






1.项目简介
1.1问题描述
淡水是我们最重要和最稀缺的自然资源之一,仅占地球总水量的 3%。它几乎触及我们日常生活的方方面面,从饮用、游泳和沐浴到生产食物、电力和我们每天使用的产品。获得安全卫生的供水不仅对人类生活至关重要,而且对正在遭受干旱、污染和气温升高影响的周边生态系统的生存也至关重要。
1.2预期解决方案:
通过参考英特尔的类似实现方案,预测淡水是否可以安全饮用和被依赖淡水的生态系统所使用,从而可以帮助全球水安全和环境可持续性发展。这里分类准确度和推理时间将作为评分的主要依据。
1.3数据集
训练集:https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
测试集:https://pan.baidu.com/s/1Eu_7hL_Kda8MvVqv46sOEA
提取码:asd3
2.数据探索
2.1查看数据集
查看数据集前五行
data = pandas.read_csv('../data/dataset.csv')
display(data.head())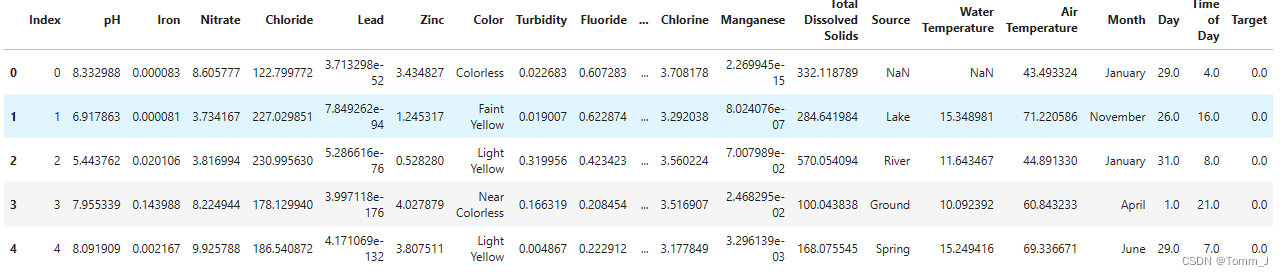
查看各类特征是离散值还是连续值。
cat_cols = [] # 存储离散特征
float_cols = [] # 存储连续特征
for col in data.columns:
if data[col].dtype == 'object':
cat_cols.append(col)
else:
float_cols.append(col)
print('离散特征:', cat_cols)
print('连续特征:', float_cols)

将离散数据转化为连续数据
factor = pd.factorize(data['Color'])
print(factor)
data.Color = factor[0]
factor = pd.factorize(data['Source'])
print(factor)
data.Source = factor[0]
factor = pd.factorize(data['Month'])
print(factor)
data.Month = factor[0]
data.describe()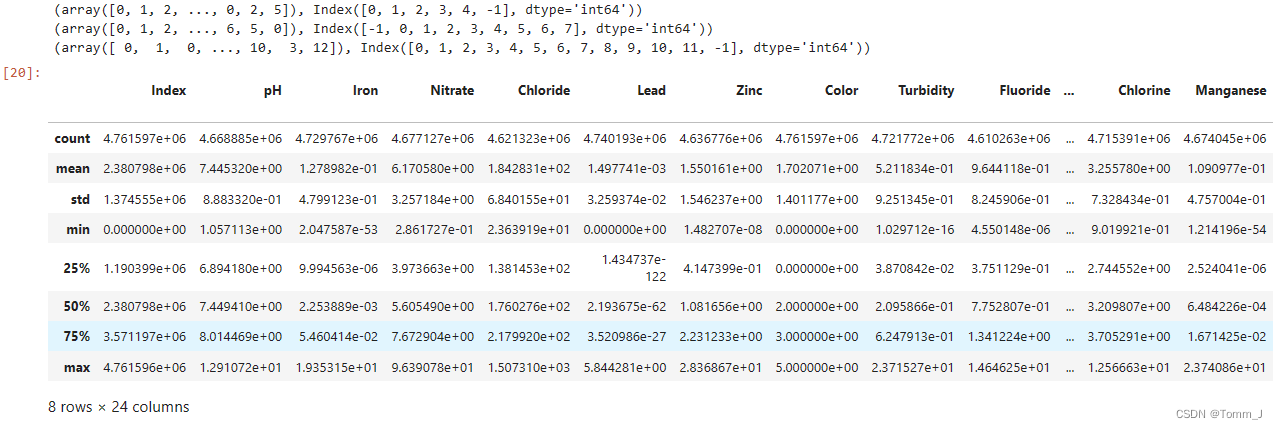
2.2数据可视化
查看数据类别
通过饼状图直观反映数量对比。
# 统计 Target 列中 0 和 1 的数量
target_counts = data['Target'].value_counts()
# 绘制饼形图
plt.figure(figsize=(8, 6))
plt.pie(target_counts, labels=target_counts.index, autopct='%1.1f%%', startangle=140)
plt.title('Distribution of Target')
plt.axis('equal') # 使饼图为正圆形
plt.show()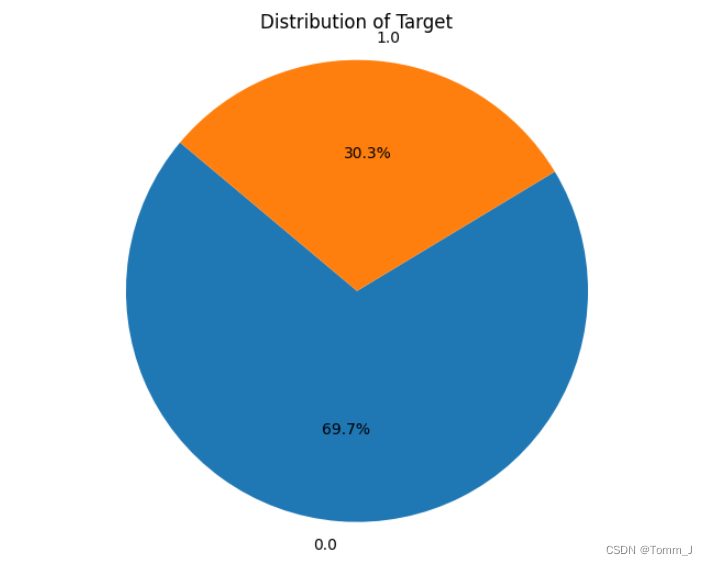
