






本文主要是基于自己现阶段的知识去理解为什么要提出这些网络?以及是如何去思考网络的改进的方式?如何去找到问题并提出对策解决?找到问题是核心。
RCNN
RCNN的提出背景是因为CNN等网络(AlexNet,ResNet等)的兴起和有效性。
当时CNN网络主要用于图像分类,像前面的那些经典网络,对图像进行处理了之后直接全连接层就可以输出图像的类别,如果引入目标检测领域,显然存在这样可以直接想到的问题,
1.因为我是需要进行目标检测,图像中可能存在很多的目标,我如何在图像中找到可能存在的目标区域?
如果进行滑动窗口的方法,效率很低,也会找到很多冗余的部分,那我需要用一个更快速的方法在原图中找到潜在的目标区域。
这个问题,RCNN中使用选择性搜索SS(Selective Search)的方法进行解决,也就是在原图像中找到一组可能包含目标的候选框。
选择性搜索(Selective Search):
优点:
- 效率较高:比滑动窗口方法生成的候选框数量大幅减少。
- 覆盖全面:结合多尺度、多颜色空间和分割策略,能生成高质量的候选区域,几乎不漏检目标。
局限性:
- 速度慢:虽然比滑动窗口快,但选择性搜索仍然需要数秒才能处理一张图像,成为 RCNN 的性能瓶颈。
- 无法实时应用:由于选择性搜索的速度限制,RCNN 不能用于实时场景。
- 缺乏优化:选择性搜索本质是启发式算法,不能通过反向传播进行优化。
目前从原图中通过这个选择性搜索的方法生成了一组候选区域,大约2k个。接下来就可以按照图像分类的方法使用那些经典网络对选择的2k个的每一个区域进行特征提取(使用那些经典网络),然后进行分类和坐标框回归。
不过,还有一些细节需要考虑:
由于那些经典网络虽然比较方便,但是它们需要固定的输入的大小,所以(Selective Search)的方法需要resize为统一的大小。(resize的原因好像也是因为方便?
改变的方法在SPP Net中实验了两种warp和crop,显然存在一些问题(不完整等等),如何处理可以看一下这篇的总结:
【目标检测】研究生第二次组会汇报PPT(初稿)_目标检测汇报ppt模板-CSDN博客

其次,坐标框回归是2k个基于选择的区域的,所以我需要知道这些选择的区域的坐标(在使用Selective Search的时候,输出就是选择区域和位置坐标了),然后再输入坐标框回归的模型进行坐标调整(通过目标框的真实坐标和需要的输出,这里我没有看原文,但是根据损失函数就可以知道去调整这个需要的输出是什么)。输入这个回归模型的也是经典网络提取出的特征,这些output回归到四个参数,用于调整。(如何约束,就是损失函数的事情,所以输出的是什么只要通过损失函数可以约束就行,不一定是直接输出坐标,也可以输出坐标的调整参数或者偏移量都可以)

总结一下这个流程:

