from neural_compressor import quantization
# 指定量化模型的路径
quantized_model_path = './quantized_models'
# 加载 Qt 模型和 JSON 配置
googlenet_model_path = f'{quantized_model_path}/best_model.pt'
json_config_path = f'{quantized_model_path}/best_configure.json'
# 加载 Qt 模型
googlenet_model = torch.jit.load(googlenet_model_path, map_location='cpu')
# 加载 JSON 配置
with open(json_config_path, 'r') as json_file:
json_config = json.load(json_file)
进行推理:
# 随机选择一个测试图像
test_path = '../data/test1'
test_files = [file for file in os.listdir(test_path) if file.lower().endswith('.jpg')]
select_test = np.random.choice(test_files, 1, replace=False)
image_path = os.path.join(test_path, select_test[0])
# 读取并转换测试图像
image = Image.open(image_path).convert('RGB') # 如果需要,转换为RGB格式
image_tensor = transform(image).unsqueeze(0) # 添加批量维度
# 显示原始图像
image_np = np.array(image)
plt.imshow(image_np)
plt.axis('off')
plt.show()
# 模型推理
googlenet_model.eval()
start_test_time = time.time()
with torch.no_grad():
output = googlenet_model(image_tensor.to(device))
_, predicted_label = output.max(1)
end__test_time = time.time()
# 输出预测标签
print("预测标签:", "猫" if predicted_label.item() == 0 else "狗")
print(f"Time: {end__test_time - start_test_time:.2f} seconds")推理结果:

5:总结
在使用oneAPI的优化组件以后,推理的时间大幅度下降,从原来的7.37s到目前的4.63s,其次,在使用量化工具以后,模型变小,在整个过程中F1分数的值一直稳定在0.98左右,这是一个非常好的现象。证明了oneAPI优秀的模型压缩能力,在保证模型精确度,F1值的基础上还能够缩小模型的规模。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









