







关于SVM算法
SVM,即Support Vector Machine(支持向量机),是一种使用线性分割平面的二元分类算法。其原理是通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
如图所示:
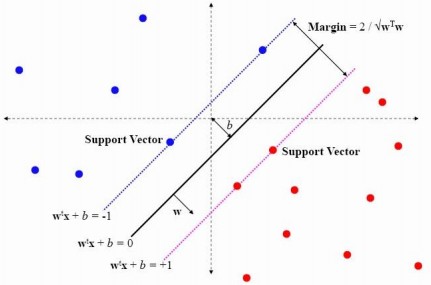
更多详细内容可查看:http://blog.csdn.net/v_july_v/article/details/7624837。
SVM的优与劣
| SVM | 优点 | 缺点 |
|---|---|---|
| 1 | 利用内积核函数代替向高维空间的非线性映射;简化了通常的分类和回归等问题 | 对大规模训练样本难以实施:由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。 |
| 2 | 少数支持向量决定了最终结果:这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。 | 解决多分类问题存在困难:经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。 |
Spark实现SVM算法(Java)
SVM作为一种二元分类算法,同样只预期0或1的标签。通过SVMWithSGD类,我们可以访问这种算法,它的参数与线性回归和逻辑回归的参数差不多。返回的SVMModel与LogisticRegressionModel一样使用阈值的方式进行预测。
//进行Spark的配置
SparkConf conf = new SparkConf().setAppName("GMM").setMaster("local");
conf.set("spark.testing.memory","2147480000"); //Spark的运行配置,意指占用内存2G
JavaSparkContext sc = new JavaSparkContext(conf);//获取训练样本
JavaPairRDD<Integer,String> trainRDD = sc.parallelizePairs(list); //将每类的标签词转化为RDD
JavaPairRDD<Integer,String> trainSetRDD = trainRDD.mapValues(new ToTrainSet(vocabulary)); //将标签词转化为向量模型
List<Tuple2<Integer,String>> trainSet = trainSetRDD.collect();
writeTrainSet(trainSet); //写成libsvm文件格式,以方便训练
System.out.println("trainset is ok");
//读取训练集并训练模型
String path = "./trainset";
JavaRDD<LabeledPoint> trainData = MLUtils.loadLibSVMFile(sc.sc(),path).toJavaRDD()//测试集生成
double [] d = {1,1,2};
Vector v = Vectors.dense(d);//测试对象为单个vector,或者是RDD化后的vector//支持向量机
int numIterations = 100;//迭代次数
final SVMModel svm_model = SVMWithSGD.train(trainData.rdd(), numIterations);//构建模型
System.out.println(svm_model.predict(v));参考资料:
1.SVM的优缺点
2.Spark MLlib SVM算法















 4513
4513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