热力图
显示属性之间的两两相关性
# 计算属性之间的相关系数矩阵
correlation_matrix = data.corr()
# 绘制热力图
plt.figure(figsize=(12, 10))
sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", fmt=".2f", linewidths=0.5)
plt.title("Correlation Heatmap of Attributes")
plt.show()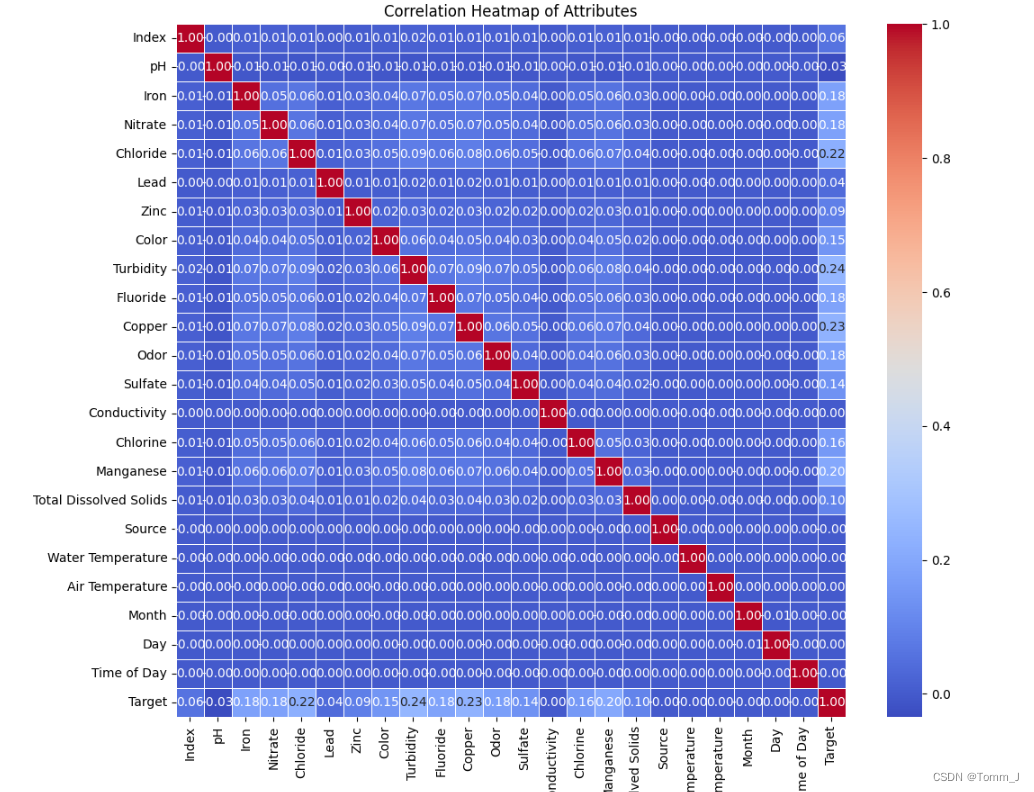
绘制出属性与目标变量之间的相关系数柱形图。
import matplotlib.pyplot as plt
# 计算属性与目标变量之间的相关系数
correlation_with_target = data.corr()['Target'].sort_values(ascending=False)
# 绘制柱形图
plt.figure(figsize=(10, 6))
correlation_with_target.plot(kind='bar', color='skyblue')
plt.title('Correlation with Target Variable')
plt.xlabel('Features')
plt.ylabel('Correlation')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()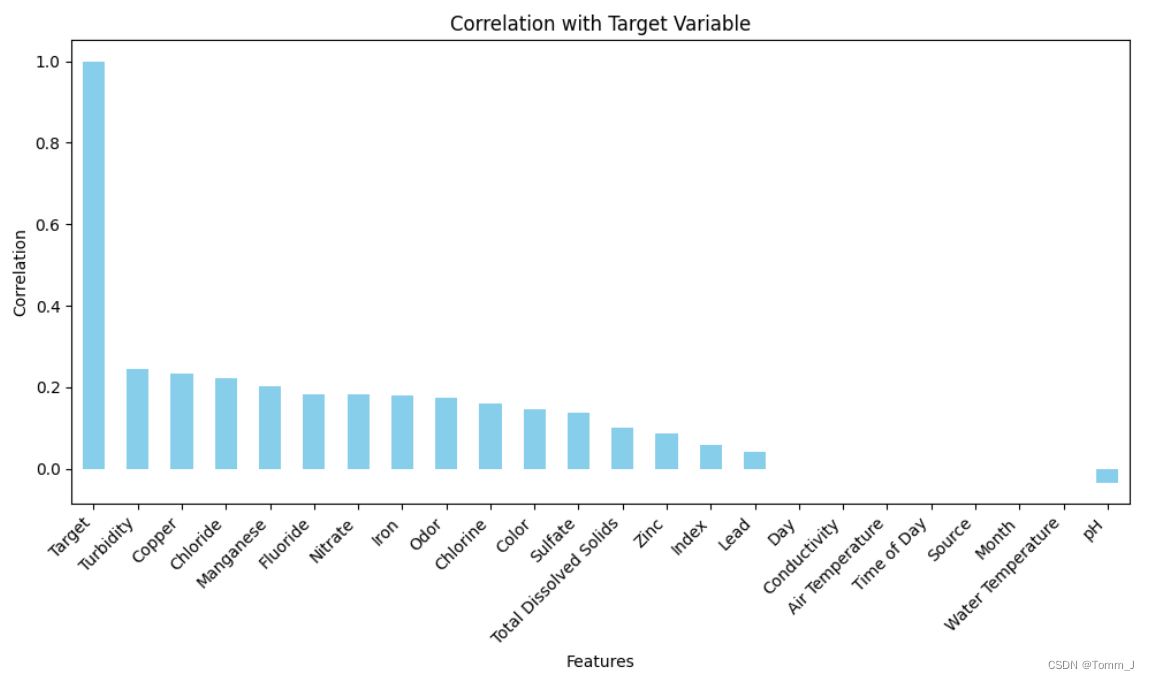
3.数据处理
删除不相关列
data = data.drop(
columns=['Index', 'Day', 'Time of Day', 'Month', 'Water Temperature', 'Source', 'Conductivity', 'Air Temperature'])3.1获取各列的缺失值数量
# 获取各列的缺失值数量
missing_values = data.isnull().sum()
print(missing_values)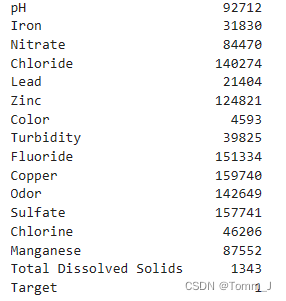
3.2处理缺失值和重复值
数据完整性:通过填充缺失值,保证了数据的完整性,避免了由于缺失值导致的数据不完整的情况。
特征选择:根据特征的方差和与目标变量的相关性进行特征选择,删除了方差较小且与目标变量相关性较低的特征,有助于减少特征空间的维度,提高模型的训练效率和泛化能力。
提高模型性能:通过删除无关特征和噪声,可以提高模型的性能和预测准确性,使模型更加精确地捕捉数据的规律。
# 填充缺失值为均值
mean_value = data.mean()
data.fillna(mean_value, inplace=True)
# 删除方差较小的特征和与目标变量相关性较低的特征
var = data.var()
numeric = data.columns