Fast RCNN
后来,出现了Fast RCNN的方法,
但是如果是我,我如何去分析RCNN的问题?
我想到的是:
1.问题:前面选择出来的框有2k个,每一个图像都要经过裁剪、特征提取,这样需要计算量很大。
那我能从哪些地方进行改进呢?
1)选了2k个候选区域,这个太多了。但是已经进行了各种多尺度分割、合并、筛选IOU的操作,降低了候选框的个数,这个方法还能有什么改进呢?
2)很明显,这2k个区域虽然是实验得到的能够平衡模型结果的参数,但是2k个确实是冗余和重复的,一张图像中存在目标的基本上只有两位数,而这些冗余的部分都要进行后半部分的模型(通过那些经典网络进行特征提取),导致模型计算量很大。
所以该如何做呢?如果不改变模型的结构,改变方法,就只能往改进(Selective Search)的方向去想。如果可以改变结构,该怎么改?
2.由于使用的是SVM方法,有10个类的话就需要10个SVM,每一个选择区域的特征图都需要经过这10个SVM,同时这些输出还要经过这个回归的部分,进行坐标的修正。可以看到这个模型不是端到端的,过程是阶段阶段性的。
对于这个问题,可以直接使用全连接层进行输出。
Fast RCNN 是这样解决第一个问题的,
它采用改变结构的思路,从前面的分析可以看到增大计算量有两个,一个是2k,一个CNN网络对2k进行特征提取的阶段
Fast RCNN相当于减少了CNN网络对2k进行特征提取的阶段的计算量,直接对原图进行特征提取F1,然后和基于原图得到的2k个区域R1进行对齐,也就是在F1中找到R1对应的特征框。这个操作是ROI池化操作。(ROI Align是mask rcnn中提出的)
先看Fast RCNN的结构:
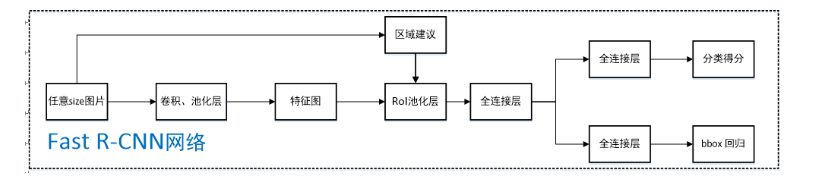
接下里解释ROI Pooling操作:
(虽然写的池化层,但是实际上进行了ROI映射和ROI pooling两个操作)
ROI映射的操作是根据F1和2k个区域,找到2K个区域对应的特征图。
ROI池化的操作是将这些特征图转化为相同的大小。
根据在原图中提取的R1的位置坐标将F1中的特征池化为固定尺寸的特征图。
后面进阶的ROI Align的目的是更好的找到区域边界框的位置。
一个是原图像的特征图,一个是特征,这怎么映射?
由于特征图是F1一般是通过下采样得到的,我们知道下采样的倍数,知道这个下采样倍数就可以将候选框的坐标映射到特征图的区域。因此,就得到了2k个特征图来表示候选区域。

