









数据集下载链接:AffectNet – Mohammad H. Mahoor, PhD (mohammadmahoor.com)
数据集介绍:
1. 数据集包含11个类别的表情,根据其他研究者的使用的情况来看,前面7类或者8类是常使用的。
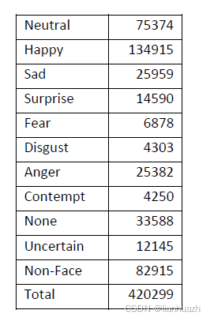
2.数据集分为手动和自动标注两个部分:
自动标注的数据集更大一些,53万多张并且没有分割出训练集和训练集。
手动标注的数据集分割出来了训练集和数据集,一共有42万张左右。
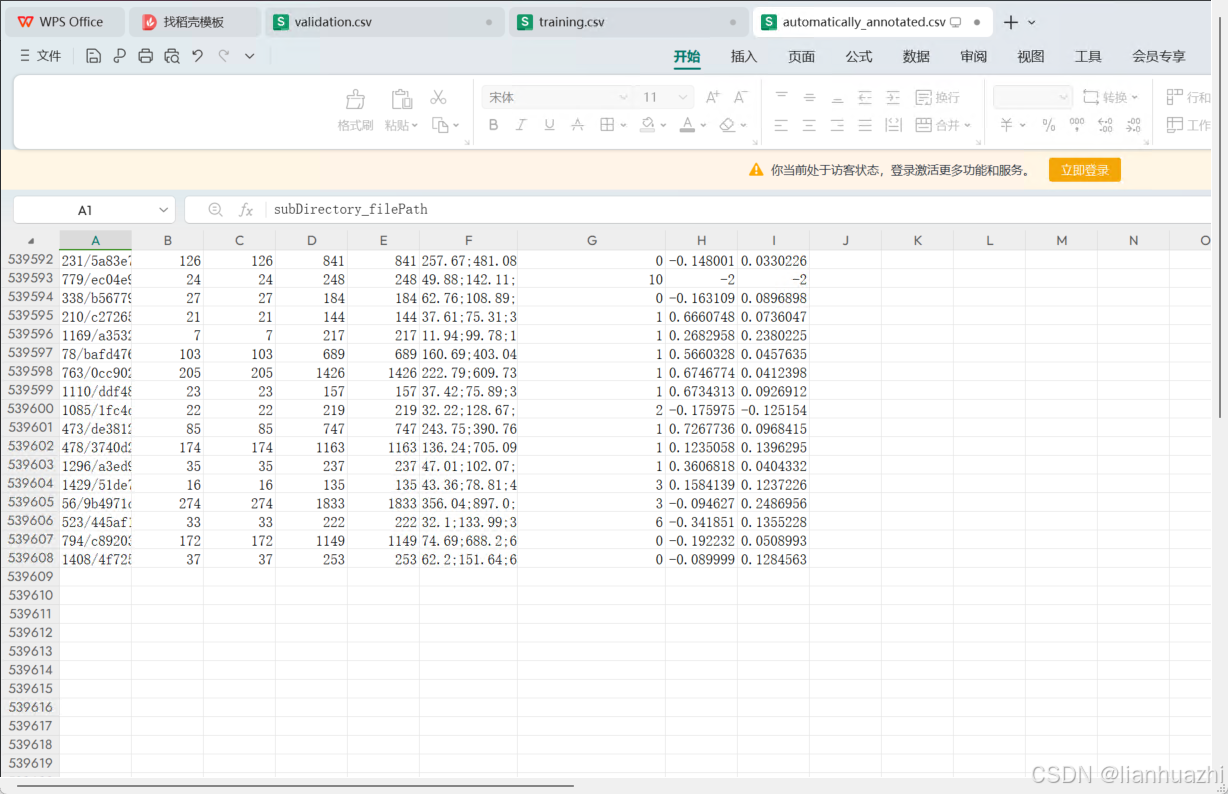
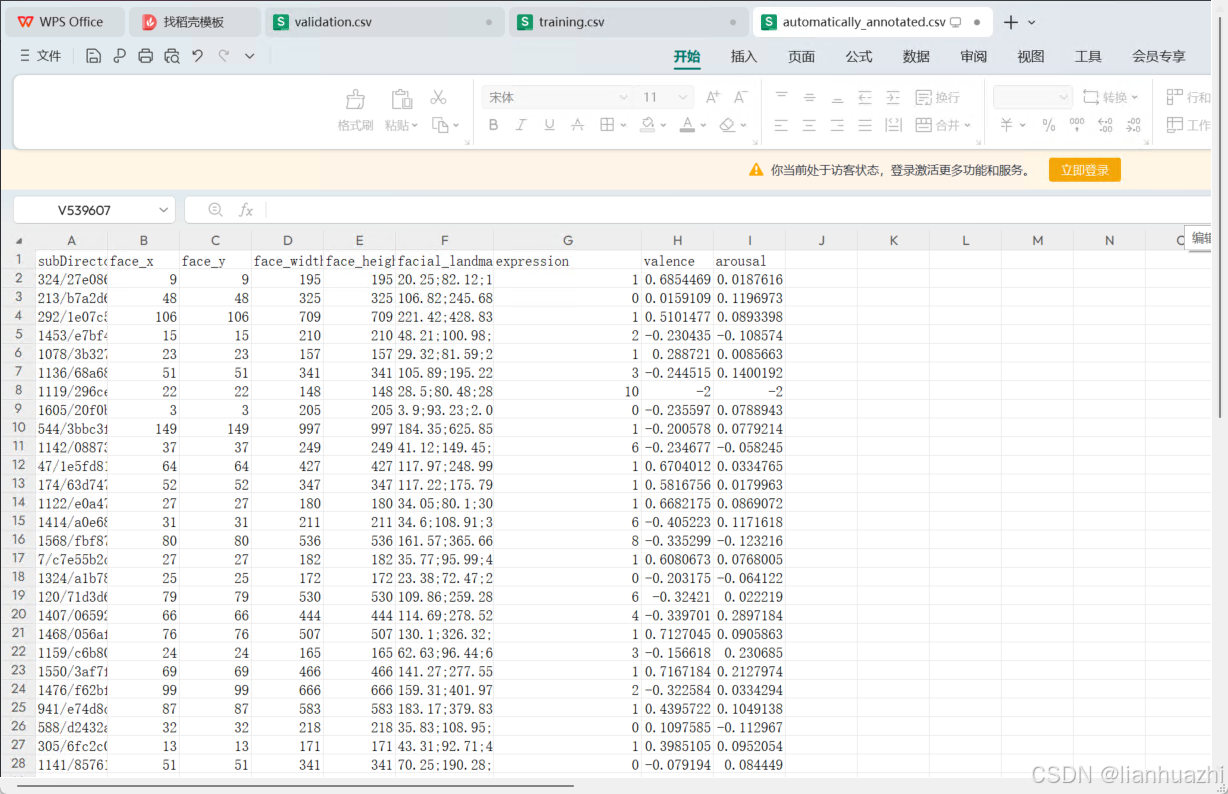
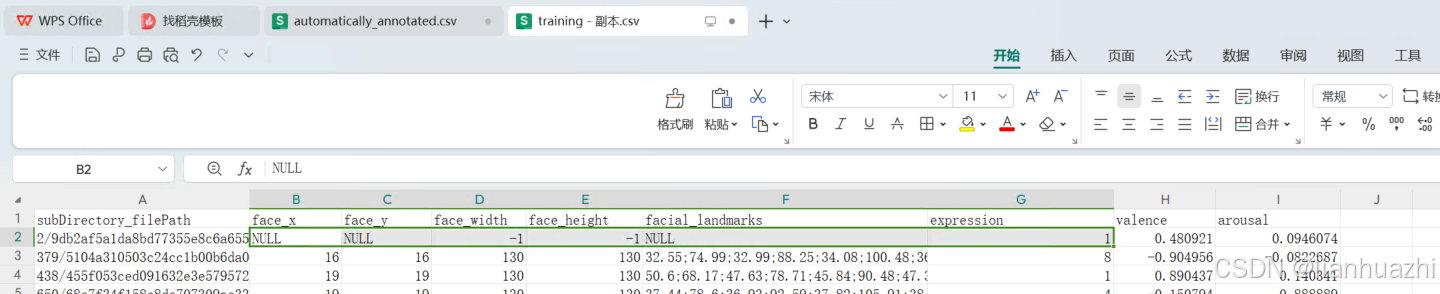
3.标注的内容和数据都放在csv表格里面,表头分别是:图片的相对路径,图像中表情人脸的坐标,facial_landmark(人脸标注点),表情类型,
valence和arousal是心理学里面的术语,valence是衡量情感价值或者情感的愉悦度,正面情感具有高 valence,而负面情感具有低 valence。
arousal是情感的激活或唤醒水平,Arousal 可以是高或低,高唤醒水平可能与兴奋、紧张或愤怒等情感状态相关,而低唤醒水平可能与放松、平静或无聊等状态相关。
在情感分析和人机交互领域,valence 和 arousal 常常一起使用,它们构成了情感状态的两个维度,可以用来更细致地描述和分析一个人的情感体验。这种二维情感模型有时被称为情感的 "情感空间"(affective space),可以用来表示情感的不同状态,如快乐、悲伤、愤怒或恐惧等。
数据集清洗:
1.通过标注点把人脸图像表情裁剪出来
出现的问题
1)找不到部分图片
2)图片位置标注为NULL
代码:
# 首先把图片按照csv文件中的图像的坐标把图像裁剪出来
# 再按照类别把图像按照不同的类别放在不同的文件夹中
import os
import csv
from PIL import Image, UnidentifiedImageError