for i in range(len(var) - 1):
if var[i] <= 0.1: # 方差小于或等于10%
data = data.drop(numeric[i], axis=1)
variables = data.columns
for i in range(len(variables)):
x = data[variables[i]]
y = data[variables[-1]]
if pearsonr(x, y)[1] > 0.05: # 相关性 p 值大于0.05
data = data.drop(variables[i], axis=1)
# 输出处理后的数据
print(data.head())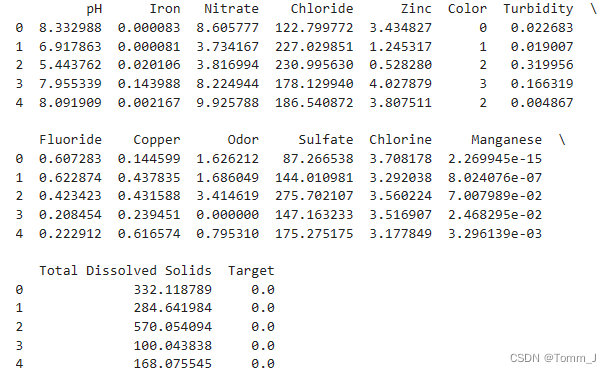
4.训练模型
XGBoost(eXtreme Gradient Boosting)是一种非常流行的机器学习算法,特别适用于回归和分类问题。它是一种基于决策树的集成学习算法,以其出色的性能和可扩展性而闻名。以下是XGBoost的一些关键特点:
梯度提升框架(Gradient Boosting Framework):XGBoost是一种梯度提升框架,通过迭代地训练决策树来逐步改进模型的性能。
正则化:XGBoost在目标函数中引入了正则化项,以防止过拟合,包括L1和L2正则化。
高性能:XGBoost实现了并行处理和高效的缓存优化,以提高训练速度。它还支持分布式计算,可以在大规模数据集上进行训练。
灵活性:XGBoost支持多种损失函数和分裂准则,使其适用于各种类型的问题。
特征重要性:XGBoost可以计算特征的重要性得分,帮助识别最相关的特征。
缺失值处理:XGBoost能够自动处理缺失值,不需要对数据进行预处理。
可解释性:虽然XGBoost是一种复杂的模型,但它仍然提供了一些解释模型预测的功能,例如特征重要性排序和树结构可视化。
4.1划分数据
将数据集换分为训练集和测试集,其中训练集占80%,测试集占20%。
from imblearn.under_sampling import RandomUnderSampler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import datetime
X = data.iloc[:, 0:len(data.columns.tolist()) - 1].values
y = data.iloc[:, len(data.columns.tolist()) - 1].values
# # 下采样
under_sampler = RandomUnderSampler(random_state=21)
X, y = under_sampler.fit_resample(X, y)
X = data.drop('Target', axis=1)
y = data['Target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=21)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("Train Shape: {}".format(X_train_scaled.shape))