总结一下:
Faster RCNN
可以看到Fast RCNN 还是没有放弃2k个区域提议的部分,这是主要导致时间长的问题
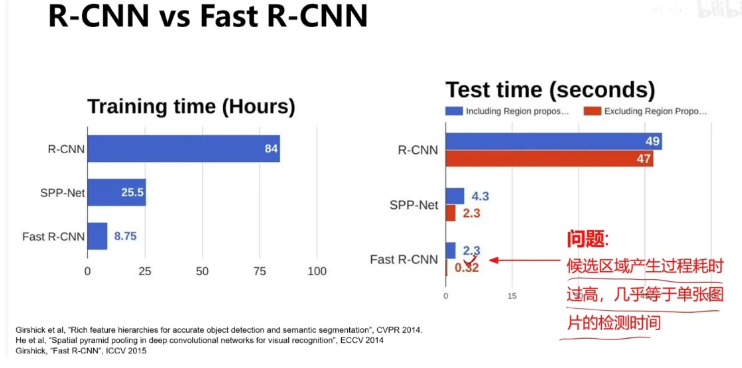
那去除这个部分可以吗?不用selective search生成2k个区域?
可以看到前面对于Fast RCNN来说,这个selective search的主要作用是给特征图提供位置坐标,根据这个位置坐标找到合适的特征图。最终目的是找到合适的region proposal,用于选择合适的特征图。
所以我想取消这个部分的 话,就需要找到一个操作可以代替selective search,也就是在特征图中可以根据另一个操作选出一下候选区域。
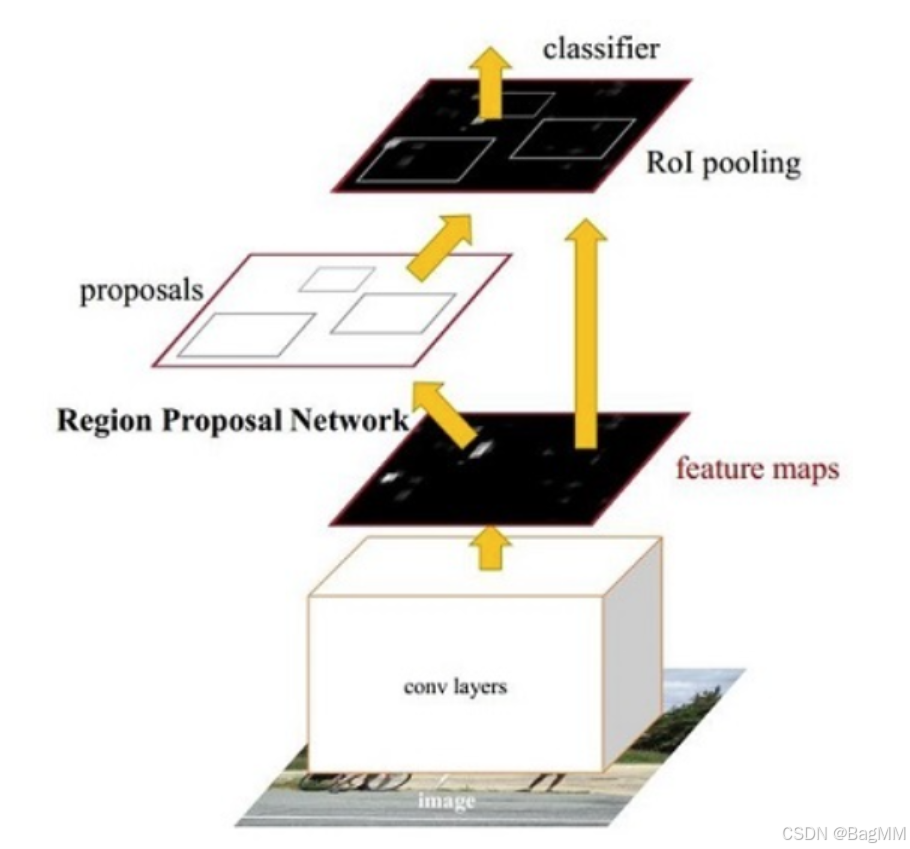
于是,在Faster RCNN中,采用了RPN网络来代替这个过程。用一个可以学习的网络来代替找到候选区域的问题。注意,这个部分是代替了selective search,其他操作和Fast RCNN是相同的。
selective search是在原图上进行的
RPN就是在特征图上进行的,选取大概目标概率前300个合适的框到ROI操作中。
注意:RPN的分类损失不是对最终类别进行分类。
RPN的操作可以理解为仅仅是为了初步选择一个合适proposal而存在,后面详细的解释为什么不直接用 RPN 的输出进行最终检测,而需要进一步通过 ROI 操作对区域进行细化处理?
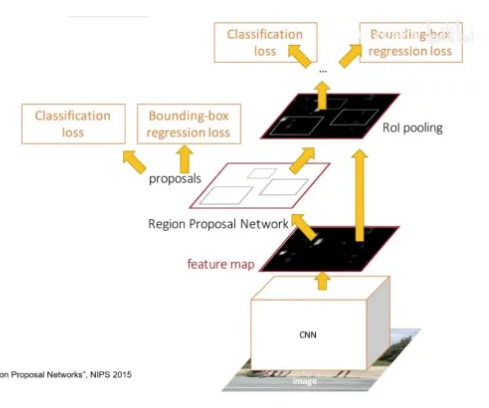

怎么想到的用RPN进行选择,前面都是用的一些定则的方法,随着神经网络的兴起,发现神经网络通过损失函数约束,可以做到同样的事情,而且神经网络的处理还可以学习,不断优化,可能是这样的原因最后用一个网络结构来替代selective search的操作。
那这里就有一个显然的问题,为什么不直接用 RPN 的输出进行最终检测,而需要进一步通过 ROI 操作对区域进行投影?