init_path= '。。。\AffectNet' # root path
image_path = os.path.join(init_path,'Manually_Annotated\Manually_Annotated\Manually_Annotated_Images')
annot_path = os.path.join(init_path,'Manually_Annotated_file_lists')
# 读取csv文件的内容,根据第一列的内容找到图片第一列图片的相对路径 file_path=(689/737db2483489148d783ef278f43f486c0a97e140fc4b6b61b84363ca.jpg),根据后面的坐标剪裁
# 完整的路径是 pic_path=os.path.join(image_path,file_path)
# 两个csv文件,trian和val
# 定义裁剪图像的函数
def crop_image(image_path, left, top, width, height):
try:
with Image.open(image_path) as img:
cropped_image = img.crop((left, top, left + width, top + height))
return cropped_image
except (IOError, FileNotFoundError, UnidentifiedImageError) as e:
print(f"Skipping image {image_path} due to an error: {e}")
return None
# 处理CSV文件
def process_csv(file_name, category_folder,init_path):
with open(os.path.join(annot_path, file_name), newline='') as csvfile:
reader = csv.reader(csvfile)
next(reader) # 跳过标题行
for row in reader:
# Check if any of the coordinates are NULL and skip the row
if 'NULL' in row[1:5]:
print(f"Skipping row with NULL coordinates: {row}")
continue
file_path = row[0] # 第一列是文件路径
left, top, width, height = map(int, row[1:5])
category = row[6] # 第7列是类别
# 构建完整的图片路径
full_image_path = os.path.join(image_path, file_path)
full_image_path = os.path.normpath(full_image_path) # 标准化路径
# 裁剪图像
cropped_image = crop_image(full_image_path, left, top, width, height)
if cropped_image:
# 创建类别文件夹,如果不存在的话
category_dir = os.path.join(init_path, category_folder, category)
if not os.path.exists(category_dir):
os.makedirs(category_dir)
# 保存裁剪后的图像到对应的类别文件夹
file_name = os.path.basename(file_path)
cropped_image.save(os.path.join(category_dir, file_name))
else:
print(f"Could not process image {full_image_path}, skipping.")
# 处理训练集和验证集
process_csv('training.csv', 'train',init_path)
process_csv('validation.csv', 'val',init_path)


















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