print("Test Shape: {}".format(X_test_scaled.shape))
X_train, X_test = X_train_scaled, X_test_scaled4.2构建模型设置参数
from sklearn.metrics import make_scorer, precision_score, recall_score, accuracy_score,f1_score, roc_auc_score
from xgboost import XGBClassifier
param_grid = {
'max_depth': [10, 15, 20],
"gamma": [0, 1, 2],
"subsample": [0.9, 1],
"colsample_bytree": [0.3, 0.5, 1],
'min_child_weight': [4, 6, 8],
"n_estimators": [10,50, 80, 100],
"alpha": [3, 4, 5]
}
scorers = {
'precision_score': make_scorer(precision_score),
'recall_score': make_scorer(recall_score),
'accuracy_score': make_scorer(accuracy_score),
'f1_score': make_scorer(f1_score),
'roc_auc_score': make_scorer(roc_auc_score),
}
xgb = XGBClassifier(
learning_rate=0.1,
n_estimators=15,
max_depth=12,
min_child_weight=6,
gamma=0,
subsample=1,
colsample_bytree=1,
objective='binary:logistic', # 二元分类的逻辑回归,输出概率
nthread=4,
alpha=4,
scale_pos_weight=1,
seed=27)
4.3训练模型
refit_score = "f1_score"
start_time = datetime.datetime.now()
print(start_time)
rd_search = RandomizedSearchCV(xgb.XGBClassifier(), param_grid, n_iter=10, cv=3, refit=refit_score, scoring=scorers, verbose=10, return_train_score=True)
rd_search.fit(X_train, y_train)
print(rd_search.best_params_)
print(rd_search.best_score_)
print(rd_search.best_estimator_)