因此,RPN 更像是一个候选区域生成器,它关注快速生成高召回率的框,而不是细化框或提供高精度分类。
这个细化的操作就是ROI和最终的分类器需要进行的。

那RPN一开始可能的潜在的区域的位置是如何初始化的?
一个想当然的想法就是使用一些现成的方法快速生成潜在区域?
总结一下ROI pooling
ROI pooling这个操作经常被其他论文借鉴使用,在这里对比一下Fast RCNN和Faster RCNN 这两篇文章中的ROI pooling操作的异同。
首先,Fast RCNN 的ROI pooling (ROI 池化操作)是SS操作在原图上找到坐标框并根据这个坐标框在原图上找到对应特征坐标框的内容部分的特征图。
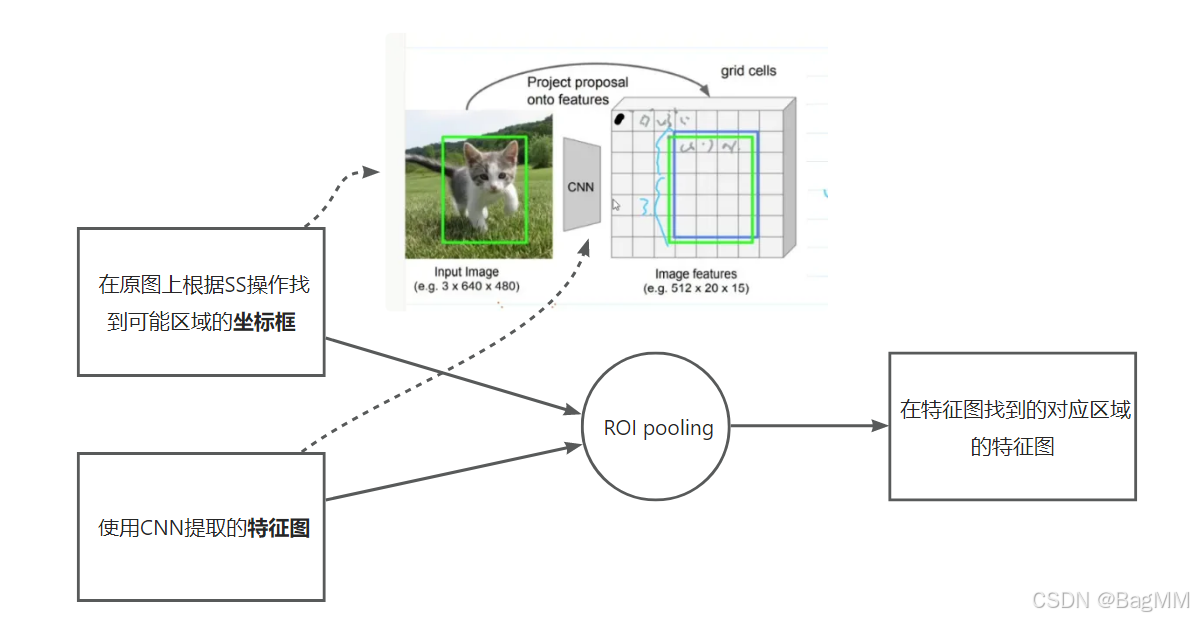
其次,Faster RCNN 相当于用RPN操作替换了SS,不需要在原图上找,而是直接在特征图上面找,通过损失函数约束粗略的找到(positive or negative & 目标框)一些潜在的区域位置的坐标框proposals(每个框的坐标)。RoI Pooling即兴趣域池化(SPP net中的空间金字塔池化)则用于收集RPN生成的proposals(每个框的坐标),并从(1)中的feature maps中提取出来(从对应位置扣出来),生成proposals feature maps送入后续全连接层继续做分类(具体是哪一类别)和回归。
为了更好的理解,从源码角度去理解一下:
参考文献:
RCNN, Fast R-CNN 与 Faster RCNN理解及改进方法 - 知乎


















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











