







1、Flume概述
Flume 是Cloudera开发的一个分布式的、可靠的、高可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化的数据存储系统中。随着互联网的发展,特别是移动互联网的兴起,产生了海量的用户日志信息,为了实时分析和挖掘用户需求,需要使用Flume高效快速采集用户日志,同时对日志进行聚合避免小文件的产生,然后将聚合后的数据通过管道移动到存储系统进行后续的数据分析和挖掘。

2、 Flume架构设计
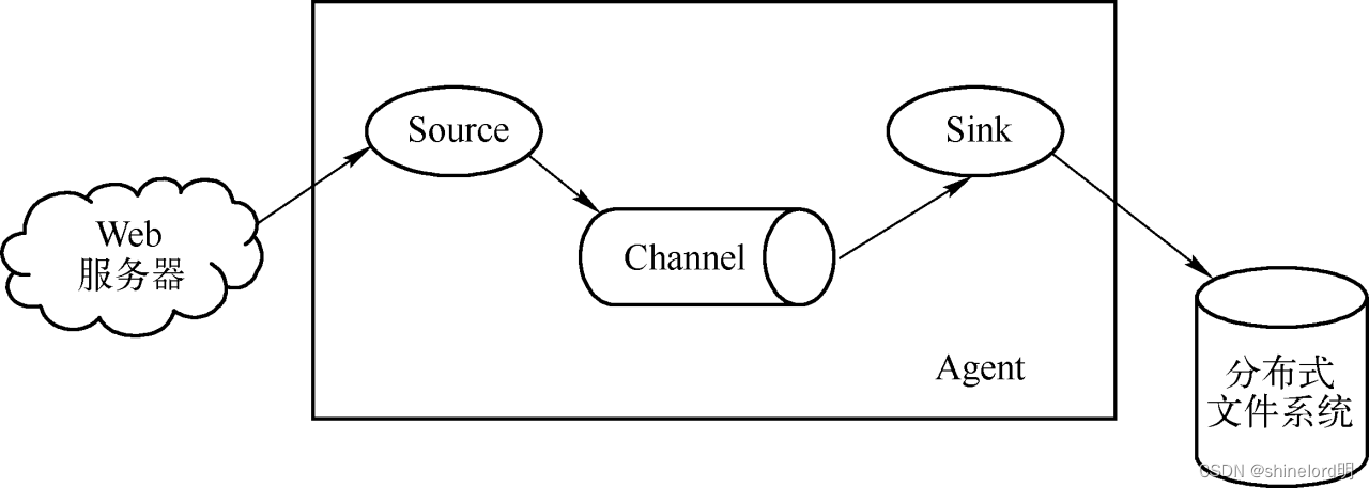
Flume架构图


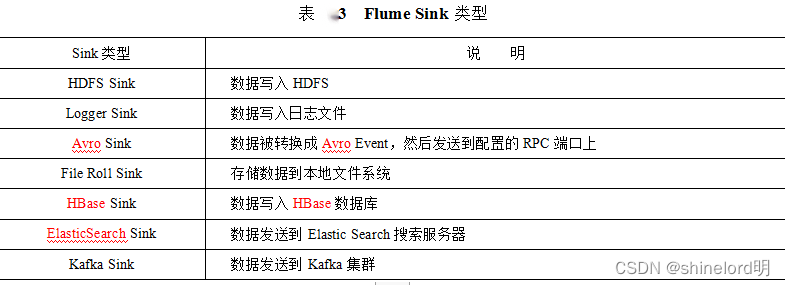
3、Flume安装部署
下载并解压
[hadoop@hadoop1 app]$ tar -zxvf apache-flume-1.9.0-bin.tar.gz
[hadoop@hadoop1 app]$ ln -s apache-flume-1.9.0-bin flume修改配置文件
[hadoop@hadoop1 conf]$ mv flume-conf.properties.template flume-conf.properties [hadoop@hadoop1 conf]$ cat flume-conf.properties
#定义source channel
sink agent.sources = seqGenSrc agent.channels = memoryChannel
agent.sinks = loggerSink
# 默认配置source类型为序列产生器
agent.sources.seqGenSrc.type = seq
agent.sources.seqGenSrc.channels = memoryChannel
# 默认配置sink类型为logger a
gent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memoryChannel
#默认配置channel类型为memory
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 100启动Flume Agent
Flume命令行参数解释如下: Flume-ng脚本后面的agent代表启动Flume进程,-n指定的是配置文件中Agent的名称,-c指定配置文件所在目录,-f指定具体的配置文件,-Dflume.root.logger=INFO,console指的是控制台打印INFO,console级别的日志信息。
[hadoop@hadoop1 flume]$ bin/flume-ng agent -n agent -c conf -f conf/flume-conf.properties -Dflume.root.logger=INFO,console4、案例实践:Flume集群搭建
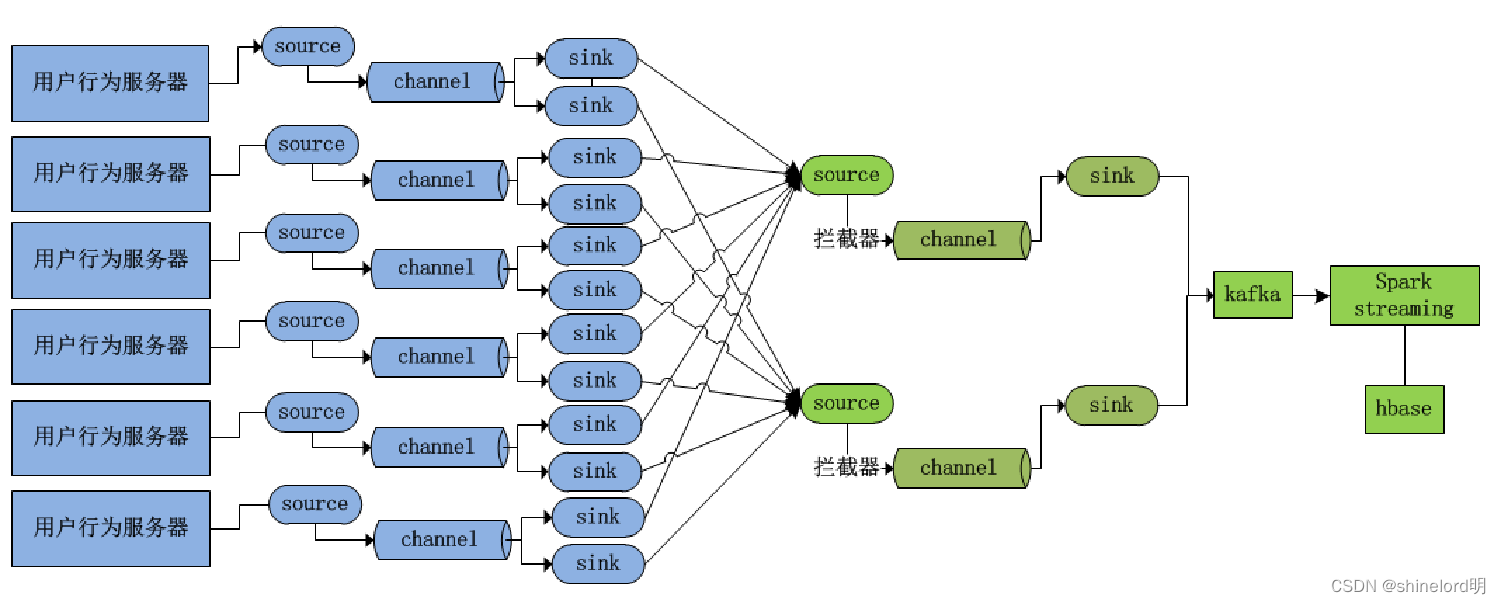
Flume集群架构图
配置Flume采集服务
[hadoop@hadoop1 conf]$ vi taildir-file-selector-avro.properties
#定义source、channel、sink的名称
agent1.sources = taildirSource agent1.channels = fileChannel agent1.sinkgroups = g1 agent1.sinks = k1 k2
