






目录
Faster-RCNN(RPN+Faster R-CNN)的不同点:
一:回顾
上一篇我们了解了单发多框检测(SSD),是一种用于目标检测的深度学习模型。"单发"指的是指单个神经网络在一次前向计算中同时预测多个目标的位置和类别,而"多框"指的是对于每个预测目标位置,它的主要思想是在整个图像上应用多个卷积层来预测不同尺度和长宽比的边界框,并通过非极大值抑制来获得最终的检测结果。SSD的优点是可以在较少的计算量下实现实时目标检测,并且可以检测不同尺度和长宽比的物体。
二:RCNN
R-CNN首先从输入图像中选取若干(例如2000个)提议区域(如锚框也是一种选取方法),并标注它们的类别和边界框(如偏移量)。 (Girshick et al., 2014)然后,用卷积神经网络对每个提议区域进行前向传播以抽取其特征。 接下来,我们用每个提议区域的特征来预测类别和边界框。
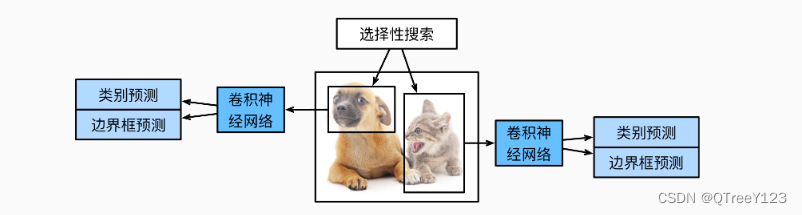
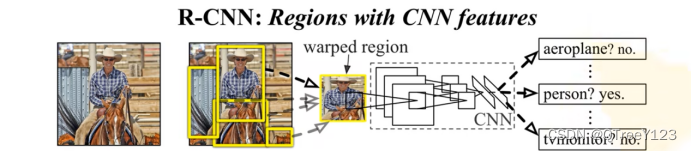

RCNN算法流程4步:

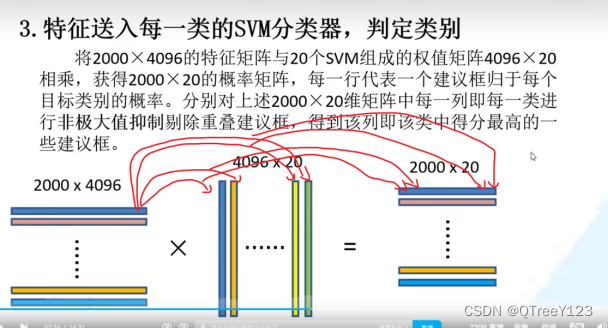
对偏移量做损失
RCNN存在的问题:
用ss算法生成一系列候选框,通过回归器调整偏移量。训练器和回归器相互独立导致训练速度很慢的原因之一

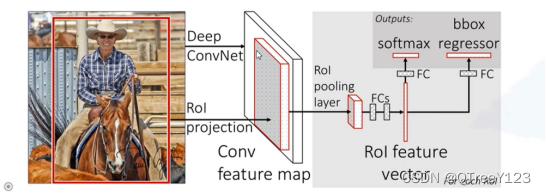
三:Fast-RCNN:
R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。 由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。 Fast R-CNN (Girshick, 2015)对R-CNN的主要改进之一,是仅在整张图象上执行卷积神经网络的前向传播。
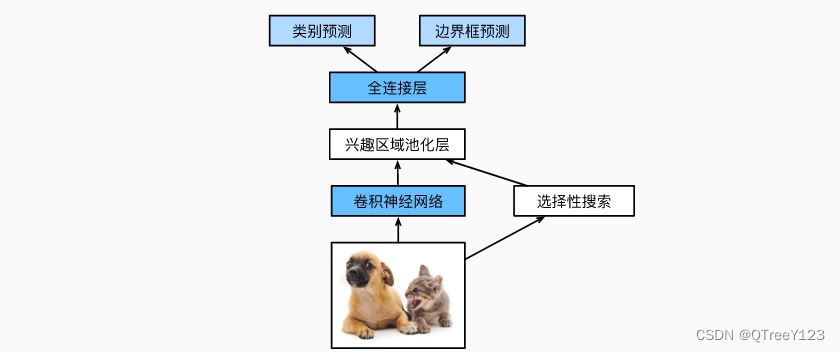