print(datetime.datetime.now() - start_time)
4.4模型预测
对验证集进行预测
import joblib
import time
from sklearn.metrics import f1_score
# 加载保存的模型
loaded_model = joblib.load('best_xgb_model.joblib')
# 开始计时
start_time = time.time()
# 使用加载的模型进行预测
predictions = loaded_model.predict(X_test_scaled)
# 结束计时
end_time = time.time()
# 计算预测时间
prediction_time = end_time - start_time
print("预测时间(秒):", prediction_time)
# 计算F1分数
f1 = f1_score(y_test, predictions)
print("F1分数:", f1)预测时间为约0.079秒,F1分数为约0.895。
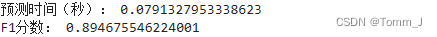
对测试集进行预测
test_data = pd.read_csv('../data/test_data.csv')
test_data = test_data.drop(
columns=['Index' ,'Day','Lead', 'Time of Day', 'Month', 'Water Temperature', 'Source', 'Conductivity', 'Air Temperature'])
factor = pd.factorize(test_data['Color'])
print(factor)
test_data.Color = factor[0]
X = test_data.iloc[:, 0:len(test_data.columns.tolist()) - 1].values
y = test_data.iloc[:, len(test_data.columns.tolist()) - 1].values
X = test_data.drop('Target', axis=1)
y = test_data['Target']
# 开始计时
start_time = time.time()
# 使用加载的模型进行预测
predictions = loaded_model.predict(X)
# 结束计时
end_time = time.time()
# 计算预测时间
prediction_time = (end_time - start_time)
print("预测时间(秒):", prediction_time)
# 计算F1分数
f1 = f1_score(y, predictions)
print("F1分数:", f1)预测时间为约0.084秒,F1分数为约0.90。
















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