# 定义和配置一个TAILDIR Source
agent1.sources.taildirSource.type = TAILDIR agent1.sources.taildirSource.positionFile = /home/hadoop/data/flume/taildir_position.json agent1.sources.taildirSource.filegroups = f1 agent1.sources.taildirSource.filegroups.f1 = /home/hadoop/data/flume/logs/sogou.log agent1.sources.taildirSource.channels = fileChannel
# 定义和配置一个file channel
agent1.channels.fileChannel.type = file配置Flume聚合服务
[hadoop@hadoop2 conf]$ vi avro-file-selector-logger.properties
[hadoop@hadoop3 conf]$ vi avro-file-selector-logger.properties
#定义source、channel、sink的名称
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1
# 定义和配置一个avro Source
agent1.sources.r1.type = avro
agent1.sources.r1.channels = c1
agent1.sources.r1.bind = 0.0.0.0
agent1.sources.r1.port = 1234
# 定义和配置一个file channel
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /home/hadoop/data/flume/checkpointDir agent1.channels.c1.dataDirs = /home/hadoop/data/flume/dataDirs
# 定义和配置一个logger sink
agent1.sinks.k1.type = logger
agent1.sinks.k1.channel = c1启动Flume聚合服务
[hadoop@hadoop2 flume]$ bin/flume-ng agent -n agent1 -c conf -f conf/avro-file-selector-logger.properties -Dflume.root.logger=INFO,console
[hadoop@hadoop3 flume]$ bin/flume-ng agent -n agent1 -c conf -f conf/avro-file-selector-logger.properties -Dflume.root.logger=INFO,console 启动Flume采集服务
[hadoop@hadoop1 flume]$ bin/flume-ng agent -n agent1 -c conf -f conf/taildir-file-selector-avro.properties -Dflume.root.logger=INFO,console准备测试数据
[hadoop@hadoop1 logs]$echo '00:00:10 0971413028304674 [梅西夺冠时间] 1 2 https://zhidao.baidu.com/question/313859864097901324.html' >> goal.log














 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









