







配置
1)创建Flume配置文件
在hadoop102节点的Flume的job目录下创建file_to_kafka.conf
[atguigu@hadoop104 flume]$ mkdir job
[atguigu@hadoop104 flume]$ vim job/file_to_kafka.conf
2)配置文件内容如下
#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
#自定义拦截器 拦截不合法的json
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c1
3)编写Flume拦截器
(1)创建Maven工程flume-interceptor
(2)创建包:com.atguigu.gmall.flume.interceptor
(3)在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
(4)在com.atguigu.gmall.flume.interceptor包下创建ETLInterceptor类
package com.atguigu.flume;
import com.google.gson.JsonElement;
import com.google.gson.JsonParser;
import com.google.gson.JsonSyntaxException;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
/**
* TODO类描述
*
* @author LZ
* @Date 2022/9/17 14:41
* @Description
*/
public class ETLInterceptor implements Interceptor {
private JsonParser jsonParser =null;
@Override
public void initialize() {
jsonParser=new JsonParser();
}
@Override
public Event intercept(Event event) {
//1.提取Body转化为string
byte[] body = event.getBody();
String line = new String(body, StandardCharsets.UTF_8);
//2.用json解析器解析
try {
JsonElement jsonElement = jsonParser.parse(line);
return event;
} catch (JsonSyntaxException e) {
//解析失败的丢弃
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
list.removeIf(next -> intercept(next) == null);
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
(6)打包
(7)引入自定义拦截器
方法一:需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面。
方法二:flume有安装第三方插件的功能
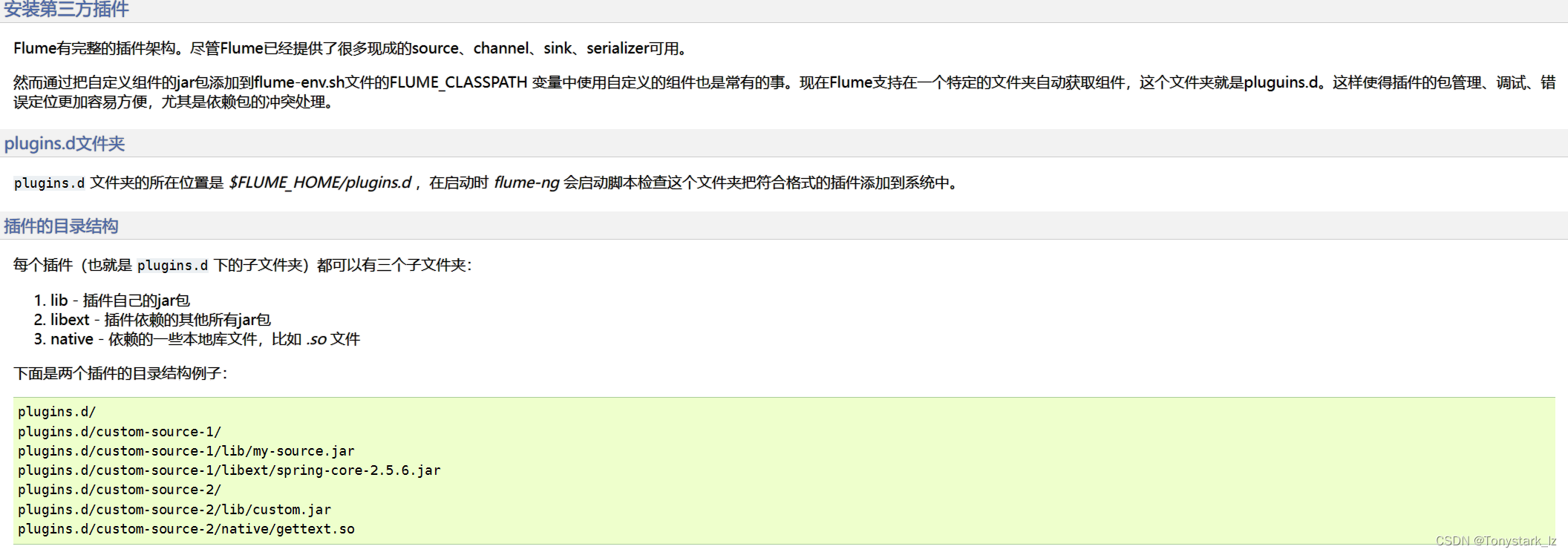
具体操作方式如下:
[atguigu@hadoop102 flume]$ mkdir plugins.d
[atguigu@hadoop102 flume]$ cd plugins.d/
[atguigu@hadoop102 plugins.d]$ mkdir etlinterceptor
[atguigu@hadoop102 plugins.d]$ cd etlinterceptor/
[atguigu@hadoop102 etlinterceptor]$ mkdir lib
[atguigu@hadoop102 etlinterceptor]$ mkdir libext
[atguigu@hadoop102 etlinterceptor]$ mkdir native
[atguigu@hadoop102 etlinterceptor]$ ll
总用量 0
drwxrwxr-x. 2 atguigu atguigu 6 9月 17 16:05 lib
drwxrwxr-x. 2 atguigu atguigu 6 9月 17 16:05 libext
drwxrwxr-x. 2 atguigu atguigu 6 9月 17 16:05 native
[atguigu@hadoop102 etlinterceptor]$ cd lib
[atguigu@hadoop102 lib]$ rz -E
rz waiting to receive.
[atguigu@hadoop102 lib]$ ll
总用量 8
-rw-r--r--. 1 atguigu atguigu 5796 9月 17 16:02 flumeplugin-1.0-SNAPSHOT.jar
测试
0)启动Zookeeper、Kafka集群
1)在Kafka中新建名为topic_log的topic
[atguigu@hadoop102 kafka]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --topic topic_log --create --partitions 3 --replication-factor 2
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic topic_log.
[atguigu@hadoop102 kafka]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --list
topic_log
2)启动hadoop102的日志采集Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
3)启动一个Kafka的Console-Consumer
[atguigu@hadoop102 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log --from-beginning --group test01
4)生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh
5)观察Kafka消费者是否能消费到数据
启停脚本
若上述测试通过,需将hadoop102节点的Flume的配置文件和拦截器jar包,向另一台日志服务器发送一份。
方便起见,此处编写一个日志采集Flume进程的启停脚本
在hadoop102节点的/home/atguigu/bin目录下创建脚本f1.sh
[atguigu@hadoop102 bin]$ vim f1.sh
在脚本中填写如下内容
#!/bin/bash
function f1_start(){
xcall -w 'hadoop102,hadoop103' "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
}
function f1_stop(){
xcall -w 'hadoop102,hadoop103' "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9"
}
case $1 in
"start")
f1_start
;;
"stop")
f1_stop
;;
"restart")
f1_stop
sleep 2
f1_start
;;
*)
echo "$0 start|stop|restart"
;;
esac
增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod +x f1.sh
f1启动
[atguigu@hadoop102 bin]$ f1.sh start
[atguigu@hadoop102 bin]$ jpsall
=============== hadoop102 ===============
3984 Kafka
2403 QuorumPeerMain
5722 Application
5165 ConsoleConsumer
5838 Jps
=============== hadoop103 ===============
2306 Kafka
2547 Application
2661 Jps
1455 QuorumPeerMain
=============== hadoop104 ===============
2307 Kafka
2522 Jps
1453 QuorumPeerMain















 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