Fast-RCNN(相比与R-CNN快了200多倍 ,但是在cpu上预测还是很慢),再下一步faster-RCNN就想办法把SS算法融入到网络中,就形成了端对端的训练过程。
四:Faster R-CNN:
为了较精确地检测目标结果,Fast R-CNN模型通常需要在选择性搜索中生成大量的提议区域。 Faster R-CNN (Ren et al., 2015)提出将选择性搜索替换为区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。
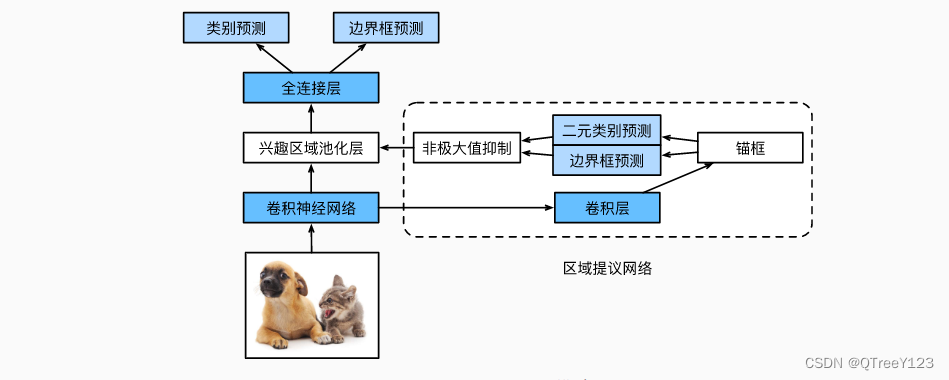


Faster-RCNN(RPN+Faster R-CNN)的不同点:
用RPN网络代替了SS算法生成预选框

五:Mask R-CNN
如果在训练集中还标注了每个目标在图像上的像素级位置,那么Mask R-CNN (He et al., 2017)能够有效地利用这些详尽的标注信息进一步提升目标检测的精度。
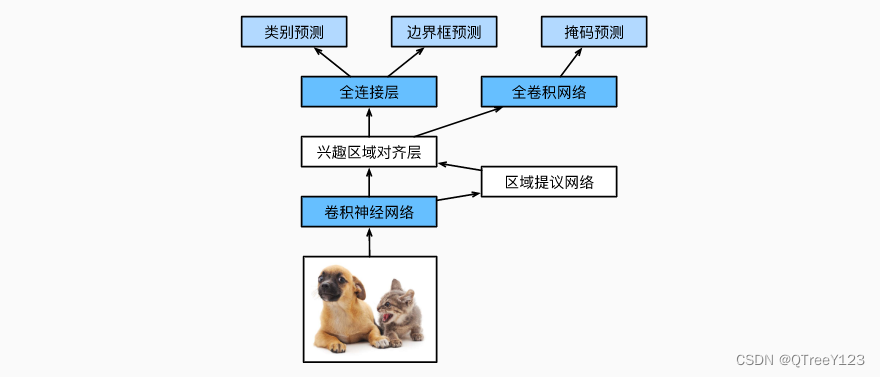
Mask R-CNN是基于Faster R-CNN修改而来的。 具体来说,Mask R-CNN将兴趣区域汇聚层替换为了 兴趣区域对齐层,使用双线性插值(bilinear interpolation)来保留特征图上的空间信息,从而更适于像素级预测。 兴趣区域对齐层的输出包含了所有与兴趣区域的形状相同的特征图。 它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置。
六:总结
R-CNN是单独ss算法提取预选框,然后CNN做特征提取,然后svm做分类,然后偏移量做回归。Fast R-CNN是单独拿出来一个SS算法来生成预选框,而其他三个部分是在CNN网络中。而Faster R-CNN是RPN代替SS算法来提取预选框。4个部分却别融合在CNN网络中,是个整体。
所有项目代码+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章















 2048
2048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









